基于距离感知的目标情感分类模型
2021-12-22马晓慧马尚才闫俊伢
马晓慧,马尚才,闫俊伢,陈 波
(1.山西大学商务学院,山西 太原 030031) (2.山西财经大学信息管理学院,山西 太原 030006) (3.山东理工大学计算机科学与技术学院,山东 淄博 255020)
目标情感分类[1]是一种细粒度的情感分类任务,给定一个包含特定目标实体的文本,该任务的目的就是确定文本中各目标的情感极性. 如,“这款手机屏幕很亮但拍照效果不佳”. 这句话包含“屏幕”和“拍照效果”两个目标实体,“屏幕”的情感极性为积极,而“拍照效果”的情感极性为消极. 目标情感分类一般包含目标提取、类别检测和情感极性判别3个子任务[2],在工业界有很大的应用需求.
目前,目标情感分类方法主要分为两类:(1)以使用语言资源构建分类器为主的机器学习方法,如使用语法分析器生成特征[3-6],使用最大熵、条件随机场、支持向量机、朴素贝叶斯等[7-10]分类器进行情感极性分类. 这些方法虽然简单高效,但也存在诸如数据集规模要求高、对手工训练数据依赖性强、领域迁移效果不佳等缺点. (2)以深度神经网络进行特征提取和表示的方法[11],如卷积神经网络[12-13]、以LSTM[14-15]和GRU[16-17]为代表的循环神经网络,结合注意力权重的网络模型[18-20]等. 在目标情感分类任务中,将注意力机制和LSTM、GRU等循环神经网络结合的模型存在训练时间长和无法对分类文本并行输入等问题. 传统的卷积神经网络模型虽能缓解循环神经网络的性能限制,可以通过关注局部特征和最大池化方案来改善不相关词对给定目标的影响,但没有考虑文本中每个词与目标词之间的距离信息,忽略了目标在文本中的位置特征.
为解决上述问题,本文提出了一种基于距离感知的目标情感分类模型,利用卷积神经网络对目标实体及其他非目标词语间距离及位置特征进行建模,使用距离感知窗口将重点放在离目标词更近的词上,进而进行情感分类. 实验对本文方法与TD-LSTM、TDparse和BILSTM-ATT-G等模型在SemEval2014数据集上进行了比较. 实验结果表明,通过对文本中每个词与目标词之间的距离信息进行建模,提高了分类准确性. 对于两种数据集,本文方法的训练时间都比BILSTM-ATT-G短,说明卷积神经网络可以有效降低模型的训练时间,提升模型的运行效率.
1 研究方法
1.1 卷积神经网络
给定句子s={x1,x2,…,xi,…,xn},n为句子长度,xi为句子中的第i个词.使用卷积神经网络对s进行情感分类时,首先将s中的每个单词表示为映射后的单词向量X∈Rn×d:
X1:n=x1⊕x2⊕…xn,
(1)
式中,⊕为向量拼接操作,n为输入文本中的单词数,d为词向量的维数.
使用卷积核对X进行卷积运算,提取文本中的局部特征.设使用窗口大小为k的卷积核w∈Rk×d在文本向量上进行卷积操作,则可以得到特征ci:
ci=f(w·X(i:i+k-1)+b),
(2)
式中,(·)为矩阵点乘操作,X(i:i+k-1)是从i个词到(i+k?1)个词的词向量矩阵,b是偏置项,f是一个非线性变换函数.
对于长度为n的句子,通过重复应用卷积核w进行卷积操作,得到特征向量:
c=[c1,c2,…,cn-k+1],
(3)
式中,c∈Rn-k+1.
(4)
式中,m是卷积核的数量.最后将特征向量x输入到一个全连通的softmax层中进行分类,判别输入文本的情感极性.
1.2 目标依赖的卷积神经网络
在目标情感分类中,给定句子s={x1,x2,…,xi,ti,…,xn},n为句子长度,xi为句子中的第i个词,ti为目标实体.其中ti可以为单词也可以为短语. 在使用基础卷积神经网络进行情感分类时,未考虑具体目标实体的情感类别. 基于此,我们设计了使用卷积神经网络进行目标情感分类的基线方法,称作目标依赖的卷积神经网络(convolutional neural network for target-level sentiment analysis,CNN-TSA). 该方法使用卷积神经网络进行目标情感分类时,不考虑目标实体在句子中的位置,直接连接句子映射的词向量和目标词向量作为输入向量Xi,输入到CNN中提取特征并进行分类,连接后的特征向量为:
Xi=[X;Xt1:tT],
(5)
式中,;为拼接操作,t1、tT分别为某一目标实体的起始位置和结束位置,一个目标实体可能包含多个词语,T为目标实体的长度.实际应用中,一个目标的情感极性更可能依赖于它的邻近词,本方法没有考虑目标词与周围词的距离关系,将作为对比基线方法来评估基于距离感知的目标情感分类方法性能.
1.3 基于距离感知的目标情感分类模型
在目标依赖的卷积神经网络基础上,本文提出了基于距离感知的目标情感分类模型(distance-based model for target-level sentiment analysis,D-TSA),模型总体结构图如图1所示. 模型主要由5个模块组成:输入模块对输入信息进行距离向量嵌入处理,包括待分类文本词矩阵和距离矩阵组成的输入矩阵;卷积模块对不同的输入矩阵进行特征提取;池化模块对卷积层的输出进行最大池化操作;连接模块用来融合全局信息,将提取到的不同特征进行拼接,拼接后的向量包含全文信息、目标词的位置信息,传递到下一层输出模块中进行处理;输出模块使用softmax进行情感分类并进行输出.

图1 D-TSA模型结构图Fig.1 The architecture of D-TSA model
模型的输入模块分为两部分,第一个卷积网络输入为整个句子的嵌入词向量,第二个卷积网络的输入为目标词邻近文本的嵌入词向量. 其中,邻近文本的长度由距离感知窗口决定. 假设距离感知窗口的大小设置为“p”,则距离感知窗口包含(2p+T)个词,即目标词本身加上左侧紧邻的p个词和右侧紧邻的p个词.如前所述,T为目标实体的长度,由于一个目标实体可能包含多个词语,t1、tT分别为该目标实体的起始位置和结束位置.形式上,给定文本单词向量X∈Rn×d,距离感知窗口中的文本词向量为X(t1-p:tT+p),分别通过两个卷积网络的卷积层和池化层进行特征提取,最后将第一个卷积网络池化层输出的句子特征向量x和第二个卷积网络池化层输出的距离特征向量xd进行拼接,得到:
Xi=[x:xd].
(6)
最后特征Xi被输入到全连接的softmax层预测目标情感.模型的交叉损失函数定义为:
(7)

2 结果与讨论
2.1 实验数据集和实验方法
实验采用SemEval2014数据集[21]评估模型的性能,数据集包括餐馆和笔记本电脑两个数据域. 该数据集主要用于细粒度情感分析,非常适用于有监督的机器学习算法或者深度学习算法,文件格式为.xml. 数据的情感极性包括积极、消极、中立和冲突,由于对比文献都不考虑冲突类型的情感极性,所以在预处理时剔除了数据集中的这类样本. 经过数据预处理,每条数据包含文本、目标、情感极性,表1列出了数据的情感类别分布情况.

表1 SemEval2014实验数据集分类情况统计Table 1 Statistics of the SemEval2014 experimental dataset
实验环境为64位 Windows10操作系统,CPU为英特尔core i7-7500,8G内存,开发环境为 Keras,开发语言为 Python的实验环境. 实验中,随机失活取0.5,批大小取32,学习率设为0.01,卷积核尺寸分别为3、4、5,距离感知窗口大小为2,使用Word2Vec预先训练词向量,具体超参数设置见表2所示.

表2 超参数设置Table 2 Hyperparameter configuration
实验对基于循环神经网络、基于外部语法分析器、基于注意力机制、基于基础卷积神经网络等5种模型和本文模型进行了比较.
(1)CNN. 利用基础卷积神经网络模型进行分类.
(2)SVM. 文献[22]提出的结合N元语法和情感词特征的SVM分类模型.
(3)BILSTM-ATT-G. 文献[11]将注意力机制应用于带有门单元的LSTM进行目标情感分类.
(4)TD-LSTM. 文献[15]分别使用两个LSTM从给定目标的左侧和右侧文本中提取目标相关的特征.
(5)TDparse. 文献[3]使用语法分析器提取与目标相关的词进行情感分类.
2.2 模型分类性能分析
本文在SemEval2014数据集的两个领域用户评论上进行7组实验,分析不同模型目标情感分类的效果,实验结果见表3和图2所示. 可以看出,本文提出的D-TSA方法在2个领域的数据集上均取得较好的分类效果. CNN模型由于没加入任何特征信息,在表现较好的餐馆数据集上的正确率只有65.3%. 与CNN模型相比,基于注意力机制的BILSTM-ATT-G模型的分类正确率在笔记本电脑领域数据集提升了12.6%,在餐馆领域数据集提升了7.1%,说明注意力机制能够通过聚焦句子中目标特征,更好地进行情感分类. BILSTM-ATT-G模型在两个领域的数据集中表现也整体优于TDparse模型和TD-LSTM模型,验证了深度学习方法作为目标特征提取器的有效性和网络结构设计的重要性. TDparse使用解析器来提取与目标相关的词,输入到SVM分类器进行分类. 如果解析器提取的目标词在预先训练的词表集合中不存在,则会随机初始化SVM分类器的嵌入向量,导致情感极性分类错误. 相反,基于深度学习的BILSTM-ATT-G模型在模型训练期间会更新单词,提高了目标情感极性分类的准确率.

图2 不同模型分类性能比较Fig.2 Performance comparison of the different models

表3 不同模型在SemEval2014数据集上情感分类正确率比较Table 3 Accuracy on sentiment classification of different models in the SemEval2014 dataset
对比不考虑位置信息的CNN-TSA基线模型和使用注意力机制的BILSTM-ATT-G模型可以看出,BILSTM-ATT-G模型在2个数据集的分类正确率都高于CNN-TSA基线模型,其中笔记本电脑数据集高出2.5%,餐馆数据集高出1.5%. 实验结果表明基于注意力机制的BILSTM-ATT-G模型可以更好地学习特定目标的情感信息,可以比不考虑目标实体在句子中的位置的特征提取方法取得更好的分类效果.
对比本文提出的D-TSA模型和BILSTM-ATT-G模型,可以看出,D-TSA在SemEval2014两个领域数据集的分类正确率均高于BILSTM-ATT-G,正确率分别提升了2.3%和1.2%. 实验结果表明,基于RNN的方法会忽略文本中每个单词之间的距离信息,当BILSTM-ATT-G模型给予某一目标词最高的注意力权重后,该词语左侧和右侧两个词也会被认为是重要的单词,导致在部分数据上的情感预测错误. 相比结合注意力机制的双向LSTM网络,D-TSA模型克服了BILSTM-ATT-G的局限性,根据邻近单词与目标之间的距离进行建模,使网络在训练过程能提取到更有效的信息,提高了分类效果.
通过7组实验对比,说明对目标实体周围的词语进行距离建模对目标情感分类是有益的,验证了通过对文本中每个词与目标词之间的距离信息进行建模,可以提高分类准确性.
2.3 模型训练时长分析
为了分析不同网络模型的时间性能,本文进行了基于RNN的目标情感分析模型、传统卷积神经网络分类模型和本文模型3种模型的对比实验,对比实验均使用相同的软硬件环境、词向量矩阵和数据集. 表4 和图3为不同模型在两个领域数据集上执行一次迭代的运行时间对比情况.

图3 不同模型完成一次迭代的运行时间Fig.3 Running time of different models to complete an iteration
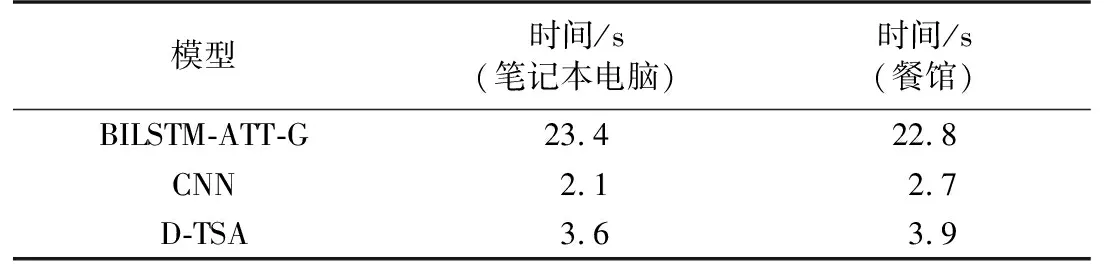
表4 不同模型完成一次迭代的运行时间比较Table 4 Comparison of the running time of different models to complete an iteration
可以看出,BILSTM-ATT-G模型训练时间代价非常高,这是因为基于RNN的网络训练的是序列性数据,每一个单元都需要复杂的运算操作,GPU难以对运算进行并行处理. 对于两个不同领域数据集,本文模型的训练时间都比BILSTM-ATT-G模型短,BILSTM-ATT-G模型完成一次迭代的运行时间约为本文模型的6~7倍,运算效率远低于本文模型. 从表4可以看出,传统CNN训练时间最短,在笔记本电脑领域数据集和餐馆领域数据集上完成一次迭代的运行时间分别只需要2.1 s和2.7 s,说明卷积神经网络可以有效降低模型的训练时间. D-TSA模型由于加入了距离特征建模,训练开销略有上升,完成一次迭代的时间最大为3.9 s. 相比CNN网络,由于提升了分类性能,训练时间的增加在可接受的范围内,相比BILSTM-ATT-G模型,训练时间性能具有绝对优势.
2.4 距离特征分析
为验证本文对目标词语的邻近词位置重要性的假设,并观察距离窗口大小对模型分类性能的影响情况,本文在SemEval2014两个领域数据集上选取多种不同距离窗口尺寸进行实验,结果如图4所示. 可以看出,在两个数据集中,较小的p值性能更优,这也验证了模型最初的假设,即位于目标附近的单词比位于目标远处的单词更重要.

图4 距离窗口大小对模型性能影响分析Fig.4 The analysis of the influence of distance window on model performance
当模型距离窗口设置为2时,其最高分类准确率为74.1%;当距离窗口设置为4时,取得最好的分类准确率为72.4%. 由此可知,由目标此邻近的2-4个词卷积而成的特征具有更好的情感分类效果. 最后当距离窗口设置为8时,模型分类精度下降为64.1%. 实验结果表明距离窗口尺寸对于模型的性能有较大的影响,过大的距离窗口尺寸会引起语义风险. 随着邻近词选取的增加,模型的参数规模会线性增长,也给模型带来过拟合风险,导致模型性能下降. 另外,距离窗口大小的选择应根据具体应用场景灵活处理,面向不同的语料场景存在p值不固定的可能.
3 结论
在目标情感分类中,很多研究集中于注意力和基于RNN网络结合的方法,分类效果较好但模型训练时间较长. 本文提出了一种基于距离感知卷积神经网络的目标情感分类方法,该方法使用距离窗口模拟文本中每个单词与目标单词之间的距离信息,解决了手动生成特征的限制问题和基于RNN的方法的固有局限性. 实验结果表明,通过距离感知窗口可以对文本中每个词与目标词之间的距离信息进行建模并提高分类效果,加入距离特征的卷积神经网络模型的训练时间远小于基于循环神经网络的模型,较小的距离感知窗口的分类性能优于较大的距离感知窗口分类性能. 未来我们拟将注意力机制应用到所提出的CNN中,在考虑到每个单词到给定目标的距离时,将每个单词的重要性可视化,能够更准确地聚焦于重要的单词. 本文研究结果对目标情感分类领域的应用具有一定的参考价值.
