基于分块离散余弦变换感知哈希算法与ResNet模型的供电安全图像管理
2022-01-10曹增新朱龙辉
曹增新,蒋 程,朱龙辉
(1.国网北京房山供电公司,北京 102401;2.西安理工大学 电气工程学院,陕西 西安 710054)
0 引 言
电能是人类日常生活中必不可少的一部分[1-2],随着电力系统的不断更新完善,越来越多的设备加入其中,供电安全管控图像的处理也被提上日程[3-4]。图像分析常常被用来作为辅助管理的手段,在电力安全管控系统中也是如此,人们将各种设备以图像的形式记录下来,对其进行去重、分类等处理以便于进行后续的管理过程[5-6]。对于供电安全管控图像地处理,使用人工智能的方法进行图像整理,不仅可以大大降低人工操作的出错率,还可以节省人力资源。
在图像去重方面,许多学者进行了不断的探索,传统的图像去重方法多数属于文件级别,即将图像视为一个二进制文件,然后再利用传统哈希算法来实现去重,如块级数据去重算法[7-8],该方法图像会因压缩变换导致文件大小发生改变,此时文件级别的去重方法将无法正确对图像进行分辨,对感知相似的图像无法判别。为了追求更高的去重效率,文献[9]采取了图像均值PHA简称AVG-PHA,通过将图像转换为灰度图并压缩大小在像素域得到图像的哈希值,再借助汉明距离计算来判断2幅图像之间的哈希序列距离。这种方法较为简单,主要基于图像原本的各个像素信息,可以减少计算费用开销,但图像均值PHA无法对经过 JPEG压缩,对比度发生变化后的图像信息进行准确的判定。文献[10]首先提出了基于DCT的PHA,简称DCT-PHA,利用提取频域中特定系数产生的图像哈希作为信号去重判断,此后有学者对其方法进行了优化,并提出改进版高准确度感知哈希算法[11],该算法对相似图更加敏感,准确度更高。上面所列举的方法虽然能够实现图像分析分类,但是在稳健性、错判率及去重率等方面性能仍然不高。
在图像分类方面,深度学习模型常被用于图像的分类[12-14]。自动编码器就是一种由编码器和解码器组成的特殊的神经网络结构。其中,编码器将数据输入到隐藏层,通过隐藏层进行表达,而解码器可以通过隐藏层恢复输入的原始数据。这种独特的结构使得它在数据降维以及特征提取等方面都取得了不错的成就。CNN主要包括卷积层和池化层,可以很好保持图像的空间信息[15-17],但是网络的性能在前期会随着网络层数的增多继续提高,但当遇到一个阈值时,网络的性能会随着层数的增多逐渐降低,这是因为CNN模型出现了梯度消失的现象[18]。
针对上述图像处理方面存在的问题,本文将深度学习算法应用于图像处理技术中,通过深度学习算法实现供电安全管控图像的去重与分类,完成电力安全管控系统下智能管理子系统的设计。对于供电安全管控图像去重模块,采用本文提出的BDCT-PHA进行去重管理,该算法稳健性好,去重准确率高,且误判率小。对于供电安全管控图像分类模块,本文提出基于ResNet模型的CNN图像分类方法,该方法可以防止出现梯度消失现象,同时减少了计算量,提高了准确率。
1 BDCT-PHA的图像去重
哈希函数[19]可处理不同长度的原始数据,将其变为统一长度的消息摘要,通常用于数据加密以及数据压缩,但由于其存在脆弱性与数据压缩性的特点,逐渐被PHA[20]所取代。PHA是图像数据集到感知摘要集之间的一种单向映射,满足区分性、感知鲁棒性和单向性的特点。与传统哈希算法相比,PHA所生成的哈希序列值较短,因此它的数据所占用的容量不会很高;PHA很难通过输出的哈希值去追溯到输入,因此输入信息可以得到很好地保护;PHA序列的生成过程不容易被模仿,无法通过对输入图像进行修改来得到与另一幅不同图像相似的哈希序列值。PHA的生成过程通常被分为感知特征的提取和量化编码2个部分,其中感知特征的提取是整个步骤的灵魂。
1.1 BDCT-PHA的优势
从算法的稳健性、去重率、错判率3个方面,对BDCT-PHA和AVG-PHA、DCT-PHA进行比较,来说明BDCT-PHA的优势。
1) 算法的稳健性。汉明距离是判定PHA序列相似度的标准,汉明距离越大也就意味着2个序列越远相距。因此在将阈值设定为同一个值的情况下,2幅相似图像之间的汉明距离越大,识别的准确率越低,稳健性越弱。对失真图像的已有研究表明,BDCT-PHA较另外2种算法相比,在多数情况下,汉明距离的平均值较小,稳健性更好。
2) 算法的去重率。据已有研究显示,汉明距离的阈值取为1或5时,PHA对相似图像的正确识别率较高。在阈值为1时,BDCT-PHA去重的正确率能达到99%,高于DCT-PHA与AVG-PHA;在阈值为5时,BDCT-PHA去重的正确率将达到95%以上,而AVG-PHA与DCT-PHA去重的正确率则在90%以下。
3) 算法的错判率。PHA会严格区分不同源的图像,不同源的图像被识别为相似图像的情况被记为错判。已有研究表明,在有限大量数据的情况下,BDCT-PHA的错判率几乎为0,相较于其他2种算法有明显的优越性。
1.2 图像去重
BDCT-PHA会首先对图像进行预处理,对其做分块DCT变换并提取特征向量,得到感知哈希序列值,再使用汉明距离来描述2幅图像之间的距离,并设定阈值来对图像相似与否进行判别,具体操作如下:
步骤1:图像的预处理。首先,使用RGB转灰度公式Hgray(i,j)=0.299R(i,j)+0.587G(i,j)+0.114B(i,j)对彩色的图像在(i,j)处进行灰度化处理,以降低图像亮度对于分析的影响。最后,图像的大小将会影响生成的感知哈希序列长度,因此需要提前对图像的大小进行统一。本文采用双线性插值的方式对图像进行处理,分辨率统一设定为64×64。
步骤2:提取图像的特征向量。首先,对经过预处理的图像进行处理,将每个图像分为64个8×8的块,然后对其进行分块DCT变换,得到每个分块的DCT矩阵;其次,分别取每个块的DC分量,按照AC1和AC5分量将相同位置的分量连接起来,连接方式为从上到下,从左到右,连接完成后组成3个一维向量Am,长度为64;再次,对得到的3组向量分别用式(1)进行二值化处理,即
(1)
最后,将3个Fm向量依次连接,生成一维特征向量F,其长度为192,且表示了图像经过处理后的感知哈希序列值。
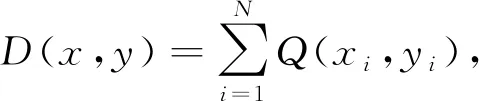
(2)
本文研究并判断2个字符串之间的相似性是通过它们的汉明距离。判断标准为:汉明距离越小,2个字符串差异性越小。对类似的字符串进行识别时,设置一个阈值T与所得汉明距离进行比较,当D(x,y)≤T时,两者被识别为相似的字符串,否则识别为不同的的字符串。对应感知哈希序列则是当D(x,y)≤T时,2个感知哈希序列代表的图像相似;当D(x,y)>T时,2个感知哈希序列所代表的图像不同。
2 ResNet模型
在达到CNN性能阈值前,不断增加CNN模型的深度会使模型的性能更好,但是当达到阈值后,不断增加CNN模型的深度,会出现梯度消失现象,而基于残差网络结构的ResNet模型可以防止梯度消失现象[21-22]。ResNet模型把残差网络引入到深度CNN之中,实现了“短路”机制,可以较好地解决“网络加深而准确率下降”的问题。
ResNet模型采用VGG的结构并在其基础上进行了修改,在增加ResNet模型非线性激活函数数量的同时减少了ResNet模型参数,这使得ResNet模型的计算量变得更小,即不是采用大卷积核的方法,而是用多个非常小的卷积核。ResNet可以使用2种残差单元,分别对应深层网络和浅层网络,两者均可在输入与输出维度一致时,直接将输入加到输出上。
2.1 超参数设置
在训练ResNet模型时,批量训练的大小、学习速率的大小、分类数目与权值衰减率的选择等都需要进行超参数的设置[23]。
1)批量训练大小的选择决定了ResNet模型下降的方向。当数据量较小的时候,为了对噪声数据产生鲁棒性,即减少噪声数据的干扰,批量训练值就应该较大。当数据量足够庞大时,为了减少计算量,应该适当减小批量训练的大小。ResNet模型在收敛精度和训练时间上存在一个最优取值,因为批量训练值按照经验存在一个全局最优值。
2)学习速率的大小与权值更新的幅度紧密相关,所以应该把学习率设置在一个适宜的范围。如果学习率设置过大,ResNet模型会在误差较小的一端来回摆动,形成一种已达到最优的错觉,因为其权值已经超过最优值,无法收敛到最优值。若学习率设置的过小,优化ResNet模型就需要大量时间,需要反复迭代,一步步靠近最优值,最不理想的情况下可能会导致ResNet模型无法收敛。
2.2 数据输入
样本数据的输入主要包括选择特征集、选取样本以及生成TFRecords样本数据集3个部分。
1) 选择特征集,选择的主要是待分类的图像。为使特征集的维度更大,模型收到的信息更全面,可以通过提取不同维度的特征来构成特征集。但是过高的图像数据特征维度,又会对ResNet模型产生不良的影响,特征维度也存在一个最优值。
2) 选取样本,选取样本点并提取样本点的M维特征,每个样本的特征是一个大小为M×N的矩阵。样本的数据量在现实运用中是远远满足不了ResNet模型的需求的,因此需要使用随机擦除与变换对比度的方式对原图像数据进行增强。
3)生成TFRecords样本数据集。按照比例将数据集拆分为训练集和测试集,并将其全部转换成二进制文件,再根据文件夹名称添加样本标签,转换得到的TFRecords文件作为ResNet模型数据输入。
2.3 ResNet模型卷积层
投影快捷方式用于在残差网络特征维度改变之前添加不同特征尺寸的特性。原始残差网络使用步幅为2的1×1卷积来改变通道的变化,如图1(a)所示。但1×1卷积会丢失大量的信息,所以如图1(b)所示,本文使用步幅为2的3×3最大池化层跟随步幅为1的1×1卷积层来代替原始的投影快捷方式。

(a) 原始投影快捷方式 (b) 改进投影快捷方式
改进的投影快捷方式的好处是在投影时将考虑来自特征映射的所有信息,并在下一步选择具有最高激活度的元素,以减少信息丢失。在通道流程方面,改进的投影快捷方式可以被视为软下采样和硬下采样的组合,这补充了2种方法的优势。硬采样有助于进行分类,而软采样有助于不丢失所有空间背景。同时这种改进不会增加模型的复杂度和模型参数量。
当前,大量研究结果表明方差为1的正态分布的白化操作可以使模型的收敛速度变得更快,即通过把输入数据拉伸为值为0的均值,将输入数据规范化和归一化。ResNet模型的每个输出层的输出结果都是下一场输入层的输入数据,因此,ResNet模型的白化操作,即为了克服模型训练时由于参数变化对模型梯度下降所产生的不良影响,需要对数据输出层增加规范化层,对每个节点的输入数据做归一化拉伸。批量归一化的主要目的是加快模型的收敛速度,避免梯度消失现象的出现,其计算公式可表示为
(3)
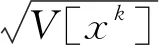
因为图像数据的特征具有稀疏性,即存在明显的线性可分性,所以为了模型能自动引入稀疏性且通过线性分段缓解梯度消失现象,在本模型中使用稀疏性激活函数ReLU。
2.4 ResNet模型训练
在对ResNet模型进行训练时,设计的目标函数可表示为
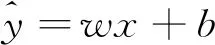
(4)
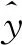
设计的损失函数为样本的真实类型与预测结果的交叉熵,可表示为
(5)
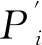
对于每批次样本,损失函数可表示为
(6)

对ResNet模型训练时,卷积层会进行特征提取工作,并把相应的参数值记录下来。在统计样本的分类值之前,会先将模型最底层提取的稀疏特征输入到Logist层。
3 仿真实验
本文的仿真实验的流程为载入数据集→完成数据集去重→将去重后的数据集输入待训练模型→完成模型训练→输出结果。其中,原始图像数据集为从现场收集到的关于开关柜、控制屏柜、刀闸等10类供电安全相关设备的图片集共300张。将数据集进行去重后,仍有254张图片。从中选取120张图片作为训练集,50张图片作为测试集。
3.1 图像去重验证
当汉明距离的阈值选取为1与5时,去重率较高,但在图像失真的情况下,阈值为5时的稳健性较好,故本文将汉明距离的阈值设定为5。
1) 选取要参与去重实验的文件。本文选择供电安全管控图像的文件夹来进行示范实验,32张图像的编码依次从00001到00032。
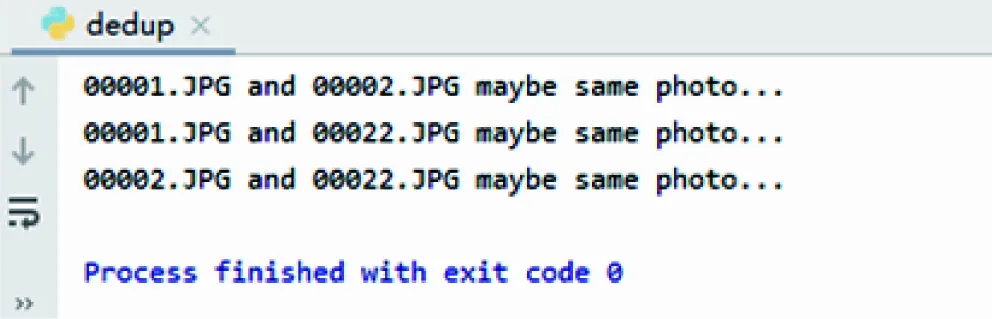
2) 存在1组相似图像的去重实验。对编号为00001到00022的22张供电安全管控图像进行去重操作,结果如图2(a)所示,可以显示出较为相似的一组图像的全部编号,对应编号图像如图3(a)所示。
3) 不存在相似图像的去重实验。对编号为00003到00021的19张供电安全管控图像进行去重操作,结果如图2(b)所示,不存在相似图像提示。
4) 存在2组相似图像的去重实验。对编号为00001与00032的32张供电安全管控图像进行去重操作,结果如图2(c)所示,显示出了2组相似图像的全部编号,并清晰地表明了与其相似的对象,对应编号图像如图3(b)所示。
(a) 存在1组相似图像的去重结果

(a) 第1组相似图像的相似图像
3.2 图像分类重验证
本文对供电安全管控图像进行如下处理,以实现图像的分类功能检验。
1) 打标签。使用labelImg工具为每张图像上的电力设备打上对应的标签,例如switchgear、monitor等。
2) 数据增强。通过水平翻转、旋转等方式将训练集数据增强至1 200张。
3) 转换格式。将数据集转化为VOC数据集的格式以便对其进行后续的训练。
4) 对数据集进行训练。本文通过损失函数来对图像分类的正确性进行表示。使用之前准备好的数据集进行训练,对过程中的各部分损失实现可视化,如图4所示。
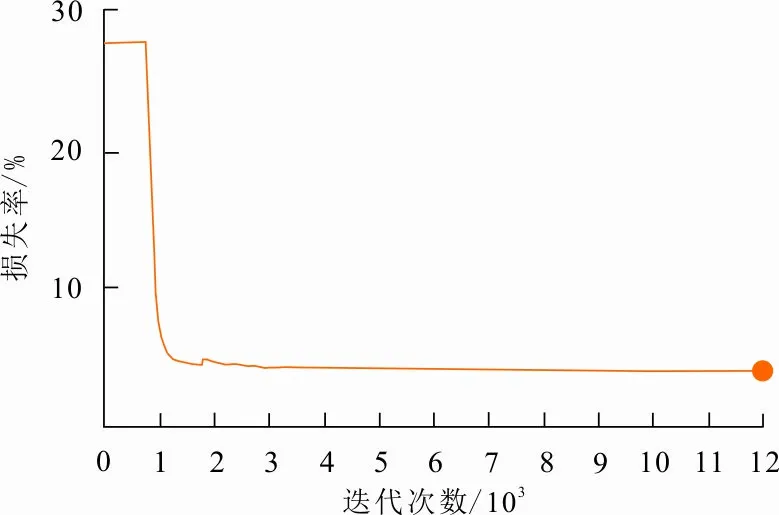
图 4 损失函数计算结果
从图4可以看出,损失在不断变小,最终收敛于一个较为稳定的范围内,即收敛于4.785%~4.894%,由此可以得出本次训练结果良好。
5) 进行对比实验。通过与densenet169[24]、vgg16[25]、mobilenetv2[26]以及原始Resnet进行准确率对比实验,实验结果如表1所示。
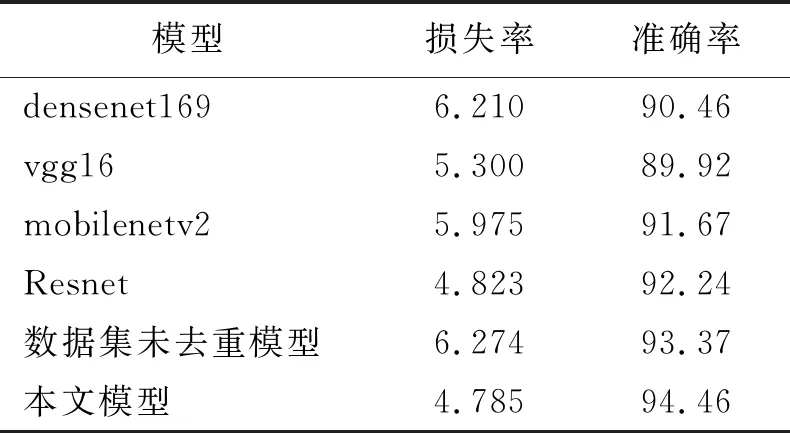
表 1 实验结果
从表1可以看出,在识别分类不同电气设备时,数据集去重操作在本实验中可有效降低模型的损失率和提升模型的准确率。
4 结 语
本文在PHA的基础上提出了一种BDCT-PHA,并采用改进的Resnet模型,最后实现电力安全管控图像的去重和分类。仿真实验表明:所提方法在有效地完成图片去重的同时可以列出被去重图片的编号,避免了重复或者过相似图片对系统管理影响;利用损失函数和分类准确率来对结果进行可视化描述,损失值不断降低并最终趋于一个相对稳定的区间,证明模型可有效被训练;分类准确率的对比结果证明所提方法具有良好的分类效果。
