基于LightGBM的特征选择算法
2021-12-21李占山刘兆赓张家晨
李占山, 姚 鑫, 刘兆赓, 张家晨
(吉林大学 计算机科学与技术学院, 吉林 长春 130012)
特征选择是数据挖掘、机器学习等领域中的重要方向,其主要通过减少冗余与不相关特征、使用合适的搜索策略来寻找最优特征子集,力求在减小特征维度的情况下减少运行时间、提高模型精度.特征选择的目标是在满足给定某种泛化误差的条件下挑选最小特征子集;或选择指定个数的特征子集,并使其在原始样本上产生最小的泛化误差[1].依据方法自身与构建模型的关系,特征选择主要分为过滤式方法和包裹式方法[2].
过滤式方法对数据特征按照一定标准进行排序并选择表现较好的特征,由于这些标准独立于学习过程且单独评价每个特征的重要度,不考虑对结果的影响,因而过滤式方法通常具有较高的计算效率,却很难得到具有较高分类准确率的特征子集[3-4].
为克服过滤式的缺点,包裹式方法一般会引入学习器来评估所选的特征子集,并根据评估结果来选择特征子集,进而找到最优特征子集.该方法引入与学习器的交互后虽然增加了计算量,但通过不断交互通常能得到满足给定泛化误差的优秀特征子集[3-4].
过滤式方法运行效率较高,但由于其选择特征的过程并没有考虑到后续学习,因而得到的特征子集的分类精度一般低于包裹式,经常不能满足后续任务的需求;包裹式方法虽然能够得到具有较高分类精度的特征子集,但引入的交互过程降低了计算效率,增加了算法复杂度,故包裹式对要求短时间内求解的任务适应性较差.
在现有研究工作中,过滤式研究着力于采用某种度量标准在较低时间复杂度内得到特征子集,包裹式的研究力求通过不断的交互得到更高分类精度的特征子集.以上两类研究缺乏对特征子集计算效率和分类精度的协调与平衡.
为克服这两类方法的缺陷,本文采用LightGBM中两种特征重要度指标作为数据特征间的度量依据,并在此基础上提出一种包裹式的特征选择算法LGBFS(LightGBM feature selection),并将提出算法与对比算法在通用的21个UCI标准数据集上对分类精度、维度缩减率和CPU时间三种指标进行了对比,随后又进行了显著性分析与时间复杂度分析.
1 LightGBM系统
LightGBM[5]是由微软提供的一个迭代提升树系统,它是梯度提升决策树(GBDT,gradient boosting decision tree)经过改进后的一种变体.经典GBDT一般只采用损失函数的一阶负梯度,而它却同时使用损失函数的一二阶负梯度计算当前树的残差,并以此结果去拟合下一轮的新树.此外,它还采用了基于Histogram的决策树算法使得GBDT算法的执行可以节省一半时间,而且其采用最大深度限制的叶子生长策略使得算法的整体执行更加具有效率.
1.1 利用直方图算法构建决策树模型
相比原始数据的浮点形式,直方图数据占用内存更少、数据分隔复杂度更低,因而LightGBM处理数据采用直方图算法(Histogram算法).
直方图算法的思想为:将数据中每列特征值都转化为一个直方图,转化方法是对每个直方图都按照数据所在整数区间生成k个bin,随后将连续的浮点特征值按照所在的整数区间放入对应的bin中,以此对每个特征的所有特征值进行转换,即得到原始数据的直方图表示形式.
经过直方图算法计算后,原始的每个特征都转换为直方图,而原始的特征值也以整数的形式存储在每个直方图的所有bin中,因而LightGBM只需遍历每个直方图,并将每一直方图作为分割点计算分割收益,即可寻得最优分割直方图作为分割节点.在计算中,LightGBM使用了整数(每个离散值在直方图中的累计统计量,也就是某一直方图中某个bin的高度)代替原始数据的浮点值,这样有两个好处:一是起到了正则化的效果来防止树模型的过拟合,二是可以通过父节点与子节点中的一个做差来得到另一个子节点,从而节省了一半的计算量.
对于分割点的增益Gain,可定义如下:
(1)
式(1)说明对每一分割点而言,其增益表示为分割后的左、右叶节点的总权重减去分割前原节点的权重.
1.2 构建迭代树
LightGBM算法中的梯度提升决策树由给定的训练数据集多轮迭代得到,并在每一次迭代的时候都会使用梯度信息重新拟合一棵新树来加入前续迭代树,而这在函数空间上可以视作一种不断更迭的线性组合过程,形式化描述如下:
(2)
式中:χ是迭代树的函数空间;fq(xi)表示第i个样例在第q棵树中的预测值.
树的每一层分裂节点采用的都是最佳分割点,构建树模型时实际采用贪心方法.LightGBM通过综合所有叶子节点的权重作为构建树的参照,继而确定分割点并计算一阶梯度和二阶梯度.
1.3 特征重要度指标
根据Guyon等的研究[6],迭代树的启发信息可以作为特征的重要衡量标准,因此,基于树结构的度量将直接影响候选特征子集的质量,也最终决定了原始机器学习算法的实验效果.
对于任意给定的树形结构,LightGBM定义了每个特征在迭代树中被分割的总次数T_Split及特征在所有决策树中被用来分割后带来的增益总和T_Gain作为衡量特征重要性的度量标准,它们的具体定义如下:
(3)
(4)
其中,K为K轮迭代产生的K棵决策树.
2 LGBFS算法
本文主要采用LightGBM构建迭代树的过程来计算样本的特征重要性度量,提出了一种包裹式的特征选择算法LGBFS.
LGBFS采用一种适应LightGBM做启发式的序列浮动前向搜索方法[7]进行特征选择,并把分类准确率最高的特征集合作为特征选择的结果.特征选择问题从本质而言,可分为评估原始特征与搜索特征子集的两阶段算法.因此本文将LGBFS算法拆分为评估原始特征阶段与搜索特征子集阶段.
2.1 LGBFS评估原始特征
在评价阶段开始前,要将其构造为迭代树模型从而利用树形结构对特征进行评价,迭代树是由K轮迭代生成的K棵决策树分步迭加而成,每棵决策树生成方式相同,故本处仅给出构建单棵决策树的伪代码.
首先,采用直方图算法将原始转化为直方图.在转换过程中,一个叶子节点的Histogram可以直接由父节点和兄弟节点的Histogram做差得到,称为差加速,体现在算法2中.随后,确定分割点时利用一阶梯度gi和二阶梯度hi进行计算,每次都选取具有最大Gain的特征进行分割并在每层分裂时都贪心选取最佳分割点.
而对于给定的训练集X,上述步骤具体细节如算法1和算法2伪代码所示,其中算法2是算法1的支撑代码.
观察上述模型,可以得到结论:一个特征可能被多次分割;特征被分割次数越多,整棵树的增益也越多.这两个结论说明:某些特征应在子集选择阶段被优先考虑.
利用DecisionTree算法构建决策树模型后,可得到上文所描述的某一特征的重要性度量Split和Gain.而利用LightGBM构建整体的迭代提升树后,可用式(3),(4)算出所有特征的T_Split和T_Gain,就得到了所需的经过树形结构评价后的原始特征集及重要度集合.

算法 1 DecisionTreeInput: X: training data, C: number of leaf, l: loss function Output:Split, GainT1(X)← X //Put all data on rootfor min(2,C) (Gain,pm,fm,vm)←FindBestSplit(X,Tm-1,l) Tm←Tm-1(X).split(pm,fm,vm) /∗ Perform split ∗/ Split←Split+1end for算法2 FindBestSplitInput: X: training data, Tm-1(X): current model H: histogram data, g: first order gradient, h: second order gradientOutput:pm: leaf on split point, fm: feature of certain dimension, vm: value of maximum gain of fm,Gainfor all Leaf p in Tm-1(X) do for all f in X.Features do H ← new Histogram() for i in usedRows do /∗Go through all the data row∗/ H[f.bins[i]].g← H[f.bins[i]].g+gi H[f.bins[i]].h← H[f.bins[i]].h+hi end for for iin len(H) do /∗ Go through all the bins∗/ SL←SL+H[i].g hL←hL+H[i].h SR←SP- SL /∗Difference acceleration∗/ hR←hP-hL Gain←S2L/hL+S2R/hR-S2P/hP if Gain >(pm,fm,vm) then (pm,fm,vm)←(p, f, H[i].value) end if end for end forend for
2.2LGBFS搜索特征子集
在子集搜索阶段,首先按照得到的重要度特征索引重新对原始数据集进行排序,随后采用一种基于LightGBM重要性度量的序列浮动前向搜索方法LRSFFS对特征子集进行浮动搜索,即每次加入L个特征使得特征子集性能更加优异;此外,在每次循环时也尝试去除R个特征使得特征子集的性能更加稳定优异.
LRSFFS搜索策略的优势在于能够交叉浮动的选择特征,从而较好避免特征子集陷入局部最优,而浮动思想也能够尽可能地兼顾特征之间的相关性,具体伪代码给出如下.

算法3 LRSFFSInput:S1: feature subset from sorting according to T_Split in descending order, S2 feature subset from sorting according to T_Gain in ascending orderOutput:Y: objective feature setY←∅while S1≠∅ do i, j← 0 while S1≠∅ do x+← S1.top ifJ(Y+x+)>J(Y)then Y←Y+x+ i← i+1 end if if i==Lthen break end if end while while j≠Rdo x-←S2.top ifJ(Y-x-)>J(Y) then Y←Y-x- j←j+1 end if end whileend while
实验结果表明,LRSFFS策略能在一定程度上减少这些特征子集搜索问题的局限性,故取得了优于其他方法的更好结果,其时间复杂度将在第4章讨论.
3 实验及分析讨论
3.1 数据集与对比算法
本文从UCI[8]数据库中选择了21个数据集对算法进行测试.表1中列出了这些数据集的名称、特征数和实例数.
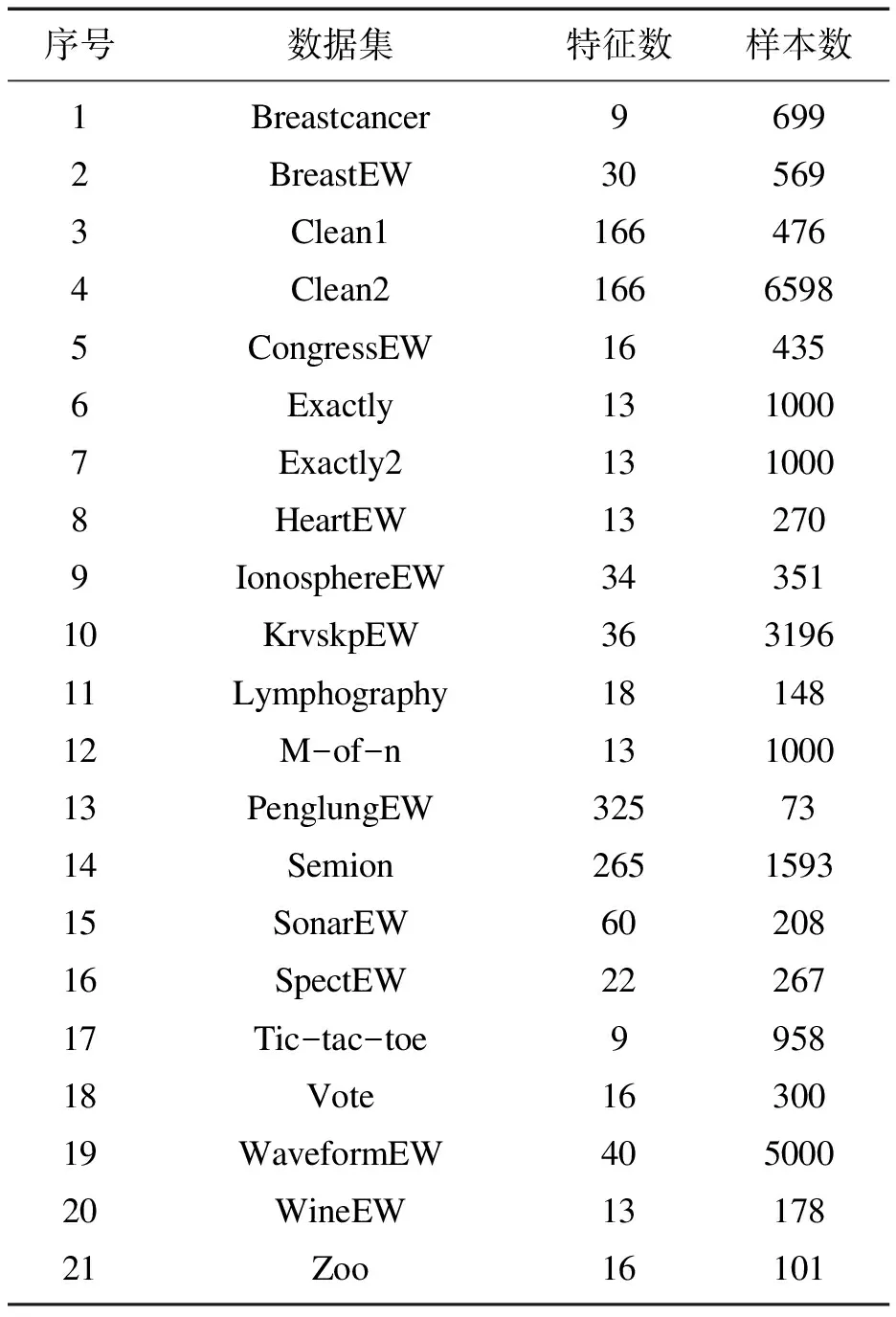
表1 数据集详细信息
为说明LGBFS算法性能的优越性,选择9种近年来具有代表性的算法(表2)进行对比.
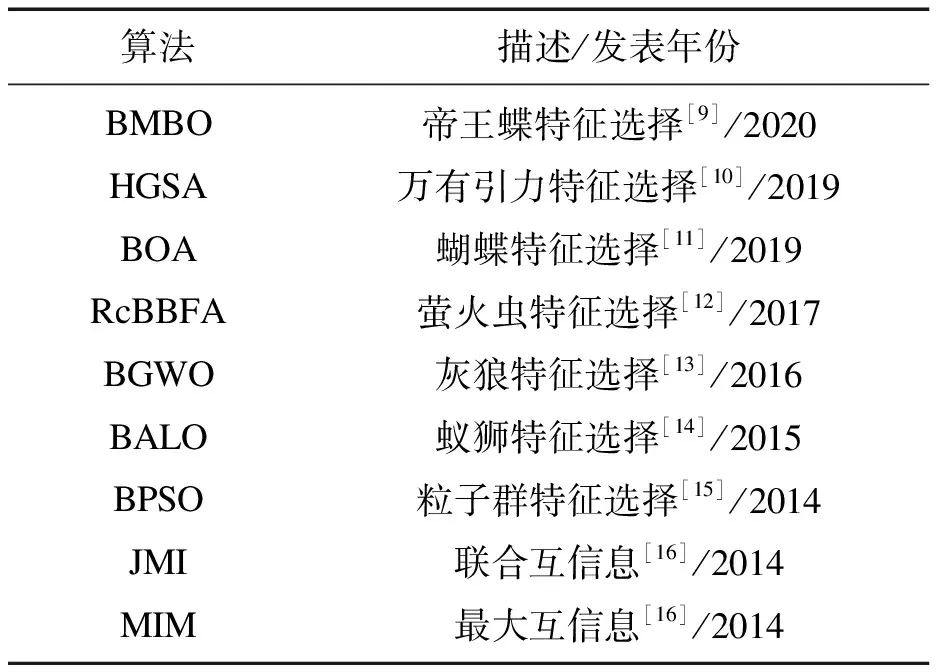
表2 对比算法的详细信息
3.2 实验参数设置及实验环境
给出本文所提算法LGBFS与9种对比算法的参数设置(表3).全部算法均采用30次独立重复实验,数据集划分方法统一为80%作为训练集,20%作为测试集.用于验证特征子集分类性能的分类器为KNN(K近邻,K=5)分类器, 因为KNN本身实现简便、稳定、参数少,在特征选择领域得到了广泛认可,许多工作[10-11,13-14]仅把KNN作为唯一的基分类器.

表3 实验参数设置
LGBFS采用的参数L,R分为3组,其具体含义为:当数据集的特征维度小于50时采用第一组参数,特征维度在50至200时采用第二组参数,特征维度大于200时采用第三组参数.此外,所有基于演化学习的特征选择算法粒子数设为10,迭代次数设置为100.
算法的实现环境为Python语言在PyCharm下的3.7.6版本,使用公开包LightGBM和scikit-learn.计算机配置为:CPU I7-7300K,内存8 GB,硬盘1 TB.
3.3 实验结果分析与检验
为表述实验结果,使用分类准确率(classification accuracy, CA)、维度缩减率(dimensionality reduction, DR)和CPU时间(CPU time)三种指标用于检验特征选择算法的性能,CA与DR的具体定义如下.
CA=N_CC/N_AS ,
(5)
DR=1-(N_SF/N_AF) .
(6)
式中:N_CC(number of correct classification)为正确的分类数;N_AS(number of all samples)为数据集的实例数;N_SF(number of selected feature)为选择的特征数;N_AF(number of all features)为特征总数.
表4,表5给出21个数据集上LGBFS与9种算法在分类准确率和维度缩减率上的对比结果.最后一行的W,S,L代表所提算法与对比算法胜、平、负的统计量.表6给出CPU运行时间的对比结果.表4~表6中下划线代表最优结果.
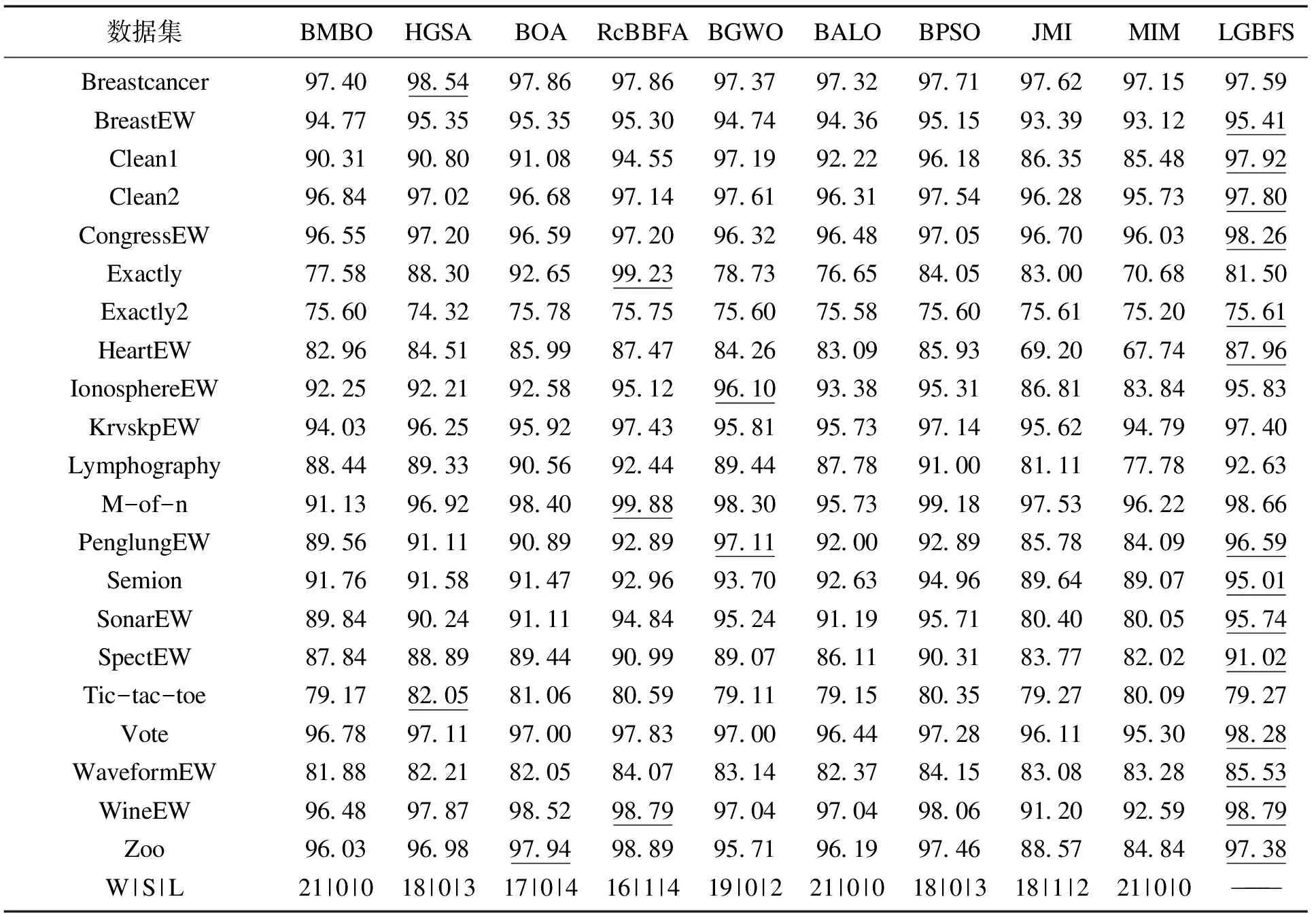
表4 LGBFS与9种算法在平均分类准确率上的对比
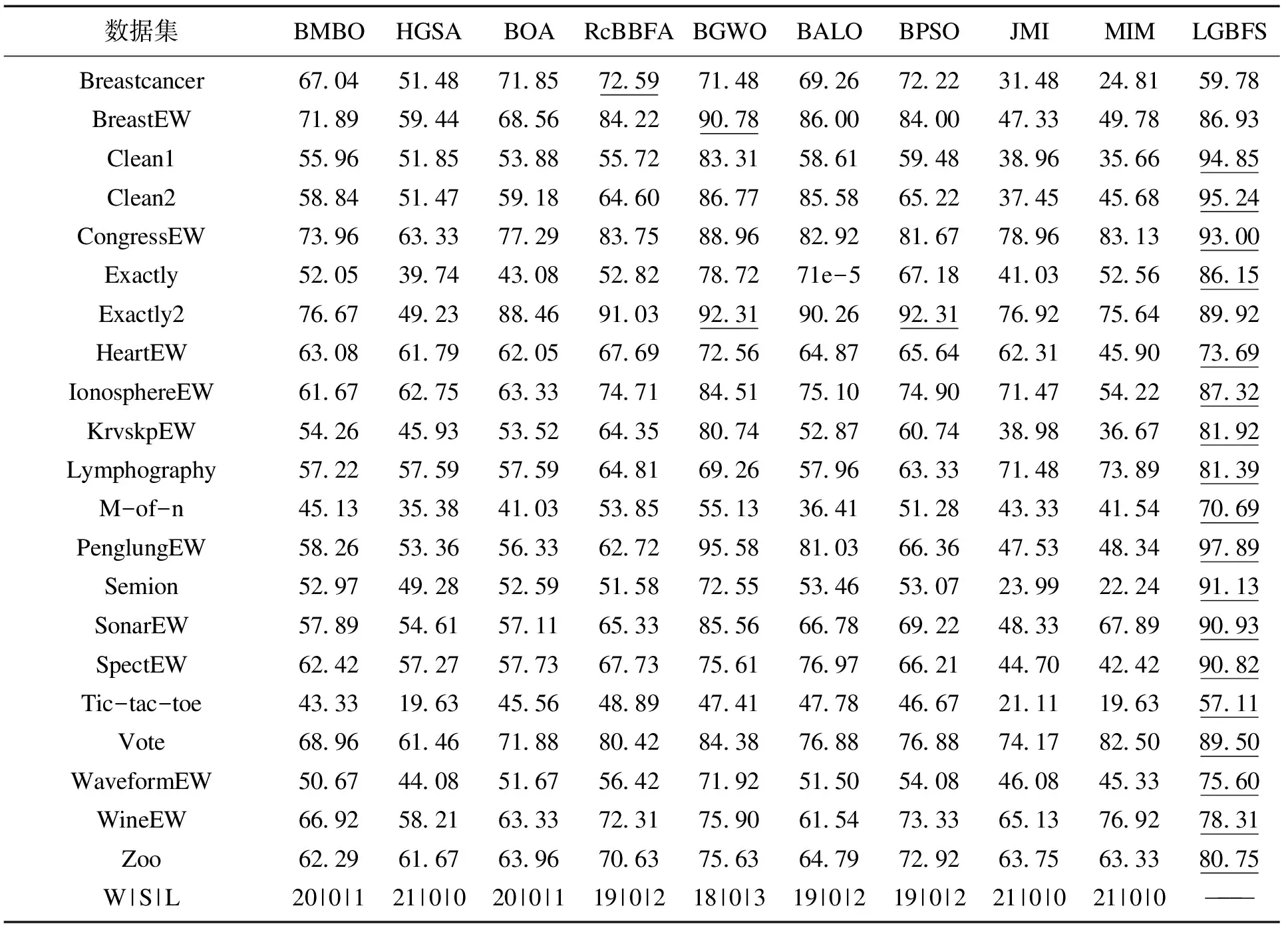
表5 LGBFS与9种算法在平均维度缩减率上的对比
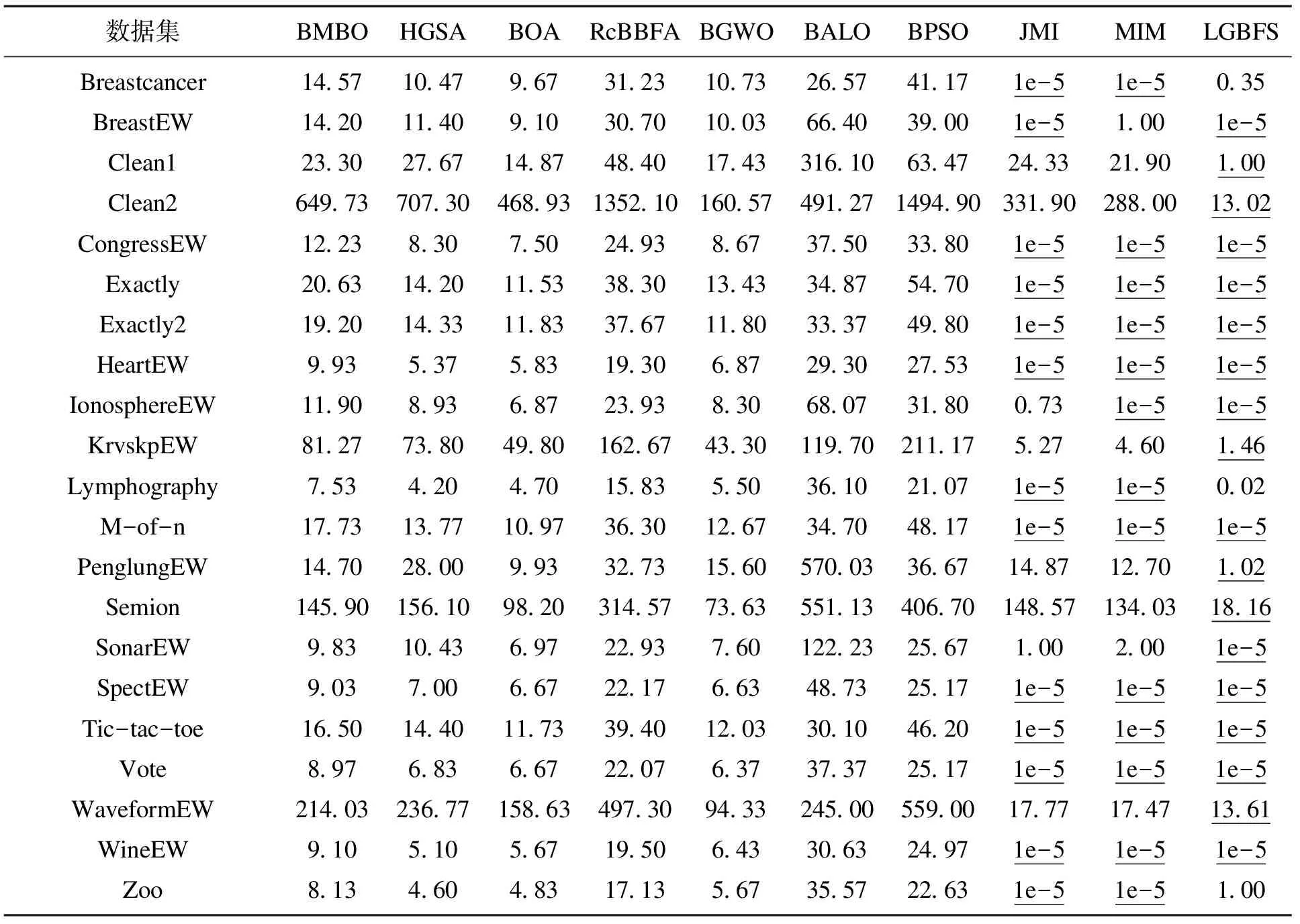
表6 LGBFS与9种算法在平均CPU时间上的对比
首先,观察表4的分类准确率结果,LGBFS在16个数据集的分类准确率均达到最高,而在未达到最高的5个数据集上相较最优结果也未存在明显差距.因此,可以认定LGBFS在多数数据集上效果达到最优或次优.再观察未能到达最优的5个数据集,可以发现这5个数据集均为20维以下的低维数据集,而LGBFS在构建树模型时需要构建较深的树形结构才能平衡掉贪心选取最优节点所带来的局部最优性,因而LGBFS算法更适合处理中高维度,实验结果也对此进行了验证.
再对表5的维度缩减率进行观察,LGBFS在被选中的21个数据集中的18个数据集上达到最优,2个数据集上达到近似最优.简而言之,可以认为LGBFS在近似全部数据集上有着更高效的维度缩减率.进一步观察,发现在维度超过100的高维数据集上,LGBFS相对其他算法总能在满足较高的维度缩减率的前提下获得同样较高的分类准确率,这也再次说明利用LightGBM评估特征的合理性和有效性,充分印证了LGBFS能够通过特征之间的内在关联找到更相关的特征并进行维度缩减,而并非仅以分类准确率的提高作为算法运行的第一要义.
随后对表6的CPU运行时间进行观察,可以发现LGBFS虽然是包裹式的特征选择算法,却并未像基于演化学习的特征选择算法需要复杂的计算量和较长的计算时间,而这是由LGBFS设计理念的完整性和设计结构的精简性所决定的.LGBFS力求在演化式包裹特征选择算法和过滤式算法中做出平衡,既希望能够得到具有优秀分类性能的特征子集,又希望能够用较少的计算时间和较小的计算量完成特征选择这一阶段的任务,从表6中可以看出,LGBFS在全部数据集上的运行时间都远优于传统的演化特征选择算法.粗略计算,LGBFS比每种演化包裹式特征选择算法快100倍以上,即使与公认计算效率最优的过滤式算法相比,LGBFS在大部分数据集的CPU运行时间指标依然处于平手,甚至在个别数据集上超过了过滤式的JMI和MIM算法的运行时间.LGBFS出色地在特征选择的计算量和特征子集的最优性间做出了平衡.
最后,为定量讨论LGBFS算法相较对比算法的有效性与显著性,本文采用了非参数的威尔森秩和检验[17](Wilcoxon rank-sum test)来确认9种对比算法与LGBFS是否有统计学上的差异(显著性水平设置为0.05),威尔森秩和检验定义如式(7)所示:
(7)
其中:CA为分类准确率;M为所使用数据集的数量;i代表21个数据集中第i个数据集;j表示9种对比算法中第j个算法;k代表30次独立重复实验的第k次实验;Wjk代表第j个对比算法相较LGBFS在第k次实验在全部数据集上的威尔森秩和检验结果.
9种对比算法的检验结果于表7给出.其中6种算法相较LGBFS的p值小于或近似等于0.05,这在统计学上表示测试拒绝默认值5%显著性水平下的中位数相等的零假设,证明了无论初始解决方案和整个搜索过程中采用的随机决策如何,LGBFS总能够找到相较其他6种算法更优异的特征子集.
通过威尔森秩和检验,既定性地分析了LGBFS的准确性与高效性,又定量地验证了LGBFS显著性与有效性.

表7 LGBFS相较9种算法在分类准确率上的威尔森检验结果
4 时间复杂度分析
分析算法LGBFS的时间复杂度,对数据集给定如下假设:给定无缺失值的具有N个样本、M个特征的数据集X,设D为树模型最大树深、T为决策树的棵数且非零重要性特征的比例为β,则m=βM,对于数据处理阶段的直方图算法,每一特征的N个特征值被分配进k个bin中(k≪N),则直方图算法时间扫描数据的复杂度为O(kM).
得到每个特征对应的直方图后,树节点的分裂对应直方图的分裂,在遍历每层特征的直方图后就确定了最佳分割点,时间复杂度仍为O(kM),对于建立最大深度为D、数量为T的迭代树模型的总计时间复杂度为O(kMDT).采用快速排序对度量后的子集排序时间复杂度为O(mlogm).
最后考虑搜索策略LRSFFS算法,由于L,R均为常数,故向项添加与后向去除的时间复杂度均为O(m),而浮动的过程导致迭代的前向交叉浮动,所以浮动算法时间复杂度为O(m2×KNN),而KNN的时间复杂度可近似表示为O(mNlogN),所以LRSFFS的总时间复杂度为O(m3NlogN).
故LGBFS算法总时间复杂度可近似表示为O(kM+mlogm+kMDT+m3NlogN).
5 结 语
本文提出了基于LightGBM的包裹式特征选择算法LGBFS,该算法利用树形信息度量特征集合,提出一种新型的序列浮动前向选择策略用于特征选择.经过21个数据集和9种特征选择算法的对比实验,验证了LGBFS算法的良好性能,对L与R参数的自适应化将是下一步的研究内容.
