炼钢合金减量化智能控制模型及其应用
2022-01-10郑瑞轩包燕平王仲亮
郑瑞轩,包燕平,王仲亮
北京科技大学钢铁冶金新技术国家重点实验室,北京 100083
钢铁行业是我国能源资源的消耗大户,在国家“碳达峰、碳中和”的目标下,如何实现企业的能源和资源的高效利用,减少生产过程碳排放和能源消耗,是钢铁企业亟需解决的关键问题[1-2].铁合金是钢铁冶炼过程中必不可少的原辅料之一,主要作用是钢液的脱氧和合金化. 据统计我国铁合金年产能约为 5800万吨,其中钢铁生产用合金消耗超过3000万吨. 然而,铁合金的生产是高耗能过程,烟尘、废渣和废水等污染排放严重,大多数铁合金生产能耗大于4000 kW·h·t-1,电解铝能耗高达1.33 kW·h·t-1,每年我国铁合金生产能耗不低于2320亿kW·h,折合2850万吨标准煤. 若钢铁企业能够实现炼钢过程的合金减量化控制,则可以有效减少能源消耗,为国家“双碳”目标助力.
铁合金是炼钢的主要原料之一,其成本占到炼钢生产成本的5%~10%[3]. 几乎所有的钢种,都需要通过铁合金进行脱氧和合金化以获得特定的化学成分并产生所需的机械性能[4]. 目前炼钢用铁合金种类繁多且价格各异,若炼钢时铁合金种类选择不当,不但会使炼钢生产成本增加,而且会产生质量问题. 因此,如何更智能地选择铁合金种类和确定最佳合金加入量是非常重要的. 传统的铁合金加料模式是钢厂技术人员主要凭经验确定合金种类、操作人员凭经验确定合金加入量,这样的操作模式一般把铁合金的收得率设定为一个固定值,不随钢液参数的变化而调整,往往导致合金加入量偏高,钢液成分不稳定,提高了炼钢成本的同时也造成钢液质量的波动. 因此,炼钢厂迫切需要一种科学且实用的铁合金加料模式与手段,目前已有部分研究者进行了相关的研究[5-13],这些研究有的已经取得的一定的突破,但大多还是停留在理论研究阶段,与现场实际生产联系不够紧密.
本文基于国内某炼钢厂工艺特点,对合金减量化工艺展开研究,建立了合金减量化智能控制模型,旨在提升钢铁企业现场的智能化水平,降低铁合金消耗,在给企业带来经济效益的同时减少能源消耗,助力“碳达峰、碳中和”目标. 受市场影响,目前铁合金价格变化较大,炼钢合金成本控制难度增加,该模型可在满足钢液成分达标的前提下,使合金加入成本大幅度降低,并实现钢液合金成分的窄区间控制,提高钢产品性能的稳定性.
1 基于 K 均值聚类的合金耗量数据分析
在实际生产过程的合金化操作中,合金物料在加入到钢液之后会有部分损失,使其不能够完全被钢液吸收,这些合金损耗主要受冶炼工艺条件的影响,包括钢液的状态参数如钢液氧含量、温度、钢渣的状态和加合金过程的钢液状态. 合金减量化研究重点之一就是找出合金损耗的关键影响因素,从这方面着手减少合金在使用过程中的损耗、提高合金的收得率[14-15].
本文首先利用SPSS软件对出钢温度、冶炼周期、吹氧时间、吹氧量、铁水和废钢装入量、TSO氧含量、TSO碳含量等炼钢工艺参数与合金耗量进行相关性分析,得到影响合金耗量的关键因子后,根据关键因子的范围对合金耗量进行分类分级. 传统的分类方式为有监督过程,即存在有先验知识的训练数据集,需根据已有经验划分区间后排列组合,分组数量大且不能完全提取数字特征.聚类是一种无监督的学习方式,它可将具有较高相似度的数据对象划分至同一类簇,且簇内的对象越相似,聚类的效果越好,适合于数据量大的冶金工业分析. 这里采用的K均值聚类算法(K-means clustering algorithm)是一种迭代求解的聚类分析算法[16],其步骤是首先随机选取K个对象作为初始的聚类中心,然后计算每个对象与各聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心. 每分配一个样本,K均值聚类的聚类中心会根据现有的对象被重新计算. 通过迭代计算最小误差平方和,得到具有不同特征的K组数据. 这样对K组合金耗量数据进行统计,可以发现合金收得率与关键因子的相关关系. 如图1(b)中,3.69±0.032c、3.94±0.038a和 3.94±0.043b,其中 0.032、0.038、0.043为数值误差限,a、b、c为差异显著性分析结果标注,字母不同表示存在显著性差异,字母相同表示差异不显著. 本文中吨钢耗量在对工艺参数的K均值聚类间差异性显著,说明与氧耗量、废钢比和终点温度等具有较强的相关关系.
以某120 t转炉炼钢厂为研究对象,选取140炉次42CrMo钢种炉次进行相关性分析,得出影响合金收得率的主要因素为吨钢耗氧量、装料铁水比和出钢温度,采用基于K均值聚类归纳法对锰元素收得率进行研究,将数据分为3个聚类,如图1(a)所示. 对出钢阶段锰元素收得率分类统计,如表1所示,锰元素收得率均值为87.31%,1类收得率高于均值1.15%,2类收得率低于均值0.75%.在所选取的140炉次中,分类1炉次共33炉,占比23.57%,分类2炉次共29炉,占比20.71%. 在收得率高于均值的1类中出钢温度低,装料铁水比高,吨钢耗氧量略高于其他两类,而收得率低于均值的2类情况与之相反. 在吨钢铁合金耗量上如图1(b)和1(c)所示,聚类1在硅锰和中碳锰铁吨钢耗量上均低于均值,分别低2.64%和2.15%,而聚类2在这两类锰系合金吨钢耗量上分别高于均值3.96%和2.80%.
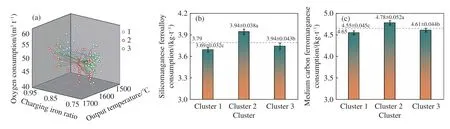
图1 42CrMo转炉出钢工序工艺参数聚类分布图(3个聚类)(a)及吨钢硅锰耗量(b)和吨钢中碳锰铁耗量(c)Fig.1 Cluster distribution map of process parameters in the 42CrMo converter steel discharge process (3 clusters) (a), silicomanganese consumption per ton of steel (b), and medium carbon ferromanganese consumption per ton of steel (c)

表1 3聚类炉次占比及锰收得率Table 1 3 Clustering proportion and the manganese yield in each cluster
由此可见在不同的钢液条件下,尤其是钢液的耗氧量和温度不同时,铁合金元素的损耗存在明显差异. 若将吨钢耗氧量、装料铁水比和出钢温度控制在聚类1范围内,减少2类的炉次占比,可显著降低转炉出钢过程的铁合金损耗. 以上研究针对转炉出钢过程的合金化,对于LF精炼合金化笔者采用同样的方法进行了研究,其中LF精炼用于K均值聚类分析的输入参数包括LF取一样温度、电耗以及C含量. 利用该方法将具有不同特征的关键因子自动划分为K类,从而在计算合金加入量时可以根据实际钢液条件选择不同收得率,避免了采用单一收得率按照控制上限加入合金造成的浪费,也为后续合金减量化模型提供了依据.
2 合金减量化模型
2.1 模型功能与框架结构
运用Matlab R2020a Appdesigner程序设计编制了合金减量化智能控制系统的人机交互界面,模型计算流程如图2所示. 模型主要功能和框架结构如下:
(1)合金信息数据库.
运用Oracle 11g软件建立合金信息数据库,数据库与模型连接,模型在运行过程中可以实时调用数据库内的数据用于模型计算使用. 数据库信息从企业各级数据库中获取,包括但不限于合金化验成分、钢液取样化验成分、生产工艺参数和钢种目标内控成分等.
(2)实时在线的输入与输出模式.
模型可以实现实时的参数获取与数据输出,模型启动后,根据合金批号更新铁合金的成分信息及价格信息,然后模型根据所读取的炉号在数据库中读取出该炉次所对应的钢种与执行标准,并获取该炉次的钢液基本信息,最后根据钢种和执行标准调取工艺卡以设定合金化后目标钢液成分.
(3)智能化的合金使用效果评价与分析系统.
模型包括基于K均值聚类的合金耗量数据分析和基于主成分分析法的BP神经网络收得率预测模型,已结束炉次的生产数据会输出到数据库,经过使用效果评价之后传输到收得率预测模型中,实现预测模型的自学习,不断完善收得率预测模型精度.
(4)基于智能分析结果的合金种类选择与加入量计算模型.
模型基于历史数据的智能分析结果,选取成本最低的合金加入种类,根据已有条件利用intlinprog函数计算出符合钢液目标成分设定值,且总加入成本最低的铁合金加入量. 该模型对于转炉炉后的合金化和LF精炼的合金化均适用,转炉炉后合金化模型仅进行一次配料计算,钢液目标成分一般设定为略低于钢种内控成分的下限值,具体数值管理者根据钢种实际情况进行设定. 在LF精炼工序模型计算流程与转炉工艺类似,将LF精炼合金化前钢液化验成分与钢种内控值进行对比,若符合成分要求则该炉次合金配料完成,否则返回到上一步重新进行配料计算与加料操作,直到成分达标为止,一般LF精炼工序进行1~2次加料.
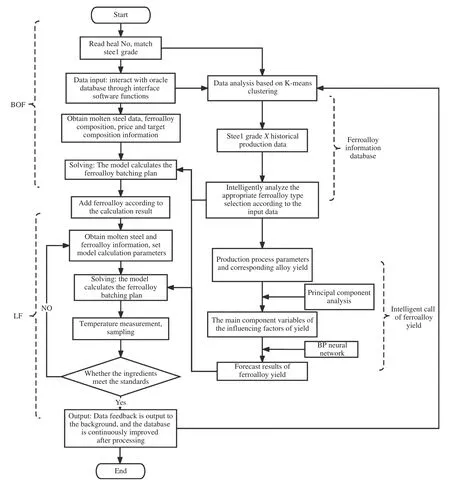
图2 模型计算流程图Fig.2 Model calculation flowchart
2.2 界面设计
在模型进行配料计算前,需要获取当前炉次所炼钢种内控目标成分、钢液信息、合金信息等,这些数据都是通过企业Oracle数据库与模型进行交互调用的,可在生产过程中实时获取. 同时,模型会将所读取数据显示在模型主界面并且用于后续的合金配料计算,合金减量化智能控制模型主界面如图3所示. 模型数据显示主要由以下几部分组成:工艺基本参数模块、合金信息模块、合金种类选择模块、合金收得率预测模块、钢液化验成分模块、加入量计算结果模块.

图3 合金减量化智能控制模型主界面Fig.3 Main interface of the intelligent control steelmaking ferroalloy reduction model
2.3 模型计算方法
模型在物料平衡计算的基础上,采用线性规划作为核心算法[17-23],包括决策变量、目标函数、约束条件三部分构成,其中决策变量为模型最终的输出结果,为每种合金的加入量,目标函数为铁合金总加入成本最低原则,约束条件包括需要保证钢液合金元素含量满足品种标准需求,同时控制杂质元素含量小于含量标准最大值,从而计算出成本最低的合金加料方案.
(1)决策变量.
在合金化过程中,需要添加多种合金料对钢液成分进行调整. 总共提供n种合金料,每种合金加入量为x1,x2,···,xn. 且合金加入量必须满足以下非负条件:

式中:xi表示第i种合金加入量,kg;n表示合金种类总数.
(2)目标函数.
以合金加入总成本Z最低为目标函数,公式如下:
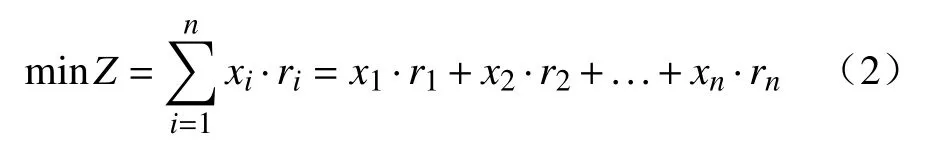
式中:ri表示第i种合金料的单价,¥·kg-1.
(3)约束条件.
为了获得最优的合金配料方案,需要对目标函数设置约束条件. 约束条件包括成分约束和用量约束,成分约束即按照模型计算所得的合金质量加入进钢液后,必须保证钢液化学成分含量满足钢种标准需求.

式中:P表示钢液总质量,kg;gj表示第j种元素含量目标值;kj表示第j种杂质元素含量目标值;bj表示第j种元素合金化前的含量;cij表示第i种合金中第j种元素的含量;ηj表示第j种元素的收得率;min表示下限值;max表示上限值.
用量约束即在实际生产过程中,合金用量通常有一定的最大限制:

式中:Li代表实际生产中第i种合金的最大加入量.
合金收得率是配料计算的重要参数,直接影响模型计算合金加入量及合金化后的钢液化学成分,准确的合金收得率能够提高钢液成分命中率[24]. 因此,本文采用基于主成分分析法(Principal component analysis,PCA)的BP神经网络对合金收得率进行预测[25-28],前文中已采用基于K均值的聚类分析法对合金收得率的影响因素进行了研究,将吨钢耗氧量、装料铁水比和出钢温度相关工艺参数作为BP神经网络的输入变量用于预测合金收得率. 由于变量间存在一定的相关性,故对其进行主成分分析处理,建立基于PCA-BP神经网络预测合金收得率并嵌入模型用户界面,神经网络建立流程如图4,网络结构如图5所示.
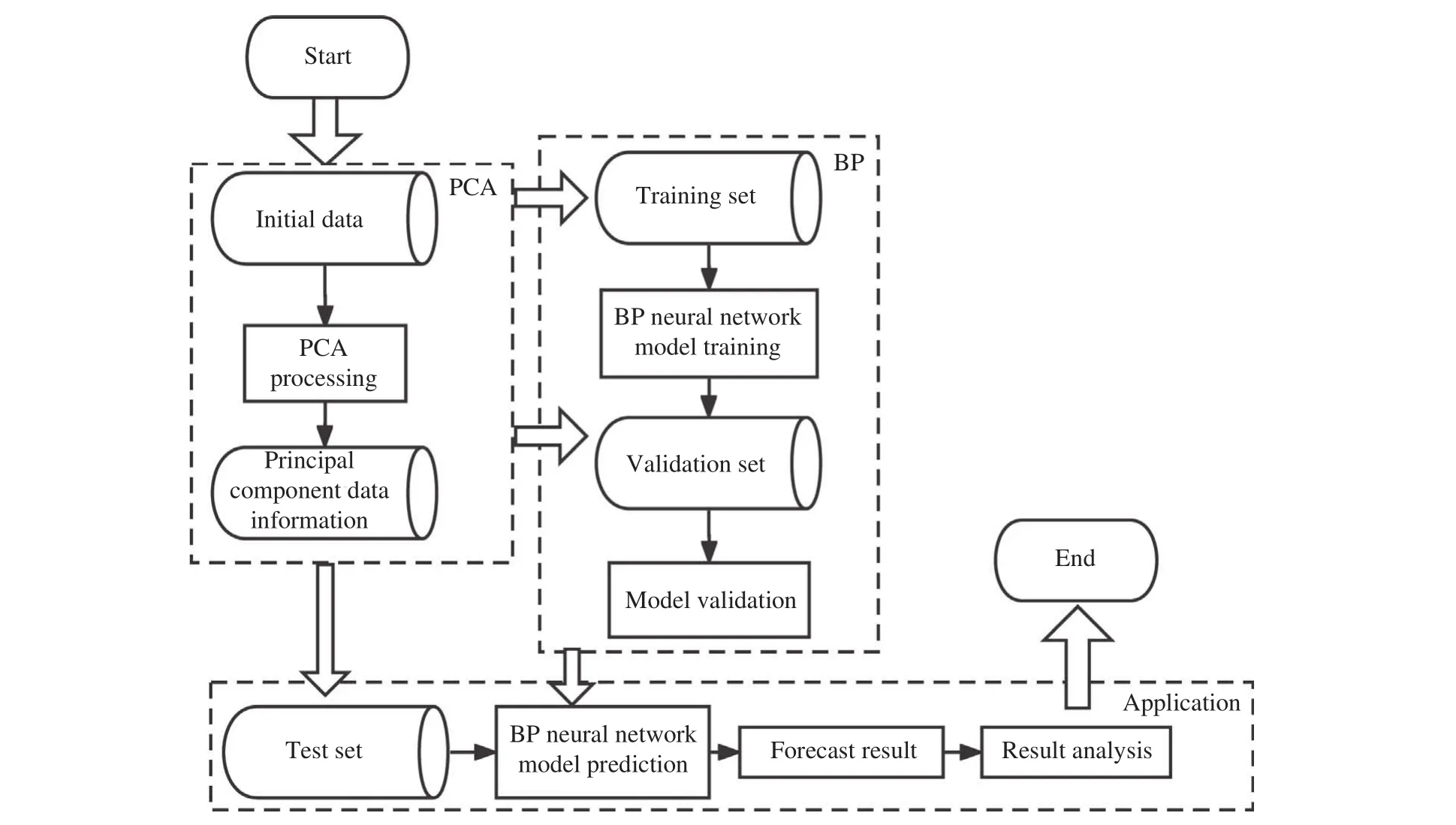
图4 合金收得率PCA-BP神经网络建立流程图Fig.4 Flowchart of the alloy element yield PCA-BP neural network

图5 PCA-BP神经网络结构图Fig.5 Structure diagram of the PCA-BP neural network
3 模型效果与应用
3.1 收得率预测准确度验证
为了验证基于K均值聚类分析和PCA-BP神经网络模型对收得率预测的准确度,以某钢厂500炉次42CrMo钢生产数据为数据样本,对锰元素收得率预测模型进行训练,并选取50炉数据作为验证集,验证模型预测精度. 模型预测误差频率分布如图6所示,其中部分预测结果如表2所示,可以看出同一座转炉生产的相同钢种,在不同炉次的钢液状态下合金收得率各不相同,若在合金配料时按照固定的收得率进行计算,将会使得合金加入量计算值与实际需求的用量差值较大,不利于合金配料的准确性和命中率.
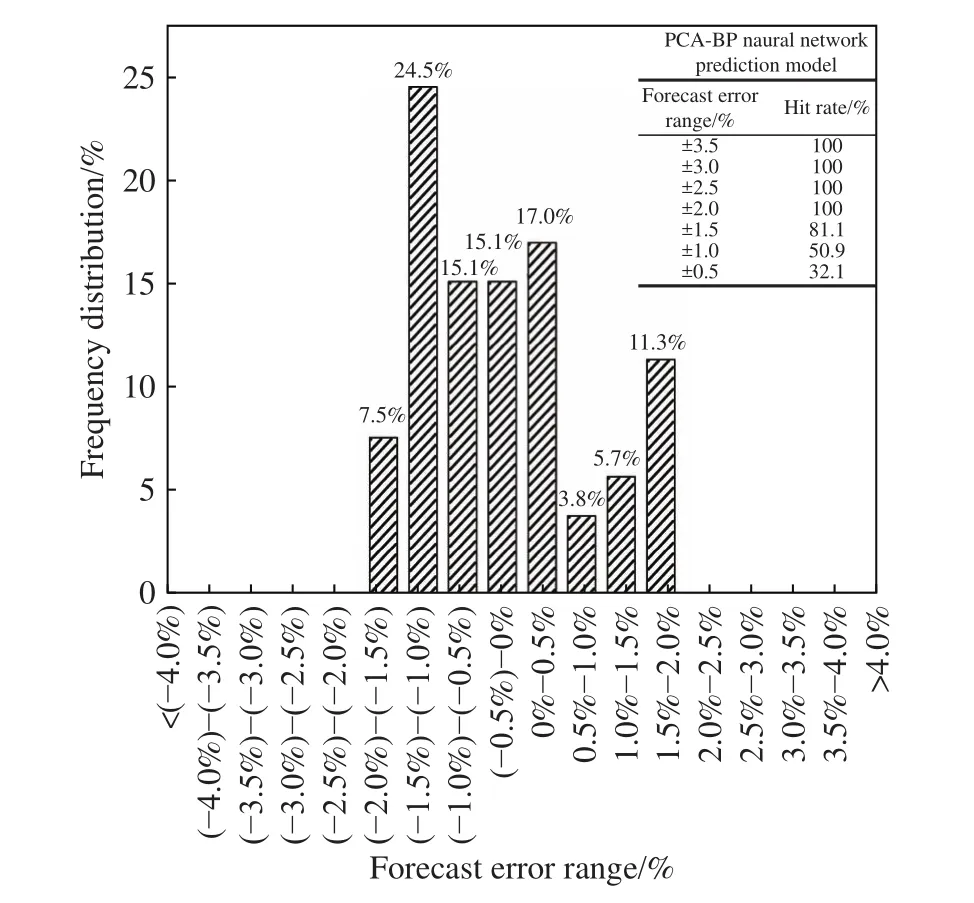
图6 合金收得率预测误差频率分布Fig.6 Frequency distribution of the alloy yield prediction error
对收得率预测模型的预报误差范围及命中率进行分析,如图6所示. 可以发现预测误差主要分布在±2%之内,预测误差在±2.0%以内的命中率为100%;预测误差在±1.5%以内的命中率为81.1%;预测误差在±1.0%以内的命中率为50.9%;预测误差在±0.5%以内的命中率为32.1%,预测结果较准确,能满足实际生产的要求.
3.2 合金化成本优化对比
为了验证模型对炼钢用铁合金的降本效果,运用模型进行模拟计算,研究不同钢种的实际合金成本与优化成本. 本文选取某炼钢厂11种钢种共35个炉次的合金加料数据为样本进行对比分析,合金加入总成本统计结果如图7所示.

表2 合金收得率预测结果和实际收得率对比Table 2 Comparison of the actual alloy yield and the forecast alloy yield
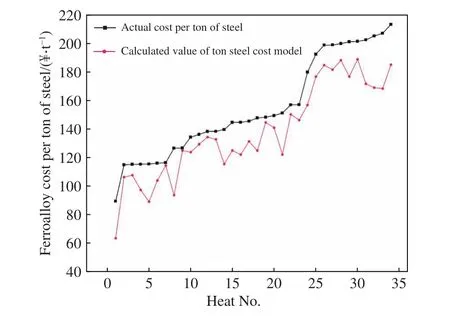
图7 模型计算成本与实际成本对比Fig.7 Comparison of the model calculation alloy cost and the actual alloy cost
从图可以看出,在统计的35炉数据中,所有炉次的模型计算合金配料方案吨钢成本均低于实际值,不同钢种吨钢合金降本2.5%~29%,平均吨钢合金成本降低11.06%,成本降低最多的炉次为38.7 ¥·t-1. 对于像轴承钢和高合金钢之类,合金加入量大且合金加入种类多的钢种,合金计算降本效果更显著. 以42CrMo钢为例,模型计算结果降本 684~2609 ¥·炉-1,吨钢降本 5.7~21.7 元,合金化成本降低6.0%~11.85%.
3.3 模型应用案例
将合金减量化智能控制模型应用于某钢厂转炉厂1#转炉在线运行,应用模型指导现场合金配料. 模型在线运行期间共指导生产115炉,其中42CrMo钢的部分工业应用实验结果如表3所示,结果表明试验炉次钢包取样的钢液成分均符合要求. 通过基于K均值聚类的合金耗量数据分析,优化控制吨钢耗氧量、装料铁水比和出钢温度等工艺参数,显著降低了转炉出钢过程铁合金的损耗,提高了收得率,实验炉次较历史对照炉次Mn收得率提高3.22%~5.29%,平均提高3.54%. 同时结合模型计算优化合金配料方案实现整体合金加入成本的降低,对实验炉次的合金降本效果进行追踪,实验炉次较历史对照炉次铁合金加入总成本降低5.95%~14.74%,平均降幅11.72%,综合降本效果明显.
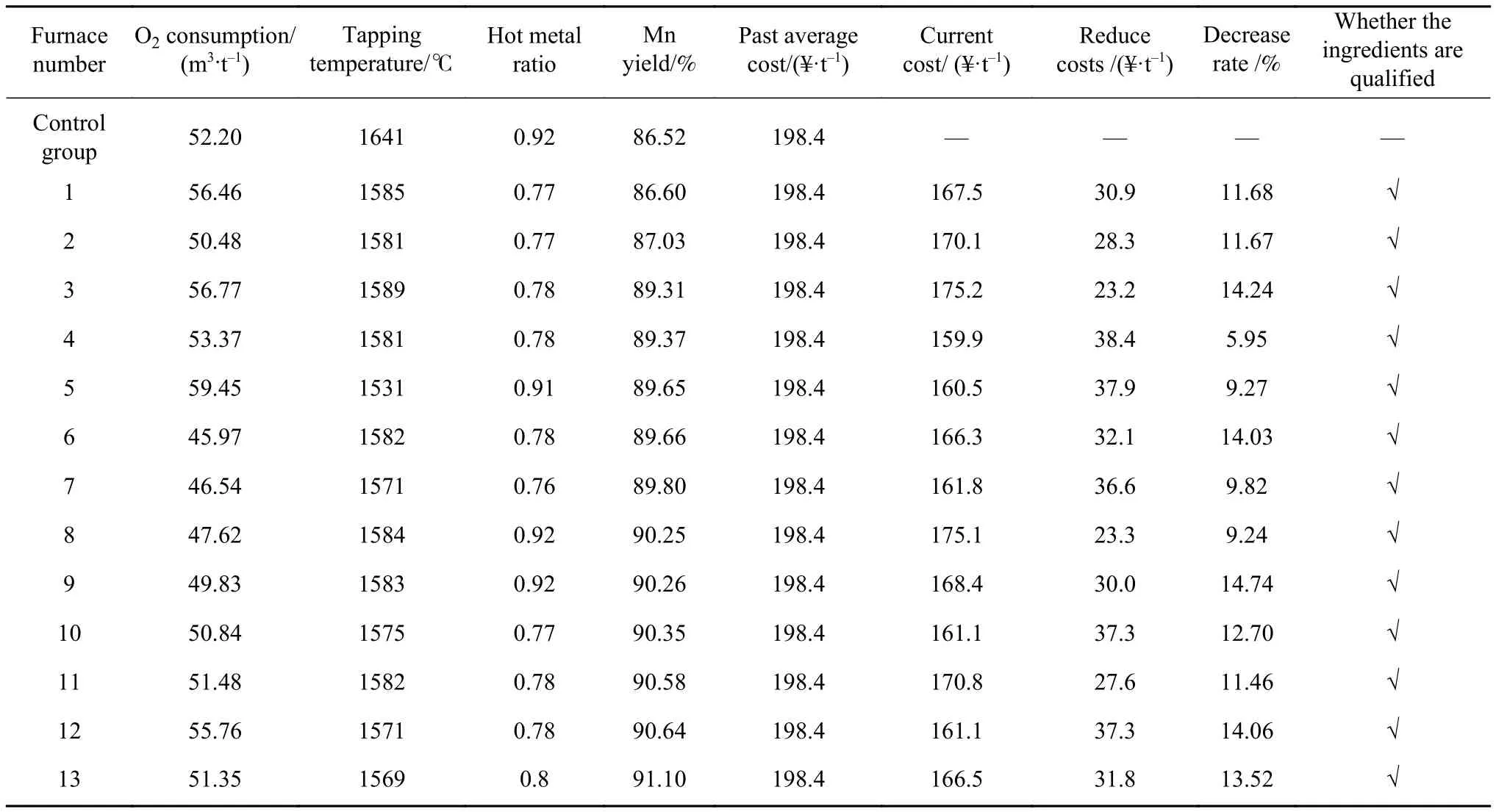
表3 工业试验结果Table 3 Results of the industrial test
合金减量化智能控制模型在现场使用的一段时间里,模型运行稳定,各工序数据传输顺畅,生产炉次均满足成分需要,未发生成分超标或成分不合的情况,生产炉次与历史数据相比,降本效果较明显. 结果表明,该模型适用于炼钢生产现场复杂的工况条件,能够符合现场的生产要求,具有一定的推广应用价值.
4 结论
(1) 基于K均值聚类法对转炉出钢过程合金损耗的影响因素进行分析,将选取的140炉次42CrMo钢按吨钢耗氧量、装料铁水比和出钢温度聚为3类. 利用聚类方法减少分组数量,有效提取数字特征,在出钢温度低,装料铁水比高的1类中锰收得率高于均值1.15%,条件相反的2类中锰收得率低于均值0.75%. 控制冶炼工艺过程在合金收得率高的范围内进行,有利于减少合金的消耗,降低炼钢生产成本,实现降本增效.
(2) 建立了基于PCA-BP神经网络和混合整数线性规划的合金减量化智能控制系统,并采用Matlab软件编制用户界面,模型实时准确地获取当前冶炼炉次的合金收得率,利用intlinprog函数线性规划求解得出合金加入成本最低的加料方案,提高了合金化钢液成分准确度,减少由传统人工经验计算配料造成的成本浪费和成分超标的情况发生.
(3) 合金减量化智能控制模型在现场工业生产测试中运行稳定,模型与企业检化验系统等数据库互联互通,能够实现数据的实时查询与调用. 应用模型指导合金配料降本效果明显,不同钢种吨钢合金降本2.5%~29%. 在模型工业在线应用试验中,试验炉次较历史炉次铁合金加入总成本降低5.95%~14.74%,平均降幅11.72%,综合降本效果明显.
