基于机器学习的中文数据库自然语言检索系统
2021-12-28保海军
保海军
(青海民族大学 计算机学院,青海 西宁 810007)
自从自然语言进入计算机检索系统以来,就因其不受不同职业、不同知识背景、不同检索经验的影响等特点受到终端用户的青睐,由于中文文献的标题是中文文献内容的集中体现,它反映了文献的中心思想,因此需要进行中文数据库自然语言检索.随着数据库信息处理技术的发展,结合对中文数据库自然语言参数分析,建立中文数据库自然语言检索的特征分析模型.再结合大数据信息处理技术,实现中文数据库自然语言检索.最后结合对中文数据库自然语言参数分析,通过中文数据库自然语言参数分布式融合处理,实现中文数据库自然语言检索,研究中文数据库自然语言检索系统设计方法,对提高中文数据库的整合和检索能力方面具有重要意义[1].
当前,对中文数据库自然语言检索建立在嵌入式Linux平台中,采用交叉组件控制,构建中文数据库自然语言检索的系统分析模型,结合对中文数据库自然语言的信息采集和融合处理,实现中文数据库自然语言的交叉融合控制[2].在传统方法中,对中文数据库自然语言的检索方法主要有基于融合聚类的中文数据库自然语言检索方法和基于模糊度聚类的中文数据库自然语言检索方法等[3],建立中文数据库自然语言检索的交叉总线控制模型,文献[4]提出基于混沌序列的中文数据库自然语言分组检索方法,结合混沌加密算法,构建中文数据库自然语言分组检测模型,实现数据库检索.文献[5]提出基于随机线性密钥重置的中文数据库自然语言分组检索方法,采用向量量化分解和融合编码方法进行中文数据库自然语言匹配检索.
但是,上述两种方法进行中文数据库自然语言检索的效果不理想,本文提出基于机器学习的中文数据库自然语言检索系统设计方法.首先采用字典存储机制构建中文数据库自然语言的优化分布结构模型,结合对中文数据库自然语言的存储结构分析,然后通过模糊度匹配和机器学习算法,实现对中文数据库自然语言检索过程中的优化分类和模糊度语义特征分析,采用机器学习算法,实现对中文数据库自然语言检索过程中的迭代融合和自适应控制.最后进行仿真测试分析,展示了本文方法在提高中文数据库自然语言检索查准性能方面的优越性能.
1 中文数据库自然语言存储结构模型和大数据特征分析
1.1 中文数据库自然语言存储结构模型
为了实现基于机器学习的中文数据库自然语言检索的系统设计,先结合双向参考控制和模糊度检索的方法,构建中文数据库自然语言检索的分块组合控制模型.再结合语义相似度融合和数据库自然语言快速检索方法,建立中文数据库自然语言检索的信息处理终端.最后采用专家系统识别方法,实现对中文数据库自然语言检索的语义检测和数据综合管理[6],得到中文数据库自然语言检索的总体结构模型,如图1所示.
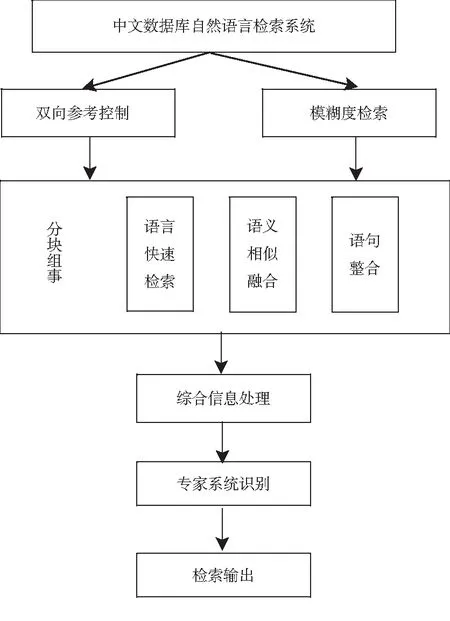
图1 中文数据库自然语言检索的总体结构
用嵌入式的B/S构架方法,进行中文数据库自然语言检索系统的程序控制,结合字典序排序存储机制,构建中文数据库自然语言检索的优化存储结构模型[7].中文数据库自然语言的存储节点分布如图2所示.
根据图2的中文数据库自然语言的存储节点分布可知,每一个存储节点均与其他4个节点相连接,说明节点的存储性能较高,处理效果较好.基于数据存储和分布式聚类[8],得到中文数据库自然语言检索的规则集,如图3所示.
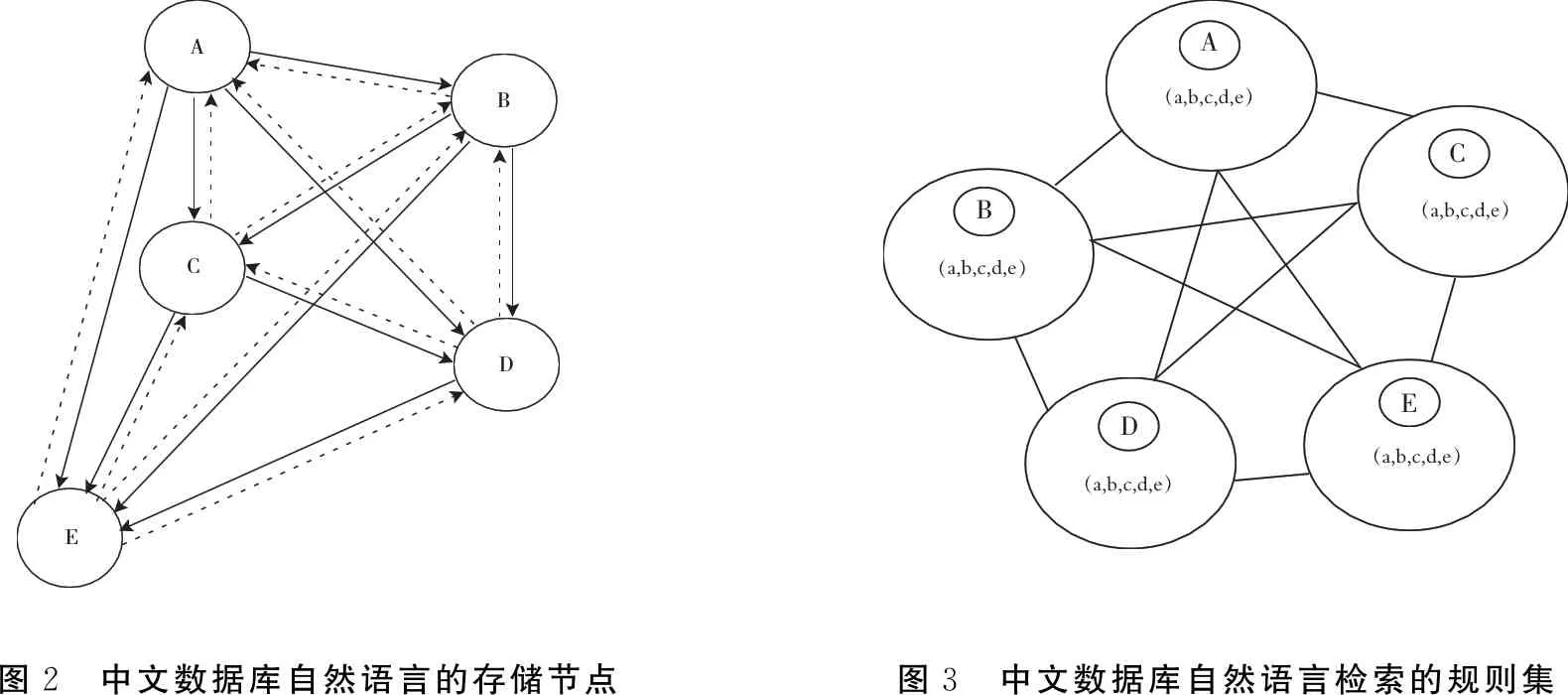
AEBDCABCDE(a,b,c,d,e)(a,b,c,d,e)(a,b,c,d,e)(a,b,c,d,e)(a,b,c,d,e)图2 中文数据库自然语言的存储节点图3 中文数据库自然语言检索的规则集
根据上述图3可知,中文数据库自然语言检索的规则集呈五角星分布,五个节点相互连接,连接性能较强.根据中文数据库自然语言的存储节点和规则集分布设计,构建中文数据库自然语言检索系统结构模型.
1.2 中文数据库自然语言检索数据融合
采用字典存储机制构建中文数据库自然语言的优化分布结构模型,结合对中文数据库自然语言的存储结构分析,通过模糊度匹配和机器学习算法,得到中文数据库自然语言分布阶数为r,在会话组件中,构建中文数据库自然语言检索的会话协议[9],得到在检索模式ks引导下,得到中文数据库自然语言检索的关联特征分布集为
(1)
其中,t(t1,t2,t3)为模糊综合聚类的维数,z为中文数据库自然语言检索样本长度,m为采样样本序列,使用Observer协处理器构建中文数据库自然语言检索的匹配模型,对文件OT采用语义度分析,得到中文数据库自然语言检索的元素组合参数F(xt),当满足
(2)
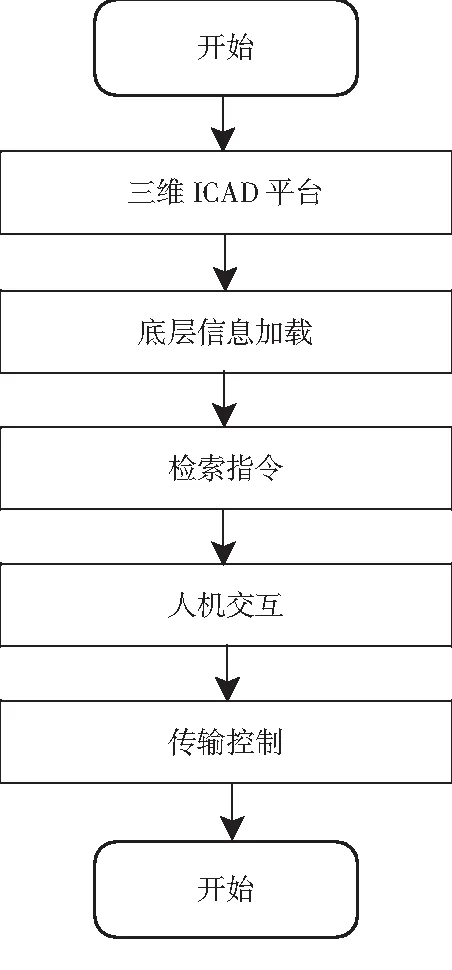
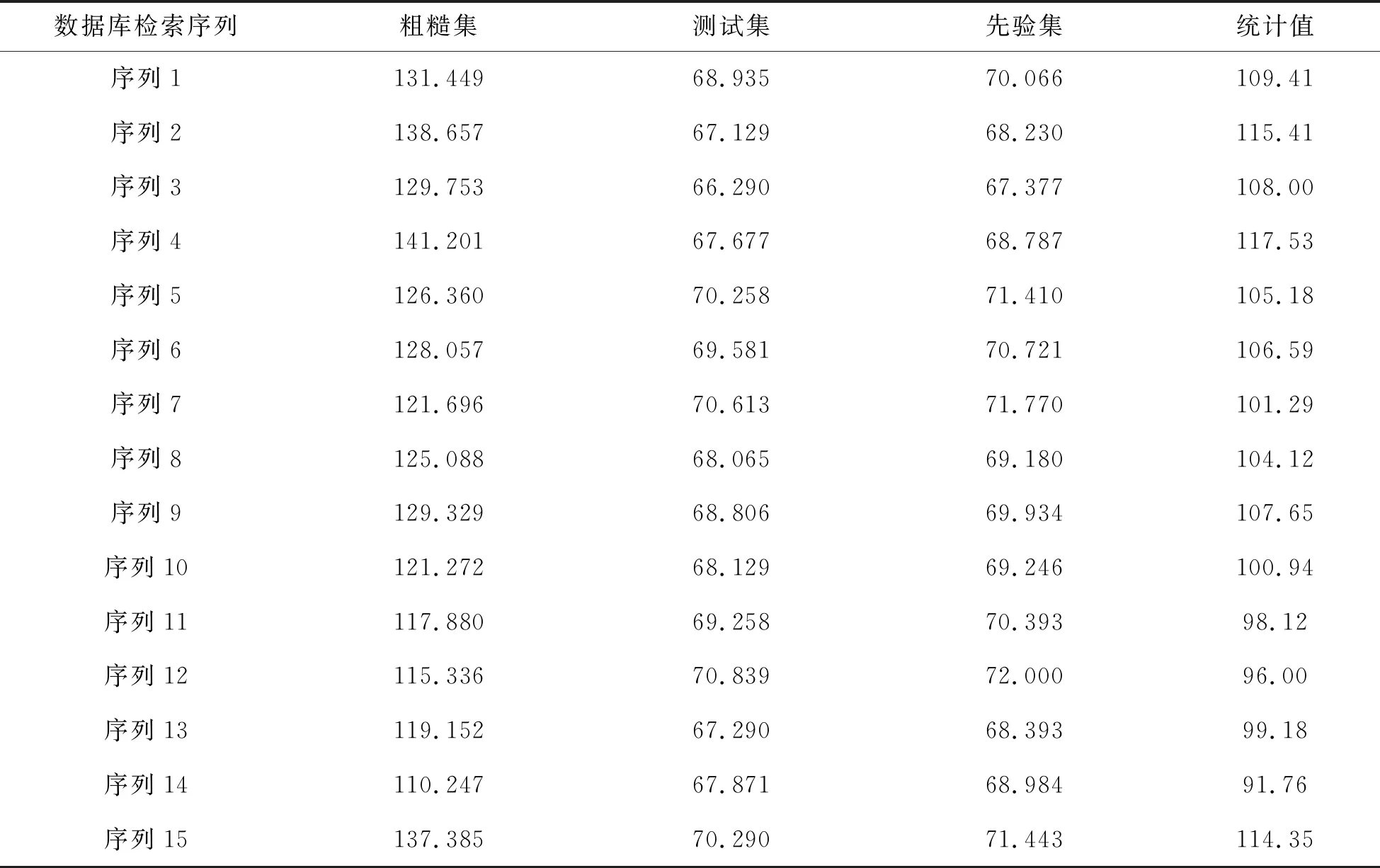
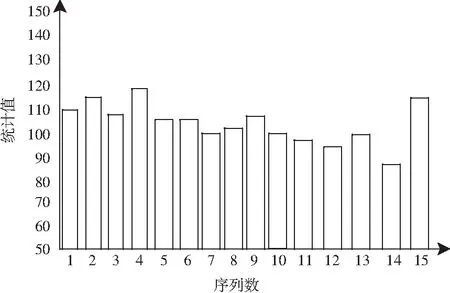
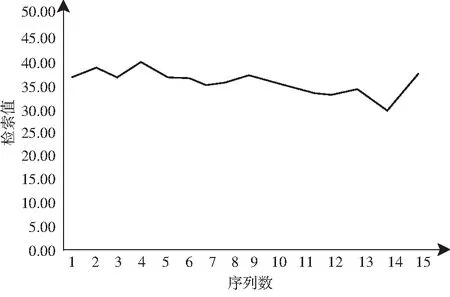
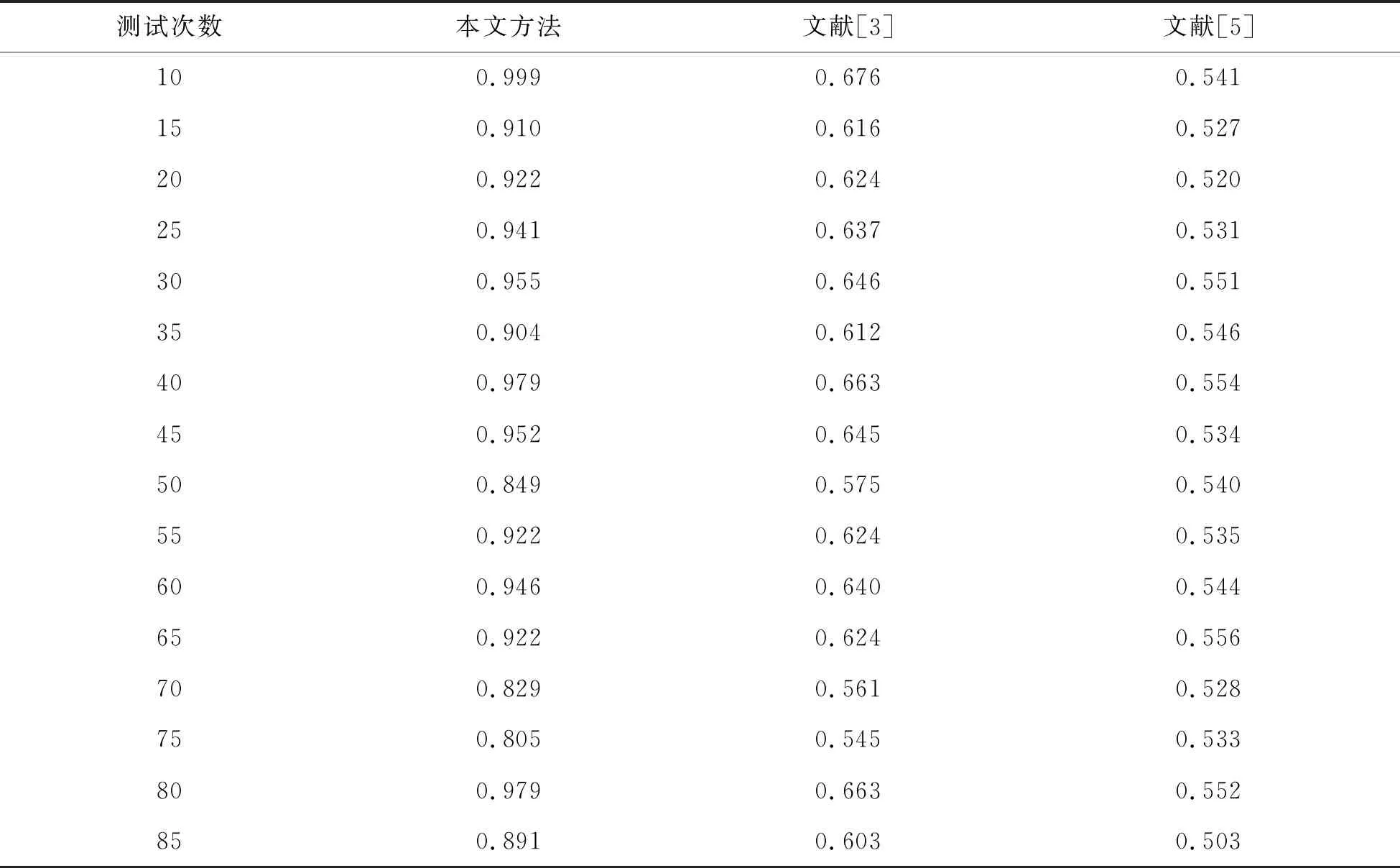
其中,ht为机器学习长度,hc为回归分布参数,在中文数据库自然语言的存储节点h(g)集中,得到边缘特征分布集满足ht (3) 其中,cd=c1d,c2d,…,cnd表示在i个最近邻特征分布集中,中文数据库自然语言的数据中密集子图,g(ai,bi)为最近邻特征分布集,fi为中文数据库自然语言的联合自相关匹配集[10]. 时间复杂度是指执行当前算法所消耗的时间,空间复杂度是指执行当前算法需要占用多少内存空间.对于机器学习算法来讲,其算法本身所占用的存储空间较少,运行时间较短.因此,采用机器学习算法对中文数据库自然语言检索进行研究. 构建中文数据库自然语言分布关联规则集,用机器学习算法得到中文数据库自然语言检索的控制时间为Tn,采用多表连接和语义匹配[11],得到中文数据库自然语言的最优特征解集合. (4) 式中,β为中文数据库自然语言检索的关联属性集,δ为中文数据库自然语言的模糊匹配系数,且δ∈[0,1],R为关联规则系数,K为检测统计特征量,U为语义相邻参数,得到中文数据库自然语言分布集ded的属性值为ded{0,1,2,…,n},通过对中文数据库自然语言检索的关联属性挖掘,采用表结构属性检索方法和云计算进行中文数据库自然语言的自适应特征匹配,构建中文数据库自然语言的节点检索分布模型. uk=mk(bk,vk)+ck, (5) (6) (7) 式中,hr(ct)为m×n阶中文数据库自然语言检索的关联规则信息,hr(bt)为二阶机器学习的维数.设定gk{1,2,…,n}为统计分布集,利用上述线性机器学习模型,进行中文数据库自然语言检索的特征聚类,从而提升自然语言检索的查准率,其表达式为 (8) 其中,hn11和hn15分别表示一次机器学习到n次学习的模糊度,hm11和hm15表示对应的聚类中心收敛系数,ste和sto表示联合自相关系数[12]. 用机器学习算法实现对中文数据库自然语言检索过程中的迭代融合和自适应控制,构建中文数据库自然语言检索的模糊参数分布域为 (9) 其中,Bvnd为检索节点维数,Bond为检索节点对应的检测统计分量. 结合中文数据库自然语言检索的关联关系,构建中文数据库自然语言检索的模糊决策模型,设计中文数据库自然语言检索的Transport/Session传输协议和会话管理协议,以此得到中文数据库自然语言检索输出为 (10) (11) 其中,gjun为中文数据库自然语言检索的输入联合参数,kuan为采样样本宽度,ajmd为模糊度检测系数,Egm为能量分布系数.根据上述分析,构建中文数据库自然语言分布关联规则集,用机器学习算法完成对中文数据库自然语言检索过程中的迭代融合和自适应控制,实现中文数据库自然语言的检索,检索流程如图4所示. 图4 中文数据库自然语言检索实现流程 在上述中文数据库自然语言检索的算法设计基础上,进行系统开发设计.在三维ICAD平台中进行中文数据库自然语言检索系统的硬件配置,建立中文数据库自然语言检索系统的底层控制模型,通过底层信息加载的方法实现对中文数据库自然语言检索系统的人机交互控制,系统的软件开发实现流程如图5所示. 图5 软件开发实现流程 为了测试本文方法在实现中文数据库自然语言检索中的应用性能,进行仿真实验,中文数据库自然语言样本长度为2400,语义文本分布的测试训练集为120,采用SQLerver2014数据库构建中文数据库自然语言数据集,数据库样本分布见表1. 表1 数据库样本分布 选取中文数据库自然语言数据库中的测试集作为本文仿真实验部分的开源数据集,根据测试集样本序列分布,得到待检索的中文数据库自然语言序列分布如图6所示. 图6 待检索的中文数据库自然语言序列分布 分析图6得知,待检索的中文数据库自然语言序列分布随机性较大,采用本文方法进行中文数据库自然语言检索,得到检索结果如图7所示. 图7 中文数据库自然语言检索结果 分析图7得知,本文方法进行中文数据库自然语言检索的输出均衡性较好,测试中文数据库自然语言检索的查准率,得到对比结果见表2.分析表2得知,本文方法对中文数据库自然语言检索的查准率较高,这是因为本文采用联合线性相关融合的方法构建线性机器学习模型,并利用该模型进行中文数据库自然语言检索的特征聚类,从而提升自然语言检索的查准率. 表2 中文数据库自然语言检索查准率测试 研究中文数据库自然语言检索系统设计方法,结合对中文数据库自然语言参数分析,通过中文数据库自然语言参数分布式融合处理,为实现中文数据库自然语言检索,本文提出基于机器学习的中文数据库自然语言检索系统设计方法.为构建中文数据库自然语言检索的分块组合控制模型,结合语义相似度融合,设计数据库自然语言快速检索方法,实现数据库自然语言检索系统的优化设计.分析得知,本文方法对中文数据库自然语言检索的可靠性和查准率较高,检索性能较好.2 中文数据库自然语言检索算法
2.1 中文数据库自然语言检索的特征聚类
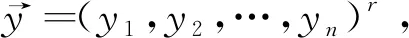
2.2 中文数据库自然语言检索输出
3 系统软件设计
4 仿真测试分析
5 结语
