基于强化学习的中小型无人机动态航线规划算法研究
2021-12-28杨雅宁
杨雅宁
(宁夏师范学院 物理与电子信息工程学院,宁夏 固原 756099)
自主无人机的飞行轨迹是根据预先规划并装载到其飞行控制系统的航线进行的,航线规划技术是无人机系统的关键技术之一.航线规划是指无人机执行任务前,在综合考虑安全、航时、航程等条件下,预先规划出一条或多条从起点到终点的最优飞行航线.在实际应用场景中,无人机起点到任务点之前往往存在地理、气象、军事等安全威胁,甚至还可能存在禁飞空域的影响,因此,无人机航线规划是在复杂环境下的最优化问题.
近些年,对无人机航迹规划算法的研究有很多,包括遗传算法[1]、A*算法[2]、蚁群算法[3]、人工势场算法[4]等.随着人工智能技术的兴起,研究人员提出了基于人工智能的路径规划方法.Chen Y W等[5]提出采用神经网络方法进行最优机器人路径规划的方法,Wu P[6]等人提出了一种基于深度学习的机器人路径规划方法,李志龙[7]等提出了一种基于强化学习Q-Learning算法实现机场服务机器人的路径规划,武曲[8]等人结合LSTM算法,提出了基于强化学习的动态环境规划算法.
本文针对复杂环境下中小型无人机航线规划问题,结合强化学习的动态规划算法理论,提出一种基于强化学习的动态规划算法,解决复杂环境下无人机的航线规划问题.并基于gym环境,使用Python语言进行仿真,验证算法的合理性和可行性.
1 基于强化学习的动态规划算法理论
1.1 强化学习与动态规划
强化学习是人工智能中策略学习的一种,是一种重要的机器学习方法.该方法起源于动物心理学的相关原理,模仿人类和动物学习的试错机制,是一种通过与环境交互学习,实现状态到行为的映射关系,并以此获得最大累计期望回报的方法[9].强化学习的要素包括智能体(Agent)、行为(Action)、环境(Environment)和回报(Reward).环境被划分为不同状态(State),智能体处于环境中的不同状态s,通过选择行为a,实现与环境的交互,并从交互中获得回报r,这个过程称为策略π.图1解释了强化学习的基本原理,在一个离散时间序列t=1,2,…中,智能体需要完成某项任务,在每一个时刻t,智能体都能从环境中接受一个状态st,并通过行为at与环境交互,转移到环境中新的状态st+1,同时返回一个立即回报rt+1,回报以价值函数Vt+1或行为价值函数Qt+1的形式给出.智能体在与环境交互的过程中,总是趋向于选择能获得最大回报的行为at,即获得最大的价值函数Vt+1或者行为价值函数Qt+1,用更大价值函数或行为价值函数下的行为更新曾经的行为.当价值函数或行为价值函数稳定收敛,智能体的行为轨迹即为最优策略π.

图1 强化学习基本原理
动态规划是运筹学的一个分支,是求解决策过程最优化的数学方法.动态规划算法的特点是一个问题可以划分为不同的子问题,求解问题的最优解可以通过求解若干子问题的最优解来实现.子问题状态之间存在递推关系,可通过较小的子问题状态递推出较大的子问题的状态.作为强化学习理论的基石马尔可夫过程同样符合以上特点,因此,动态规划算法可以用于求解马尔可夫决策过程.用动态规划算法所求解的马尔可夫模型MDP由
每个行为对应的回报价值用行为价值函数Q(s,a)给出,如式(1)所示,
(1)

智能体处在s状态下,转移到s′,获得的回报价值V(s)用最大价值函数Q(s,a)给出,如式(2)所示,
(2)
初始迭代时,模型所有状态的价值函数全部为0,当第k+1次迭代价值时,使用第k次计算出来的价值函数Vk(s′)更新计算Vk+1(s),迭代公式如式(3)所示,
(3)
当第k+1次迭代值函数为Vk+1(s)时,使用第k次计算出来的价值函数Vk(s′)更新计算Vk+1(s).经过多次迭代,直到价值函数V(s)稳定收敛.这时,智能体在每个状态的价值函数或者最大的行为价值函数下的行为a为智能体学习到的行为轨迹,即为最优策略π.
1.2 基于强化学习的动态规划算法描述
动态规划算法的流程如图2所示.首先创建环境,将环境划分为不同的状态,初始化各状态的价值函数V(s).根据每个状态s下的可能行为a,计算不同行为对应的行为价值函数Q(s,a) 函数.对不同的行为a,求取最大的行为值函数,作为当前状态下的价值函数V(s).如此反复迭代,直到价值函数V(s)稳定,算法达到收敛状态.根据收敛的价值函数,抽取每个状态下的行为a,所有状态的行为轨迹,就是所求最优策略π.

图2 动态规划算法流程图
2 实验仿真
本研究基于gym环境,使用Python语言进行仿真验证.在考虑无人机起点与任务点之间面临的气象威胁、军事威胁和地理威胁的情况下,改进动态规划算法,使其适应无人机任务的复杂环境,实现飞行航线的动态规划.
2.1 环境建模
本实验使用栅格法表示无人机起点到任务点之间的地图环境,如图3所示.无人机作为智能体,通过执行向上(UP)、向右(RIGHT)、向下(DOWN)和向左(LEFT)的行为动作与地图环境交互,获得回报.与一般情况下使用动态规划算法寻找“宝藏”问题相比,本实验的环境中存在有限个威胁区域(陷阱),同时目标位置(“宝藏”)和威胁区域均是已知的,因此该问题的最终可以定义为在存在陷阱的复杂环境中寻找一条从起点到终点的最短路径(航时航程最短),作为无人机的计划航线.为使模型更接近真实环境,本实验的环境模型遵循以下约束.
(i)根据无人机的起点(O,O)和任务点(M,N)的方位关系,拓展出边长分别为OM和ON的矩形区域,作为地图环境.
(ii)在满足无人机性能要求的前提下,将矩形区域划分为大小相等的正方形栅格,构建地图栅格.图3中构建了25个栅格的地图环境,每个栅格分配一个编号,0,1,2,…,24,共25个编号.左上角红色方格为起点区域,右下角黄色圆形区域为任务区域,白色区域为安全区域,黑色区为威胁或禁飞区域.根据实际应用情况,无人机的起点与任务点一定是安全区域.

图3 无人机地图栅格环境示例
(iii)威胁区域给定状态标识为0,其他区域给定状态标识为1.标识为威胁区域的栅格不得多于总栅格数量的30%,这也是接近实际应用情况的.同时满足从起点到任务点至少存在一条能避开威胁区域的路径,反之,如果不存在,那么扩展地图环境,重新生成地图栅格.
2.2 实验仿真
为使算法更好地适应无人机航线规划场景,降低算法计算量,结合模型约束条件,将一般动态规划算法做了如下改进:针对模型中的威胁区域和安全区域,分别使用0和1作为标识,根据模型约束和实际使用情况,无人机是不可能置于威胁区域的,因此算法中直接将威胁区域的值函数置零,忽略了在威胁区域行为值函数的计算,减低了算法的计算量.根据模型环境中无人机起点和任务点的方位关系,灵活设置不同行为所给予的回报值.使无人机正向靠近任务点的行为回报值更大,使无人机反向远离任务区域的行为回报值更小,使得算法快速收敛.
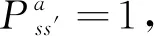
(i)如果选择执行的动作将使无人机即将离开环境边界或进入威胁区域,那么无人机将获得回报为-3,并使无人机停留在当前区域.
(ii)如果选择执行的动作将使无人机反向远离目标区域且下一区域为安全区域,那么无人机将获得回报为-3,如图3中向左的动作,无人机将进入新区域.
(iii)如果选择执行的动作不影响无人机对目标区域的趋向性,且下一区域为安全区域,那么无人机将获得回报为-2,如图3中向上的动作,无人机将进入新区域.
(iv)如果选择执行的动作将使无人机正向靠近目标区域,且下一区域为安全区域,如图3中向下或向右的动作,那么无人机将获得回报为-1,无人机将进入新区域.
(v)如果选择执行的动作使无人机进入目标任务区域,那么获得回报0,无人机将进入任务区域.
仿真结果如图4所示,图4中红色方框表示无人机的起点,黄色圆圈表示无人机的任务点,黑色方框表示地图环境中的威胁区域,白色方框代表地图环境中的安全区域,黑色箭头表示无人机在各安全区域学习到的最优移动方向.按照箭头方向,连接无人机起点到任务区的路径,即为无人机学习到的最优路径.

图4 仿真结果
图4(a)和图4(b)显示了无人机起点为左上方向,任务区为右下方向时,即起点和终点既不在同一经度,也不在同一纬度时(这代表了实际应用场景的一般情况),在不同的威胁区域影响下,无人机处于任意一个安全区域都能学习到一条安全的最优路径.图4(c)显示无人机起点与任务点在同一经(纬)方向时(这代表了实际应用场景的特殊情况),在威胁区域影响下,无人机无法直接从起飞点到达任务点,通过拓展地图区域,无人机仍能在地图的任意安全区域学习出至少一条最优路径.
3 结语
本文针对小型无人机从起点到任务点之间存在安全威胁和空域限制的问题,建立环境模型,将基于强化学习的动态规划算法应用于中小型无人机航线规划场景中.与一般动态规划算法相比,该算法通过对环境模型中威胁区域增加标识,忽略威胁区域行为值的计算,减低了算法计算量.同时,根据环境模型中无人机起点与任务点的位置关系,配置不同状态和行为下的回报值,使得算法快速收敛.实验结果表明,无论无人机起点和任务点的位置关系如何,通过本文的模型和方法,无人机处在环境中任意安全区域都能找到至少一条最优航线.
