基于改进一维卷积神经网络的多轴工业机器人故障诊断*
2021-12-29潘屹豪周玉彬姜文超贺忠堂
潘屹豪,肖 红,周玉彬,黎 萍,姜文超,,熊 梦,贺忠堂
(1.广东工业大学计算机学院,广州 510006;2.东莞中国科学院云计算产业技术创新与育成中心,广东 东莞 523808)
0 引言
工业机器人故障自动诊断与预警是自动化生产过程顺利开展的关键和难点,目前少有基于工业机器人运行大数据的深度学习故障诊断方法。当工业机器人发生故障时,其定位精度、产品质量都会发生较大幅度下降,意外停机时会带来巨大经济损失。因此,开发有效的故障诊断方法来监测多轴工业机器人工作状态显得尤为重要。
Brambilla D等[1]提出一种基于模型的机器人故障诊断方法,该方法通过广义观测器(GOS)方案来检测传感器故障。然而,现实中机器人状态在实践中难以估计,因此基于模型的机器人故障诊断通常较难使用。
近年来,在故障诊断领域出现了越来越多数据驱动的故障检测方法。Kim Y等[2]提出一种基于相位的时域平均(PTDA)方法,然而该方法仅限于恒定速度范围并且在实际工业领域中获取振动数据并不容易。
基于浅层学习的神经网络故障诊断技术的诊断性能很大程度上取决于提取的故障特征是否准确。此外,故障诊断过程中,数据处理、特征提取、特征选择和模型训练4个阶段无法同时进行优化。因此,使用原始信号数据进行故障诊断更具有可用性。随着机器人故障诊断的重要性被逐渐认识,陆续出现许多基于卷积神经网络(CNN)的故障诊断模型[3-8]。但是这些模型很少使用机器人控制器原始数据进行分析,也缺乏针对工业机器人故障特点的优化及实际验证。
多轴工业机器人一旦某个机械轴发生故障,会连带影响到其他轴的运行数据状态。因此,多轴工业机器人故障诊断必须综合各个轴的数据来整体判断。现有故障诊断方法通常基于单一器件分析,没有综合机器人整体运行情况与数据,难以直接应用到工业机器人故障诊断。本文针对工业机器人故障诊断问题,提出一种新的基于一维卷积神经网络(CNN-1D)和正交正则化[9](SRIP)相结合的工业机器人故障诊断方法(SRIPCNN-1D)。首先通过随机采样和Mixup对工业机器人故障数据进行增强;然后采用正交正则化(SRIP)一维卷积神经网络(CNN-1D)将工业机器人原始运行数据进行端到端训练;最后利用训练后的模型对工业机器人进行快速故障诊断。通过实验测试并与WDCNN,CNN-1D模型进行实验对比,结果表明SRIPCNN-1D 方法可以有效诊断工业机器人故障。
1 多轴机器人故障诊断模型
1.1 故障诊断模型结构
基于改进的一维卷积神经网络故障诊断模型结构如图1所示。模型包括连续两个卷积层、一个最大池化层、一个全局池化层、一个softmax层。模型输入维度为工业机器人运行数据的实际维度,输出维度为机器故障类别数。权重正交性是训练卷积神经网络的有利属性,模型将SRIP正交正则化器应用在卷积层,提升模型的精度与收敛稳定性。
CNN是具有交替卷积和子采样层的前馈人工神经网络(ANN)。典型的CNN包括输入层,卷积层,池化层,完全连接层和输出层。
在卷积层,卷积内核对上一层的输出执行卷积,卷积层用一定数量的滤波器获得输入特征,每层的输出是多个输入特征的卷积结果,其数学模型描述为[10-11]:
(1)

卷积运算后,激活函数将对每个卷积中的对数值输出进行非线性变换。鉴于工业机器人数据的非结构性,采用ReLU功能作为激活功能。分段函数ReLU表示为:
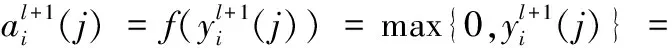
(2)
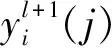
为减少神经网络参数,池化层通过数据下采样将大矩阵下采样为小矩阵。采用的池化方法有最大池化和平均池化[12-13],其表达式分别为:
(3)
(4)
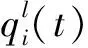
全连接层将最后一个池化层的输出扩展为一维向量,该向量用作全连接层的输入,然后在输入和输出之间建立完整连接[14]。全连接层的公式为:
(5)
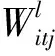
输出层使用softmax分类器创建分类标签。softmax分类器是常见的线性分类器,它是从逻辑回归中得出的多类分类的一种形式[15]:
(6)
其中,zo(j)表示输出层第j个神经元输出的对数;M表示类别的总数。
为解决训练过程中可能出现的梯度消失/爆炸、统计特征偏移、鞍点的扩散等问题。通过数据正则化对网络层参数加以限制,减少过拟合现象产生,引入SRIP正交正则化,提升模型效果,获得较高的诊断精度。假定全连接层W∈m×n,对于卷积层C∈S×H×C×M,其中,S、H、C、M分别为滤波器宽度、滤波器高度、输入通道数和输出通道数,将C整型为矩阵形式:W′∈m′×n′,其中,m′=S×H×C,n′=M,正则化卷积层在整个滤波器上实现正交性,促进滤波器的多样性。
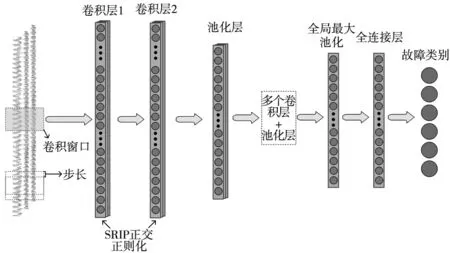
图1 SRIPCNN-1D网络模型结构示意图
1.2 数据增强
在大多数故障诊断数据集中,各个类别的样本数量不易平衡,获取故障样本要比获取正常样本难得多,这会导致模型对样本个数少的故障类型诊断效果较差。为解决CNN 训练过程中的过拟合问题,采用基于Mixup的数据增强方法对随机采样[16]数据处理,构建虚拟训练样本,提升模型的泛化能力。具体步骤分为随机采样和Mixup两步。
(1)随机采样
在随机采样方法基础上加入随机采样点,无需设置偏移量,一方面优化了训练样本的覆盖性,另一方面使得前后样本之间有更好的独立性。随机采样算法步骤如表1所示,采样原理如图2所示,假设原始序列有M个采样点,L为样本长度,理论上最多可生成M-L个随机采样点。

表1 随机采样算法步骤
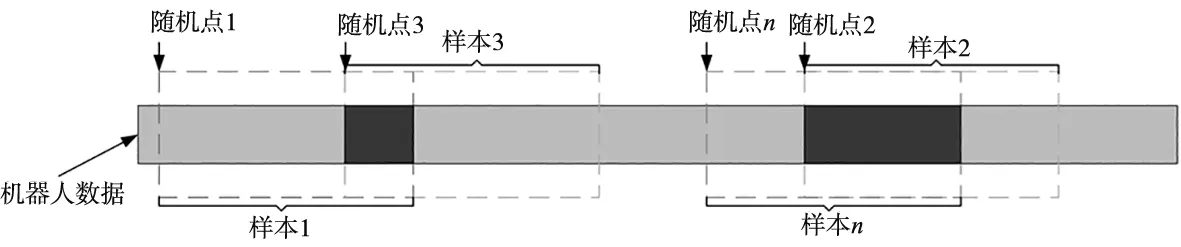
图2 随机采样示意图
通过设置较大样本数n,随机采样方法可以极大扩充输入样本量,缓解训练样本匮乏、类别不平衡以及过拟合问题。
(2) Mixup
对于工业机器人故障检测的一维数据使用数据无关的数据增强方式Mixup。通过构建虚拟训练样本来提高模型的泛化能力。Mixup数据增强方法可表示为:
(7)
(8)
其中,(xi,yi)和(xj,yj)是训练集中任意抽取的两个样本;λ为混合系数,λ∈[0,1];λ~Beat(α,α),α∈(0,∞)。Mixup通过混合特征向量及其对应标签实现线性插值。可通过超参数α的值来控制特征向量和标签的插值强度。
1.3 机器人故障诊断流程
基于SRIPCNN-1D模型的工业机器人实时故障诊断流程如图3所示。故障诊断流程分为3步,具体步骤如下:
(1)数据预处理阶段:通过机器人运行数据采集平台获取机器人实时运行数据,将数据进行清洗及归一化,然后使用数据增强方法进行数据扩充,并将数据集划分为训练集、验证集和测试集3部分。
(2)模型训练阶段:建立SRIPCNN-1D故障诊断模型,使用正交初始化避免梯度爆炸/消失现象。使用网格搜索算法优化模型的超参数。SRIPCNN-1D网络模型激活函数为ReLU,使用全局最大池化实现降维。采用Softmax分类器实现对目标类别的分类输出。模型的损失函数为交叉熵损失函数:
(9)
其中,M是类别的数量,yic为指示变量(0或1),类别和样本i的类别相同就为1,否则为0。pic为对于观测样本i属于类别c的预测概率。
(3)模型测试阶段:将验证数据输入训练好的最佳模型,验证机器人故障诊断模型效果。
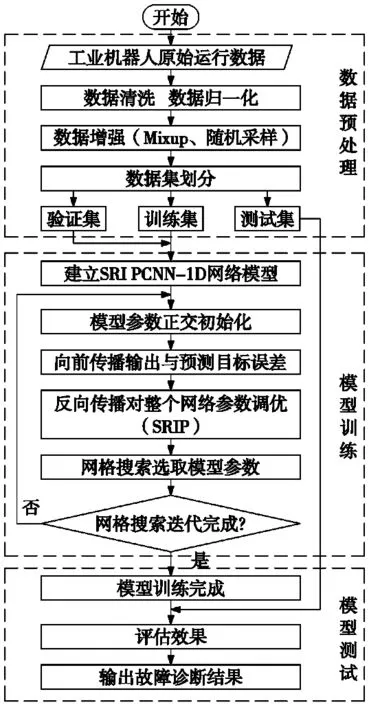
图3 工业机器人故障诊断模型流程
2 实验测试与分析
2.1 实验平台与数据采集
为了验证多轴工业机器人故障诊断模型(SRIPCNN-1D),利用某国产六轴工业机器人,搭建故障数据采集环境。该机器人产品主要应用于磨抛、喷涂、上下料、焊接等领域。
图4为实验采用的六轴工业机器人示意图,J1轴为机器人的旋转基座,J2轴负责臂组的水平运动,J3轴为肘部,负责机械臂的垂直运动。J4轴负责小臂的旋转运动,J5轴负责机械臂腕部运动,J6轴负责机械臂连接工具运动,可在末端安装焊接、喷涂、打磨、抓握等工具。
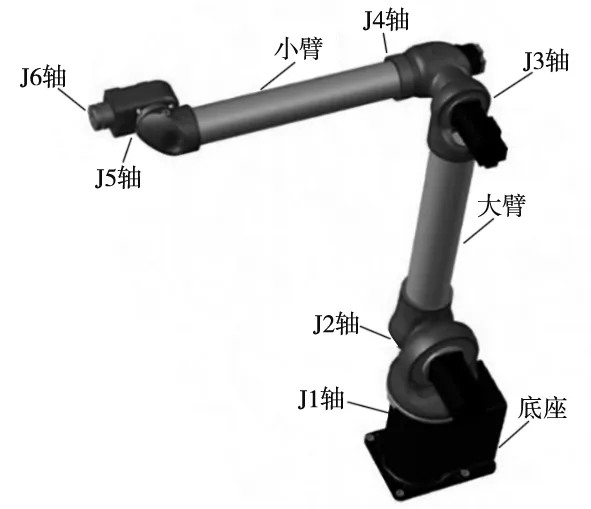
图4 六轴工业机器模型
机器人故障可以分为机器人本体故障、控制系统故障、工作系统故障、驱动系统故障等。本文实验重点关注机器人本体故障和驱动系统故障,比如:减速机故障、伺服电机故障等。
对于每台机器人,都有6个关节轴的数据,每个轴运行数据有31个特征变量,变量可分为两大类:①机器人状态数据,如参数设定、本体信息、固件版本等;②机器人实时运行数据,如:反馈力矩(tfb)、反馈电流(flow)、反馈速度(vfb)、反馈位置(pfb)等。
故障数据集包括多台正常/异常机器人数据样本,故障数据有不同轴的故障、不同部件的故障。具体故障数据如表2所示,数据样本间隔有4 ms和1 s两种,覆盖多种机器人运行程序,采集时长为120~200 h,数据通过机器人故障数据采集软件进行采集存储,共采集数据量300万条以上。进一步得到机器人反馈力矩波形图如图5所示,展示了4台同型号的工业机器人在运行相同指令、相同工况环境下的反馈力矩数据。从波形信号中可以看出,即使执行相同的程序,故障机器人和正常机器人的tfb变量也有较大不同,证明实验所采集的机器人运行数据变量进行故障诊断具有可行性。

表2 工业机器人故障数据集
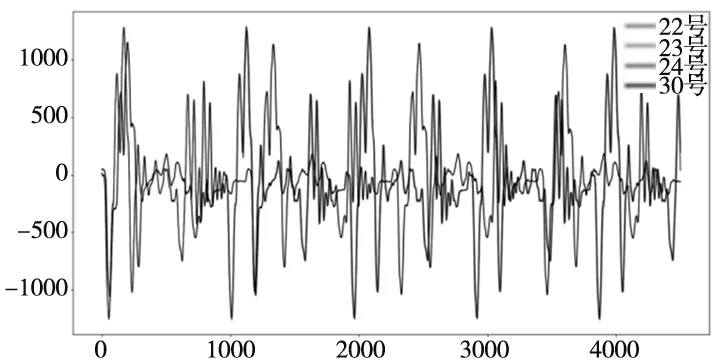
图5 反馈力矩波形图
2.2 数据增强对比分析
为了验证不同的数据增强方法对故障诊断算法的影响,分别对三种(WDCNN[16],CNN-1D,SRIPCNN-1D)故障诊断模型使用不同的数据增强方法进行测试,结果如表3所示。每类故障样本按30万条记录计算,当数据长度为2000时,仅可生成150个样本,因此在不采用数据增强时样本量很少。采用随机采样数据增强后,将样本个数扩充到20 000,极大地增加了模型的输入样本个数。

表3 多个模型分别采样不同数据增强方法的结果比较

续表
经过实验对比,从表3可以看出采用数据增强后故障诊断算法精度有明显提升,且采用随机采样+Mixup的数据增强方法效果最好。
从表3中对比发现,SRIPCNN-1D故障模型是上述所有方法中精度效果最好的。WDCNN虽然在轴承故障诊断中效果很好,被众多学者作为对比基准,但是其在工业机器人数据故障诊断领域有局限性,WDCNN为了提升滚动轴承故障诊断的精度,采用大卷积核与小卷积核相结合的方式,大卷积核提升了感受野,但是也增加了参数和计算量,而且大卷积核在提取特征方面不如多层卷积。而本文所提方法更适用于工业机器人数据故障诊断,采用两个连续的卷积核可以更好地提取工业机器人故障数据的深层特征,此种方式还可以拓展模型的感受野,并不会增加太多的求解参数。
图6为所提方法的混淆矩阵,纵坐标为实际标签,每行代表判别为该类故障和判错为其他故障类别的个数,总和为2000,即在2000个测试样本集下进行测试。横坐标为预测标签,每列表示所有样本中,被判为该类故障的个数。目前使用的故障数据集包含了工业机器人2、3、4轴的异常震动故障,根据实验结果,大多数情况下,每类故障的正确率均达到99%以上,表明SRIPCNN-1D构建的机器人故障诊断模型可以较高精度地诊断出该类故障,实现故障定位。
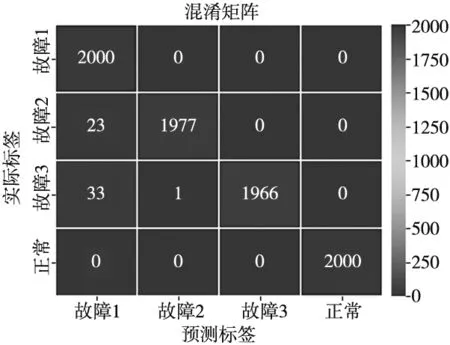
图6 混淆矩阵
2.3 结果与分析
首先验证工业机器人数据增强方法的可行性与有效性,再选取最佳的模型参数进行测试,通过与WDCNN,CNN-1D模型方法对比,评估SRIPCNN-1D的有效性。
实验采用F1-分数指标衡量模型效果。F1-分数又称为平衡F分数(balanced F Score),它被定义为精准率(Precision)和召回率(Recall)的调和平均数。F1-分数的取值为1代表模型的输出最好,0代表模型的输出结果最差。
如图2所示方法,首先将连续运行数据划分为数据段。选择2000个采样点为一个片段,并使用随机采样和Mixup方法进行数据增强。为选取最佳的网络模型参数,选取不同的卷积核尺寸、卷积核个数、迭代回合、池化方式、数据长度进行测试对比,结果如图7所示。横轴表示数据长度,纵轴代表模型的F1score评分。图7中各曲线对应的三个数值分别代表卷积核大小、卷积核数目、池化方式,如“50_100_0”代表卷积核大小为50(filtersize=50)、卷积核数目为100(filternumber=100)、池化方式为全局最大池化(GlobalMaxPooling1D)。其中,SRIPCNN-1D模型卷积层与池化层参数如表4所示。
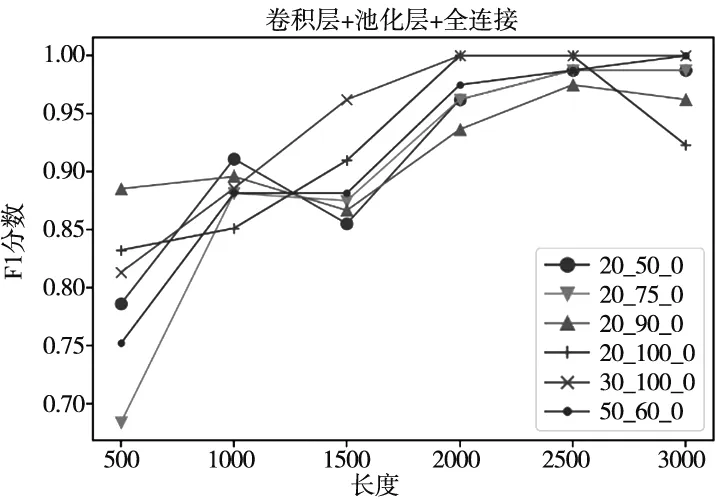
(a) 卷积层+池化层+全连接
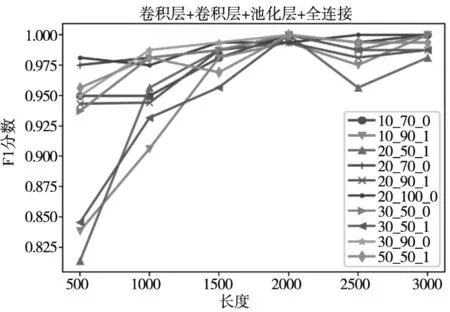
(b) 卷积层+卷积层+池化层+全连接图7 不同网络模型与参数对比

表4 SRIPCNN-1D卷积层与池化层参数
由图7可知,选取“卷积层+卷积层+池化层+全连接”为最佳模型,即两个连续的卷积层+池化层+全连接层。数据长度为2000,卷积核大小为20,卷积核数目为70,采用GlobalMaxPooling1D池化方式,最大迭代次数为50,批处理大小batch_size为100,正则化方式为SRIP正交正则化。机器人数据动作周期为500个采样点,当数据长度为2000时大约为4个动作周期。表明SRIPCNN-1D模型可以利用较少的数据进行高精度的故障诊断。
将数据长度按动作周期递增进行测试,测试数据如图8所示。按动作长度递增的数据样本精度相较于等量递增的精度略低,说明在实际故障诊断时,模型具有很好的特征提取能力,无需根据动作划分数据。
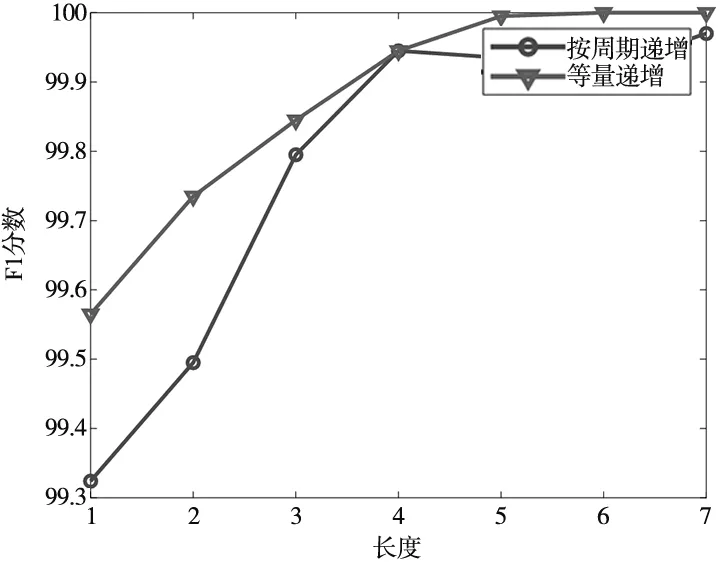
图8 不同数据长度递增方法对比
3 结论
本文提出一种基于工业机器人实时运行大数据分析的故障诊断模型SRIPCNN-1D,该模型利用随机采样和Mixup数据增强提升模型训练效果,实验平台采用某国产机器人设备,采集力矩、速度、位置、电流等运行变量数据300万条,对诊断精度指标进行实验测试,并与WDCNN,CNN-1D模型进行实验对比,结果表明SRIPCNN-1D 方法可以有效诊断工业机器人故障。SRIPCNN-1D故障诊断模型为工业机器人实时故障诊断提供了新的思路。
