基于RISC-V的新型硬件性能计数器①
2022-01-06薛子涵
薛子涵, 解 达, 宋 威
1(中国科学院 信息工程研究所, 北京 100093)
2(中国科学院大学 网络空间安全学院, 北京 100049)
1 引言
现代处理器中一般都拥有若干被称为硬件性能计数器(Hardware Performance Counter, HPC)的寄存器[1].这种寄存器只会按照软件的配置在指定的事件发生时自增计数, 对处理器的正常工作或者性能表现不会有影响.这些被记录的信息能够帮助软件工程师对代码进行优化, 也能够协助计算机架构师对处理器结构进行调优, 因此HPC几乎成为所有现代处理器的标配.作为近年来备受学术界和工业界关注的开源指令集RISC-V, 其处理器在设计之初就把HPC考虑了进去并为其制定了相关标准.RISC-V特权指令规范[2]定义了若干控制和状态寄存器(Control and Status Registers,CSRs)作为计数器和选择器.其中选择器将一个或多个(微)体系结构事件的信号接入计数器, 从而构成了可捕获特定事件的HPC.在现代处理器结构愈发复杂的时代, 这种将HPC集中在CSR模块内的方式不利于HPC的拓展, 也限制了可同时监测的体系结构事件数量.为此, 本文设计了一种分布式的性能计数器.按照处理器内部模块的划分, 将HPC分布在不同区域,并通过片上互连将HPC和CSR模块连接, 从而降低了CSR模块复杂度, 同时也为HPC的拓展提供了便利.
本文组织架构如下: 第2节介绍了相关的背景知识.第3节介绍了SiFive U74-MC[3]的性能计数器并分析其不足之处.第4节针对现有的HPC方案存在的问题, 提出了分布式的HPC方案.第5节完成了将分布式的HPC部署到lowRISC-v0.4[4], 通过运行SPEC CPU2006[5]分析结果并评估该方案效果.第6节总结本文.
2 研究背景
2.1 RISC-V
RISC-V[6]是一种优秀的开源指令集架构, 由加州大学伯克利分校于2010年发布.RISC-V充分吸取了其他指令集优点: 结构优雅便于实现、灵活性强方便拓展、免费开源无须高昂的授权费用、社区活跃工具链完善等[7,8].这些优点使其得到了众多科研团队和商业公司的青睐.目前已有平头哥、SiFive在内的商业公司推出了基于RISC-V指令集的处理器.然而RISC-V定义的HPC存在不足, 无法同时监测多种体系结构事件, 在使用中局限性较大.
2.2 RocketChip
RocketChip[9]是加州大学开源的基于RISC-V的64位处理器.其中RocketChip的Rocket处理器核采用5级标量顺序流水线, 采用Chisel (Constructing hardware in a Scala embedded language)语言开发[10].作为加州大学为推广RISC-V而开发的开源处理器,RocketChip为全世界的科研团队提供了针对体系结构研究的优良平台.
2.3 lowRISC-v0.4
lowRISC-v0.4是剑桥大学开发的基于RocketChip的开源SoC, 其基本信息如表1所示[4].相比于其他开源SoC 项目lowRISC-v0.4加入的OSD (Open SoC Debug) 模块[11]提供了函数追踪、特权模式监测、程序下载(通过UART接口)等功能.这些功能在代码调试过程中提供了详细的调试信息.本文利用OSD模块与上位机结合的方式, 使得lowRISC-v0.4能够自动运行SPEC CPU2006 benchmark[5], 并在运行结束后读取HPC, 获取体系结构事件的统计值, 从而验证HPC 能否正常工作.
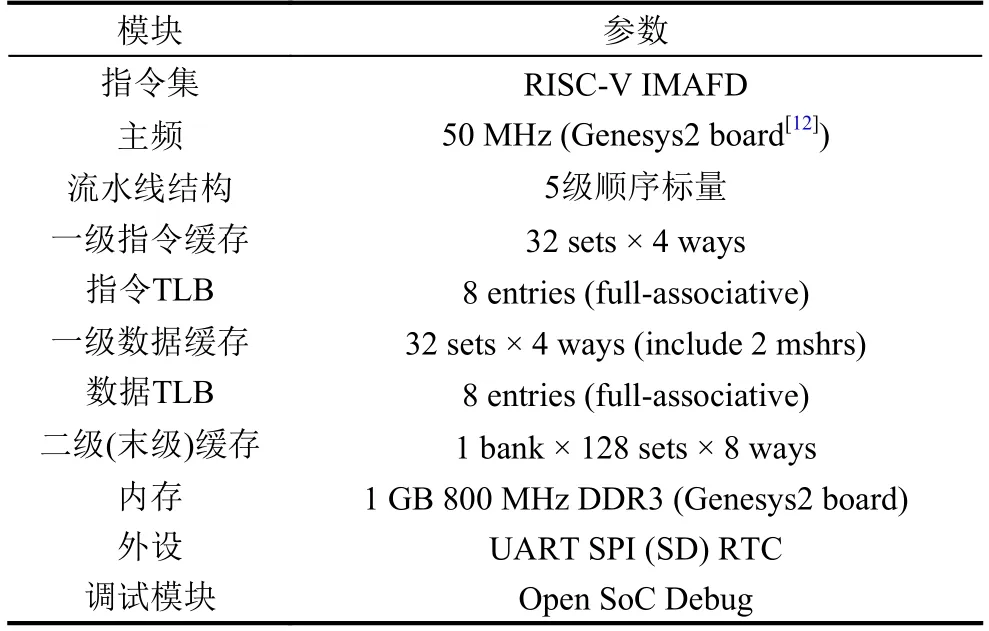
表1 lowRISC-v0.4基本信息
2.4 硬件性能计数器
硬件性能计数器是一组能够记录(微)体系结构事件发生次数的寄存器.这些事件通常包括时钟周期数、已执行指令数、分支预测失败次数、各级缓存(cache)的缺失/命中次数、TLB (Translation Look-aside Buffer)的缺失/命中次数等[1].对于会造成流水线阻塞的事件,某些处理器中的HPC还会记录该事件导致的阻塞周期数[13,14].这些寄存器通常作为系统寄存器(比如ARM中的System Register, RISC-V中的CSR), 从而能够被指令直接访问.尽管HPC不是处理器正常工作的必要组成单元, 也不会对处理器性能有影响, 然而HPC提供了硬件运行过程中实时的状态信息.利用这些信息我们能够更加高效地对系统状态进行监测[1]、对硬件资源进行高效利用[15]、对功耗进行合理管理[16]、对恶意代码进行有针对性的检测[17,18]、对计算机系统结构[19]进行优化.因此, 几乎所有现代处理器都会配置该计数器.HPC的管理和配置工作通常由性能监测单元(Performance Monitor Unit, PMU)完成.PMU为每一个HPC都分配了一个事件类型选择寄存器, 当(微)体系结构中发生的事件和该寄存器选中的事件匹配时, PMU就会控制对应的HPC增加计数值.除了计数器和选择寄存器这两个成对出现的寄存器之外, 某些处理中的PMU还包含了其他寄存器, 从而可以提供更丰富、更强大的额外功能: 比如访问控制、特权级过滤(如过滤用户态下的事件)等.HPC的基本配置和访问较为简单, 通常只需在选择寄存器中, 选中要监控的事件.对于较为复杂的需要则可以直接使用Linux下的开源工具—perf[20].经过多年的发展, 商业处理器HPC的硬件结构和软件配套已经十分完善, 能够满足各种应用需求.然而, 迄今为止开源RISC-V处理器(如RocketChip, lowRISC)中的HPC存在功能简陋、拓展性弱、能够同时统计的体系结构事件少等不足, 无法满足对于体系结构的研究需求.基于此本文设计、实现了一种分布式HPC,并使用该HPC进行我们相关的体系结构研究工作.
3 U74-MC的性能计数器
U74-MC[3]是由SiFive公司发布的基于RISC-V指令集的64位高性能多核处理器, 可应用于数据中心、通信基站等对性能要求较高的场景.作为目前性能最优的RISC-V处理器之一, U74-MC拥有功能全面的HPC.因此本文对U74-MC的HPC进行了着重分析.U74-MC的HPC可以分为两类: 第1类按照RISC-V特权指令规范, 将若干CSR作为HPC寄存器, 软件可以通过CSR指令配置和访问这些HPC.第2类专门用来统计L2的微体系结构事件, 这类HPC不会占用CSR,而是像外设一样通过MMIO (Memory-Mapped I/O,即内存映射)与处理器核连接.为了便于区分, 本文把第1类称为核内HPC, 第2类称为外设HPC.
3.1 核内HPC
按照RISC-V特权指令规范[3], U74-MC分配了4个CSR作为HPC (这些计数器称为mhpmcounter),其中两个(mcycle和minstret)用于统计时钟周期和已执行指令数, 其余两个是可编程的CSR, 可用于够捕获选定的事件, 并完成计数.事件的选择由mphevent寄存器控制, 能够选中某一种或某几种事件.为了安全起见,用户级(user-level)的程序不能配置该寄存器, 也无法直接访问mhpmcounter, 只能在机器级(machine-level).程序在[m|s]counteren中开启了对应的计数器访问权限后, 用户级程序才被允许通过访问hpmcounter, 从而间接获取mhpmcounter中的存储的计数值.即hpmcounter是mhpmcounter的影子寄存器(shadow CSR).
如图1所示, 核内HPC的寄存器位于CSR模块内部, 事件信号来自不同模块.因此这种结构的HPC拥有极低的访问延时, 软件通过CSR命令能够直接获取HPC数据.虽然核内HPC结构简单, 便于实现且能够满足大部分应用场景, 但仍存在不足: 首先, 无法同时监测大量事件, 当监测事件大于核内HPC数量时,只能由软件不断切换监测的事件类型.这种方式不仅损害了性能, 同时还降低了测量精度.其次, 计数器都集中在CSR区域, 而(微)体系结构事件却分布在如处理器核、缓存、直接存储器访问(Direct Memory Access,DMA)等各个模块中.繁多的计数信号来源给前端设计和后端布线带来了巨大挑战.
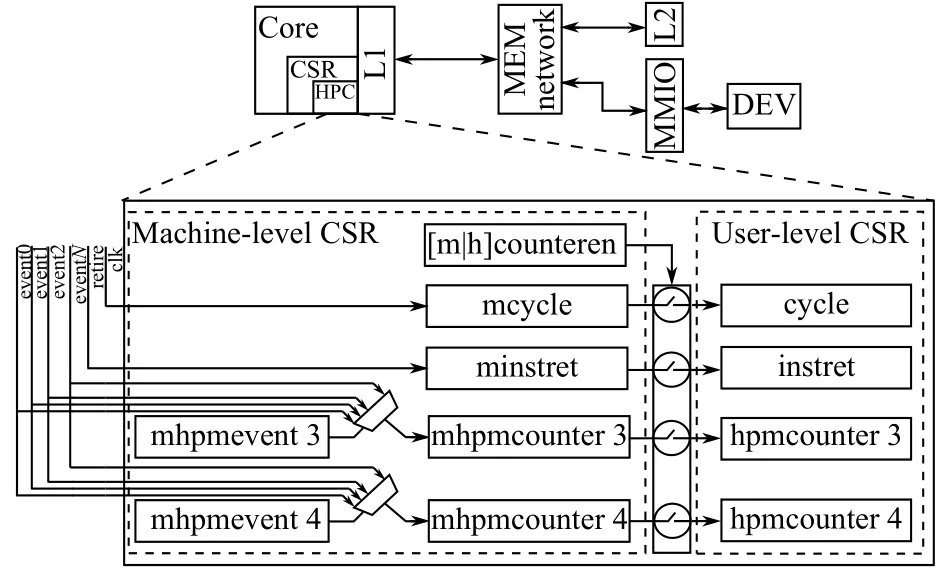
图1 核内HPC结构
3.2 外设HPC
现代处理器内部拥有种类众多的模块: 处理器核、缓存、DMA等, 将这些模块的事件信息全部汇总在核内HPC是很不明智的做法.将同一模块的HPC集中在一起并作为外设连接到MMIO, 这样就避免了核内HPC计数信号过于分散的问题, 而且通过访存指令(LOAD/STORE)就能对这些HPC进行控制和访问.U74-MC的L2 HPC就使用了这种设计方来案监测L2缓存的(微)体系结构事件.
如图2所示, 外设HPC就像外设一样通过MMIO连接至处理器核, 由于IO空间范围较大, 此结构具有较好的拓展性.外设HPC弥补了核内HPC缺陷, 能够同时监测更多的(微)体系结构事件.但仍有一些不足:首先, IO空间无法对用户态下的程序直接可见, 访问前需要经过操作系统的映射, 从而产生不小的代价.其次,MMIO由诸多外设共享, HPC数据可能被恶意外设获取, 进而被利用发起侧信道攻击, 引起难以监测的安全问题.最后, 相比于CSR访问命令, LOAD/STORE指令影响L1D (一级数据缓存)的缺失率, 即访问HPC会影响测量的准确性.
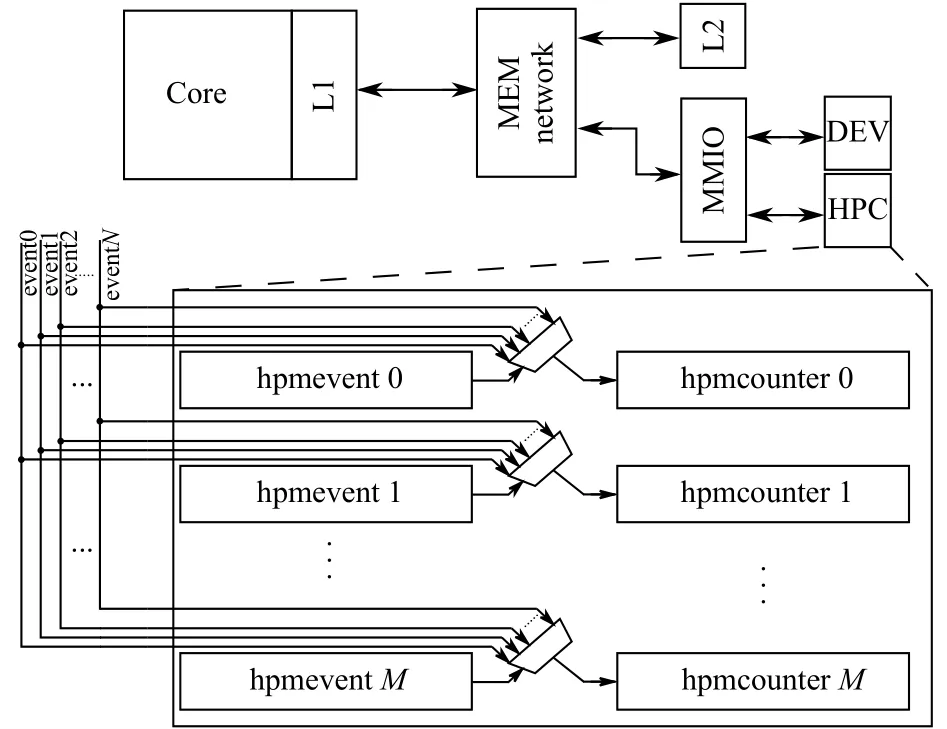
图2 外设HPC结构
4 分布式性能计数器
针对以上不足, 本文提出一种分布式的性能计数器方案, 该方案充分结合了核内/外设 HPC两者优点:首先, 该结构拥有众多HPC, 能同时监测上百种事件.其次, 易于使用, 利用3个CSR就够控制和访问这些HPC, 不影响L1D性能有更好的准确性, 不占用MMIO,因此不会带来地址映射的额外开销.最后, 有着更好的安全特性, 能够通过CSR的权限控制管理HPC的访问, 从而避免了HPC被非法使用, 进而导致侧信道攻击.
4.1 结构
核内HPC结构模型中的每一个计数器都占据了1个CSR, 当需要同时监测更多事件时, 就需要更多的CSR.如果将这些计数器从CSR中剥离出来, 根据其事件类型和触发信号的来源, 将其分布在不同模块中, 并通过片上互连, 将各个计数器和对应的CSR相连, 这样就可以通过使用少量的CSR来控制和访问数量庞大的HPC, 按照这种策略, 本文设计了如图3所示的分布式性能计数器.从图3中可以清晰地看出它由3个重要部分组成: HPCManager, HPCClient和HPCInterconnect.而HPC的寄存器被分散在了HPCManager中.
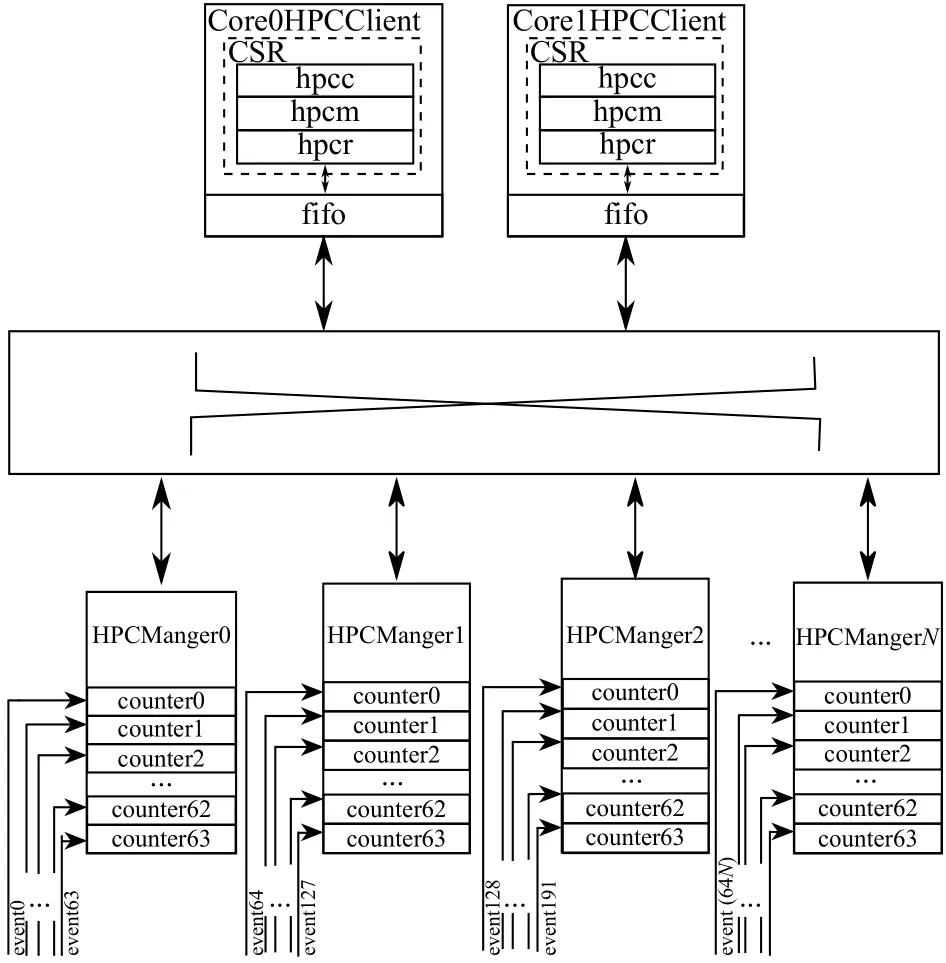
图3 分布式性能计数器结构
HPCManager主要负责接收和处理来自HPCClient的数据请求, 根据请求命令去查找指定的HPC, 并把该HPC的数据返回给HPCClient.1个HPCManager最多可以容纳64个HPC, 这些HPC并无编程功能, 每个计数器只能够记录特定的(微)体系结构事件.HPC按照所属模块进行划分, 比如处理器核中的事件统一划分给一个HPCManager, L2 (二级缓存)分片中的事件统一划分给另一个HPCManager.当模块中的事件超过64种时, 可为该模块分配多个HPCManagerID.显然, 相比于计数器集中在CSR中的方式, 这种按模块去划分的分布式方案拓展性更强, 拥有更规整、更清晰的结构, 同时带给后端布线的压力也更小.
HPCClient主要负责向HPCManager发起HPC数据请求以及接收返回的数据, 其结构如图4所示.可以看出, HPCClient位于处理器核中的CSR模块, 它占用了3个CSR: hpcm (hardware performance counters bitmap),hpcc (hardware performance counters config)以及hpcr(hardware performance counters receive).通过这3个CSR, 软件能够获取到任意HPC的数据.它们的详细内容将在本文的4.2小节展开.
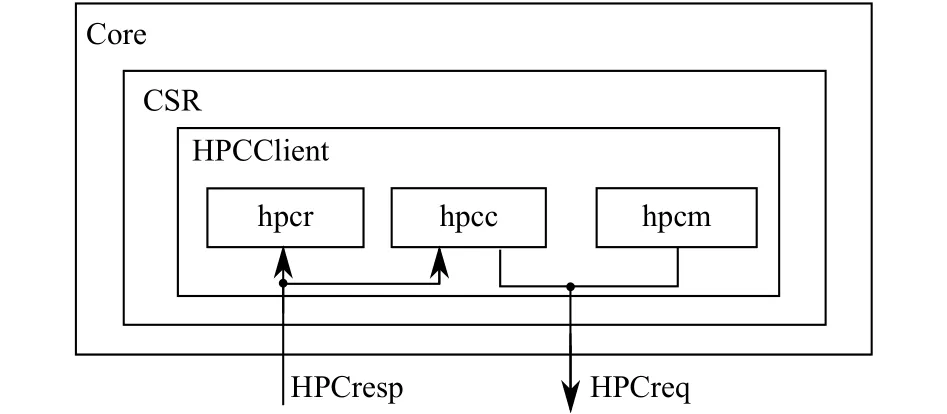
图4 HPCClient结构
HPCInterconnect则把HPCClient和HPCManager连接在一起, 并且把这两种模块的命令、数据传递到指定位置.HPCInterconnect采用循环优先级, 它保证了在多核结构中, 每个核对HPCManager都拥有相同的优先级, 在多核同时向同一HPCManager发起请求时,可以有效避免“饿死”的情况.
4.2 性能计数器占用的CSR
在CSR中定义了3个寄存器, 即hpcc, hpcm, hpcr,通过这3个寄存器来完成对HPC的管理和访问.
hpcc 即 hardware performance counters config.其比特位分配情况如图5所示.作为硬件性能计数器的功能配置寄存器, 该CSR功能包括: 向指定的HPCManager发起HPC请求、指示接收状态、指示软件读取是否失败等.
以下内容是依据图5对hpcc的功能划分进行说明:

图5 hpcc寄存器
(1) trigger: hpcc[0] ReadWrite
该位主要功能是发起和取消HPC请求.如果此位为0, 则表示当前没有正在进行的HPC请求, 这时写入1就可以触发一次新的HPC请求.若此位为1, 则表示有正在进行的HPC请求, 软件可以通过写入0的方式来撤销当前未完成的请求.当HPCClient接收完所有指定的数据后, trigger会自动复位, 表示完成了1次请求, 即所有需要的HPC数据均已存入fifo.
(2) interrupted: hpcc[1] ReadOnly
该位用于表示HPC在请求过程中, 是否发生过上下文切换.当软件写hpcm时, 该位自动复位, 当上下文切换时, interrupted自动置位, 表示HPC请求阶段可能出现数据错误, 需要重新发起请求.软件只拥有该位的读取权限.
(3) empty: hpcc[2] ReadOnly
该位用于表示接收返回数据的fifo状态.当fifo空时, 该位会被置位, 否则被复位.当软件写hpcm时该位自动置位, 软件只拥有该位的读取权限.利用empty, 我们可以实现更快速地HPC读取, 当empty复位后, 软件就可以开始读取该数值, 而不必等到接收完HPCManager返回的所有数据(此时trigger自动复位)才开始读取工作.因而把该位当作读取开始的判断依据, 能够节约一定的时钟周期.
(4) readerror: hpcc[3] ReadOnly
该位用于表示软件读取HPC时是否发生了错误.当软件写hpcm时, 该位自动复位, 当软件从空的fifo中读出了数据时, 该位置位, 表示读到了错误的数据.软件只拥有该位的读取权限.
(5) HPCMangerID: hpcc[20:4] ReadWrite
即HPCManager的ID.软件向该位写入正确的ID号, 从而在选中预期的HPCManager之后, 置位trigger就能向该HPCManager发起HPC请求.为了增强扩展性, 该位无法独立工作, 需要与hpcm寄存器配合使用.事实上, HPC可以按照任意规则划分到HPCManager,本着“一种逻辑清晰的划分规则, 既能给使用者带来便利也能够减轻后端布线的压力”的思想, 本文采取按照“模块化”的划分策略, 将HPCMangerID分割成module和extend两部分, module指的是处理器核0, 处理器核1, 末级缓存分片0, 末级缓存分片1等模块.而复杂模块内的事件数量通常会超过64, 因此会使用extend对模块分配多个HPCManagerID.
useren: hpcc[21] ReadWrite
该位用于对用户级程序HPC访问权限的控制, 用户级的程序对该位只有读取的权限, 只有机器级或特权级下的程序能够对该位进行更改.若此位为1, 则用户级的程序能够发起HPC请求, 否则用户级的程序在置位trigger时会触发异常.该位的置位复位可以由操作系统完成, 这样能够对任意进程进行HPC访问权限的控制.避免了HPC数据被恶意程序利用, 有着很好的安全特性.
hpcm即 hardware performance counters bitmap.作为硬件性能计数器的位图选择器, 该寄存器的每一比特都对应HPCManager中的1个HPC.当hpcc.trigger处于复位状态时, 软件拥有hpcm的写权限, 否则软件只能读取该寄存器.当 HPCClient按照HPCMangerID指示向目标HPCManager发起请求时, hpcm选定了要读取的HPC, 同时该寄存器自动复位.之后每接收到HPCManager返回的1个HPC, 就将对应的比特位置位, 通过读取该位, 软件可以知晓已接收到的HPC.受限于寄存器最大位宽, 因此每次选取的HPC不能超过64个, 从而理论上, 1个HPCManager最多管理64个计数器.为不同模块分配单独的HPCManager, 记录了不同模块内部的(微)体系结构事件, 目前支持的事件和对应的hpcm位图如表2所示.read表示读取缓存的次数.readmiss表示读取缓存, 但发生数据缺失的次数.write表示向缓存写入数据的次数.writemiss表示向缓存写入数据, 但是发生缺失的次数.writeback表示将缓存中的数据写入下一级缓存或者内存中的次数.

表2 记录的事件和其所在位置
hpcr作为硬件性能计数器的接收寄存器, 软件只有该寄存器的读取权限.通过读取该寄存器, 软件可以获得HPC数值.hpcr是直接连接到fifo输出端口, 软件每读取一次hpcr, fifo就会弹出一个新的数据存入hpcr寄存器.当fifo为空时就会把过时或错误的数据存入该寄存器.发起HPC请求后, 软件可以在hpcc.trigger由1变0后才开始读取hpcr (表示当前的HPC全部接收完毕), 也可以在hpcc.empty由1变0后立刻读取(表示当前接收到有返回的HPC).在没有异常或例外的情况下, 两者得到的数值以及数值顺序完全相同, 且后者更节约时钟周期, 尤其在请求的HPC数量较多的情况中.
4.3 编程模型
在裸机环境(bare metal environment)中, 不存在多个线程对HPC控制权的争抢问题, 配置并访问HPC十分简单.算法1适用于裸机环境下获取HPC数值:行①使用CSR置位指令, 将bitmap写入hpcm寄存器,其中bitmap代表选中HPCManager中的某几个HPC.行② id用来选中HPCManager, 置位trigger会触发对HPCManager的请求.行④等待HPCManager返回数据(empty复位).行⑤empty复位后, 软件读取hpcr并将得到的HPC数据存入数组.

算法1.裸机环境HPC的访问输入: HPCM 的id和HPC对应的bitmap输出: HPC记录的数据Function get_HPCs(id, bitmap):① set_csr(hpcm, bitmap);② set_csr(hpcc, id&trigger);③ for(i=0; i<=hpcnumber; i++) {④ while(get_csr(hpcc.empty));⑤ hpcs[i]=get_csr(hpcr);⑥ }
在多线程环境下, 可能会出现同一个处理器核中的多个线程同时向HPC发起请求.HPC的获取需要HPC的3个寄存器相互配合, 当配置工作被其他线程打断, 则会出现意想不到的错误.针对这种问题, 我们通过使用“软件锁”, 防止多个程序同时对HPC的3个寄存器进行控制和访问.然而“软件锁”不仅实现复杂而且开销较大, 对测量精度有影响.为此, 我们通过监测hpcc.interrupted位, 来判断HPC的请求程序是否发生过中断.当系统中线程个数与中断次数均较少时, 这种方式的失败率可以忽略.这种方法编程简单、易于实现, 不会给系统带来过多的额外开销, 更加适合我们的研究工作.其具体算法如算法2所示: 行②复位hpcc寄存器, 终止可能正在进行的HPC请求.行③至行⑧如算法1, 获取HPC数据并存入数组.行⑨判断上述操作是否出现上下文切换, 若出现过上下文切换, 则返回到行②处.

算法2.多线程中HPC的访问输入: HPCM 的id和HPC对应的bitmap输出: HPC记录的数据Function get_HPCs(id, bitmap):① do {② clear_csr(hpcc.trigger);③ set_csr(hpcm, bitmap);④ set_csr(hpcc, id&trigger);⑤ for(i=0; i<=hpcnumber; i++) {⑥ while(get_csr(hpcc.empty));⑦ hpcs[i]=get_csr(hpcr);⑧ }⑨ } while(get_csr(hpcc.interruped))
5 结果与分析
我们通过将本文设计的分布式硬件性能计数器,部署在lowRISC-v0.4上, 其消耗的资源如表3所示.可以看出本文的设计硬件开销较小: LUTs和Registers分别占用了1.66%和6.29%.其中, HPCClient使用寄存器相对较多, 其原因是用于接收HPC数据的缓冲区容量较大.lowRISC-v0.4能够以50 MHz的频率工作在Genesys2开发板[12], 其工作频率并没有受到HPC的影响.通过使用OSD模块, 我们实现了lowRISC-v0.4可以自动运行SPEC CPU2006的各个整数测试集,在运行完一百亿条指令后, 采用算法1读取HPC.每个基准的测试用例结果的平均值如表4所示, 可以看出L2的读取次数等于指令缓存和数据缓存的缺失次数之和, 符合L1和L2包含关系.结合表3、表4, 我们可以得出一个结论: 分布式的HPC能够以极少的硬件资源为代价, 实现了准确地记录时钟周期、执行指令数以及L1与L2各分片的读写次数和缺失次数.
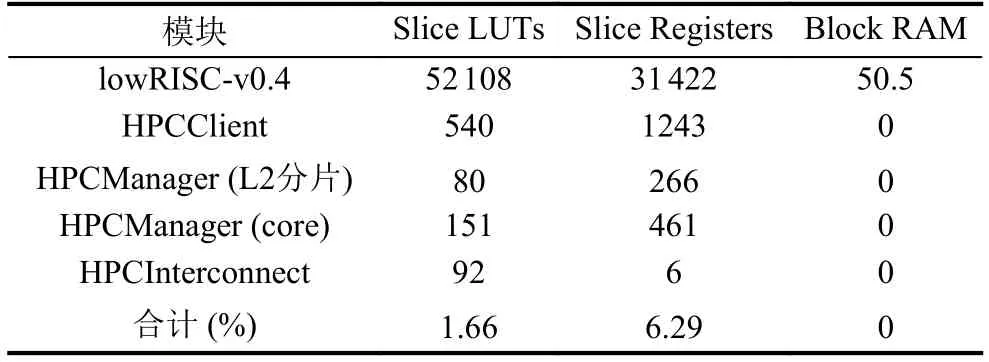
表3 性能计数器资源消耗情况
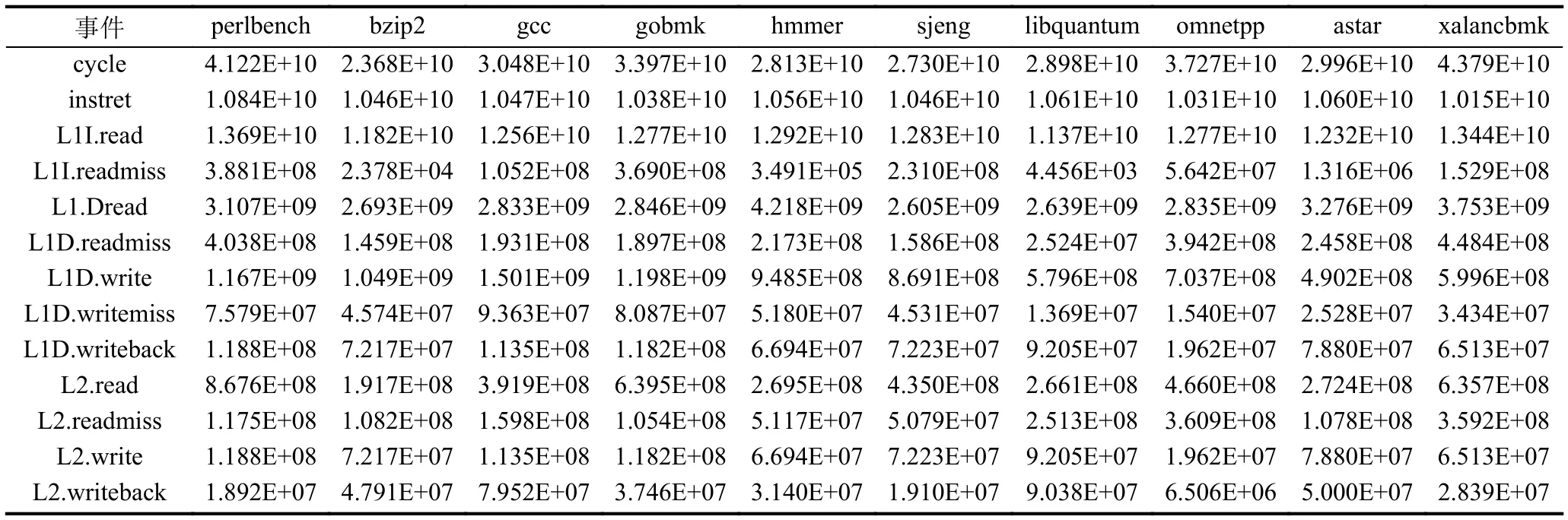
表4 SPEC CPU2006 (整数)运行结果
6 结论与展望
表5将分布式的HPC和SiFive公司的U74-MC处理器所包含的两类HPC进行对比: U74-MC的核内型HPC结构简单安全性强, 但是在监测大量事件时,需要依靠软件不断切换监测事件, 既增加了编程代码也降低了测量精度.U74-MC的外设型HPC将计数器部署在IO空间, 因此有很大的拓展空间, 能够同时监测大量事件, 然而由于通过MMIO连接, HPC数据可能泄露给恶意外设, 对处理器安全有一定影响.而且外设型HPC需要LOAD/STORE指令访问, 这些指令对L1D的缺失率有一定影响.本文设计的分布式HPC为每个事件都单独分配了计数器, 因而测量精度得到了保障.根据事件种类将计数器部署在不同HPCManager中, 并利用独立的HPC互连将这HPCManager和处理器核中的HPCClient进行连接, 因此分布式HPC有着很大的拓展空间和很好的安全性.除此之外该方案仅使用3个CSR就能访问所有的HPC, 避免了对CSR资源的过多占用.这些优点给我们之后的相关研究工作带来了极大的便利.但仍存在诸多缺陷: 首先分布式的HPC只适用于64位处理器, 通用性较差.其次精力所限, 本文提出的方案没有经过严格测试无法保障稳定性, 只适合研究工作.再次相较于商业处理器提供的众多监测事件, 本方案目前监测的事件种类少, 只统计了我们研究需要的事件.这些不足均需要后续完善.

表5 3种HPC特点对比
