基于多模型特征与精简注意力融合的图像分类①
2022-01-06宋东情朱定局
宋东情, 朱定局, 贺 超
(华南师范大学 计算机学院, 广州 510631)
图像分类是计算机视觉领域最基本的任务之一,其性能取决于算法和特征的选取.早期图像分类方法主要基于人工提取特征, 如使用SIFT[1]和HOG[2]等特征算子提取特征.后来学者们开始采用传统机器学习算法, 如随机森林[3], 支持向量机[4]等进行分类, 但分类性能仍有提升空间.
2012年, 随着AlexNet卷积神经网络[5]在图像分类领域的成功应用, 深度卷积神经网络(DCNN)引起了人们高度关注.DCNN的基本研究理念是开发先进的卷积神经网络架构以及相应的训练算法.随着DCNN的蓬勃发展, 各种视觉任务的精度得到了极大提升[6-8].其成功主要归功于深度架构和端到端的学习方法, 该方法能够自动学习输入图像在不同层次的内部特征,从而大幅度提高分类精度.为了提取更有效的特征进行识别, 近年来学者们不断提出先进的深度卷积网络架构和相应训练算法.
最近研究[9-11]表明加深网络深度和拓宽网络宽度能够提高卷积神经网络的性能.加深网络深度方面,He等[8]提出了一种152层的ResNet网络, 比VGGNet[9]深8倍, 在2015年的ILSVRC多项任务中都取得了最先进的性能.拓宽网络宽度方面, Zagoruyko等[12]提出的WRN网络减小了ResNet的深度, 增加了ResNet的宽度, 并取得了不错的性能.此外, 减小卷积核或池化的步幅[9,13]、提出新的非线性激活函数[14,15]、增加新的层数[10,16]以及有效的规则等都能够提高网络性能.本文在现有的卷积神经网络基础上, 通过结合不同的卷积神经网络特征层增加网络宽度, 学习互补特征, 提取更准确的图像表示进行识别.
原始输入图像往往包含许多无关的背景干扰信息, 从而干扰分类决策.图像分类任务中的小物体目标往往只占图像的一小部分, 准确识别这小部分特征对分类决策来说至关重要.本文引入注意力机制, 在进行图像特征提取时能够让网络自动选择需要关注的区域, 在网络学习过程中, 能够更关注图像的关键目标区域, 对模型提取的特征进行选择, 以获取更有效的信息.
基于以上, 本文提出一种多模型特征和注意力模块融合的图像分类算法(image classification algorithm based on Multi-model Feature and Reduced Attention fusion, MFRA), 通过多模型特征融合, 让网络学习图像的不同特征, 增加特征互补性, 增强网络特征提取能力.并引入了注意力机制, 使网络更关注目标区域.在几大公开数据集上进行了试验对比, 验证了本文算法的有效性.
1 本文算法
在提高特征表达能力及提取显著性特征方面, 目前的主流分类算法仍有上升空间.基于迁移学习技术, 本文提出MFRA算法.本文网络架构如图1所示,不同网络架构能够学习到不同图像特征, 为了提高特征互补性, 本文使用Inception-v3[17]和MobileNet[18]网络作为特征提取器, 输入图像分别经过Inception-v3网络的mixed9特征层和MobileNet网络的conv_pw_12_relu特征层, 并在提取高层语义特征后嵌入注意力模块,可使网络将注意力放在重要特征上, 降低背景信息.并在算法最后添加一个全连接层进行图像分类.
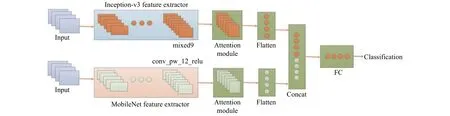
图1 基于多模型特征与注意力模块融合的网络结构
1.1 迁移学习与目标模型
为节约训练时间与资源, 本文使用在ImageNet数据集上预先训练好的Inception-v3和MobileNet网络,并在目标数据集上进行微调.迁移学习与构建新的网络结构相比, 能够取得更好的效果.
Inception-v3网络在包含1000个不同类别的被认为是计算机视觉分类任务基准数据集的ImageNet上进行训练, Inception-v3网络结构如图2所示, 由图2可知, Inception-v3网络内部集成了多个不同尺度大小的卷积核, 能够学习到不同尺度的特征.Inception-v3还通过将一个大卷积分解为几个小卷积, 以及将空间分解为非对称的卷积等操作减少网络参数, 从而节省计算开销, 加快网络训练速度.在ImageNet数据集上,Inception-v3达到了目前较高的分类性能, 错误率仅为17.3%.

图2 Inception-v3网络结构
MobileNet网络是针对手机等移动嵌入式设备提出的轻量级深层神经网络模型, 其核心是采用可分解的深度可分离卷积, MobileNet网络结构如图3所示.由图3可知, MobileNet网络架构由正常卷积和深度可分离卷积交叉组成, 深度可分离卷积是对常规卷积做出小规模调整, 对于来自上一层的多通道特征图, 将其全部拆分为单通道特征图, 分别对其进行单通道卷积后重新堆叠.深度可分离卷积可以降低模型计算复杂度, 并降低模型体积.

图3 MobileNet网络结构
1.2 精简注意力机制
在计算机视觉领域, 研究者们围绕着注意力机制的本质提出了许多注意力机制变体.Hu等[19]提出的通道注意SE块采用两个全连接层结构, 从而获取各通道的重要性权重.Woo等[20]提出的卷积注意力模块(CBAM)采用通道和空间注意力串行的方式, 对于通道注意模块,特征向量分别经过最大池化和全局平均池化进入权值共享的网络, 空间子模块同样利用最大池化和全局平均池化的输出, 沿通道轴汇集到卷积层.Park等[21]将通道和空间注意力结果相加形成瓶颈注意模块.为了在尽可能少增加网络参数的情况下提高网络的特征提取能力, MFRA算法简化了注意力机制结构, 只保留最本质的注意力结构, 因为本文提出的注意力机制结构简单, 因此称之为精简注意力.本文提出的精简注意力结构如图4所示.
由图4可知, 精简注意力由通道注意力和空间注意力串行组成.特征提取器提取的特征向量先输入通道注意模块, 根据各通道的重要程度得到通道权重矩阵, 然后将通道权重矩阵输入空间注意模块, 根据特征图的重要区域得到空间权重矩阵.网络通过嵌入精简注意力模块, 可以使网络更关注有意义的特征.具体过程可表示为:
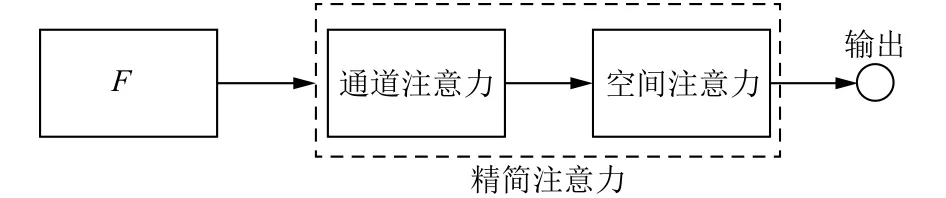
图4 本文精简注意力机制网络结构

其中,F为输入特征,Wa和Wb分别为空间注意特征权重矩阵和通道注意特征权重矩阵,Fa和Fb分别为空间注意特征矩阵和通道注意特征矩阵, σ为 S igmoid激活函数, ⊗为矩阵相乘操作,out为输入特征经过精简注意力后的输出特征.
1.3 通道注意力
输入图像经过Inception-v3和MobileNet特征提取器提取特征, 不同通道表示不同类型的视觉特征, 以Inception-v3模型的mixed9特征层为例, mixed9特征图中包含2048个通道, 每个通道均描述图像部分特征,而对分类器而言, 不同特征算子提取到的特征重要性不同, 因而每个通道的重要程度不同, 应该给予每个通道不同权重, 让分类器更加关注对网络有意义的通道,加强显著性区域特征, 减弱非显著性区域特征.
传统通道注意力网络SENet[19]在空间维度采用全局平均池化进行压缩, 经过两个全连接层和激活函数,得到通道注意力权重矩阵.由于全连接层参数较多, 加重网络负担, 增加网络过拟合风险, 因此本文采用一种精简的通道注意力模块, 其结构如图5所示.

图5 本文通道注意力机制网络结构
由图5可知,F为特征提取器提取到的特征向量,维度为 (B,H,W,C), 经过全局平均池化操作得到维度为(B,1,1,C)的特征矩阵, 输入神经元个数为C为的全连接层, 经过 σ 激活函数得到通道注意权重矩阵, 其特征通道权重矩阵和为1, 其过程表示为:

其中,F为输入特征,AvgPool为全局平均池化,Dense为全连接层, σ为激活函数,Fb为通道注意特征权重矩阵.
1.4 空间注意力
在原始输入图像经过特征提取器提取的特征图中,特征图是原始输入图像的映射.对于图像而言, 目标总是只占据图像部分区域, 而其余区域则是背景信息.如何更好地让分类器更加关注存在目标的区域, 而降低背景信息干扰对图像分类性能起着关键作用.因此, 本文采用一种简单的通道注意力模块, 其结构如图6所示.

图6 本文空间注意力机制网络结构
由图6可知,F为特征提取器提取到的特征向量,维度为 (B,H,W,C), 经过卷积操作得到维度为(B,H,W,1)的特征矩阵, 然后经过激活函数得到空间注意权重矩阵, 其特征空间权重矩阵和为1, 其过程表示为:

其中,F为输入特征,Conv为卷积操作, σ为激活函数,Fa为空间注意特征权重矩阵.
2 实验结果及分析
本文实验环境为Windows系统, 显卡型号为NVIDIA GeForce RTX 2060, 采用基于TensorFlow[22]的Keras深度学习框架和Python编程语言, 分别在Caltech-101[23], Cifar-10[24], Cifar-100[24]这3个数据集上进行实验, 采用网络的错误率来验证本文算法的有效性.
2.1 Cifar-10数据集
Cifar-10数据集是图像分类常用数据集, 分为10类, 每类6000张图像, 共60 000张图像, 其中50 000张图像用于训练, 10 000张图像用于测试, 图像尺寸为32×32.在模型训练过程中, 为了提高模型的泛化性, 使用随机翻转, 亮度变化等数据增强技术.在参数设置方面, 学习率初始化为0.01, 批处理大小为32, 使用SGD优化器, 并在训练中使用学习率递减策略, 当验证集的准确率3个epoch不再下降时, 学习率递减为原来的一半.
基于Cifar-10数据集, 表1为本文提出的MFRA算法与其他算法的实验结果对比, 从表1可知, MFRA算法的错误率为3.86%, 相较于其他网络错误率降低1.11%至6.55%, 据作者所知是目前同种类分类网络中错误率较低, 说明MFRA具有更佳的分类性能.

表1 不同算法错误率对比 (Cifar-10数据集)
2.2 Cifar-100数据集
Cifar-100数据集由100个类的60 000张32×32彩色图片组成, 每个类有6000张图片.分为50 000张训练图像和10 000张测试图像.与Cifar-10不同的是,Cifar-100数据集的每类图像都带有一个精细标签即它所属的类和一粗糙标签即它所属的超类, 因此Cifar-100数据集比Cifar-10数据集更具有挑战性.在模型训练过程中, 为了提高模型的泛化性, 使用随机翻转, 亮度变化等数据增强技术.在参数设置方面, 学习率初始化为0.01, 批处理大小为32, 使用SGD优化器, 并在训练中使用学习率递减策略, 当验证集的准确率3个epoch不再下降时, 学习率递减为原来的一半.
基于Cifar-100数据集, 表2为MFRA算法与其他算法的实验结果对比, 从表2可知, MFRA算法的错误率为17.51%, 与其他网络相比错误率至少降低8.34%,说明MFRA算法具有更佳的分类精度.

表2 不同算法的错误率对比 (Cifar-100数据集)
2.3 Caltech-101数据集
Caltech-101是一个非常流行的图像分类数据集,共9144张图像, 分为102个类别.每个类别的图像数量在31至800图像之间.在实验中, 为了比较的结果更具说服力, 与比较的其他算法一致, 我们使用每个类的随机选择的30张图像进行训练, 其余的图像用于测试.
在模型训练过程中, 为了提高模型的泛化性, 使用随机翻转, 亮度变化等数据增强技术.在参数设置方面,学习率初始化为0.001, 批处理大小为16, 使用SGD优化器, 并在训练中使用学习率递减策略, 当验证集的准确率3个epoch不再下降时, 学习率递减为原来的一半.
基于Caltech-101数据集, 表3为MFRA算法与其他算法的实验结果对比, 从表3可知, 本文算法的错误率为5.36%, 与其他网络模型相比有所降低, 说明MFRA算法具有更好的分类能力.

表3 不同算法的错误率对比 (Caltech-101数据集)
2.4 消融实验
MFRA算法的核心在于多模型特征融合及精简注意力模块, 在实验参数设置相同的前提下, 本节基于Cifar-100数据集上进行两组消融实验来分别证明多模型特征融合及精简注意力模块的有效性.其中, 第1组实验验证精简注意力模块对本文网络结构性能的提升,第2组实验验证了多模型特征融合对本文网络结构性能的提升.
图7为不使用注意力模块的网络和只使用一种注意力模块的网络与使用精简注意力模块的网络在Cifar-100数据集的准确率曲线对比, 其中, A曲线为不使用任何注意力模块的网络, B曲线为使用空间注意力模块的网络, C曲线为采用通道注意力的网络, D曲线为采用精简注意力的网络.由图7可知, 使用精简注意力模块的网络模型与其他网络模型相比, 收敛速度更快且分类准确率更高, 证明了在网络模型中加入精简注意力可以加快模型的训练速度, 使模型更快收敛,从而提高网络性能.
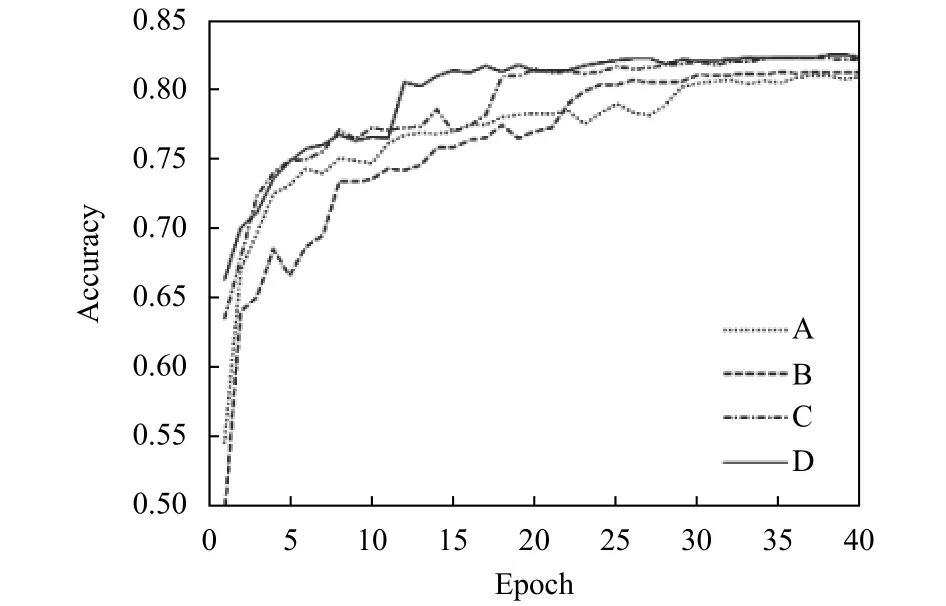
图7 不同模块的准确率曲线对比
从表4可知, 在Cifar-100数据集上, 不使用注意力模块的网络分类错误率为18.96%, 只使用了空间注意力或通道注意力模块网络错误率相比不使用注意力模块的网络性能会有所下降, 分类错误率降低了0.22%至1.19%, 使用精简注意力模块的网络分类性能最佳,达到了17.51%的分类错误率, 这充分验证了精简注意力模块的有效性.

表4 不同模块的错误率对比
图8为使用单一模型和多模型特征网络在Cifar-100数据集上的准确率曲线对比.其中, A曲线为只使用Inception-v3模型mixed9特征层的准确率曲线,B曲线为单一MobileNet模型conv_pw_12_relu特征层的准确率曲线, C曲线为多模型特征融合的准确率曲线.由图8可知, 采用多模型特征融合网络比单一模型网络分类性能更佳.收敛速度更快且分类准确率较高, 证明了多模型特征融合网络的有效性.

图8 不同模块的融合结果对比
由表5可知, 在Cifar-100数据集上, 使用单一Inception-v3模型特征的网络分类错误率为19.02%, 使用单一MobileNet模型特征的网络分类错误率为19.98%, 而使用多模型特征网络的分类错误率为18.96%.这充分验证了多模型特征融合的有效性.

表5 不同模型的错误率对比
3 结束语
本文提出一种多模型特征和注意力模块融合的图像分类算法——MFRA算法.该算法选取当前主流的卷积神经网络进行迁移学习, 节省训练成本.根据不同的网络架构学习到图像的不同特征, 利用模型的多样性提取互补的视觉特征, 通过融合不同模型的所提取的特征提高网络的特征提取能力, 提高网络分类性能,并在网络中嵌入精简注意力模块, 使网络将注意力集中于重要特征上, 降低背景干扰.在几个常用的分类数据集上的实验结果表明, MFRA算法取得了较好的图像分类性能, 相较于其他算法, 其准确率有显著提升.
