一种融合上下文信息特征的改进MTCNN人脸检测算法
2022-01-10顾梅花
顾梅花,冯 婧,杨 娜
(西安工程大学 电子信息学院,陕西 西安 710048)
0 引 言
人脸检测的目的是框定输入图像中所有人脸的具体位置,是人脸验证、人脸识别、表情识别、人机交互和人脸追踪等重要任务的前置环节[1-3]。然而,在课堂场景下,人脸检测仍面临诸多考验,如人脸遮挡、光照变化、图像分辨率低和人脸姿态多样性等问题[4-6]。因此,在课堂场景下如何增强人脸检测算法的鲁棒性和提升人脸检测算法的精度已成为当下研究热点。
早期的人脸检测算法主要以特征变换为主,例如:基于Harr-like的AdaBoost算法[7]、基于HOG特征的DPM算法[8],基于肤色模型的算法[9-11],基于范例的VPE算法[12]。近几年来,以卷积神经网络为主的人脸检测算法井喷而出,主要有CCF算法[13]、CascadeCNN算法[14]、MTCNN算法[15]、TinyFace算法[16]、SSH算法[17]、FaceBoxes算法[18]、PyramidBox算法[19]和SRN算法[20]等。
以上算法均能实现人脸检测,早期的人脸检测算法精度偏低,MTCNN算法因其兼顾人脸检测与人脸对齐任务、网络结构轻量精简、检测速度快且召回率高而得到广泛应用[21-25]。但另一方面,MTCNN算法对小人脸检测率较低,在课堂场景下,对教室后排的小人脸检测鲁棒性不高。针对MTCNN人脸检测算法在课堂场景下教室后排的小人脸检测率较低的问题,本文提出一种融合上下文信息特征的改进MTCNN算法。
1 改进MTCNN人脸检测算法
1.1 算法原理
MTCNN算法的卷积网络由3层网络构成,分别是P-Net、R-Net和O-Net层网络。其中,P-Net层网络主要生成大量人脸候选框;R-Net层网络的核心任务是对大量人脸候选框进行位置回归与优化筛选;O-Net层网络主要用来进一步优化人脸候选框位置以及生成人脸关键点位置。训练时,3层网络分别进行训练,互不干扰,当各层网络分别完成训练后,获得3个人脸检测器,将其输入至测试网络中,级联3个检测器实现对人脸框由粗到细的层层过滤。测试时,首先通过P-Net层网络生成大量人脸候选框,然后通过R-Net层网络对人脸候选框进行位置回归与优化筛选,最后由O-Net层网络生成最终的人脸框和人脸关键点。
改进的MTCNN人脸检测算法主要工作包括:①对R-Net层网络集成上下文信息卷积模块,通过扩大特征图的感受野来获取更多小人脸信息,以提升R-Net层网络对小人脸目标的检测鲁棒性,并通过引入反卷积层和最大池化层来解决特征融合时的数据维度不一致问题;②对O-Net层网络集成上下文信息卷积模块,进一步提升对小人脸的检测性能,同时添加2个卷积池化层使特征融合时输入特征维度一致。该算法的原理如图1所示。
图1中,上下文信息模块是一种特定的卷积结构,由于人脸框可利用卷积分类和回归得出,因此可采用扩大卷积核的方式来增加与相应卷积层步幅成比例的感受野,使网络捕捉到更多有效的小人脸特征信息。然后,将上下文信息模块提取的特征与原始网络所提取的特征进行融合,提升小人脸检测鲁棒性。
上下文信息卷积模块最初采用5×5卷积核与7×7卷积核并联构成,为了减少参数数量,使用2个3×3卷积核来替代1个5×5卷积核,使用3个3×3卷积核来替代1个7×7卷积核,具体如图2所示。
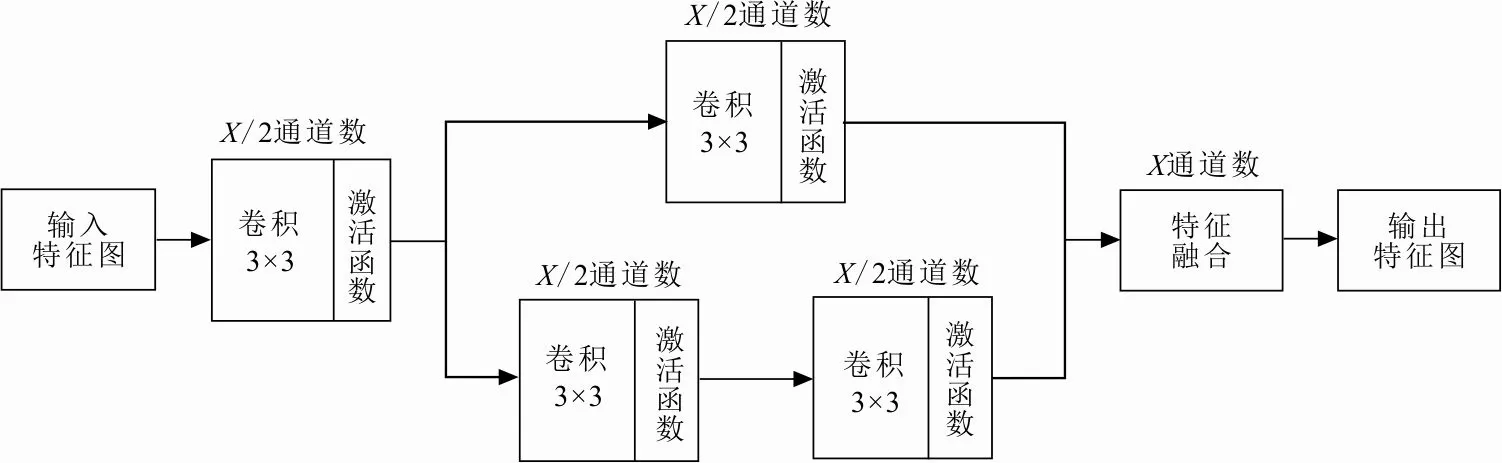
图 2 上下文信息卷积模块结构
1.2 改进R-Net层网络结构
为提升R-Net层网络对小人脸候选框的筛选、回归质量,采用集成上下文信息模块的方式对原始R-Net层网络进行改进,通过增加更多的上下文信息,扩大特征图的感受野,提升对小人脸的检测效果[16-17],改进后的R-Net层网络结构如图3所示。
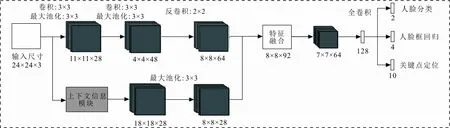
图 3 改进R-Net层网络结构
图3中,针对在R-Net层网络集成上下文信息卷积模块时产生的数据维度不一致问题,采用增加反卷积层和最大池化层的方式予以解决。其中,计算反卷积的步骤分为3步。
第1步,对输入原始图像进行相邻像素之间填充0像素变换,可表示为
is=i+(s-1)(i-1)
(1)
式中:i为输入图像尺寸;s为卷积核移动的步幅;is为相邻像素之间填充0像素变换的输出结果。
第2步,对式(1)的输出结果进行卷积计算,得:

(2)
第3步,利用式(3)求解反卷积输出尺寸。
(3)
由于在原始R-Net层网络中集成上下文信息卷积模块会导致输出的数据维度(18×18)大于原始卷积网络输出的数据维度(4×4),导致特征无法融合。因此,在原始卷积分支上增加反卷积核为4×4,移动步幅为2的反卷积层,同时,在上下文信息卷积模块分支上增加一个池化核为3×3,步幅为2的最大池化层,使输出数据维度统一为8×8,从而解决了特征融合时数据维度不一致问题。
1.3 改进O-Net层网络结构
为进一步提升O-Net层网络对小人脸候选框的回归、筛选能力,采用集成上下文信息卷积模块的方式对O-Net层网络进行改进,通过扩大O-Net层网络特征图的感受野,增加O-Net层网络提取的小人脸特征信息,并与原始网络分支进行特征融合,提升O-Net层网络对小人脸的检测能力,改进后的O-Net网络结构如图4所示。

图 4 改进O-Net层网络结构
图4中,为了解决特征融合数据维度不一致问题,引入卷积层和最大池化层。由于经过上下文信息卷积模块处理后,数据维度为42×42,而原始网络分支数据维度为8×8,导致特征无法融合。因此,采用3×3卷积层、3×3最大池化层、3×3卷积层和3×3最大池化层级联的方式,将上下文信息卷积模块分支网络输出的数据维度降低至8×8,从而解决了O-Net层网络特征融合时的数据维度不一致问题。
2 实验结果
2.1 FDDB数据集评价指标对比
为评估改进MTCNN人脸检测算法的性能,在FDDB人脸检测基准数据集上,将改进MTCNN算法与基于范例的VPE算法[12]、基于卷积神经网络的CCF算法[13]和CascadeCNN算法[14]以及原始MTCNN[15]算法进行定量实验评估。其中,FDDB数据集共有2 845张自然场景下的测试图像,包含5 171张人脸,检测难点在于存在小人脸、人脸遮挡、光照和表情变化。
采用FDDB数据集上的ROC曲线进行评估,该曲线下的面积越大,表示算法性能越好。绘制ROC曲线时,首先根据具体算法的预测结果对所有样本进行排序,然后按此顺序逐个作为人脸样本进行预测,根据式(4)和式(5)计算假正例率RFP和真正例率RTP,分别作为ROC曲线的横、纵坐标。
(4)
(5)
式中:TP为检测正确的人脸数目;FN为漏检的人脸数目;FP为将背景误检为人脸的数目;TN为正确检测背景,值为0。
FDDB数据集上5种算法的离散ROC曲线对比如图5所示。绘制离散曲线时,要求预测人脸框的IOU(intersection over union)值(表示预测人脸框与真实人脸框的重叠程度)大于0.5。
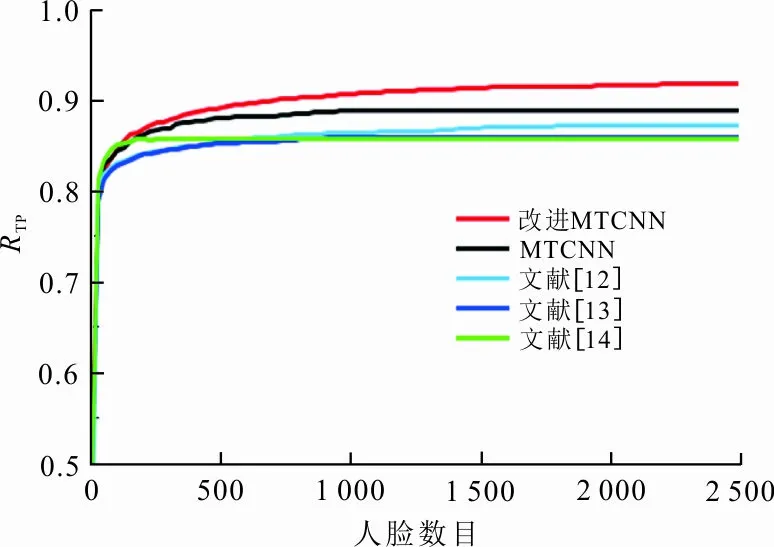
图 5 FDDB数据集上5种算法ROC曲线对比
从图5可以看出,当误检人脸框数目为2 500时,5种算法的检测精度趋于平稳。此时,改进MTCNN、MTCNN[15]、CascadeCNN[14]、CCF[13]和VPE[12]的检测精度分别为91.8%、85.6%、87.2%、85.9%和88.8%,可见,融合上下文信息特征能够有效提升MTCNN算法的检测精度。
2.2 课堂场景检测结果对比
为评估改进MTCNN算法在课堂场景下实际检测效果,制作相应人脸检测数据集,使用公开网络上大学生上课的6段视频,采用Python语言及OpenCV库将其逐帧解析成图像,共获得112张图像(共6 731张人脸),平均每张图像中可检测人脸数目为50,每张图像中的教室后排理论上可被检测的小人脸数目至少为5。
改进MTCNN算法与其他比较算法在复杂课堂场景下的检测效果如图6所示。

(a) 文献[12]
图6中共60人,其中15人被严重遮挡,不在检测范围内,理论上可检测人数为43人,其检测难点在于:①拍摄视角非正向导致绝大部分人脸为侧面;②光照不均,由于教室窗帘位置不同,大部分人脸曝光度低,小部分小人脸曝光度高;③学生密集,学生人数多且位置集中导致后排小人脸检测难度加大。图6(a)、(b)、(c)、(d)、(e)分别检测出25人、31人、33人、37人和43人,可以看出,5种算法均能正常检测位置靠前的人脸,漏检现象主要发生在后排小人脸区域。主要原因是后排小人脸分辨率较低,且存在遮挡、偏转和低头等问题。具体来说,CascadeCNN算法[14]基本无法检测出后排曝光度高、遮挡和偏转程度高的小人脸;CCF算法[13]、VPE算法[12]和MTCNN算法[15]检测效果相对较好,能够检测出部分存在一定程度遮挡和偏转的小人脸,但仍有6人因遮挡和偏转程度高被漏检;而改进MTCNN算法对上述曝光度高、遮挡和偏转程度高的小人脸检测率最高,对后排小人脸检测的鲁棒性明显强于其他比较算法。
为进一步定性说明改进MTCNN算法的鲁棒性和泛化能力,利用5种课堂场景图像(见该文首页OSID码的“本文开放的科学数据与内容”)进行相关实验,得到学生密集场景、正向视角场景、非正向视角场景、光照适度场景及复杂课堂场景下人脸检测结果,如表1所示。

表 1 不同课堂场景下人脸检测结果比较
从表1可以看出,针对不同的拍摄视角、光照条件以及学生人数,改进MTCNN算法正确检测的人数明显多于其他比较算法,表明改进MTCNN算法在不同的课堂场景下泛化能力更强,鲁棒性更好。
采用人脸检测召回率、准确率和F1分数对改进MTCNN算法在课堂场景数据集上进行定量评估。根据式(5)计算人脸检测召回率RTP,F1分数是基于准确率P和召回率RTP的调和平均值,可表征算法的综合性能,根据式(6)和式(7)进行计算。
(6)
P=Tp/(Tp+Fp)×100%
(7)
课堂场景数据集上算法的召回率、准确率和F1分数对比如表2所示。
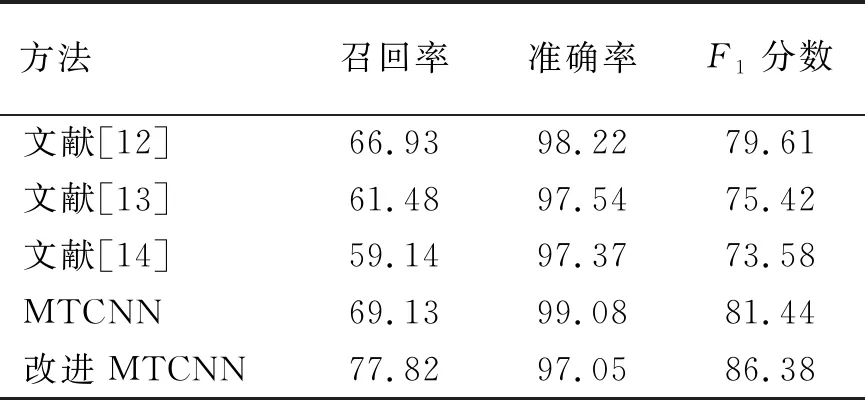
表 2 课堂场景数据集上算法性能比较
从表2可以看出,改进MTCNN算法准确率为97.05%,略低于其他比较算法,其召回率和F1分数分别为77.82%,86.38%,明显高于其他比较算法。结果表明:在课堂场景下,改进MTCNN算法的检测性能最好。
3 结 语
该文提出了一种融合上下文信息特征的改进MTCNN人脸检测算法,采用集成上下文信息卷积模块的方法,分别对MTCNN原始网络模型中的R-Net层网络和O-Net层网络进行了改进,能够有效提升MTCNN算法在课堂场景下的小人脸检测率,有助于后续人脸识别和表情识别等任务。经过实验对比,改进MTCNN算法在FDDB数据集上的检测精度更高,在课堂场景下,也具有明显的优势。在未来的研究中,将致力于提升改进MTCNN算法的检测速度,从而增加算法的可移植性。
