基于双路聚类的在线学习行为分析研究
2022-01-11单志龙
彭 涛, 单志龙,2*
(1. 华南师范大学计算机学院, 广州 510631; 2. 华南师范大学网络教育学院, 广州 510631)
随着社会整体水平的迅猛发展,人们对知识的渴求愈发强烈,远程教育系统进入公众的视野,为学生实现自主学习提供了机会[1]. 然而,远程教育在提供便利的同时,由于其具有丰富的教育资源,在学习过程中较难给予学习者更有针对性的学习服务[2]. 因此,基于学习者学习行为数据,借助技术手段对学习者进行分析,已经成为当下教育数据挖掘的重要研究内容.
目前教育大数据挖掘领域处于快速发展阶段[3],学者们从多个方面对教育数据进行挖掘. 如:RUIPEREZ-VALIENTE等[4]使用聚类算法对学生在游戏场景中的行为进行分析,将学生分为学习很认真、中等认真以及不认真3类;SHOU等[5]利用相似度矩阵分类出学习风格相似的群体并且规划了更合适的学习路径;KCA等[6]将LLM算法应用于学生辍学预测方面,结果表明不同的学生群体对课程有着不同的理解模式;吴青等[7]使用关联规则对继续教育的学生进行数据挖掘,得出的14条规则为学生与教师双向促进提供了依据;WANG和JIANG[8]基于ARCS模型分析学习行为,认为自测和学习前置课程对学习效果有显著提升;张莉等[9]将支持向量机应用于高考成绩的预测,最终证明支持向量机的准确度比神经网络的更高;WIDYAHASTUTI和TJHIN[10]通过观测学生在论坛中的学习表现来预测学生的学习潜力.
考虑到教育资源数据具有隐含性,许多属性无法从数据记录中直接获取[11],仅采用统计型粗粒度数据作为输入将会造成一定程度的信息损失,而用细粒度特征可降低数据具有的隐含性所带来的困扰[12-13]. 如,蒋卓轩等[14]在获取统计型特征后将其融合为更具有实际意义的细粒度特征,并以此为基础将学习者分为五大类型,进而分析不同类型学习者的学习行为.
在进行教育数据挖掘时,大多研究仅通过对单一角度的粗粒度数据进行单路数据挖掘建模[15-16],易出现分类效果较差、分析不全面问题[17-18]. 针对上述问题,本文提出双路聚类建模方法(Two-way Clustering,TWC),该方法以细粒度数据为核心特征,对学生数据特征进行分类,对行为类数据特征和学术类数据特征进行双角度聚类建模,最终融合模型,对学习者的学习行为进行多方面分析,并对其进行分类.
1 数据来源
1.1 平台简介
本文的原始数据来源于某大学网络教育学院的在线平台. 该平台集机考平台、课程平台和论坛等于一体. 课程以录播的形式上传平台,学生在申请课程成功后即可开始学习. 学生在平台上的操作将会留下日志文件,如点播记录、论坛发言时间、学习时长等. 原始数据有视频观看、论坛讨论和在线作业三大类(表1).

表1 网络教育学院数据类型Table 1 The type of data of online education institute
1.2 数据采集
理解学习者与远程教育系统的交互行为这一点很重要. 心理研究表明,通过对行为的分析,可以区分人类动机、状态和目标等有效信息,为制定个性化课程和合理评价学习效果提供依据[19].
学习者的行为分析需要大量的数据支撑,如视频播放时长、论坛讨论情况等. 本文采集了2019-09-01—2020-01-01期间参与了《计算机基础》课程的10 853名学生的日志记录:10 853名学生的1 301 546条点播记录、315 269条讨论记录.
2 方法设计
通过对教育数据的挖掘,对学生群体进行聚类,能对学生进行个性化分析和指导. 结合学生属性特征,本文提出双路聚类建模方法(Two-way Clustering,TWC),方法框架如图1所示.

图1 TWC框架图
2.1 输入编码层
输入编码层主要对原始样本的特征进行数据清洗工作:首先,对属性特征进行数据预处理,如标准化、离散化和填充缺失值等;然后,基于预处理后的数据进行特征构建.
本文对数据集中的每一个样本都构建下述8个数据特征:视频点播次数(PlayCount)、视频观看总时长(PlayTime)、知识点个数(KCount)、参与讨论次数(DiscussCount)、讨论发言量(DiscussAmount)和3个细粒度特征(学习态度值(SAttitude)、知识点熵(KEntropy)和知识点合格率(KPassPercent)).
学习态度值表示学生参与课程的学习态度:
(1)
其中:mi为学生i的学习起始日期与学习结束日期之差,代表学习周期;m′i为学生i在学习周期内有效学习的天数,m′i/mi为学生i的学习密度;αi为学生i的学习时长与学生平均学习时长的商.
知识点熵代表学生在学习过程中的涉猎广度.信息熵常用来度量样本集合的纯度,熵越大,表示纯度越低. 标准化信息熵定义如下:
(2)
其中,D为样本集合,pk为样本集合中第k类样本所占的比例,|y|为类别总数.
假设学生i观看的视频中包含n个知识点,每个知识点上的学习时长分别为t1,t2,…,tn,则可得学生i的知识点熵为:
(3)
(4)
学生的知识点熵越小,表示该学生学习的知识广度越窄,在某个知识点上的学习时长要明显多于其他知识点. 知识点熵越大,则表示该学生学习的知识广度越宽,倾向于对所学习的知识点均匀发力.
知识点合格率用来反映学生在学习过程中对知识点的学习程度,合格率越高,表示学习程度越高. 其计算公式为
(5)
其中,Kcount为学习者学习了的知识点个数,Kcount′为学习者有效完成了的知识点个数. 在学习者的点播记录中,某个知识点的累计播放时长超过该知识点视频总时长的80%,则视为有效完成.
特征构建完毕后,数据集合中的每个学生被映射为一个8维的特征向量,最终得到10 853×8维的学生群体特征数据.
2.2 双路聚类层
聚类的目标是发现数据中自然形成的簇,发掘数据本身所蕴含的信息. 因此,输入的特征数据将对聚类产生决定性影响. 本文将8个特征再进行细分,与在线学习行为相关的视频点播次数、视频观看总时长、参与讨论次数、讨论发言量和学习态度值称为行为特征(Behavior Attributes,BA),与课程知识相关的知识点个数、知识点熵和知识点合格率称为学术特征(Academic Attributes,AA).
双路聚类层将分别从学习行为特征数据和学习学术特征数据2个角度进行聚类:基于不同数据类型的特征数据,构建特征矩阵并建立起不同角度的数据模型,更全面地刻画每一个学生的学习轮廓. 主要过程如下:
(1)构建特征矩阵. 一般地,假设学生i的属性特征集合为Mi,由一系列的属性特征attributesi={x1,x2,…,xn}组成,即Mi={attributesi}. 特征矩阵A为:

(6)
其中,i为各特征列的维度,n为属性特征的数目.
(2)双路聚类建模. 本文采用Kmeans聚类法对学生属性数据进行聚类建模,将建立好的行为数据特征矩阵和学术数据特征矩阵作为输入,结合簇内平方和误差(SSE)和手肘法来确定最佳聚类个数. 记i、j分别代表当前样本序号、当前簇序号,则簇内平方和误差定义如下:
(7)
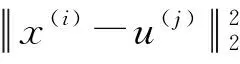
2.3 类别融合层
双路聚类层从行为特征和学术特征2个方面对学生样本进行聚类. 假定行为特征聚类产生的簇类别的集合L1={a1,a2,…,an},学术特征聚类产生的簇类别的集合L2={b1,b2,…,bm},将α、β作笛卡尔积,则矩阵L=L1×L2. 矩阵L中的每个元素即为融合类别,最终选取k个数目最多、最典型的类别作为输出结果.
3 实验结果与分析
3.1 对比实验
实验所使用的TWC算法采用Python编程实现,主要使用Scikit-Learn库来封装. 硬件执行环境配置为Intel(R)Core(TM)i5-8300H CPU@2.30 GHz处理器、16 GB内存.
在本文采集的数据集中,应用原始K-means算法[20]、K-means++算法[21]、新型聚类算法DPC[22]、RP-DPC算法[23]和本文提出的TWC算法,通过运行时间、簇内平方和误差、轮廓系数来比较5种算法的分类效果. 由实验结果(表2)可知: TWC算法的簇内平方和误差最小、轮廓系数最高,说明TWC算法有效地增强了簇的内聚性,使得聚类更精确;TWC算法的运行时间略高于K-means、K-means++、RP-DPC算法,究其原因为:虽然TWC算法在双路聚类时采用并行聚类,加快了运行速度,但该算法聚类前需要在数据编码层进行编码,这一步骤消耗了一定的时间.
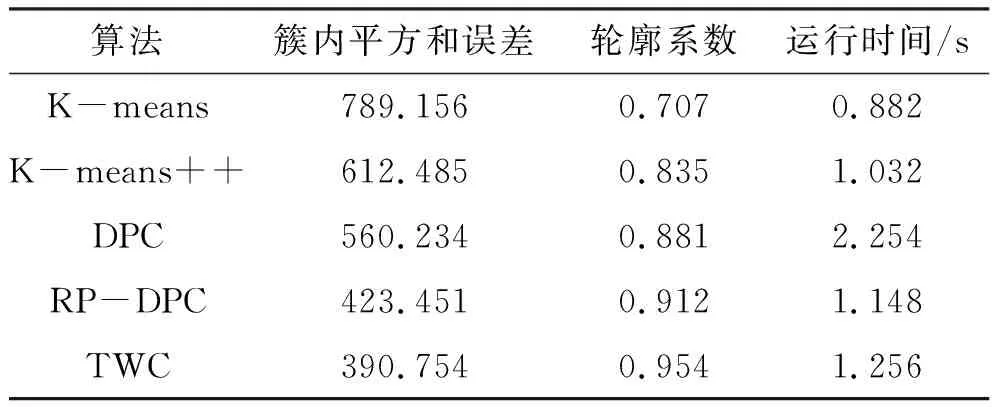
表2 5种算法在同一数据集上的性能指标对比
3.2 聚类结果与分析
TWC算法最终将10 853名学习者分为5种类别. 为进一步检验聚类效果,本文使用PCA降维算法来可视化聚类效果. 由结果(图2)可知:学习者被明显聚簇为5类.
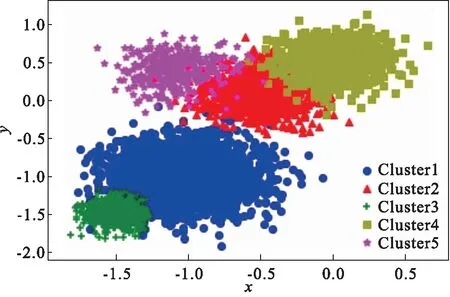
图2 聚类结果可视化
根据聚类结果,Cluster1、Cluster2、Cluster3、Cluster4、Cluster5分别包含4 724、2 355、1 752、1 412、610名学生. 为更好地展现不同类别学习者的区别,计算各类别学习者的统计特征(表3),如最小值(Min)、最大值(Max)、平均数(Mean).
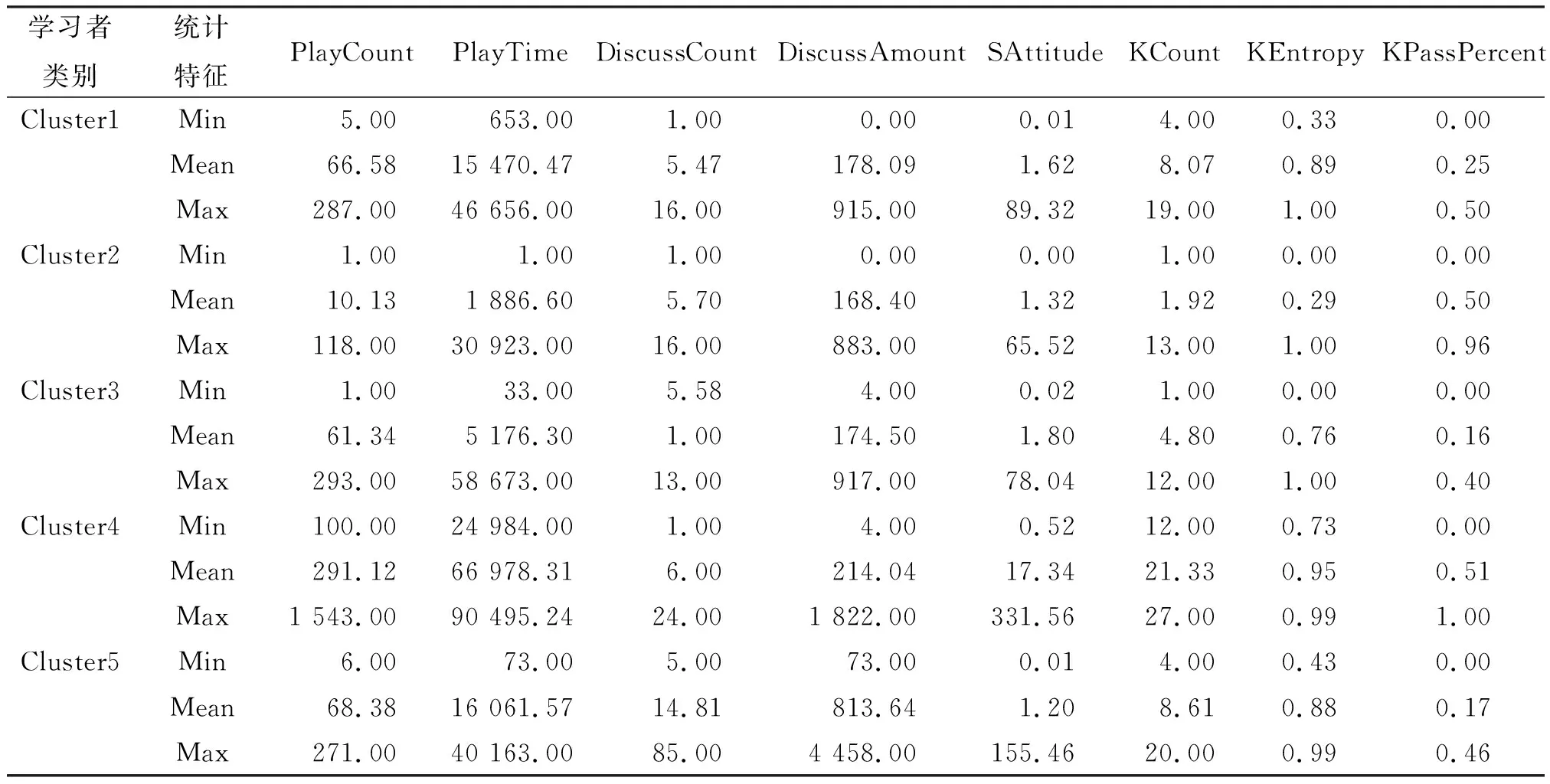
表3 各类别学习者统计特征概览Table 3 The overview of the statistical attributes of learners in different clusters
下面分析这5类学习者的行为:从学习态度方面来看,Cluster4的学习态度最好,学习态度均值高达17,远超其他4类. 相比之下,其他类别学习者的学习态度则较低迷,学习态度值都低于2. 从视频观看情况来看,Cluster4依旧处于突出位置,点播次数均值接近300次,播放时长均值在67 000 s左右,均为其他类别学习者的数倍至数十倍,表明Cluster4观看学习视频更频繁,同时也印证了Cluster4的学习态度最好. Cluster5在参与讨论方面表现很突出,远超其他类别学习者,说明Cluster5在课下很积极,经常利用论坛与同学和老师交流.
进一步分析各类别学习者在学术特征方面的表现:Cluster4学习的知识点最多,知识点熵最高且知识点合格率最高,说明Cluster4学习知识全面但有侧重点且学习效果不错;Cluster2学习的知识点并不多,但知识点合格率却仅次于Cluster4,表明Cluster2是有针对性地进行选择性学习,这类学生往往是有基础的学生;Cluster3的各项学术特征都处于低水平状态,表明学习状态急需调整;Cluster1学习的知识点多于Cluster3,但仍然处于不理想状态,合格率仅为25%,这代表Cluster1的学习有些片面且不够深入;Cluster5观看的课程数目多于Cluster1,但合格率仅为0.17,学习状态稍差于Cluster1.
由不同类别学习者在不同时间的注册比例(图3)可知:(1)Cluster2在刚开课时的注册比例高达60%,随后一个月内迅速下降到15%左右,在学期的中后期,注册比例又逐渐增加,这表明有基础的学生会在开课报名时更加积极,在课程快结束时再度掀起一波学习高潮. (2)Cluster1约占总学习者的一半,在开学后逐渐增加占比,最后稳定在50%左右. (3)Cluster3、Cluster4的曲线处于平稳且缓慢下降的状态,Cluster5的曲线则一直保持稳定的状态. (4)在12月20日后的阶段,Cluster1、Cluster2和Cluster4的曲线出现较大的震荡,这是因为这个阶段处于学期末,加入课程的学生比较少,数据有些微小的增减就会造成比较大的震荡.
由各类别学习者的结课比例分布(图4)可知:学期的中前期,各类型学习者的结课比例都处于宽幅震荡中(前期的结课总人数很少);11月24日后,Cluster4逐渐增加结课比例,说明越优秀的学习者的结课时间越晚,持续学习的时间越长;其余类型的学习者的结课比例大多从11月10日开始进入平稳递减的阶段.
总结分析结果,得到Cluster1、Cluster2、Cluster3、Cluster4、Cluster5的特点如下:
Cluster1:学习片面型. 此类学生学习的知识点较少,从而导致学习时长不足,学习态度值、知识点熵和知识点合格率等特征表现平平,且此类学习者数量众多,表明网络教育的水平还有较大的提升空间.
Cluster2:重点学习型. 此类学习者多为有基础的学生,在行为类的特征上与Cluster1类似,并不占优势,但应与Cluster1加以区分,因为Cluster2的学生都是有选择地去深入学习某些知识点.
Cluster3:打酱油型. 此类学生处于放弃学习的边缘,各项特征都是不良的状态,呈现消极怠慢的状态. 网络教育管理者应该充分调动此类学生的学习积极性.
Cluster4:全面学习型. 此类学生的特征显示学生的学习状态很优秀,知识点学习比较全面,持续学习时间长,也会区分重点知识,具有一定的主观能动性.
Cluster5:热衷讨论型. 此类学生积极参与论坛中的讨论,是活跃论坛的主力军,但学习情况并不如Cluster4全面,所以推测这类学习者的学习方法可能存在问题,需要教师及时纠正.
通过对5类典型学生的个性化分析并结合远程教育的优势,提出以下建议:
(1)远程在线学习的学习效果可以进一步提升,教师应更加关注学生的学习广度和深度,在学习平台的设计上可以适当减少一些灵活性. 例如,学习视频可以设计为不能拖动进度条的,但可以适当快进和快退.
(2)学生对学习平台中的论坛关注度很低,论坛的作用没有高效发挥,教师应积极引导学生提问,发挥学生的主观能动性,或者适当提高学科难度.
(3)对于学习优秀的学生可设立一个提高班,学习更符合他们自身水平的知识. 同时,学习平台可以增加一项“红绿灯”功能,对学生进行预警,当出现红灯时,就代表其学习状态已经低于同批次学生的平均水平. 这种学生内部竞争的方式或许比外部施压的方式更有效.
4 结论
为解决远程教育平台日志文件挖掘不充分和学习者画像刻画不深刻的问题,本文对10 853名学生的1 301 546条点播记录和315 269条讨论记录进行挖掘,力图从中发现学生的学习行为规律和特性,从而提升网络教育的授课水平. 基于日志记录,本文发掘多个细粒度特征,以此为基础提出了双路聚类建模方法,并对各类学习者进行详细的分析,刻画了5种典型的学习者画像. 研究结果表明:以细粒度特征为核心的双路聚类建模方法可有效地将不同类型的学习者进行细分,且时间复杂度较低,有利于在大数据集上应用.
下一步研究可关注如何更合理地评判学生的学习效果,而非只靠统计型数据;同时,个性化试题推荐将是一个研究重点;关于教师层面的数据挖掘,目前研究资料还比较少,通过教师与学生之间的互动,探索“教”与“学”之间的模式匹配问题也值得关注.
