基于信息多重蒸馏的轻量化低照度图像增强方法
2021-12-25钱宇华卢佳佳王克琪原之安黄琴刘畅
钱宇华 ,卢佳佳,王克琪,原之安,黄琴,刘畅
(1.山西大学 大数据科学与产业研究院,山西 太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原 030006;3.山西大学 计算机科学与信息技术学院,山西 太原 030006)
0 引言
高质量图像处理是计算机视觉和机器学习应用领域的研究热点,其直接影响高级视觉任务的处理性能,例如目标检测、目标跟踪和语义分割等任务,但是由于成像设备在低照度环境下捕获的光子数少、信噪比低,导致图像亮度偏低、饱和度不足、具有大量噪声等问题。因此,针对低照度图像处理具有重要的研究意义。目前,图像增强技术已被广泛应用于各种科学和工程领域,如大气科学、卫星遥感、计算机视觉、人体医学及交通领域等。现有的针对低照度图像增强方法的研究大致可分为两类:传统方法和基于深度学习的方法。
传统方法一般通过直方图均衡化算法[1]、Retinex 算法[2-3]以及基于数据驱动的图像增强方法[4]来提高图像平均亮度,但是存在颜色保真度不高的问题。近年来,随着深度学习得到快速发展,尤其在计算机视觉领域[5],众多学者聚焦于低照度图像增强任务。现有的低照度图像增强技术大多数是通过增加更多的卷积层以提高峰值信噪比(peak singal to noise ratio,PSNR)和结构相似性(structural similarity,SSIM)等指标值,但仍存在模型参数量较大等问题,使他们不适用于资源受限的设备中。例如,Chen等人设计了一种数据驱动的方法[6],有效提高了成像表现,但是该网络有23个卷积层,模型参数量为7.4 M。Karadeniz等人提出了一种多尺度框架[7],该网络有48个卷积层,模型参数量为14.8 M。Zamir等人提出了一种基于递归残差的卷积神经网络 MIRNet[8],该网络有 52 个卷积层,模型参数量为30.3 M。对于移动设备,当可用内存和推理时间限制在一定范围内时,不仅需要高性能,还需要高执行效率。
为了克服以上的问题,本文基于U-net[9]网络引入了信息多重蒸馏的思想,提出了一种轻量且高效的卷积神经网络,通过信息多重蒸馏提取更有用的特征(边缘、角和纹理等),同时采用对称的编码器-解码器结构,以更好地平衡性能和适用性。本文在低照度图像增强任务上,利用公开的数据集进行了大量的实验研究,通过与现有低照度图像增强算法的对比,验证了本文算法在视觉质量、优化计算空间和计算量之间实现了较好的平衡,定量分析结果如图1所示。

图1 定量分析可视化图Fig.1 Quantitative analysis visualization on SID Sony and LOL datasets
图1(a)、(b)分别为在SID Sony数据集上本文提出的算法与其他算法的性能和模型大小、计算量之间的定量分析可视化图;图 1(c)、(d)分别为在LOL数据集上本文提出的算法与其他算法的性能和模型大小、计算量之间的定量分析可视化图,可以看到本文提出的算法以较少的参数量和计算量达到比较好的性能。
1 相关工作
1.1 低照度图像增强
现有的研究中有很多技术用来增强低照度图像的对比度,经典方法大致可以分为两大类:直方图均衡化和伽马校正[10]。直方图均衡化平衡了整个图像的直方图,伽马校正可以在压缩明亮像素的同时提高黑暗区域的亮度,但这些方法忽略了单个像素与其相邻像素之间的关系。基于Retinex理论的增强方法,是将图像分解为反射图和照明图。Jobson等人相继提出了单尺度Retinex算法(Single-Scale Retinex,SSR)[11]和多尺度 Retinex 算法(Multi-Scale Retinex,MSR)[12]。SSR 是通过减弱原始图像中的光照分量并分离出反射分量,但无法兼顾图像细节增强和色彩保真的要求。MSR采用高斯环绕尺度估计光照分量,解决了SSR存在的问题,但导致色彩失真,同时该算法存在复杂度高、处理速度慢等缺陷。为了进一步提高增强的适应性,避免由于光照不均匀导致的局部过增强或欠增强,Wang等人[13]通过多尺度图像融合增强图像,但这些方法仍然无法解决噪声严重和色差等问题。
为解决传统方法的不足,研究者们利用基于深度学习的方法对图像增强领域展开研究。Chen等人[6]采用U-net网络对RAW图像数据到RGB图像数据的映射关系进行端到端的学习,从而实现图像增强,同时构建了真实场景的低照度图像数据集(See-in-the-Dark,SID),并在该数据集上有效实现图像增强,但增强结果存在伪影。Wei等人将Retinex理论与CNN相结合,提出了Retinex-Net网络[14]来估计光照图以增强低照度图像,但该方法的曝光时间是人为确定的,难以选择最佳曝光时间。ZHANG等人提出了基于Retinex理论的KinD(Kinding the Darkness)[15]方法,该方法将原始图像空间解耦成光照和反射两个部分,以学习调整光线的等级。Wang等人提出了DeepUPE(Underexposed Photo Enhancement Using Deep Illumination Estimation)网络[16],该网络通过估计图像与光照的映射来增强曝光不足的图像,但该算法没有考虑低光噪声对图像质量的影响。Lü等人提出了一种多分支弱光增强网络MBLLEN(multi-branch lowlight enhancement network)[17],通过 CNN 卷积层将图像丰富的特征提取到不同的层次,使用多个子网络进行同时增强,最后将多分支输出结果融合得到输出图像,但模型的泛化性能较差。Liu等人提出了一种全新的高效低照度图像增强方法RUAS(Retinex Inspired Unrolling with Architecture Search)[18],首先基于 Retinex 理论引入先验约束建立低照度图像增强模型,然后通过展开其优化求解过程以构建整体的网络架构,最后通过设计一种无参考的协作学习策略,以从自定义的紧致搜索空间中发现面向低光先验的高效深度网络结构,该模型轻量,计算资源消耗少,但是增强效果欠佳。
1.2 卷积神经网络
卷积神经网络凭借着强大的特征提取和表征能力在计算机视觉领域中展现出巨大的潜力[19-21],如图像分类、目标检测、语义分割等。Yann等人提出了卷积神经网络的第一个经典模型LeNet-5[22],由两个卷积层、两个池化层以及一个全连接层组成,模型应用于手写字体识别并取得很好的效果。Hinton 等人提出了 AlexNet[23],由五个卷积层、三个池化层、两个全连接层以及一个数据局部归一化层组成,采用dropout避免模型过拟合,用ReLU替代sigmod作为激活函数。SIMONYAN等人提出了VGG模型[24],采用连续的几个3×3的卷积核代替AlexNet中的较大卷积核来提升性能,并探索了网络的深度与其性能的关系。He等人提出的ResNet[25]通过采用残差学习解决了梯度消失或爆炸的问题,可以最大程度的加深网络。但是这些卷积神经网络在达到令人满意的精度的同时往往需要较大的模型参数量和大量的浮点运算量,例如AlexNet模型大小约为200 M,VGG-16模型大小超过500 M,ResNet152[26]计算量达到 11.3 亿次。由于对硬件的高要求使得深度卷积神经网络模型在实际应用中受到限制,很难在手机等便携式设备以及资源受限的嵌入式设备中部署。因此,本文结合信息多重蒸馏设计了一种轻量化的卷积神经网络并引入到低照度图像增强任务中,既减少了模型参数量,又提高了模型的精度。
2 基于信息多重蒸馏的低照度图像增强方法
2.1 低照度图像增强流程
本节将对低照度图像增强流程进行详细阐述,具体的低照度图像增强流程如图2所示。其中虚线箭头流是RGB图像的增强流程,实线箭头流是RAW数据的增强流程。RGB图像采用端到端的处理方式,而RAW格式数据要经过数据预处理、图像增强处理以及分辨率恢复三步。从成像传感器中得到原始数据后,传统的图像处理操作有白平衡、去马赛克、去噪、锐化、gamma变化等,但这些操作无法处理极低信噪比的情况,并对相机的硬件要求较高。本文采用文献[6]中的数据预处理流程,具体的实施流程如下:

图2 低照度图像增强流程图Fig.2 Low-light image enhancement pipeline
(1)首先进行黑电平校正,消除暗电流造成的成像干扰,并将像素值归一化。
(2)将信号数据(Bayer arrays)的R、G、B像素分别取出,并按R、Gr、Gb、B将RAW数据的单通道格式转化为4个通道格式,对应的分辨率变为原来的一半。
(3)将经过预处理后的图像数据输入至基于信息多蒸馏的低照度图像增强网络(Information multi-distillation Unet,IMD-Unet)进行图像增强。
(4)将IMD-Unet的输出结果再经过sub-pixel层[27]恢复分辨率,输出结果为3通道的RGB空间。
2.2 IMD-Unet网络
近年来,研究者们提出来的基于深度卷积神经网络的图像增强算法模型参数量较大,为此本文受文献[28]的启发,引入信息多重蒸馏模块(information multi-distillation block,IMDB),大部分现有的信息蒸馏方法用于图像超分辨率任务上,将信息蒸馏用于图像增强任务的研究较少。信息蒸馏的提出是为了有效提取重要特征信息、剔除冗余特征,从而减少网络参数量。本文网络结构采用的是一个编码器-解码器结构,编码器部分采用下采样增加感受视野的大小、降低运算量,实现特征提取,解码器部分采用上采样进行特征还原。
IMD-Unet框架如图3所示。首先将低照度图像(low-light,LL)经过一个3×3卷积提取浅层特征信息,在编码器部分堆叠3个IMDBn,其中n代表的是蒸馏次数,取值分别为1、2、3。本文在3.5节对n的取值的设定进行了研究)。每个IMDBn后用步长为2的最大池化进行下采样。在传统的下采样步骤中,输入通道数量呈指数增加,本文为了减少模型参数量和计算量,将输入通道的数量采用线性增加。在解码器部分由3个IMDBn和3次用于上采样的反卷积操作组成,为了还原下采样带来的信息损失,将编码层的输出与同高度的解码层的上采样结果进行加操作,本文用加操作来替代拼接融合,这样更节省参数和计算量。最终通过一个sub-pixel层输出正常光照(nomal-light,NL)图像。
2.3 信息多重蒸馏模块
如图3右半部分IMDBn所示,本文的信息多重蒸馏模块由逐层信息蒸馏、信息融合以及用于调整通道数的1×1卷积构成。由于高分辨率的时候计算量较大,所以本文在高分辨率时使用更少的蒸馏次数和输入通道数,在低分辨率使用更多的蒸馏次数和输入通道数,来减少整体网络的计算量,表1展示了信息多重蒸馏模块的超参数。

表1 信息多重蒸馏模块的超参数Table 1 Hyperparameters of information multi-distillation module
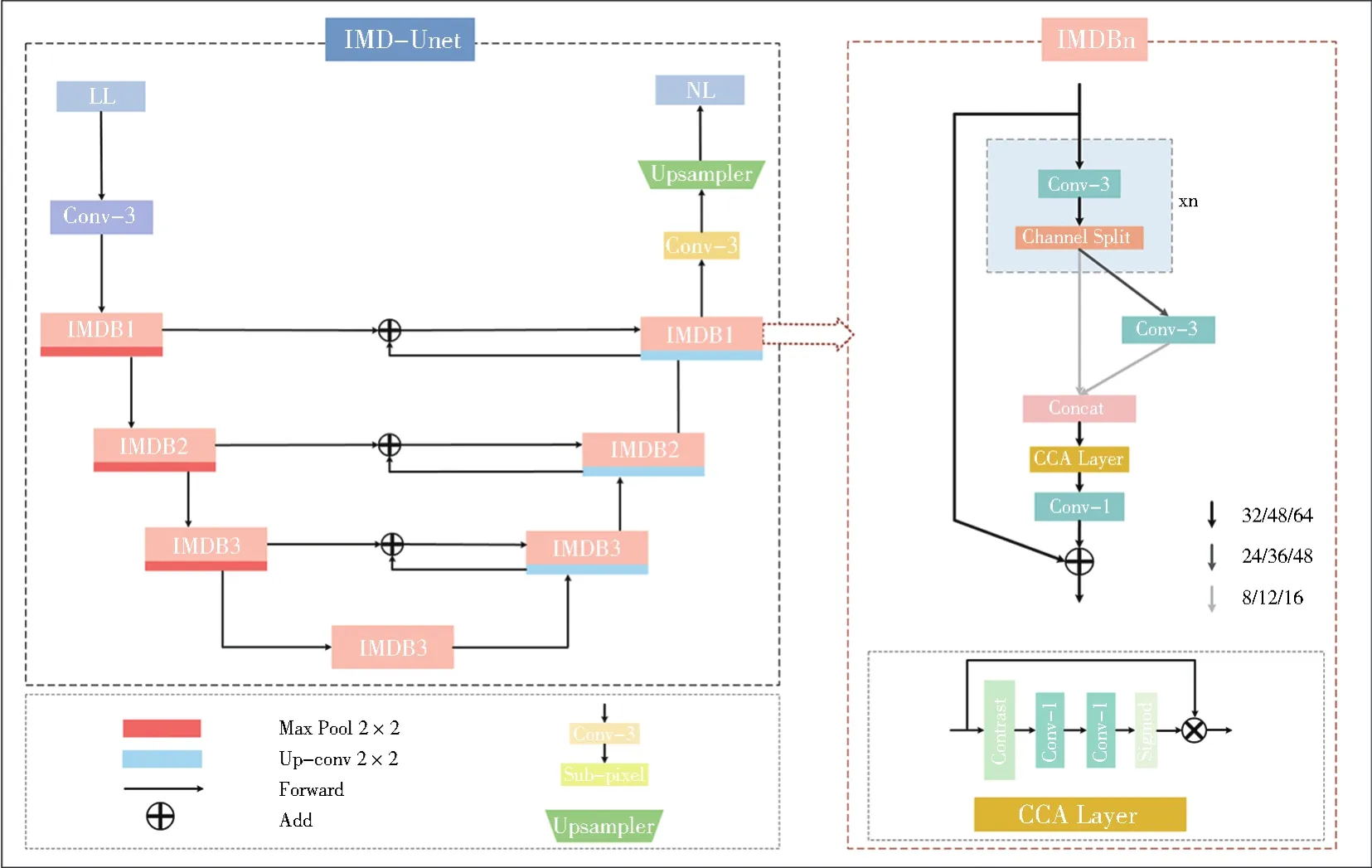
图3 基于信息多重蒸馏的低照度图像增强网络框架Fig.3 Low-light image enhancement network framework based on information multi-distillation
逐层信息蒸馏用来逐步提取不同层次的特征,逐步提取有用的特征,每一层将25%的特征提取保留下来,剩下75%的特征继续向后通过卷积进行再次提取,重复蒸馏n次,最后将提取出来的所有信息进行拼接融合。信息融合包括两部分,首先采用基于对比度的通道注意力机制(contrast-aware channel attention,CCA),根据特征的重要性用标准差和均值之和对空间信息进行聚合,从而进一步提高整体网络的性能,然后通过两个1×1卷积分别进行下采样和上采样。
本文提出的IMD-Unet与文献[28]中的IMDN(information multi-distillation network)的不同:(1)IMDN均采用相同的输入通道数和输出通道数64,并且堆叠的每个IMDB蒸馏次数均为3,而IMDUnet引入了先编码再解码,采用线性增加的输入通道数量32/48/64以及蒸馏次数由少变多再变少的对称结构,有效地减少了模型和计算复杂度(2)IMDN采用中间信息收集(intermediate information collection,IIC),而IMD-Unet将编码层和解码层的特征融合,不仅有利于网络内信息的流动,而且有效地提升了网络性能和运行效率。
2.4 损失函数
由于MS_SSIM(multi_scale structural similarity)容易导致亮度的改变和颜色的偏差,但是可以较好地保留高频信息(图像的边缘和细节),而L1损失函数可以较好地保持颜色亮度不变,因此本文为了加快网络的收敛速度和提高图像增强质量采用了MS-SSIM和L1损失的结合[29],混合损失LMix表示为:

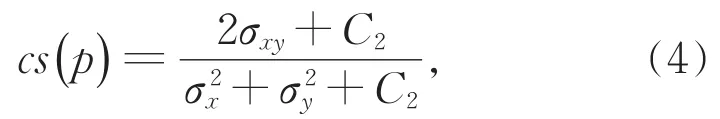
其中μ是均值,σ是方差,C1和C2分别是常数,M表示图像缩小倍数。
Lℓ1表示为:

其中p表示某一像素点,P表示Patch像素集,N表示样本数量,x表示处理后图像,y表示真实图像。
3 实验
3.1 评价指标
本文使用评价指标PSNR、SSIM[30]、MS_SSIM[31]和 visual saliency-induced index(VSI)[32]对实验结果进行定量分析。
3.2 数据集
本文使用SID[6]数据集和LOL(Low light Paired Dataset)[14]数据集进行实验分析和对比。LOL是第一个在真实场景下采集的配对数据集,它由500对真实场景的RGB图像和1 000张合成的RGB图像组成。每对图像包括低照度图像和曝光良好的图像,其中485对图像用于训练,15对用于测试,图像分辨率为400×600,本文只使用真实场景图像。SID是由Sonyα7sⅡ和Fujifilm X-T2摄像机在极低光条件下捕获的。SID包括5 094张短曝光RAW图像和424张长曝光RGB图像。输入的短曝光图像的曝光时间设置在1/30秒到1/10秒之间,而相应的长曝光图像的曝光时间为10到30秒。Sony子数据集包含2 697张短曝光图像和231张长曝光图像,图像分辨率为4 280×2 832。Fuji子数据集包含2 397张短曝光图像和193张长曝光图像,图像分辨率为6 000×4 000。本文使用了SID中的Sony和Fuji子数据集。
3.3 训练细节和参数设置
本文提出的算法在用LOL数据集训练时,输入为低照度图像,标签为正常光照图像,迭代次数为1 500,学习率为1×10-4,批处理大小设置为1,随机裁剪为400×400的大小。在用Sony和Fuji数据集进行训练时,网络输入的是短曝光RAW图像,对应的长曝光RGB图像作为参考图像,迭代4 000次,在每次训练迭代中,将输入图像由RAW格式转换成JPG格式,随机裁剪为512×512的大小,并利用翻转、旋转等操作来随机增强数据。初始学习率设定为1×10-4,在2 000次迭代后学习率降为1×10-5,批处理大小设置为1。本文使用计算高效并且所需内存少的Adam作为优化器,权重衰减率设置为 1×10-4。实验所用 GPU为 NVIDIA Tesla P100。
3.4 实验结果分析
本文分别在Sony、Fuji和LOL数据集上和现有的一些低照度图像增强算法进行了定量和定性分析。本次实验对比方法如下:LTS[6]、MIRNet[8]、RetinexNet[14]、KinD[15]、LIME(low-tight image enhancement)[33]、Ying[34]、BIMEF(A Bio-Inspired Multi-Exposure Fusion Framework)[35]、SGN(Self-Guided Network)[36]、LLRNet(lowlight restoration network)[37]、GLADNet(Global illumination Aware and Detail-Preserving Network)[38]、LLISP(Low Light Image Signal Processing Network)[39]。表 2 展示了本文算法在LOL数据集上与其他算法定量比较的结果,最好的结果加粗表示,其中“-”表示传统算法无法测出模型参数量(Params)和计算量(floating point operations,FLOPs)。由表2分析可得,本文算法在最少参数量和较少计算量的前提下PSNR、MS_SSIM和VSI指标均优于其他算法,SSIM逼近KinD算法。表3展示了本文算法在Sony和Fuji数据集上与其他算法定量比较的结果,最好的结果加粗表示。从表3的实验结果可知,本文算法以最少的参数量和计算量在Sony和Fuji数据集上均实现了可比的增强效果。图4展示了本文算法与其他算法在LOL数据集上的定性对比结果,传统的算法存在大量的噪声和亮度失真,而相比于其他的基于深度学习的方法,本文算法输出的增强图像在亮度和全局对比度上更接近参考图像,并且有效地抑制了伪影。图5和图6分别展示了本文算法与其它算法在Sony和Fuji数据集上的定性对比结果,本文算法利用信息多重蒸馏模块提取大量有效特征来增强图像,从而使增强结果具有更准确的色彩和细节信息。通过以上大量的实验分析,充分验证了本文算法的优越性。

表2 在LOL数据集上本文方法与其他方法的定量评估结果Table 2 Quantitative evaluation results of IMD-Unet and other algorithms on the LOL dataset

图4 LOL数据集定性评估结果Fig.4 Qualitative evaluation results of the LOL dataset

图5 Sony数据集定性评估结果Fig.5 Qualitative evaluation results of the Sony dataset

图6 Fuji数据集定性评估结果Fig.6 Qualitative evaluation results of the Fuji dataset

表3 在Sony和Fuji数据集上本文方法与其他方法的定量评估结果Table 3 Quantitative evaluation results of IMD-Unet and other algorithms on the Sony and Fuji datasets
3.5 消融实验及分析
为了进一步探索网络中不同超参数对实验结果的影响,修改IMDBn中n的取值以及输入通道进行相关的消融实验。表4为本网络模型设置不同的超参数时在SID Sony数据集上的消融实验结果对比。实验一、实验二、实验三的7层IMDBn中n的取值分别为1、2、3,实验四的7层IMDBn中n的取值分别为1、2、3、3、3、2、1(即高分辨率蒸馏次数少,低分辨率蒸馏次数多,并且编码解码的蒸馏次数是对称的),输入通道为32/64/128。实验五、实验六、实验七的7层IMDBn中n的取值分别为1、2、3,实验八的7层IMDBn中n的取值分别为1、2、3、3、3、2、1,输入通道为32/48/64。从表4可以看出输入通道数和n的取值对于实验结果都有较大的影响。当输入通道数采用传统的两倍增加时,虽然PSNR和SSIM提高了,但是导致参数量和计算量也成倍增加,所以输入通道默认设置为32/48/64。当n的取值全部为1或2时,实验五、实验六的PSNR和SSIM均偏低,说明蒸馏次数太少会影响网络的性能,而实验八相较于实验七,在性能相差不大的前提下,参数量和计算量更少,所以7层IMDBn中n的取值设置为1、2、3、3、3、2、1是最优选择。通过以上八组消融实验,充分证明了本文算法的有效性。

表4 本网络模型设置不同超参数时的消融实验结果Table 4 Comparison of ablation experiment results on SID Sony dataset with different hyperparameters settings of IMD-Unet
4 结论
为了在网络规模、计算复杂度以及性能之间取得更好的平衡,本文提出了一种高效轻量级网络IMD-Unet。本文通过引入信息多重蒸馏模块(IMDB),实现了逐层、准确地提炼重要特征,弥补了传统卷积神经网络的局限性,并采用编解码结构加快推理速度。同时,将编码层与解码层的上采样结果进行特征融合,为特征的还原提供更丰富的信息。最后,通过对比实验验证了IMD-Unet能以相对较低的计算量和参数量获得更优的主观和客观结果,并通过消融实验验证了不同的网络超参数对实验结果的影响。如何保持轻量高效的同时,进一步加快推理速度,这是未来的研究工作。
