基于多尺度融合方法的无人机对地车辆目标检测算法研究
2021-12-29张立国蒋轶轩田广军
张立国,蒋轶轩,田广军
(燕山大学电气工程学院,河北秦皇岛066004)
1 引 言
对地车辆目标检测,在传统检测算法中,占据主导地位的是基于人工特征提取的方法。人工特征提取方法中需要选取感兴趣区域并使用滑动窗口选出候选区、手动提取特征然后分类[1]。如Papageorgiou提出了一种在复杂场景的图像中进行目标检测的通用可训练模型,其不依赖任何先验模型,在此基础上提出了基于运动的扩展,提高了性能[2]。但是很显然,手动提取依赖经验且提取特征的好坏将会直接影响检测结果,而基于深度学习的方法具有不需要人工提取特征,灵活多变,可在精确率与速度之间进行权衡等优点[3]。随着硬件技术的发展,被越来越多的研究者使用。如使用TensorFlow构建Faster R-CNN,提高了检测的精确度与速度;将Faster R-CNN与ZF、VGG16结合,改善了模型的鲁棒性;基于轻量化SSD的LVP-DN模型,实现了检测速度极大提高。但这些算法为特定场景研发的,侧重点有所不同,难以将其应用到无人机图像对地车辆检测中使用。其中突出的问题就是无人机图像目标尺寸相较于整个图像较小,而且极易出现多物体重叠,造成了检测错误,效果不甚理想。因此,提出了基于多尺度融合的图像多目标检测方法,以Faster R-CNN为基本框架,卷积层使用VGG16,将卷积层中不同尺寸的特征信息依次结合生成融合层,在这一过程中,需要来自卷积层和前一层的特征信息所需的特征图像尺寸及通道数保持一致并分别使用不同的网络模块对其进行处理。再将新得到的特征图结合上下文信息,对其使用RNN算法,提高对车辆目标的检测效率。
本文实验所用到的数据集是VisDrone2019数据集。在实验部分,对算法的性能参数进行测试,并使用了Faster R-CNN和YOLO与改进后的算法进行比较,以综合比较模型的性能。
2 基于Faster R-CNN的多尺度融合算法
2.1 Faster R-CNN
在Faster R-CNN算法中,大致可以分为4个步骤:卷积层网络提取特征;区域候选框网络生成候选区域;感兴趣区域池化层将特征图输出为统一大小;候选区域分类和回归[4]。其流程图如图1所示。
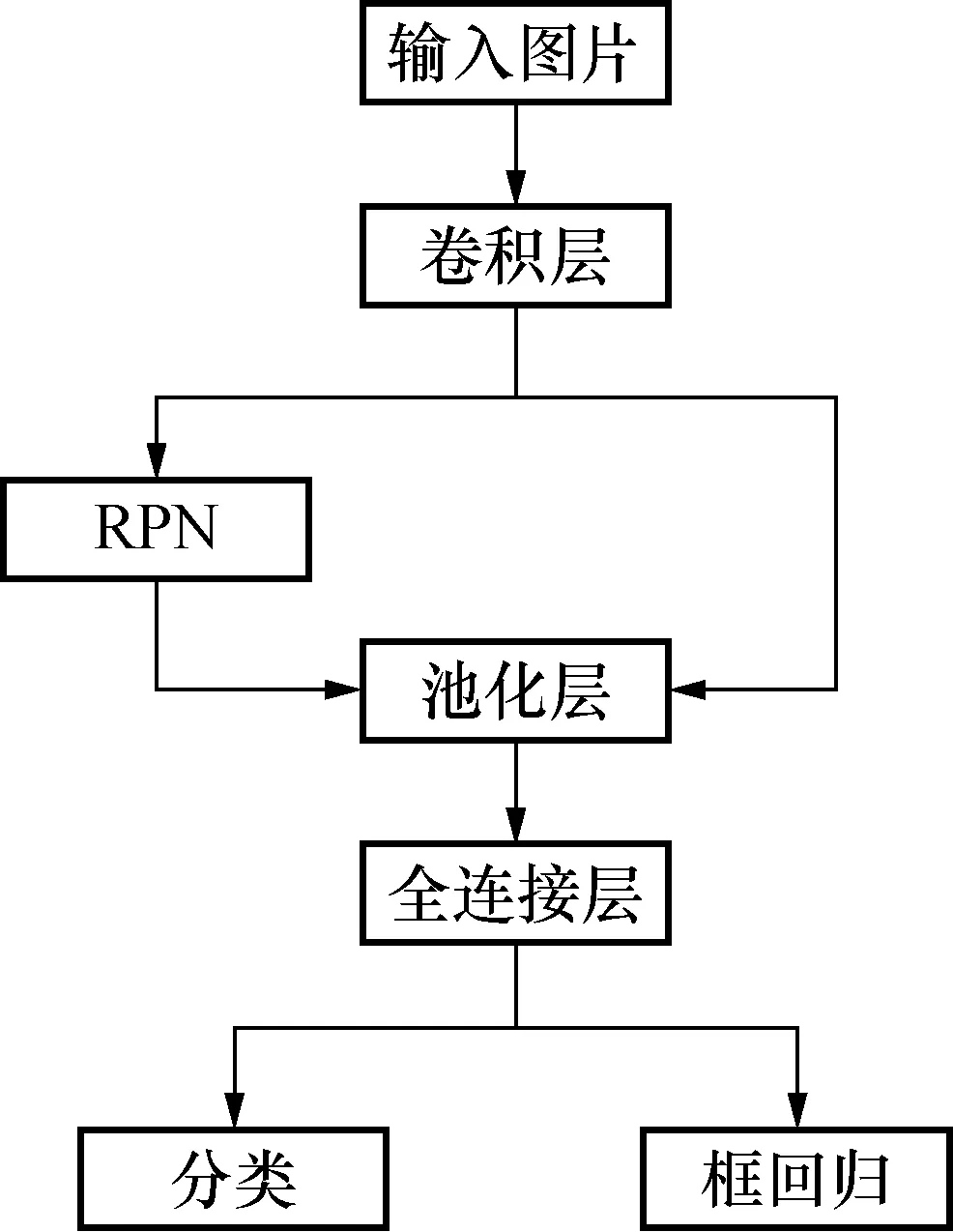
图1 Faster R-CNN流程图Fig.1 Faster R-CNN flowchart
特征提取的卷积层网络的种类有很多种,常见的有VGG16、ResNet网络等,在本文中VGG16选用网络进行特征提取[5]。其结构简单,可以通过构建多层次的网络结构来提升特征提取的能力。VGG16使用的是3*3的卷积核以及2*2的最大池化。将输入图像进行一系列的卷积、池化后,得到相应的特征图,然后将特征图送入区域候选框网络(RPN,region proposal network)。
RPN的作用是生成大小不一的候选框[6]。在Faster R-CNN之前,基于区域的two-stage目标识别算法普遍采用Selective Search提取候选框,非常浪费时间。为此,Faster R-CNN使用区域候选框网络代替Selective Search,并引入了锚框机制(anchor)[7]。即在特征图上的每个位置,生成不同大小与尺寸的锚框。
经过RPN网络后,模型生成了大小不一的候选区,由于在模型后面要使用到全连接层,要求统一输入大小,Faster R-CNN设计了感兴趣区域池化层。对于输入的特征图,根据自身尺寸大小分为固定的几个部分[8]。对每个部分取最大值,从而将特征图输出为固定尺寸。
经过感兴趣池化层后,得到的特征图送入全连接层,输出每个候选框对应各类别的置信度,并利用边框回归得到每个候选框的相对于实际位置的偏移,得到更贴近实际的检测框。
2.2 多尺度融合
本文以Faster R-CNN为基础进行改进。输入图片经过卷积层的时候,会经过多次卷积、池化、激活等操作,因此可以得出不同层次不同空间分辨率的特征信息[9]。在Faster R-CNN中,只利用最后的特征信息进行RPN操作以及分类回归[10]。但是在经过VGG16后,此时的特征图中小目标的语义信息几乎消失,造成了对小目标检测的难度较大。但如果使用较低层次的特征图进行计算,其低水平的特征显然会损害模型的目标检测能力。
因此,本文利用卷积层所产生的、不同层次的特征信息,将其结合后得到新的特征图像进行目标检测。为实现这一目标,需要对算法模型进行改进,将不同层次的特征信息融合。用融合后的特征信息代替最后一层特征信息,达到对小目标的精确检测。与此同时,模型最大限度地使用Faster R-CNN框架,仅对其进行部分改进,减小对速度的影响和对内存的消耗。
改进后的模型框架如图2所示。其中,使用卷积操作是为了提取特征,这是深度学习常用的提取特征的方法;使用激活操作为网络加入非线性因素,使其能解决非线性问题,使用的激活函数是RELU激活函数;使用池化操作是为了降低计算的规模并且防止过拟合,使用的池化方法是最大值池化,步长被设置为2[11]。由图2可知,经过卷积神经网络,可以获取不同尺度的特征信息。而多尺度融合就是将不同尺度的特征信息进行融合,获取新的特征图取代卷积层的最后一层特征信息。
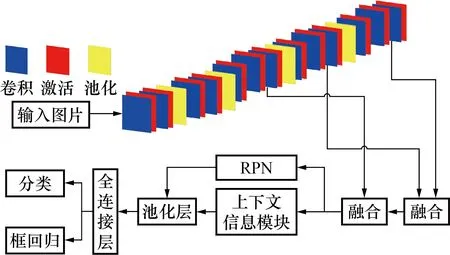
图2 多尺度融合的Faster R-CNN网络框架Fig.2 Multi-scale fusion Faster R-CNN network framework
在以往的算法中,只用到了最后一层特征图,而在本算法中选取了卷积层中最后3个阶段的特征。之所以没有选取更前层次的特征图,主要考虑到使用浅层特征会占用大量内存,不利于检测速度。并且选择每个阶段最后的输出(既经过池化层前的最后一个卷积层)作为所使用的特征信息。这样选的好处是选取的特征信息是每个阶段最好的特征。首先将最后1层得到的特征图与倒数第2层的特征图进行融合,然后将新得到的与倒数第3层的特征图进行融合,这样得到的就是多尺度融合的特征图。
融合层的生成方式如图3所示,其中1*1代表对特征图进行1*1的卷积,3*3代表对特征图进行3*3的卷积,2*代表对其进行2倍上采样。融合模块有2个输入,对从前一层得到的特征信息先进行3*3的卷积操作,再进行2倍上采样以得到更大的特征图以便融合。而对于从上而下的特征图要经过一个1*1的卷积操作,以调整通道数。

图3 特征融合模块Fig.3 Feature fusion module
在将不同层次的特征图融合时,前提条件就是各层的特征图像在融合前要大小一致且通道数一致[12]。因此在特征融合模块需要对输入进行调整,从而实现特征图像的统一化,得到最后的特征图。在特征图经过结合上下文信息的模块后,送入感兴趣区域池化层(ROI)并进行分类和回归。多尺度融合的意义在于在深层特征语义更强也更抽象,因此对分类有益;浅层特征则有利于小目标的检测。将其结合,可以在一定程度上提高中小尺度目标检测精度。
3 上下文信息
在图2中可以看到,在完成了多尺度信息的融合之后,并没有直接使用特征信息进行目标检测。为了进一步提高模型的检测能力,决定采用结合上下文信息的方法,获取周边信息,实现对特征图充分利用以提升性能。设计了一个获取上下文信息的模块,并将2个该模块插入算法中,接收融合得到的特征图。模块如图4所示。将特征图作为输入,使用模块的4个循环卷积网络(RNN)获取不同方向(上、下、左、右)的信息。再将所有信息连接起来(concat操作),然后新得到的特征信息与输入相结合。
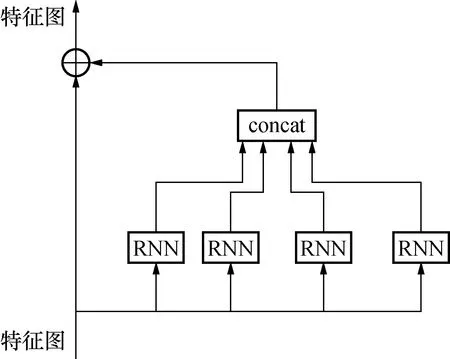
图4 模块结构Fig.4 Module structure
本文借鉴并使用了RNN算法,如图5所示,并对其进行了改进。传统的RNN网络输入和输出序列是等长,本文将多尺度融合得到的特征图像中的每一个像素点以及不同方向的像素点作为RNN的输入。以左侧为例,输出为在该点时的特征信息,进行RNN计算。在每个像素点进行RNN计算时,将左侧的像素点以及该像素点作为输入,分别为图5中的x1,x2,x3,…,而目标点为最后一个输入。将特征图通过不同方向的RNN网络,使用如图4模块结构得到特征图像。因此,每个像素点都可以获取周边的4个位置即上下左右的信息,而这4个位置又可以获取再外侧的信息,这样该像素点就得到以该点为中心的十字感受野。在第2次的过程中,因为每个像素点都获取了十字感受野,即得到了全图信息。这样就使特征图的每个点都兼顾了上下文信息,从而得到对无人机图像更好的检测能力。

图5 RNN结构Fig.5 RNN structure
图5中,h与y的计算公式如式(1)和式(2)所示。对于RNN计算,参数保持不变[13]。如在计算不同的h时,U,W,b都保持不变。
h1=f(Ux1+Wh0+b)
(1)
y=f(Vh4+C)
(2)
式中:f为激活函数;U,W为参数矩阵;b为偏置量参数,计算y时的激活函数与计算h时的不一定相同,V与C作用类似于W和b。
4 实验结果及分析
4.1 检测标准
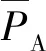
(3)
式中:PT为被正确识别的正样本;NT为被正确识别的负样本。召回率表示所有正样本当中,被正确识别为正样本的比例[15]。
(4)
式中:P为在验证集上所有的图像对于该类的精度值;n为存在该类目标的所有图像的数量。
(5)
式中i为具体第i个类。
4.2 实验设置
本文使用的硬件设备是NVIDIA的Jetson TX2,配置环境是:Ubuntu+Python2+Tensorflow1.2+CV2+CUDA8.0。端到端开源机器学习平台使用TensorFlow,其拥有完善的文档,丰富的算法库,灵活的移植性以及多语言支持[16]。使用的数据集为VisDrone2019数据集,该数据集由无人机拍摄图像组成,涵盖了广泛的范围,可以检测多种物体,包括行人、车辆、船只等[17]。本文针对车辆目标进行检测,需要对图片进行重新标注。由于卷积训练需要大量的数据,因此为了增加样本的数据,对图像进行仿射变换,包括平移、旋转等。得到包含各类车辆的图片一共大约8 000张作为训练数据集,对车辆进行标注,并划分为4类:小型轿车、卡车、公交车、工程车。数据集部分图片如图6所示。

图6 VisDrone2019数据集部分图片Fig.6 Partial picture of VisDrone2019 dataset
图6中,8 000张图片分为5 600张训练集、1 600张验证集以及800张测试集。学习率初始值为0.001,batch size大小设定为64。
4.3 实验结果
在进行实验的过程中,需要对模型进行训练和测试。图7是模型的各个损失函数,横坐标为迭代次数,纵坐标分别为RPN网络分类损失函数、RPN网络定位损失函数、候选区域分类与回归过程分类损失函数、候选区域分类与回归过程定位损失函数、总损失函数。
图7中,图7(a)和图7(b)表示RPN网络的分类损失函数和定位损失函数随迭代次数的变化;图7(c)和图7(d)表示在候选区域分类和回归过程中的分类损失函数和定位损失函数随迭代次数的变化;图7(e)则表示模型的总损失函数,即前4幅图之和。在实际操作过程中,最常用就是模型的总损失函数。如果经过训练总损失函数较低且平滑稳定时,就代表模型性能较好;反之如果经过训练总损失函数无法降低或者起伏较大,则说明模型有待优化。通过图像可知,当训练次数达到40 000左右时,各参数变化基本稳定,表明改进的网络能够很好的收敛。
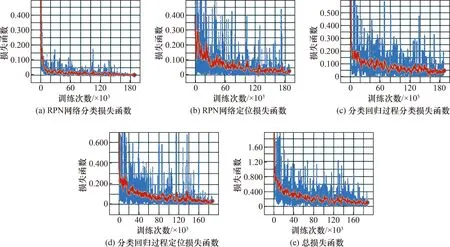
图7 训练模型损失值Fig.7 Training model loss
本文分别对改进的算法、Faster R-CNN以及YOLO v3在Jetson TX2进行检测。一般来说,Faster R-CNN的检测效果要好于YOLO v3(这一点在实际检测中也有体现)。因此仅在图8中,给出了改进的算法与Faster R-CNN对数据集中部分图片的检测结果。从图8可以看出,左侧的采用Faster R-CNN算法的2幅图中都出现了漏检的情况。可以直观地感觉出相较于Faster R-CNN,改进的算法对于无人机图像中中小型目标的检测效果更好。

图8 改进的算法与Faster R-CNN部分图片检测结果Fig.8 Improved algorithm and Faster R-CNN partial image detection results
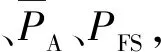

表1 不同模型的检测评价指标Tab.1 Detection and evaluation indicators of different models
同时也要看到由于实验平台的硬件性能限制,3种算法的PFS都较低,即使是速度较快的YOLO v3的PFS也仅为19帧/s。而改进算法的PFS为4.5帧/s,相比于Faster R-CNN还要低。但由于本文所要研究的无人机对地车辆检测更倾向于精确度,改进算法的PFS足以满足实际需要。因此,综合考虑各种因素,可以看出本文所提出的模型在无人机目标检测中更具有优势。
在对不同车辆类型实验中,得到4种类型的PA值,如表2所示。
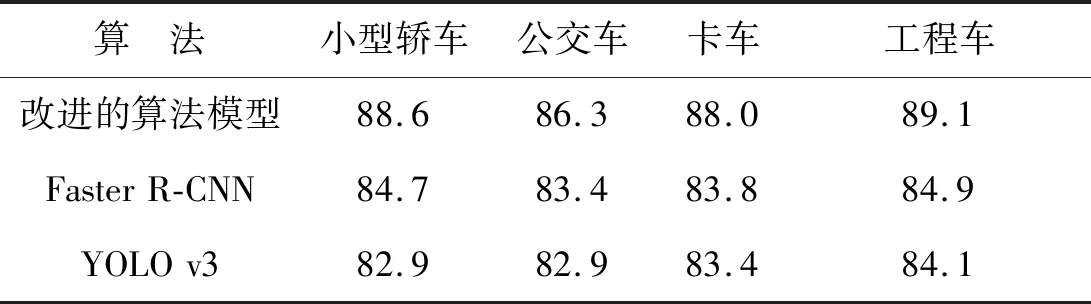
表2 不同模型对于不同类别的平均精确度Tab.2 Average accuracy of different models for different categories (%)
在表2中可以看到,在不同的类别当中,改进的算法模型都取得了最好的检测效果。例如,在对于小型轿车的检测当中,平均检测精度提高了至少1.9%。同时可以看出上面四个类别中,工程车的平均精确度最高,公交车的平均精确度最低。工程车的检测精度好于其他几类的原因可能是工程车在外形上与其他类有较大的差别。
5 结 论
