基于边缘计算的智能配电网多源数据处理与融合技术研究
2021-12-31潘志新翟学锋王成亮官国飞徐妍
潘志新,翟学锋,王成亮,官国飞,徐妍
(江苏方天电力技术有限公司,江苏 南京 211100)
配电网作为连接变电站与用户的重要公共基础设施,是提升智能电网末端供电质量和用户体验的关键环节[1-2]。伴随着我国配电网智能化发展,除传统配电网本身运行和管理数据之外,智能化的感知终端设备产生的数据大量增加,且呈现种类繁多、多源、不确定等特性[3]。
传统应用配电网中心采用云-边缘的计算模式,由于海量数据的急剧增加和数据复杂度的影响,产生的上行终端监测数据和配电网运行数据以及下行云计算处理信息为通信传输层带来了巨大压力,同时严重约束了智能配电网的推进。深入挖掘边缘计算在配电网智能化中的应用潜力成为了主要研究热点,越来越多的配电网数据信息终端化处理、边缘化计算及局部化解决的方式成为一种重要方式[4-5]。但是复杂的多源异构数据的边缘化集成为智能配电网的高效边缘计算带来新的挑战,因此,亟待实现智能配电网多源数据边缘化模式下的处理和融合,是提升和保证基于边缘计算的配电网智能化发展的重要基础[6-7]。
长期以来,国内外专家学者关于智能配电网海量数据分析挖掘方法与多源数据处理与融合技术开展了众多有意义的研究,周杨珺等[8]针对配电网数据源及数据特征展开分析,并设计了包含四个层次的配电网运行数据分析系统架构;孙浩洋等[9]提出了一种边缘计算技术在配电网物联网中的应用方法,并深入分析了边缘计算技术在配电行业的实际应用中面临的不足之处;Okay F Y等[10]提出了一种边缘计算架构在智能电网模型中的应用方法,并结合智能终端数据与运行量测数据,具体阐述了边缘计算在数据安全与效率分析方面的意义;马洲俊等[11]提出了多源异构数据分析结果辅助配电网故障信息识别定位的策略,为有效挖掘配电网智能化数据应用化价值提供了研究借鉴;Barik Rabindra K等[12]提出了利用先进的计量基础设施和雾计算融合实现智能电网增强,延伸了分布式控制、通信和计算的能力,使得智能电网的可靠性、弹性和可伸缩性均得到了提高;王维嘉等[13]建立了一种自适应多目标群交叉优化算法实现多源数据分类融合与异构数据的准确融合。
综上所述,智能配电网的发展已然成为一种必然趋势,边缘计算技术的应用提供了分布式服务和计算的功能,但海量多源异构配用电数据的有效清洗与联接研究的不足,使得边缘计算性能的巨大潜力无法发挥。文中提出一种基于边缘计算的智能配电网多源数据处理与融合技术,设计充分考虑边缘计算的数据处理与融合架构;提出基于广义幂变换Zscore(Box-Cox transformation Zscore,BC-Zscore)的各配电网数据源量纲和数量级的变换统一处理方法;通过构建基于冲突优化DS推理(principal components analysis-dempster shafer,PCA-DS)的多源数据融合模型,基于多维特征因素考量对多源异构数据进行分组聚合。考虑边缘计算的智能配电网多源数据的处理与融合技术研究,可有效实现配电运行数据、终端监测数据、环境信息数据等基础数据源的融合,为提升智能配用电大数据多源并行挖掘和融合计算分析奠定了良好的基础,具有重要的研究价值和意义。
1 基于边缘计算的智能配电网多源数据处理与融合架构
智能配电网(smart distribution grid,SDG)建设,是指通过引入现代电子、通信、网络、计算机等领域的前沿技术,实现整个配电系统配电过程稳定和异常运行情况下的监视、保护与控制[14]。
结合边缘计算定义和技术特点,可有效解决智能配电网建设过程中的核心环节,作用于末端电力运行设备及智能监测设备与云主站之间,实现数据汇聚的基础、数据计算、数据存储以及更高级别的数据应用,充分发挥本地计算的边缘化结构优势,达到智能配电网终端扩展、拓扑灵活、计控实时的配电业务功能目标[15-16]。而目标的实现或实现程度则取决于配用电大数据下的数据汇聚操作,配用电数据的汇聚不单单是对数据的汇总与整合,应是配电管理系统中多源异构信息数据量纲和量级的处理变换,以及充分考虑不同数据源间特征属性关联的深度融合。高效的多源数据处理与融合可以促使配用电数据更好地服务于边缘计算,提高边缘计算在智能配电网中的应用能力。
考虑边缘计算下的智能配电网多源数据处理与融合架构如图1所示。
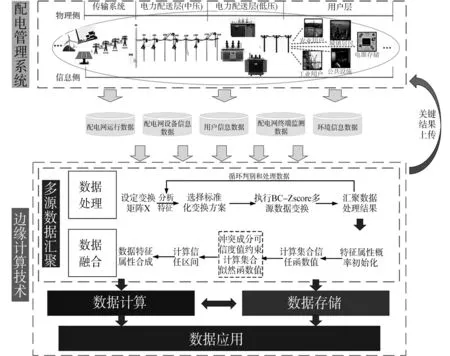
图1 多源数据处理与融合架构Fig.1 Multi-source data processing and fusion architecture
2 基于广义幂变换Zscore的多源数据标准化处理
配电网运行过程中各数据源特征属性的格式、量纲、数据类型以及数量级均不相同,为实现智能配电网边缘化的数据融合计算和信息挖掘,必须消除多种不一致因素产生的限制,实现对多源数据的标准化处理。根据配电大数据时序性的特征,通过在原有Zscore多源异构数据标准化处理基础上引入Box-Cox转换,文中提出一种基于广义幂变换Zscore的配电网多源异构数据标准化处理方法。
由于Zscore数据标准化处理是假设多源异构数据因子服从正态分布规律的,否则时序数据的偏度和峰度的影响会使得数据处理过程中某一因子上的得分明显偏大或偏小,Box-Cox转换作为一种广义幂变换方法,可有效地处理连续响应变量不满足正态分布的情况,在一定程度上消除配用电数据运行或采集过程中产生的多源时序数据波动偏移问题,保证了多源异构数据标准化处理的准确性和稳定性。
多源数据标准化处理流程如图2所示。
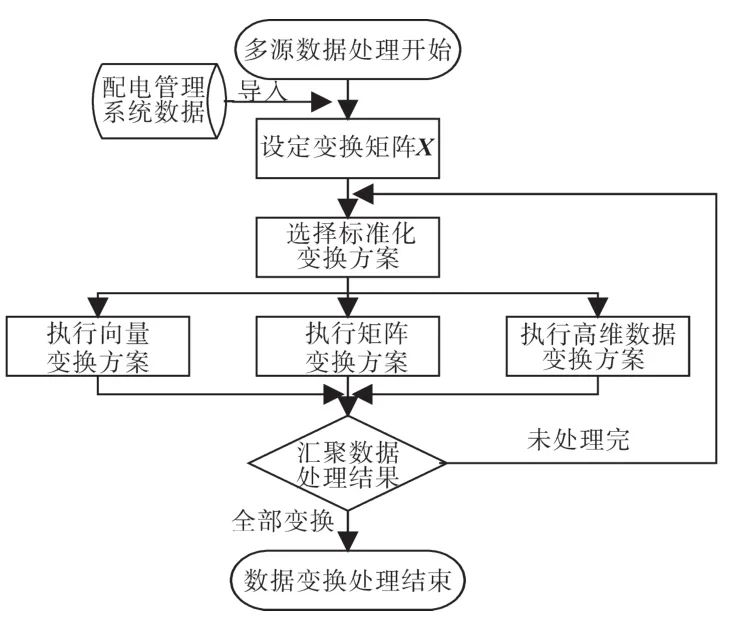
图2 多源数据标准化处理流程Fig.2 Multi-source data standardization process
具体方法执行步骤如下:
步骤1:将采集的智能配电网多源数据根据时序特征进行分解处理,记X为标准化变换输入,其中X能够以多维数据的形式、矩阵形式及向量形式存在。设当X=(X1,X2,…,Xp)以矩阵形式出现时:

步骤2:由于配用电大数据多源异构的特点,为保证不同源数据格式均实现数据变换处理,分别设置应对不同格式的BC-Zscore标准化变换方案:
1)若X是以向量的形式存在时,返回变换后的结果向量
2)若X是以矩阵的形式存在时,逐一利用X的列向量的均值和标准差对相应的列进行数据标准化处理,返回变换后的结果矩阵BC_Z;
3)若X是以多维数组的形式存在时,通过沿X的多个维度求解其均值和标准差,再对X进行数据标准化处理,返回变换后的高维数组BC_Z。
步骤3:X=(X1,X2,…,Xp)经BC-Zscore数据标准化处理后:

其中
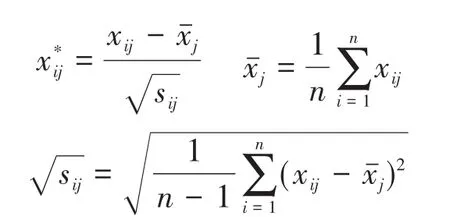
Xj的标准差;i=1,2,…,n;j=1,2,…,p。
经过BC-Zscore数据变换处理后X=(X1,X2,…,Xp)的每列中
步骤4:根据选定的多源数据处理方案进行数据迭代处理,循环执行步骤2步骤3,汇聚数据变换处理结果。
步骤5:直到任务输入的数据源均经过量纲与量级的统一变换后,进行任务输出保存,用于多源数据融合、边缘数据计算或数据存储,多源数据标准化变换结束。
3 构建基于冲突优化DS推理的多源数据融合模型
基于边缘计算模式下的智能配电网主要包括三个阶段:信息融合、状态评估以及关联决策。信息融合通过对配用电大数据处理与融合实现,只需要涉及极少简要的数据计算,关键数据计算处于信息融合后的阶段之中[17-18]。因此,数据融合的性能和意义显得极为重要,直接关系到配电网状态评估和关联决策计算结果值。文中在多源数据标准化处理的基础上,构建基于冲突优化DS推理的配电网多源数据融合模型,经过数据融合将来自多个数据源或来自相关数据库的异构数据结合在一起,从而相比使用单一数据源的边缘计算获得更高的准确性。
D-S(Dempster-Shafer)推理法,以下简称 DS推理法,作为一种处理不确定性问题的经典数据融合方法,实现了对概率论中贝叶斯条件概率的进一步改进,避免了先验概率的计算,能够很好地表示“不确定”,被广泛应用于各种领域的数据融合[19]。但由于DS推理法处理冲突子集时,因组合规则中的归一化过程会出现违背不同数据源融合常理的结果,因此,应用PCA算法对DS推理法在处理冲突数据源融合时进行进一步优化PCA可以实现寻找m(m<n)个新成分的目标,使它们反映冲突信息的主要特征,实现冲突信息主要成分的提取利用,而不是全部分配给未知项不进行融合考虑,可利用的成分取决于所定义的成分可信度函数:

基于PCA-DS推理的多源数据融合模型具体流程如图3所示。
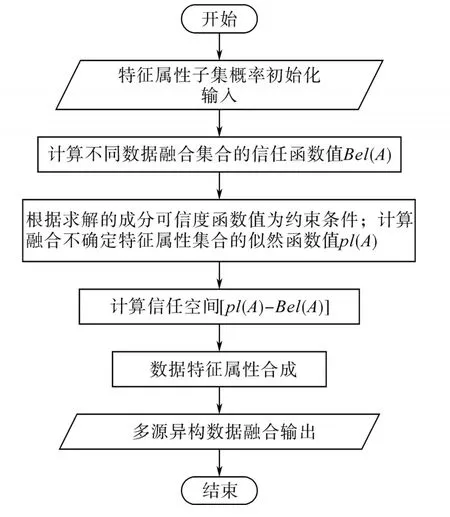
图3 多源异构数据的特征级融合Fig.3 Feature level fusion of multi-source heterogeneous data
针对配用电大数据呈现出的种类繁多、多源、不确定等特性,通过将各数据源或监测终端数据信息抽象为特征属性子集,实现智能配电网下多源异构数据的特征级融合,具体执行步骤如下。
步骤1:多源特征属性子集基本概率初始化,标记U为智能配电网多源数据融合模型框架,则函数m:2U→[0,1]满足两项条件:
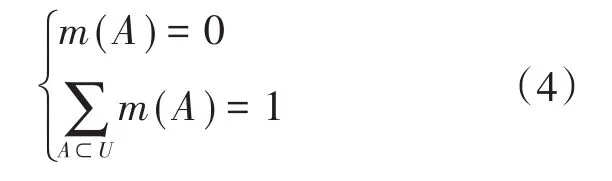
式中:m(A)=0为多源数据融合集合A的初始值,而m(A)的大小代表对其的信任程度。
步骤2:定义信任函数(belief function)计算不同数据融合集合的信任函数值。
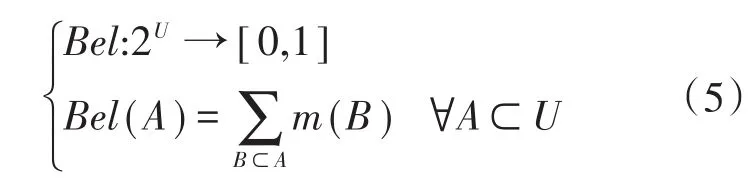
式中:Bel(A)为多源数据融合集合A中所有子集分配概率值之和,每项分配概率值表示了该项子集中特征属性组成的信任程度值,表示其中包括的配电网多源特征属性可实现最基本的数据融合。
步骤3:定义多源数据融合似然函数(plausibility function)计算融合不确定特征属性集合的信任程度值,不确定特征属性的可利用成分取决于所求解的成分可信度值͂,计算函数如下:
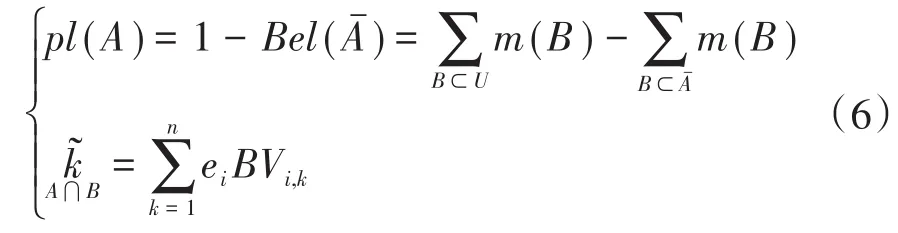
式中:pl(A)为对多源数据融合集合A似乎可能融合的不确定性特征属性的度量为集合A融合不确定性特征属性时冲突成分可信度值。
步骤4:计算数据融合的信任空间。根据信任函数和似然函数之间的关系:pl(A)≥Bel(A),A⊂U,A的不确定性可以表示为

式中:pl(A)-Bel(A)为信任空间,表示多源数据融合过程中根据配电网计算实际应用允许变动的不确定性特征属性。
步骤5:多源异构数据特征属性合成。对于∀A⊂U,智能配电网多源数据融合模型框架U上的有限个mass函数m1,m1,…,mn的Dempster合成规则为
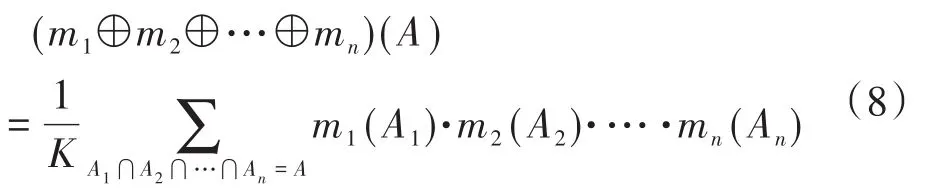
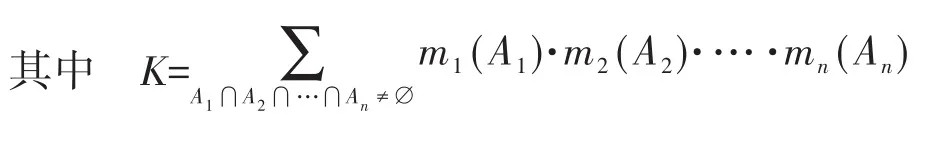
根据合成规则,利用不同源中数据特征属性索引实现特征级数据融合。
4 实验结果与分析
为验证文中所提基于边缘计算的智能配电网多源数据处理与融合技术的有效性与可靠性,以某地区配电网为例,配电网IEEE14节点仿真拓扑如图4所示。算法通过Matlab2019a实现,选取同一时间周期的配电网运行数据、终端监测数据、环境信息数据为实验多源数据,分为两个实验分别测试多源数据标准化变换处理方法,以及在数据处理的基础上进行多源数据特征级融合的可行性。
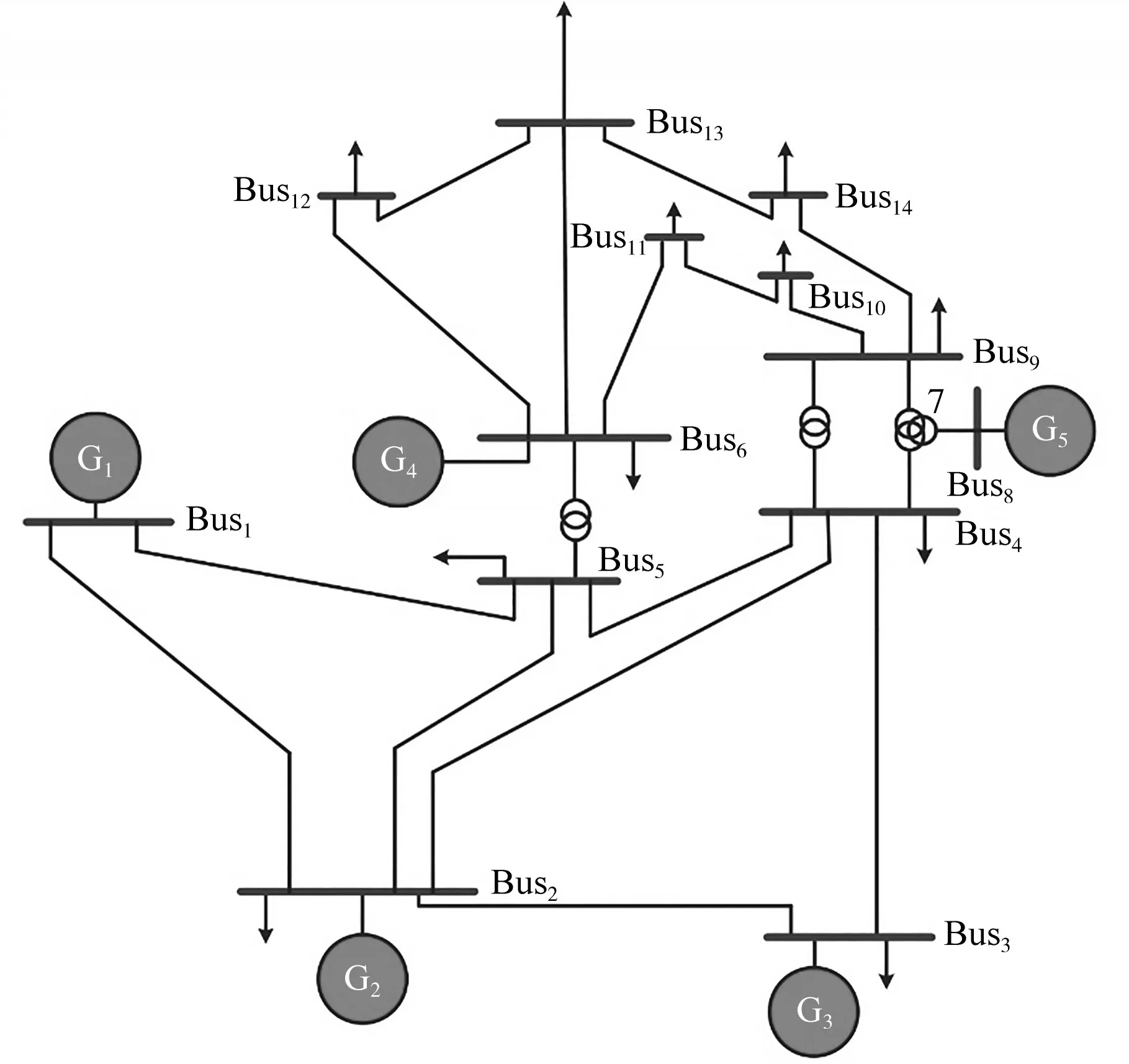
图4 配电网IEEE14节点仿真拓扑图Fig.4 Simulation topology diagram of IEEE14 nodes in distribution network
实验1:多源数据标准化变换处理。
配电网运行量测主要使用配网数据采集与监视控制系统(supervisory control and data acquisition,SCADA)数据;终端监测数据主要使用配网故障分布式系统(system of malfunction distribution,SMD)数据;有关环境信息数据使用气象网公开数据,主要包括时间点、经度、纬度、温度、风速、气压等对配电网影响显著的特征属性数据。各数据源分别从属不同数据采集系统,数据格式复杂多样、结构差异较大,极大地限制了配电网边缘化的混合计算。经多源数据标准化变换处理前后结果对比如图5、图6所示。
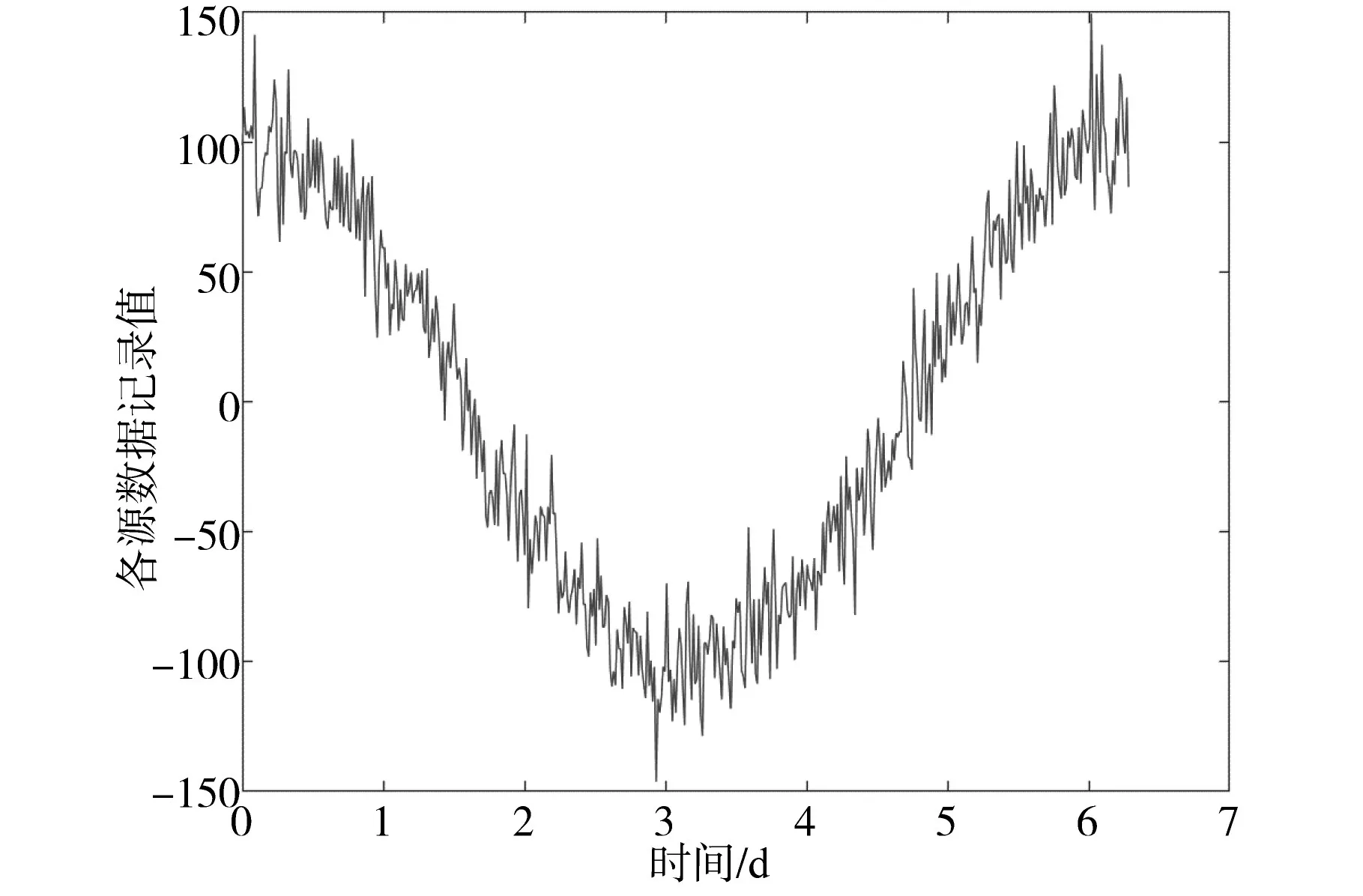
图5 多源数据处理前结果Fig.5 Results before multi-source data processing

图6 多源数据处理后结果Fig.6 Results after multi-source data processing
为了避免处理方法的偶然性,以6~11线路为例,随机抽取10条观测序号展示结果。在经本文所提基于BC-Zscore的配电网多源异构数据标准化处理方法处理后三个不同格式、量纲、数据类型以及数量级的数据源特征属性处理结果值如表1所示,单位均为标幺值。
实验表明,通过对一周内的连续原始数据进行基于BC-Zscore的多源数据标准化处理,该方法有效实现了对各数据源特征属性的格式、量纲、数据类型以及数量级的统一变换处理,通过表1实验结果可以看出,各数据源特征属性变换后每个元素的绝对值取值均在0~1之间,明显消除了多种不一致因素产生的限制,为后续的智能配电网边缘化数据融合计算和信息挖掘奠定了基础,保证了配电网的稳定计算控制和重要信息的深度挖掘。
实验2:多源数据融合。
智能配电网各种高级应用计算均建立在多源数据融合计算的基础上,利用多源数据处理结果,围绕配电网自然灾害故障信息诊断与挖掘这一实际应用场景需求,进行数据的特征级融合。以运行数据源、终端监测数据源、环境信息数据源为对象,结合应用场景需求分析多源信息构成及关键特征属性,各数据源在故障信息诊断与挖掘中融合占比图如图7所示。
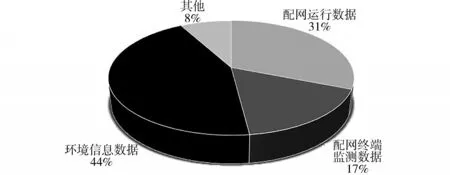
图7 多源异构数据源融合占比Fig.7 Proportion of multi-source heterogeneous data source fusion
根据多源异构数据特征属性合成规则,对多源数据进行分类组合与融合,数据融合过程中不同信任函数值与似然函数值下信任区间变化如图8所示,寻找最佳数据融合点,保证稳定度的前提下尽可能多的融合不确定特征属性。
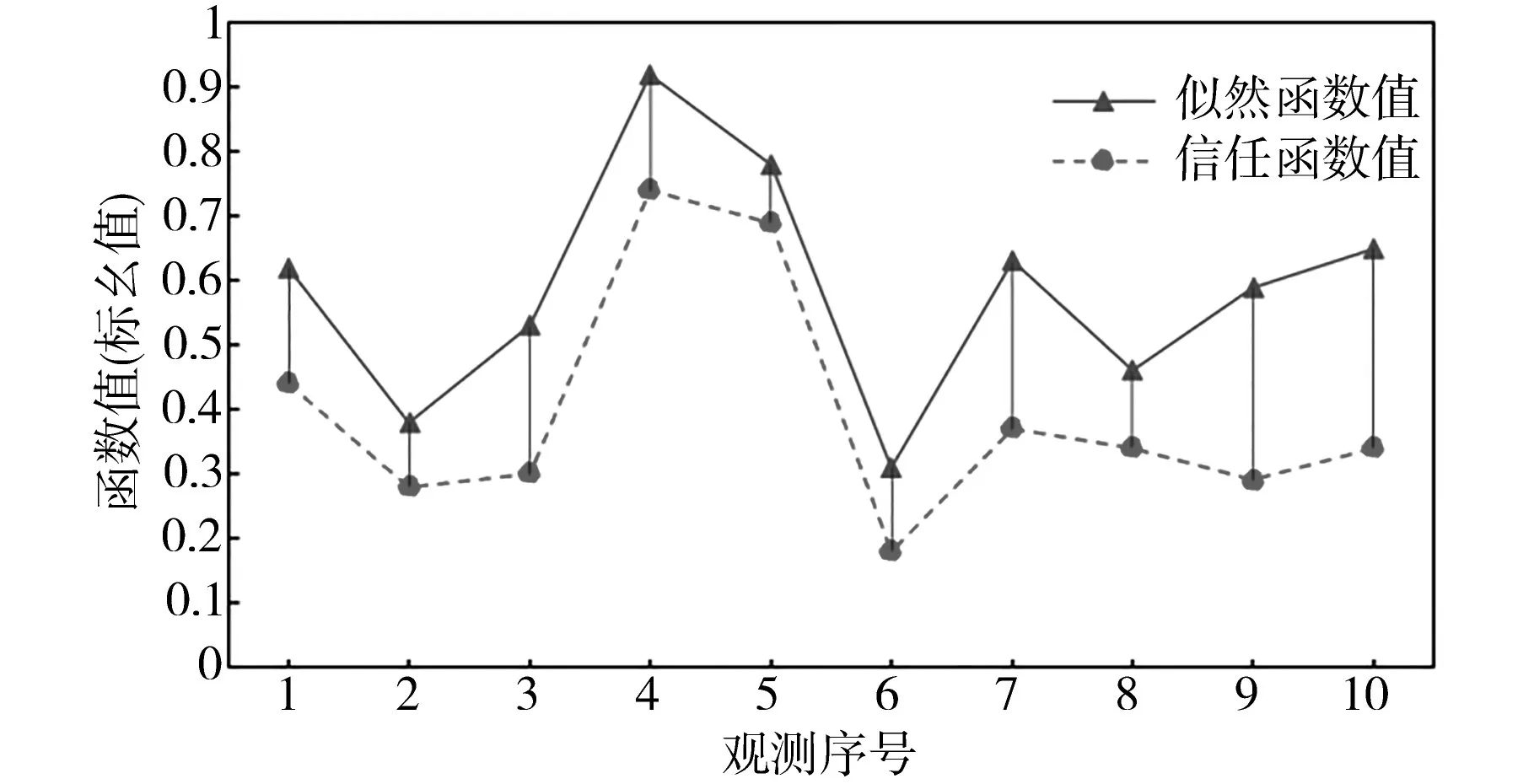
图8 数据融合过程中的信任区间变化Fig.8 Change of confidence interval during data fusion
为了验证文中提出PCA-DS推理的多源数据融合结果在后期配电网自然灾害故障信息诊断与挖掘的高准确性。对一周内经BC-Zscore多源数据处理后的实验结果值分别采用DS推理法、BP神经网络与DS推理法结合算法(BPNN-DS)及文中算法(PCA-DS),三种算法进行融合效果对比实验,三种实验融合结果在后期诊断分析中准确率变化如图9所示。
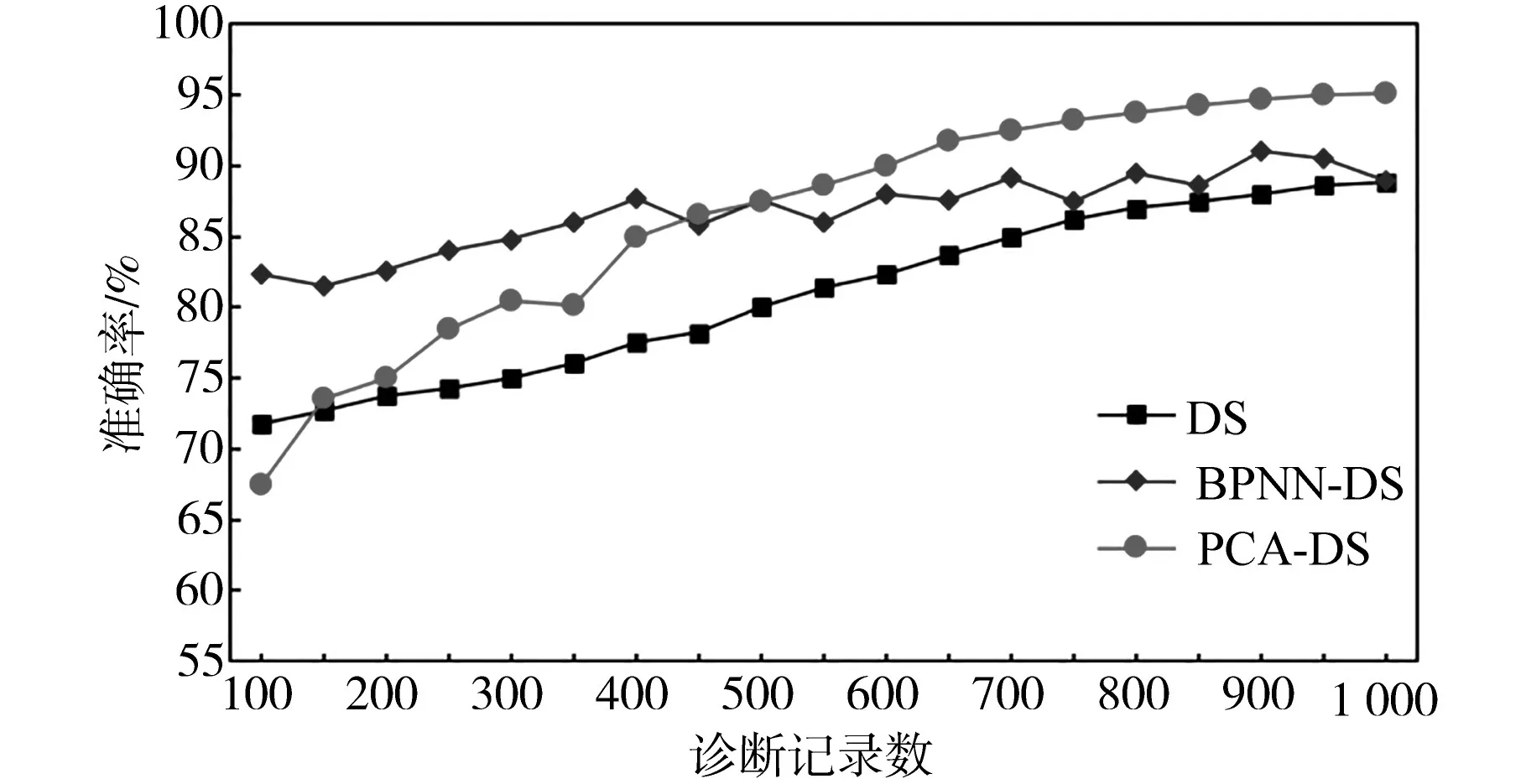
图9 三种算法结果值在后期诊断分析中的准确率对比Fig.9 Comparison of the accuracy of the results of the three algorithms in the later diagnosis analysis
由图9实验结果可知,基于PCA-DS推理的多源数据融合模型有效地实现了从数据源头、特征属性等不同角度出发,对多源异构数据进行分组聚合。根据融合过程中信任区间的收缩变化,提高了多源数据分布特征的拟合精度。同时,通过考虑多源数据融合的配电网自然灾害故障信息诊断与挖掘对比结果可以看出,文中利用定义成分可信度函数约束DS推理过程中不确定特征属性融合,大幅提高了DS推理在多源数据融合中的稳定性和准确性,而且有效融合方法下的多源信息合成进行配电网场景应用分析计算结果值明显优于仅考虑单一或少量因素的传统方法。
5 结论
文中提出了一种基于边缘计算的智能配电网多源数据处理与融合技术,该技术的提出在一定程度上加快了边缘计算技术在智能配电网中的应用,同时又为配电网后续的高级计算和应用决策分析提供了保障。通过深入分析配电网智能化建设过程中海量异构数据造成的存储混乱与融合计算性能不足的问题,设计了一种充分考虑边缘计算模式下的配用电数据处理与融合架构,其中的广义幂变换Zscore多源数据变换处理方法,有效地实现了多种配电网数据采集系统下量纲与量级的统一;基于冲突优化DS推理的数据融合模型,根据智能配电网高级应用场景需求预先实现了高精度的特征级配用电数据融合,进一步为配电网边缘智能化计算和高级应用奠定了基础,满足了智能配电网在运行状态评估、故障信息诊断挖掘、突发事件数据可信度识别等高级应用中高可靠性的需求。
