汉语框架语义角色标注中特征模板选择法比较
2021-12-25宋毅君王瑞波
宋毅君,王瑞波
(山西大学 现代教育技术学院,山西 太原 030006)
0 引言
在自然语言处理中,语义角色标注任务的目标是给定一条汉语句子,在已知其核心目标词及所属框架的前提下,自动标注出该目标词所搭配的语义角色的边界及类型[1]。自2006年起,随着汉语框架网络的建设,汉语框架语义角色自动标注问题已经得到广泛的研究[2-4]。这些研究工作将大量的语言学特征形式化成相应的特征模板[5],并将其融合到统计机器学习算法之中,例如:条件随机场[6-7]、最大熵[8]、支持向量机[9]、神经网络[10]等。这些研究表明,优良的特征模板是提升汉语框架语义角色标注模型性能的重要因素。
然而,汉语框架语义角色标注任务常涉及大量候选特征模板。多种类型的语言学特征被用于构建语义角色标注模型,如:词特征、词性特征、浅层句法特征、浅层路径特征等。这些特征可以通过开窗口的方式进行选取。特定窗口大小的多种特征的组合构成一个特征模板。随着特征窗口数量和特征类型的数量的增加,候选特征模板的数量呈指数增长。这为最优特征模板的搜索带来了很大的挑战。
面对上述挑战,构建有效的特征模板选择方法是十分必要的。一个有效的特征模板选择方法必须确保在有限的时间复杂度内“尽可能”找到最优特征模板。为此,本文重点从两方面来衡量特征模板的有效性。第一、所选用的特征模板选择方法是否能有效地选出全局最优的特征模板;第二、所选用的特征模板选择方法是否具有可行的计算时间复杂度。基于完全搜索的特征模板选择方法需要在所有的候选特征模板上逐个建立模型,其时间复杂度是不可容忍的。因此,本文不考虑完全搜索方法,主要对比了两种常用的特征模板选择方法:贪心选取法和正交表选取法。本文的实验结果表明,相比于贪心选取法,正交表选取法可提前规划好候选特征模板集合,在短时间内选择到性能较优的特征模板。
本文的组织结构如下:第1部分具体描述了两种常用的特征模板选择方法;第2部分给出了汉语框架语义角色标注任务上的实验设置;第3部分给出了相应的实验结果及分析;第4部分总结了全文。
1 特征模板选择方法
特征模板选择方法的目的是为语义角色标注模型中的各种类型的特征选择合适的特征窗口,以改善语义角色标注模型的性能。初期的一些研究直接将所有特征的窗口大小固定,仅在算法类型和特征类别上调优[11-13]。这种方法从主观上忽略了特征窗口大小对于模型性能的影响,因此模型的性能也相对较低。后续的研究工作中,特征窗口对模型性能的影响[2-4]也被逐渐重视。本节分析对比了两种常用的特征模板选择方法:贪心选取法和正交表选取法。
1.1 贪心选取法
贪心选取法是一种基于贪心算法的特征模板选择方法。它的基本思想是将特征按一定的顺序排列,然后按顺序逐个特征调整至最优窗口[14]。表1给出了贪心特征模板选择算法的算法框架。
表1表明,贪心算法最终输出的特征模板与从候选特征集合中选取特征的顺序是有关系的。若选取的顺序不同,则输出的特征模板也会发生变化。本文加入特征的顺序为:目标词、词、词的二元组合、词性、词性的二元组合、位置、位置的二元组合、词与词性的搭配、词与位置的搭配、词性与位置的搭配、位置的三元组合、词与目标词的搭配。每种特征的窗口设置如表2所示,贪心算法中每种特征窗口都由小到大依次搜索,并且仅将目标词作为必选特征加入模板中。其中,“位置的三元组合特征”设置略微不同,贪心算法中设置为“-”(不选取)、“[-1,1]”和“[-2,2]”三种窗口。

表1 语义角色标注的贪心特征模板选择算法Table 1 Greedy feature template selection algorithm of semantic role labeling
特征模板的贪心选取法的基本思想来源于统计学中的单因素轮换法。由于单因素轮换法的最终输出十分依赖于初始输入;而且由于调整某一个特征时,其他特征的窗口仅为条件最优而非全局最优,因此,这种方法很难保证找到全局最优模板。贪心选取法的另外一个特点是第n次实验的特征模板依赖于第n-1次实验的结果。因此,该方法只能以串行的方式搜索最优窗口,从而导致实验运行时间比较长。
1.2 正交表选取法
在统计实验设计领域,对于单因素轮换法的一个更好的替代是正交表方法。基于正交表方法,本文将特征与因子相对应,窗口的大小与水平相对应,从而形成基于正交表的特征模板选择方法。本文以3个因子(特征),每个因子3个水平(窗口)为例来说明正交表的选点原理,具体见图1。在三维空间中每个维度代表一个因子,且其方向上的3个点分别与3个水平相对应,这样空间中共有27个点(模板)。如果要找到最优模板,需要遍历27种组合。但是,基于正交表方法,仅遍历图中所示的9个点便可找出最优模板。从图1可知,这9个点是均匀地分布在立方体中的。其均匀性体现在:将这9个点投影到任何一个2维空间中都是完全试验点,并且立方体中的每个方向上都有3个切面,每个切面上都有3行线段3列线段,在每一行线段上恰有一个试验点,每一列线段上也恰有一个试验点。这样就很大程度上缩小了特征模板的搜索空间。

图1 三因子三水平正交表的九个试验点的分布Fig.1 Distribution of the nine experimental points in a 33 orthogonal array
对于汉语框架语义角色标注模型,本文所用特征包含:词、词性、位置、目标词以及这些特征组合搭配特征。这些特征的具体解释见文献[2]。每种特征的候选窗口在表2中给出。
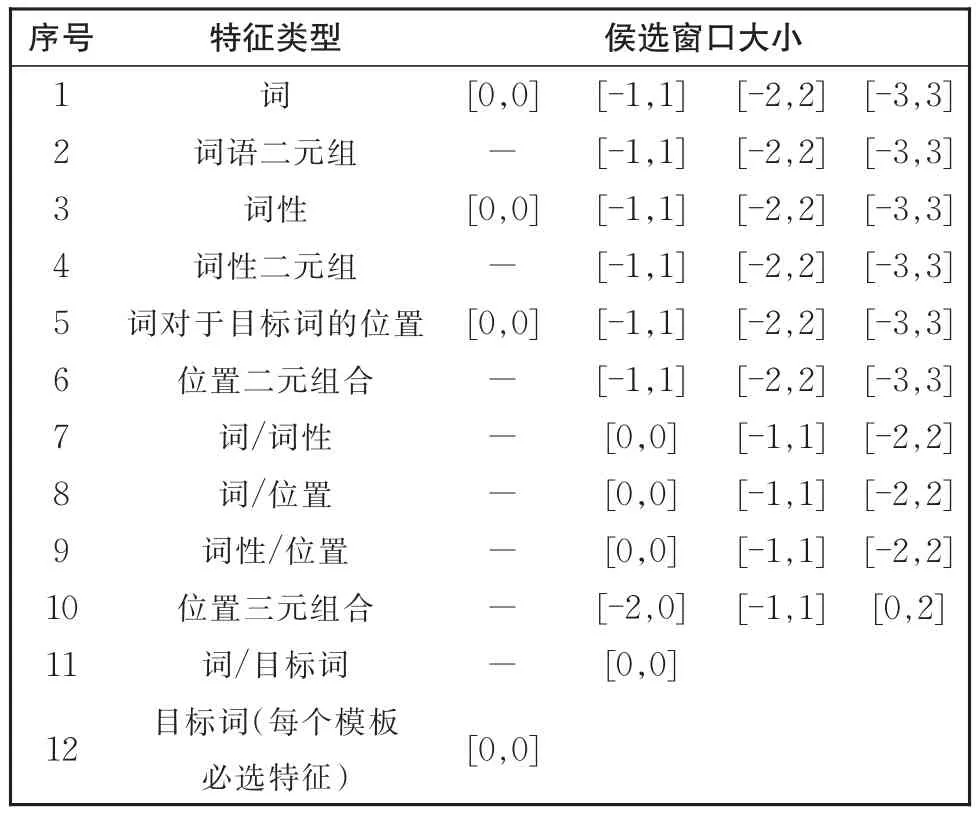
表2 词层面的候选特征及窗口大小Table 2 Candidate features and window sizes at the word level
由于目标词在构建框架语义标注模型时已被确定,并且不同的目标词的语义角色搭配结构有着明显差别,在表2中,目标词被设置为必选特征。
将表2中的前11种特征对应到正交表中的11个因子,每种特征的可选窗口对应各因子的水平,便可基于正交表方法来选择最优特征模板。考虑到前10个因子各有4个水平,第11个因子为2水平,为了使用文献中的L32(49×24)正交表,本文将第11种特征拆成3个2水平的特征:[-2,0],[-1,1],[0,2]分别与(-)搭配组成一行。这样,根据L32(49×24),可构造出32个候选特征模板。
一般地讲,正交表选取法是一种多因素的优化实验设计方法,它从全体实验样本点中选出具有代表性的一部分样本点来实验,所选的样本点具有正交性,其优点是通过较少的实验次数就可以选出因素水平间的最优搭配。但是,当特征类型比较多时,要求相应的正交表也比较大。不过,所形成的所有候选模板训练时没有先后顺序,不会相互影响。因此,可采用并行化方法来训练相应的标注模型,从而降低了训练时间的开销。本文仅从实验的角度来分析正交表选取法的有效性和计算复杂性。
2 实验数据集设置
2.1 语料选取与切分
目前,汉语框架网络知识库包含130个框架。在不同的框架中,标注例句的数量和质量有所差异。为了减少人工标注质量对汉语框架语义角色标注模型的影响,本文选出了例句数较多且质量较高的25个框架作为实验用语料。实验所用的25个框架及实验数据的详细信息见表3。需要注意的是,词语“陈述”在作为名词词元和动词词元时,语义角色上的分布差别较大。因此,本文将其分解成“陈述”名词模型和“陈述”动词模型。因此,实验中共训练得到了26种语义角色标注模型。
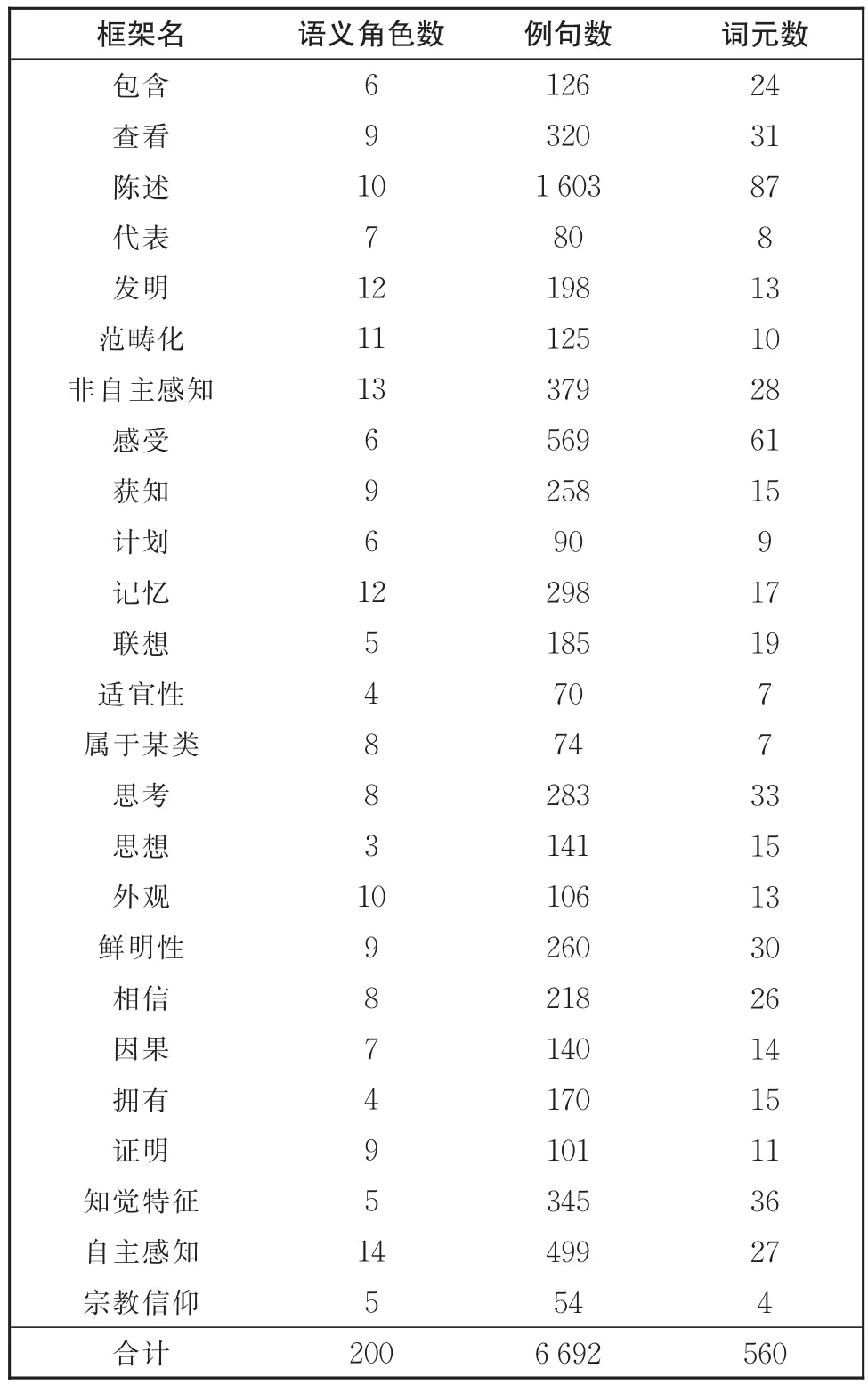
表3 实验所用25个框架的基本统计信息Table 3 Basic statistics of the 25 frames used in the experiments
2.2 评价指标
本文的评价指标主要从模型性能和特征模板选择方法的运行时间两方面来考虑。
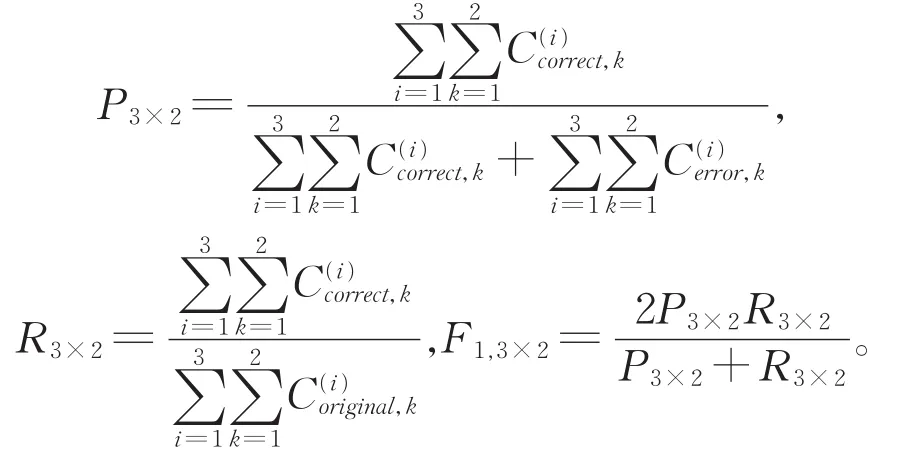
针对模型性能,本文采用了三种常用评价指标:准确率(P)、召回率(R)、F1值。具体定义如下:

其中,Ccorrect,Cerror和Coriginal为预测正确的语义角色块数、预测错误的语义角色块数和例句库中原有的语义角色块数。
本文使用了组块3×2交叉验证来进行特征模板选择。具体地,将每个框架中的所有例句平均切分为4份,使用其中2份作为训练集,剩余2份作为验证集。这种切分方式可构成3组2折交叉验证,称为组块3×2交叉验证。在任意两组2折交叉验证中,训练集间的重叠例句数基本相同,因此,组块3×2交叉验证可有效地减少模型性能的方差[15]。组块3×2交叉验证已经在模型选择方面进行了较为深入的研究[16-17],且可有效地改善自然语言处理中模型比较方法的性能[18]。
本文使用准确率、召回率和F1值的组块3×2交叉验证的微平均值来度量语义角色标注模型的性能。具体地,组块3×2交叉验证含有6次实验。在每一次实验中,记预测正确的语义角色块数、预测错误的语义角色块数和例句库中原有的语义角色块数分别为其 中,i=1,2,3 为组标号,k=1,2为组内实验标号。那么,准确率、召回率及F1值的组块3×2交叉验证的微平均为:
对于每个特征模板选择方法的运行时间,本文给出了实验所耗费的实际运行时间。在正交表选取法中,本文采用了并行计算技术,所统计的时间为并行处理时间,不做相应的叠加。基于正交表选取法的并行处理设置在下一小节中给出。
2.3 标注模型的并行化处理
在25个框架的语义角色标注模型的学习阶段,可以从如下三个不同的方面进行并行化处理。具体如下:
(1)框架层面的并行化处理。在语义角色标注实验中,25个框架所形成的26个不同的语义角色标注模型之间是相互独立的,这允许高性能集群对26个不同的标注模型进行并行训练,以节省模型串行训练的时间消耗。
(2)交叉验证层面的并行化处理。对于每一个框架的例句库,当语料被切分成相应的交叉验证集后,组块3×2交叉验证中6次切分的学习过程是相互独立的。因此,6次切分可以进行并行化处理。
(3)在正交表选取法中,32组特征模板是在构建语义角色标注模型之前设计好的。因此,32个特征模板上的实验可以并行处理。然而,在贪心选取法中,特征模板的生成和模型的学习过程紧耦合(见表1)。这导致并行化处理无法在贪心选取法中实施。
此外,语义角色标注模型的预测和评价阶段也可进行并行化处理。但考虑到预测和评价阶段所需要的时间代价相对较少,本文并没有针对这两个阶段进行并行化的处理。
本文基于山西大学的Windows高性能集群平台提供的并行环境来比较正交表选取法和贪心选取法。该平台包含:1个管理节点;25个计算节点(每个节点单CPU双核3.0 G,4 G内存);1个文件服务器(1.2T);全千兆网络互联。该平台上现已安装微软集群管理软件,MSMPI并行编译环境,C语言、Fortran语言、R统计语言等编译语言以及条件随机场等多种机器学习算法工具。实验采用了CRF++工具包作为机器学习算法,且仅使用其中的CRFL2算法。
在语义角色标注实验中,本文对于Windows HPC中的资源做如下处理。在实施贪心选取法时,管理节点用来提供服务管理和调用;计算节点NODE002-NODE015用于并行处理26个语义角色标注模型的主程序;计算节点中的NODE016-NODE026分别用来处理26个标注模型所生成的条件随机场算法学习阶段的并行化需求。对于正交表选取法,计算节点NODE002-NODE015用于执行26个模型的主程序,计算结点NODE016-NODE026用于处理32个特征模板之间的并行训练。
3 实验结果及分析
本节从特征模板选择方法的运行时间以及对应的汉语框架语义角色标注模型性能两方面对比分析了正交表选取法和贪心选取法。
3.1 特征模板选取方法的时间开销
表4中给出了正交表选取法和贪心选取法在语义角色标注任务上的实际运行时间。最后一行中的“总用时”指的是26个模型在Windows高性能集群平台上从作业提交到完成时总共耗费的时间。

表4 基于两种特征模板选择方法的标注模型训练时间Table 4 Training times of labeling models based on two kinds of feature template selection methods
对比正交表选取法和贪心选取法的用时情况可以发现,正交表选取法的用时明显小于贪心选取法,仅为后者的12.79%。因此,正交表选取法在训练用时及可并行化程度上均明显好于贪心选取法。
3.2 框架语义角色标注模型性能
表5给出了基于正交表选取法的25个框架中26种语义角色标注模型的性能。其中,“包含”框架的F值可以达到86.30%。这主要是因为包含框架的语义角色个数较少,并且语义角色与句法之间的对应有明显的规律性。相反,“联想”“自主感知”等框架的语义模型性能相对较低。实际上,在人工标注的时候,属于“联想”“自主感知”等框架的句子的语义信息也相对难以判断。最终,26个标注模型的总体平均F1值为61.62%。

表5 基于正交表选取法的标注模型性能(%)Table 5 Performance of labeling model based on orthogonal array selection method
表6给出了基于贪心选取法的语义角色标注模型的实验性能。26个标注模型的总体F1值达到了61.56%,略微低于正交表选取法的总体F1值,但不明显。

表6 基于贪心选取法的标注模型性能(%)Table 6 Performance of labeling model based on greedy selection method
为了对比各个框架中正交表选取法和贪心选取法的性能差异,本文分别将两种特征模板选择方法的相应结果进行了相减,形成了各框架上准确率,召回率和F1值之间的差,具体见图2。图2表明,绝大多数框架中,正交表选取法的准确率明显高于贪心选取法的准确率,最大的差值可以达到近7%。不过,很多框架中,贪心选取法的召回率明显高于正交表选取法的召回率。从F1值来看,正交表选取法在一些框架上具有优势,但总体上并不明显。最终,在26个标注模型上,正交表选取法的F1值仅比贪心算法高0.06%。
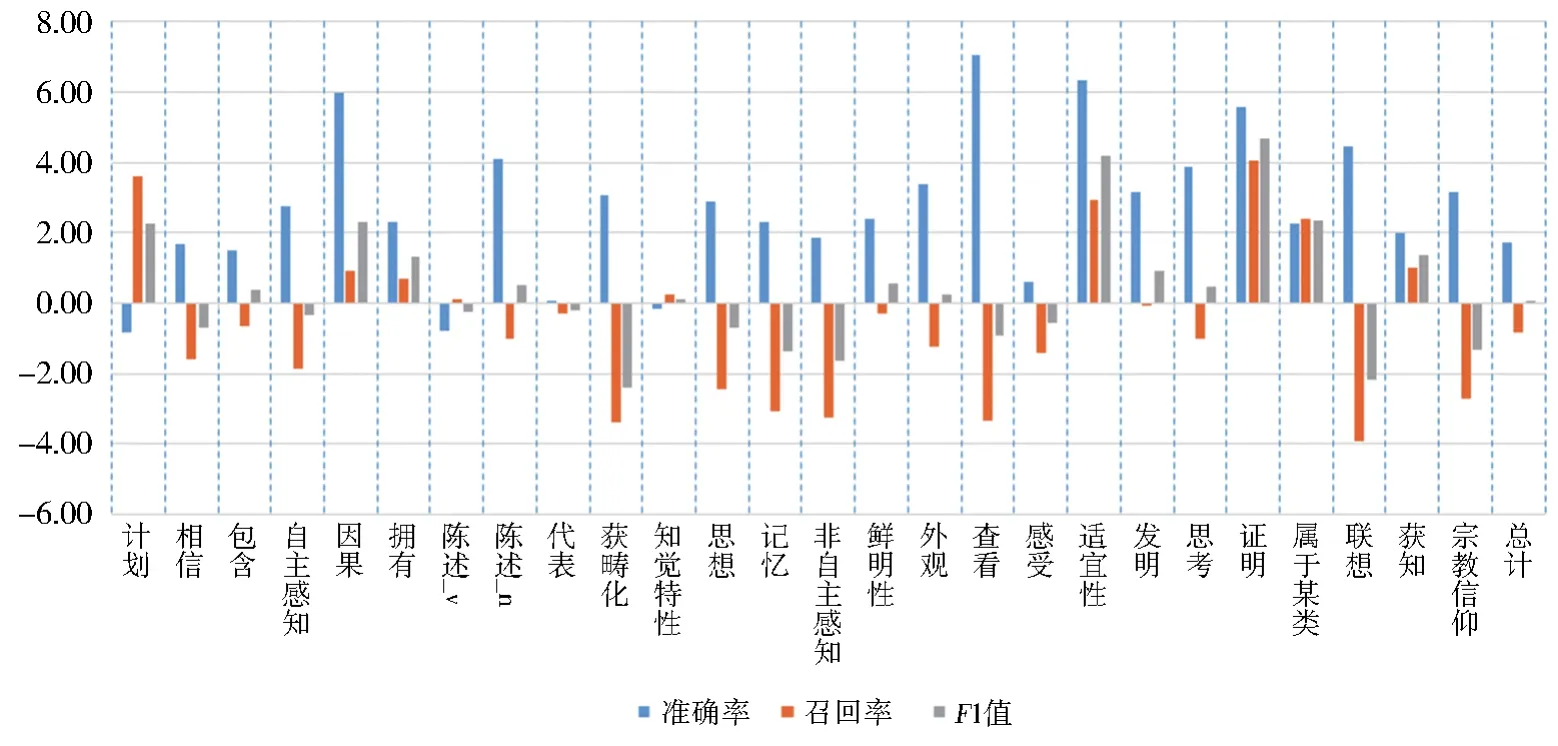
图2 正交表选取法与贪心选取法的性能差异比较Fig.2 Comparson of model performance between orthogonal array selection method and greedy selection method
综上所述,从特征模板选择方法的模型性能以及相应的运行时间可以看出,正交表选取法优于贪心选取法。正交表选取法在压缩了运行时间的基础上,有效地找到了性能较优的特征模板。
4 结论
本文分析了贪心选取法和正交表选取法两种模板选择方法对模型性能的影响。从汉语框架网络知识库中选取25个框架作为实验用语料,比较了两种特征模板选取方法的时间复杂度和模型性能。实验结果说明正交表选取法所用时间明显少于贪心选取法本身,并且正交表选取法的所选模型的F1值略微高于贪心选取法的所选模型的F1值。
