基于多尺度分层双线性池化网络的细粒度表情识别模型
2021-12-20苏志明蓝峥杰
苏志明,王 烈,蓝峥杰
(广西大学计算机与电子信息学院,南宁 530004)
0 概述
人脸表情识别(Facial Expression Recognization,FER)旨在通过识别人脸表情使机器能够理解人的内心感受。该技术在远程教育、辅助医疗、安全驾驶、人机交互、公共安全等多个领域具有广泛应用[1],相关人脸表情识别研究已成为人工智能主要研究热点之一。
早期的表情识别基于传统特征提取方法,大体上可分成3 种:基于线性变换,如主成成分分析法[2](Principal Component Analysis,PCA);基于纹理特征,如局部二值模式法(Local Binary Pattern,LBP)[3];基于几何,如主动形状法(Active Shape Models,ASM)[4]和主动外观模型(Active Appearance Model,AAM)[5]。但这些方法存在特征提取不充分导致识别率低的问题。由于深度学习可以从端到端地学习更多差异化的面部表情特征,且与传统方法相比具有更高识别率,因此研究人员致力于将深度学习应用于面部表情识别,基于深度学习的人脸表情识别算法也层出不穷。文献[6]改进了AlexNet,引入多尺度卷积提取多尺度特征和利用全局平均池化将低层特征降维跨连到全连接层分类,在CK+人脸表情数据集的准确率达到94.25%。文献[7]提出利用小尺度核卷积代替大尺度核卷积的神经网络模型,在FER2013 数据集上取得了73.39%的识别率。LIU 等[8]将课程学习策略应用到卷积神经网络训练阶段,在FER2013 数据集上达到72.11%的识别准确率。LI 等[9]改进了经典模型LeNet-5,通过将池化层的特征跨连到全连层,有效融合了高低层特征分类,在JAFFE 和CK+这2 个公开人脸表情数据集的识别率分别达到94.37%、83.74%,但改进后的模型人脸表情识别率仍然有待提高。ZHANG 等[10]提出一种基于注意力分层双线性池化残差网络的表情识别方法。该方法在ResNet-50 的框架基础上嵌入有效通道注意力机制,并引入分层双线性池化网络以交互同一网络不同层级间的特征,取得了不错的人脸表情分类效果。但该方法仅交互同一网络中来自3 个不同层级间的特征,缺乏不同网络不同跨层的多尺度特征表达,因此面部表情细微特征表征能力有待进一步提升。
目前,国内外在表情识别领域已取得较大进展,但人脸表情识别算法仍面临众多挑战。总体而言,人脸表情识别研究仍需要解决复杂环境下的表情识别、模型层间交互和模型多层特征融合等问题。
本文设计并训练应用于人脸表情分类的3 种粗细尺度网络,并构建一个基于多尺度双线性池化卷积神经网络的识别模型。通过分层双线性池化捕捉不同网络的多尺度特征,挖掘神经网络对嘴巴、眉毛、眼睛等面部表情关键区域细微变化的辨别力,同时提出一种多层信息融合的方法获取有用的低频信息,从而提高人脸表情分类性能。
1 卷积神经网络
1.1 神经网络结构
本文提出多尺度分层双线性池化网络(Multi-scale Hierarchical Bilinear Pooling Network,MHBP)模型如图1 所示。3 列网络分别使用卷积尺度核为3、5、7 的不同粗细尺度网络,以提取更为精细的人脸表情特征。每列网络有9 个卷积层、3 个最大池化层。3 列网络有共同的人脸表情图像输入,通过分层双线池化网络交互3 列网络最后同一深度位置的后3 个卷积层的特征图,集成同一网络以及不同网络的不同跨层特征,捕获不同层级间的部分联系,以便于后续人脸表情特征分类。因集成的特征维度过高,冗余特征多,直接用以分类并不适用,所以需添加2 层全连接层过滤特征以实现表情分类。图中仅给出了网络最后一层卷积层输出的特征图跨层交互简略示意图,忽略了其他层,具体交互的机制见1.3.2 节。
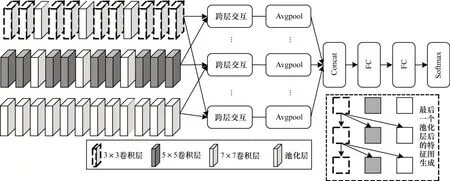
图1 多尺度分层双线性池化网络结构Fig.1 Multi-scale hierarchical bilinear pooling network structure
为更好地利用主干网络的不同尺度特征,本文提出了多尺度注意力交互模块,如图2 所示。
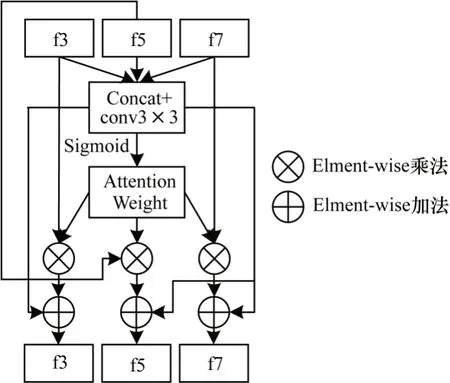
图2 多尺度注意力交互模块Fig.2 Multi-scale attention interaction module
该模块先将3 个粗细尺度网络的特征图f3、f5 和f7 经3×3 融合,一分支经Sigmoid 函数激活生成特征权重后分别与特征图f3、f5 和f7 元素相乘得到重新标定的特征图,最后分别与另一分支经PReLU 函数[11]激活后的融合特征元素相加得到最终的各自输出。该模块可根据反向传播自我更新学习,自动选择各支路需要融合的多尺度特征。该模块在本网络训练测试时加入位置为网络前3 个池化层前的2 个卷积层之间,共添加3 个。
1.2 模型参数配置
MHBP 模型的具体参数配置如表1 和表2 所示。表1 和表2 省略了主干网络多尺度特征融合模块。根据输出特征图分辨率的不同,可分为4 个阶段,每个网络的前3 阶段均有2 个卷积,后一个阶段有3 个卷积。3 个网络拥有共同输入为48×48 大小的人脸表情图像灰度图。3×3、5×5、7×7 网络的卷积核尺寸分别为3×3、5×5、7×7,步长和填充均为1,卷积核个数均为32。Maxpool 中的(3,2,1)表示滤波器尺寸为3×3,步长为2,填充为1。输出特征图为h×w×c,其中:h、w分别为特征图的高和宽;c为特征图数量即卷积核的数量。通过双线性池化集成了18 组512 维人脸表情双线性特征向量。为避免模型过拟合,通过提高模型的泛化能力进一步提高人脸图像分类准确率。在每个池化层后加入Dropout网络,丢弃概率为0.1。同样地,在汇合分类阶段,2 层全连接层后均加入BN(Batch Normalization)和Dropout 网络,其中Dropout 网络丢弃的概率为0.5,目的是加强网络挖掘隐藏特征的能力,从而提升模型性能。第1 个全连接层与1 024 个神经元完全连接,而第2 个全连接层与512 个神经元完全连接。输出层是由7 个神经元组成的Softmax 层,用以预测7 种表情的输出。
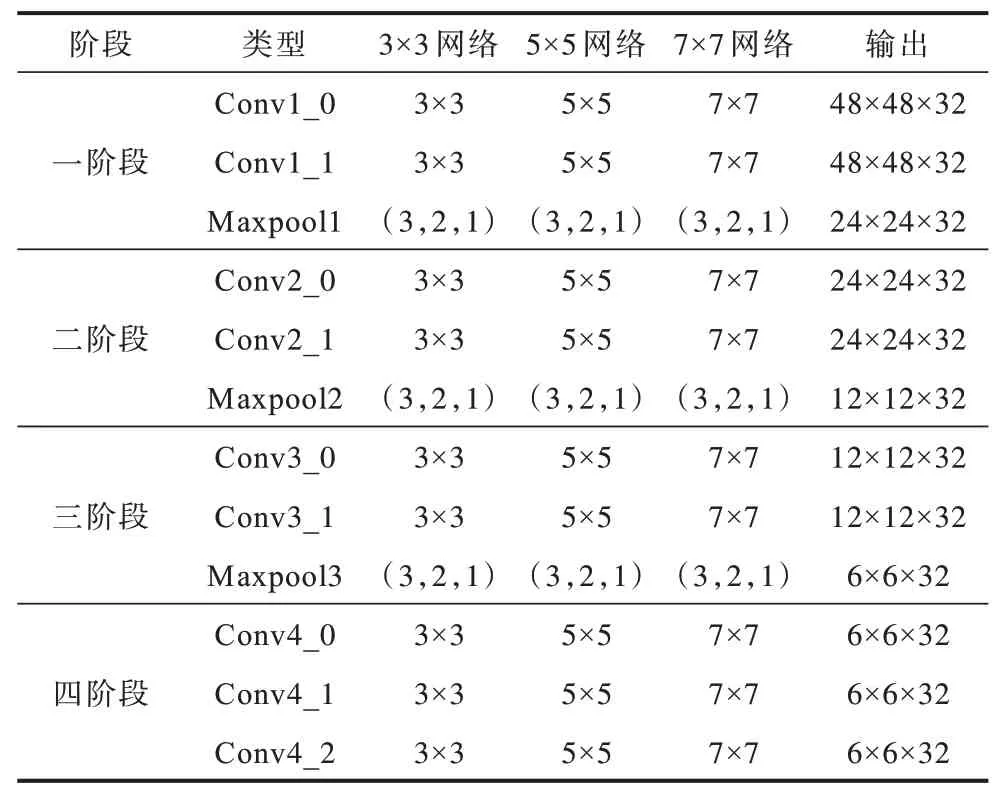
表1 MHBP 模型参数配置1Table 1 Parameter configuration of MHBP model 1

表2 MHBP 模型参数配置2Table 2 Parameter configuration of MHBP model 2
1.3 分层双线性池化
分层双线性池化[12]对局部成对特征的交互式建模已被证明是解决细粒度识别问题的有力工具。为获得更好的表情特征表达,提出了一种在细粒度识别任务背景下的表情挖掘方法。通过在不同跨层中交互建模,融合同尺度网络和不同尺度网络不同卷积层的中间层特征,实现表情识别。
1.3.1 工作原理
分层双线性池化模型基于分解双线性池化模型[13]构建。因子分解双线性池化的过程为:将经粗细尺度主干网络提取的特征图记为X∈ℝh×w×c,其中h、w、c分别为特征图的高度、宽度、通道数。令x=[x1,x2,…,xc]T为X上的一个空间位置c维描述符。双线性模型的定义如下:

其中:zi为双线性模型的输出;Wi∈ℝc×c为投影矩阵。双线性模型可将Wi分解为低阶外积运算得到输出特征:

其中:P∈ℝd×o为分类矩阵;d为决定嵌入维度的超参数;o为图像分类类别总数;U∈ℝc×d和V∈ℝc×d为从c维特征向量中获得d维池化特征向量的投影矩阵;◦为哈达玛积。
双线性池化捕获成对表征关系,是细粒度识别的重要技术。因为判断人脸表情属性的重点区域只有眼睛、眉毛、鼻子、嘴角附近区域,属于精细工作,因此可借助双线性池化完成。但若只关注单一卷积层,完全忽略信息的跨层交互,将导致人脸表情分类效果不佳。这是因为单个卷积层的激活不完整,每个表情均有多个属性,例如嘴的形状、嘴角的弧度等,而这些对表情的细微变化至关重要。不同卷积层之间的层间特征相互作用能够帮助捕获细微表情的区别性特征。利用跨层双线性池集成更多中间卷积层,进一步增强表情特征的表征能力。通过独立的线性映射(1×1 卷积)将来自不同卷积层的特征扩展到高维空间。集成不同跨层表情特征的输出表达式为:
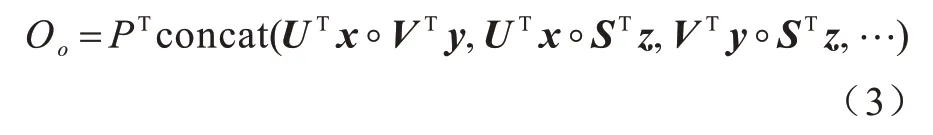
其中:U∈ℝc×d,V∈ℝc×d,S∈ℝc×d,…分别为需要的交互跨层卷积层特征x,y,z,…的投影矩阵。将聚合的来自不同跨层的表情特征输入至全连接层和Softmax 分类中,Softmax 分类损失函数定义如下:
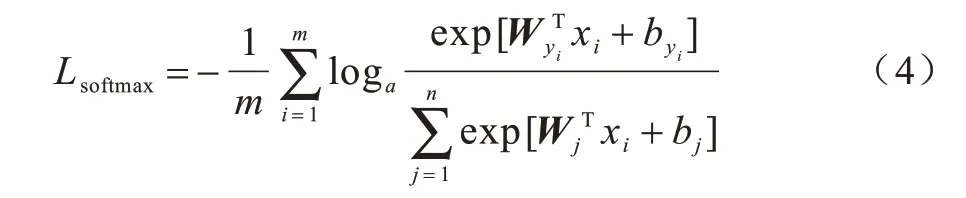
其中:m为样本数;n为总类别数,因本文需识别7 种面部表情,故取值为7;x为分类前全连接层的输入特征向量;b为偏置量表示第i个样本全连接层输出矩阵中预测类别为真实类别的目标判定。
1.3.2 交互机制
为捕获不同尺度层间特征关系,本文分层双线性池化跨层融合了来自同一网络及不同网络的不同卷积层特征,需要融合的层为经PReLU 函数激活的不同尺度网络最后3 层卷积层(Conv4_0,Conv4_1,Conv4_2)见表3。PReLU4_0_j,j=0,1,2。其中:j为第几列网络标号;0 为3×3 网络;1 为5×5 网络;2 为7×7 网络。
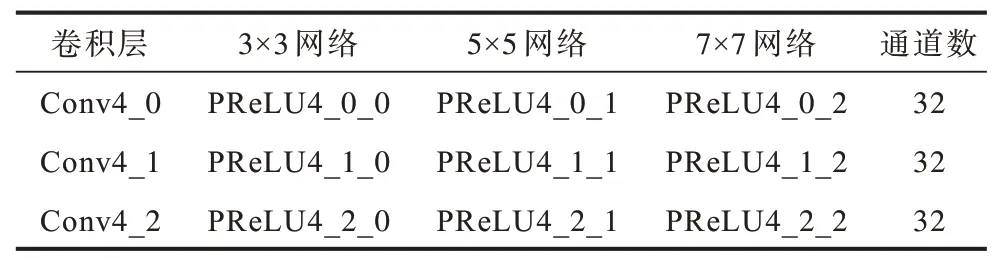
表3 双线性交互层列表Table 3 Bilinear interaction layer list
现将双线性汇合不同跨层特征分为以下3 类:
1)同一网络不同层级特征。将3 种网络最后3 个卷积层经PReLU 函数激活后的特征图分别在同一网络内两两交互,得到共9 组双线性特征。
具体交互的双线性特征计算表达式如下:

图3 所示为同一网络不同层特征交互示意图,其中,每列特征分别对应3×3、5×5、7×7 网络的最后3 个卷积层经激活函数激活后的输出特征每个虚线框代表一组特征两两交互。
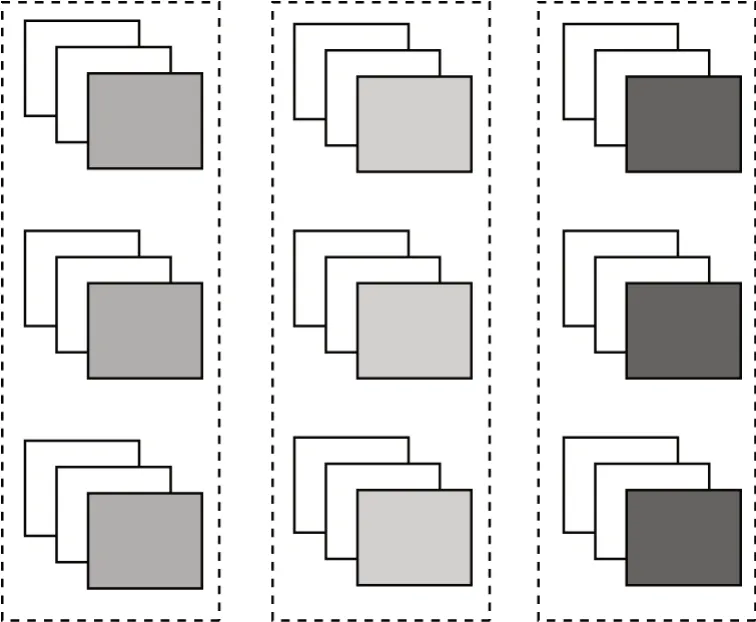
图3 同一网络不同层的特征交互Fig.3 Feature interaction between different layers of the same network
2)不同网络不同层级特征。为使不同尺度网络的不同层特征交互,增加了2 个限制条件:
(1)每个网络最后一个卷积层必须参与交互。这是因为一方面目前主流的神经网络分类模型通过最后一层卷积提取的特征直接展平为一维向量,或者先通过全局平均池进行降维,然后平铺为一维向量分类。另一方面,神经网络的最后一层通常包含输入图像的高频和全局特征信息,适合分类。
(2)不同网络的不同层存在互斥。以不同网络不同层做为一组,分为3 组,每组有3 个层两两交互,共得9 组双线性交互特征。
具体交互的双线性特征计算表达式如下:

如图4 所示,3 种不同颜色的箭头指向的不同层级特征图为3 组需要交互的特征。其中,每种颜色箭头包函3 个不同网络不同层的特征。
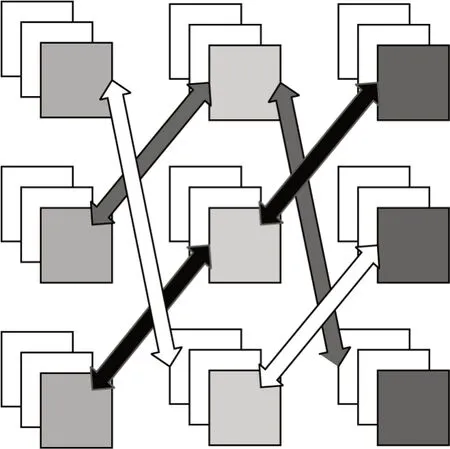
图4 不同网络不同层的特征交互Fig.4 Feature interaction between different layers of different networks
3)不同网络同一深度位置特征。以同一深度层做为一组,可分为3 组,每组内有3 个层两两交互,共得9 组双线性交互特征。具体交互的双线性特征计算表达式如下:

不同网络同一深度特征交互示意图如图5所示。
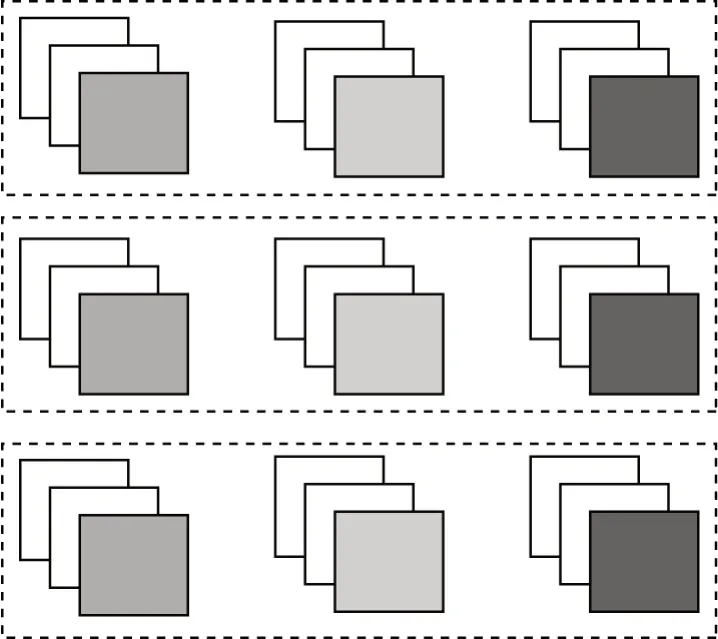
图5 不同网络同一深度的特征交互Fig.5 Feature interaction in the same depth of different networks
1.4 多层信息融合
当卷积神经网络向前传播时,通过逐层卷积获得高频信息,将最后一层提取的特征输入到全连接层并进行分类。逐层过滤将丢失一些低频特征信息,如纹理、边缘等细节信息,导致信息无法得到充分利用。为获取有用的低频信息,从而提高人脸表情图像的识别率,本文提出一种多层信息融合(Multi-layer Information Fusion,MIF)方法。该方法通过反卷积将当前卷积层输出的激活值转换为新的激活值,并逐层融合、逐层降维,最后将其输入全连接层分类,如图6 所示。
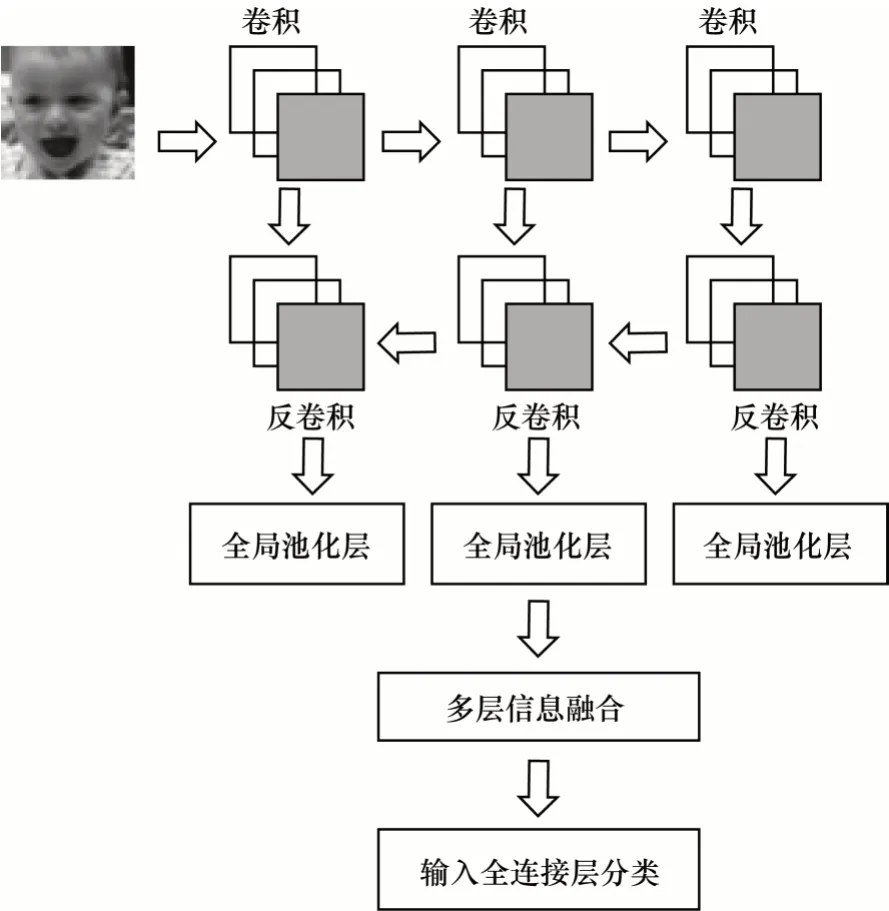
图6 多层信息融合Fig.6 Multi-layer information fusion
若将没池化前的卷积层记为一个阶段,则MHBP 网络共有3 个同一深度位置的池化层,故可将卷积分为4 个阶段。图6 中的卷积为MHBP 网络一个阶段的卷积,前3 个阶段的每个阶段均有6 个卷积层,最后一个阶段共有9 个卷积层。多卷积层特征具体融合的过程如下:
步骤1将最后一个阶段n的9 个卷积层输出的特征图激活值通过torch.cat 拼接,通过1×1 卷积融合降维为上一个阶段所有卷积层特征图的维数(这里取32×6=192),并通过BN 和PReLU 函数激活得到激活值。接着将其输入到反卷积层得到特征图激活值。
步骤2将步骤1 中得到的激活值和拼接后上一阶段n-1 的所有卷积层的激活值做加性融合。融合后的特征图c×h×w共有2 分支操作,一分支通过全局平均池化降维得到压缩特征图c×1×1,另一分支继续通过反卷积得到特征图c×h×w激活值。降维的目的是减少参数,加快网络运行。
步骤3执行步骤1 一次,重复步骤2 两次可得到3 组降维特征图,将其拼接融合后展开为一维向量,则共有32×6×3=576 维表情特征向量,将其添加到MHBP 网络的全连接层进行人脸表情分类。
2 实验
2.1 实验环境
FER2013 实验在型号为GTX2080Ti 的Pytorch框架上进行,batch_size=128,初始学习效率为0.01,60 个epoch 后每10 个epoch 衰减0.9 倍。模型优化器为SGD,动量为0.9,权重衰减为0.001。为提高模型的泛化能力,引入一种数据增强方式Mixup[14],该方式主要用于图像分类,可用来提高模型的表情识别率。从训练样本中随机抽取2 个样本进行简单随机加权求和,样本的标签也对应于加权求和。通过加权求和,计算预测结果与标签之间的损失,并用逆导数更新参数,计算式如式(8)和式(9)所示:

其中:xi和xj为原始图像输入向量;yi和yj为one-hot标签编码。其数据增强方式与文献[15]类似,区别是增加了随机旋转,角度为0.5。计算数据集的均值和方差后,再归一化输入到网络训练和测试。使用Xavier 系统进行初始化,训练时将表情图片尺寸预处理为52×52,再随机剪切为48×48,训练和测试时采用TenCrop 方法,将图像沿左上角、右上角、左下角、右下角、中心剪切并水平翻转,取人脸表情识别率的平均值做为模型最终表情分类准确率。
2.2 数据集
FER2013[16]数据集共有35 888张人脸表情图像,其中训练样本28 709 张,公开测试样本和私有测试样本各3 589 张。采用私有测试样本测试。FER2013 数据集由Python 爬虫获得,存在人脸角度、遮挡、光照条件、头部姿态变化、噪声等复杂环境,满足本文研究要求。
CK+数据集[17]是国内外研究人员常用的面部表情识别研究课题的基础数据库,具有较高的认可度,共593 个图像序列,其中带标签的表情序列有327 个,从每个序列中提取最后3 个帧,共981 张。CK+实验去掉了中性表情,取剩下的生气、厌恶、害怕、高兴伤心、惊讶、蔑视等表情做为实验数据。2 个数据集人脸表情示意图如图7 所示。

图7 不同数据集人脸表情Fig.7 Facial expressions in different data sets
2.3 实验结果与分析
实验1不同方法的有效性验证。不同方法的表情识别率如表4 所示。前3 个方法实验网络架构的池化层前卷积只有一个,网络使用2×2 池化且池化后没有加入dropout 网络,在FER2013 人脸表情公开数据集上的识别率仅为72.081%,而使用3×3 重叠池化且加入dropout 后,识别率为72.75%,提升了0.669 个百分点。这说明dropout 在防止模型过拟合的同时还能增强网络的学习能力。延长训练次数识别率有所提高,说明网络还没有完全收敛。当将每个最大池化前的卷积添加到2 个时,网络的表情特征提取能力得到增强,表情识别率达到了73.725%,提升了0.724 个百分点。由于硬件资源的限制,本文算法没有继续通过增加卷积层数来探索网络性能。

表4 不同方法的表情识别率对比Table 4 Comparison of expression recognition rates of different methods %
实验2不同层的特征交互有效性验证。实验2在实验1 的基础上进行,将同一网络不同层级的特征交互记为x1,将不同网络不同层级特征交互记为x2,将不同网络同一深度位置特征交互记为x3。在FER2013 数据集上通过分层双线性池化集成不同跨层的双线性特征对比实验如表5 所示。当集成同一网络不同层级特征和不同网络不同层级特征时,表情识别率最高为73.725%,说明模型捕获了不同跨层间特征的部分联系,也说明了多尺度双线性池化的有效性。模型集成特征x1、x2与单集成特征x1,集成特征x1、x2、x3相比,表情识别率分别提高了0.494、0.278 个百分点。通过双线性池化集成过多的不同跨层特征容易导致冗余特征过多,不利于面部表情分类。

表5 FER2013 数据集不同层特征交互结果Table 5 Interaction results of different layer features of FER2013 data set %
实验3不同高维空间的模型性能分析。将不同层次的特征升级到高维空间后采用分层双线性池的方法提取双线性特征,将对人脸表情识别的准确性有一定的影响。FER2013 测试集的准确率随不同维度空间变化的曲线如图8 所示。随着维数的增加,人脸表情识别的准确率逐渐提高(不同维度空间中0~200 的低点在误差范围内),当维数为400~600时达到最大值,之后随着维数的增加识别率逐渐降低。
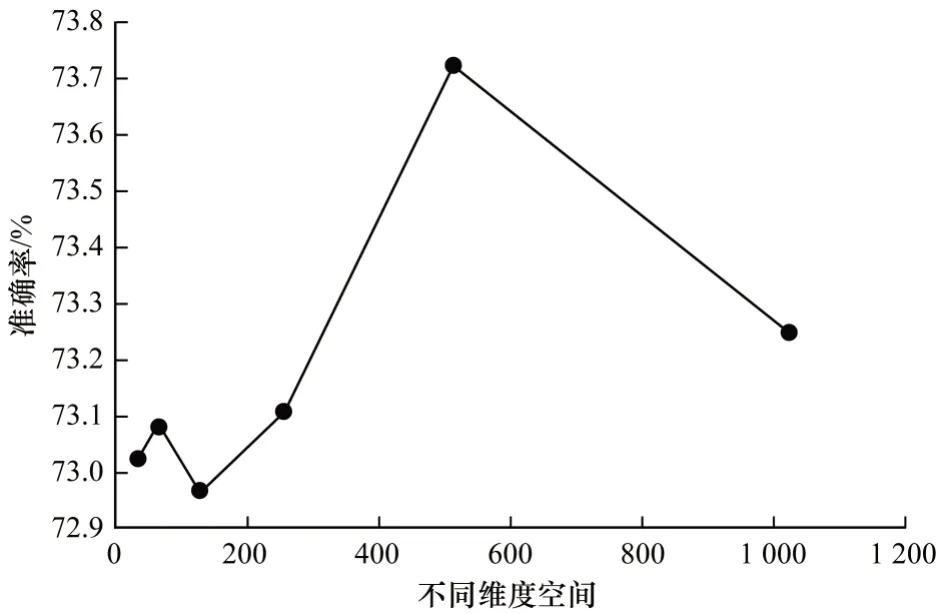
图8 不同维度空间对识别率的影响Fig.8 Influence of different dimension space on recognition rate
为更直观地看到不同维度空间的表情识别率,表6 给出了具体的数值。当尺寸从初始值32 上升到64、128、256 时,精度呈现非线性提高但幅度有限。当维数升级到高维空间值512 时,模型的识别率可高达73.725%,当维数升级到1 024 个超高维空间时,模型的识别率下降到73.252%。这说明将维数提升到合适的高维空间可以提高模型的表情识别率,且当维数过低时,由于缺乏有效的人脸表情特征分类导致分类性能低下;但维数过高时,过多的冗余特征将影响分类性能。
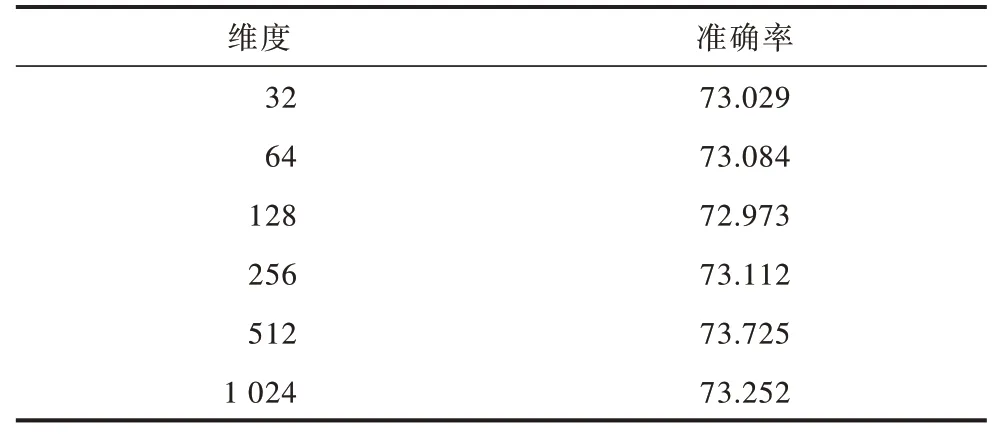
表6 不同维度空间的识别率Table 6 Recognition rate of different dimension spaces %
实验4不同通道数的模型性能分析。通过实验3 发现,当把当前维度升维到高维空间时表情识别率有所提升,在升维16 倍时取得最高值。实验4将研究不同通道数及升维16 倍到高维空间时模型表情的识别性能,性能分析如表7 所示。
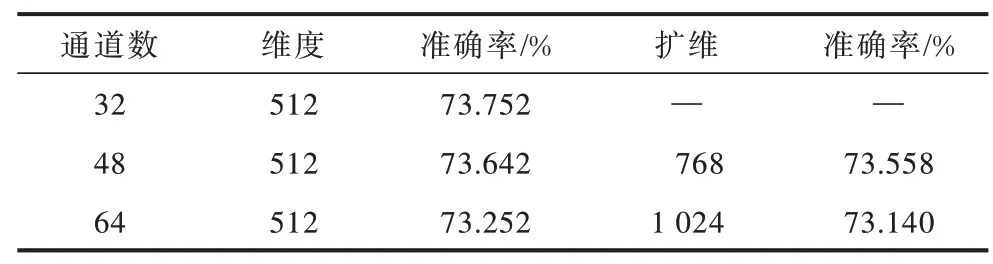
表7 不同通道数的模型性能分析Table 7 Performance analysis of models with different channel numbers
当维度保持512 不变时,随着通道数增加,人脸表情识别准确率逐渐降低,说明基础通道数对模型性能影响不大。当通道数为48、维度为512 时,表情准确率为73.642%,而将通道数扩展16 倍变成768时,准确率有所下降,但幅度不大。同样地,将维度通道数64 拓展到1 024 特高空间时,准确率同样出现略有下降的趋势,原因可能是当维度扩大时,全连接层的输出参数不变。
实验5不同尺度网络的识别率比较。由图9 曲线可知,网络模型大概在400 个epoch 时开始收敛,最后趋于稳定。在表情识别率方面,不同尺度网络MHBP>5×5>7×7>3×3。其中3、5、7 均为单一尺度网络,5×5 网络较7×7 网络识别率高,这是因为网络最后3 层卷积的特征图大小为6×6,大尺度核卷积较小尺度核移动次数少,导致缺失重叠卷积部分特征。单一尺度5 和7 网络均比单一尺度3 网络的识别率高,说明适当增大尺度核尺寸可提高识别率。MHBP 网络集成了不同的跨层多尺度特征,可捕获同一尺度及不同尺度的不同跨层特征联系,加大对表情细微特征表征对象的利用。因此,本文提出多尺度MHBP 网络在人脸表情识别率方面优于其他单一尺度网络算法。
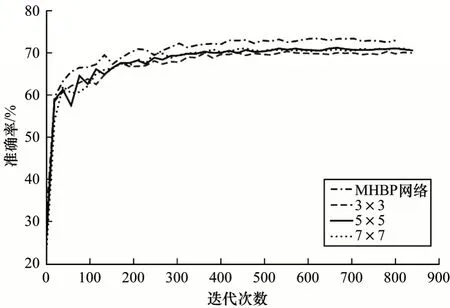
图9 不同尺度网络对识别率的影响Fig.9 Influence of different scale networks on recognition rate
如图10 所示,4 种不同尺度网络的损失值均在0.8~0.9 之 间。MHBP网络的损失值最小;5×5 网络和7×7 网络次之,且两者损失值相近;3×3 网络损失值最大。此外,MHBP 网络损失值下降速度最快,收敛也快,且波动幅度不大,这进一步说明了MHBP 网络集成不同跨层特征的优越性。
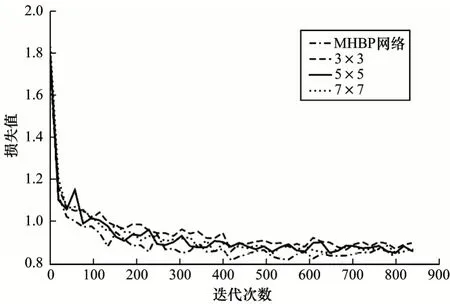
图10 不同尺度网络损失值比较Fig.10 Comparison of network loss values at different scales
由表8 可知,MHBP 网络在FER2013 公开人脸表情数据集的识别准确率比单一3×3,5×5,7×7 网络分别提高了3.037、2.034、2.173 个百分点。这说明单一尺度网络虽然集成了网络最后3 层卷积层的特征,但缺乏多尺度表情特征信息,因此并不能准确地对表情做出判断。同时也证明端到端学习集成能够提高多跨层多尺度双线性人脸表情特征的辨识度,从而提高模型分类准确率。

表8 不同尺度网络的表情识别率对比Table 8 Comparison of expression recognition rate of different scale networks %
实验6多层信息融合的有效性分析。在MHBP 网络添加多层信息融合FER2013 的实验发现表情识别率并没有提升。这可能是受FER2013 数据集存在标签错误、光照不一、头部姿势各异等复杂背景因素影响。为排除外界非人脸因素的影响,本节实验选择实验室环境的CK+表情数据集验证多层信息融合的有效性。将CK+数据集按照9∶1 划分为训练集和测试集,采用十折交叉训练,选择优化器为AdaBound[18]。优化器参数设置如下:学习率为0.001,并在250 epoch后每2 个epoch 衰 减0.9 倍,amsbound 参数设置为True。如表9 所示,在MHBP网络中加入MHBP+MIF 及MHBPM 多层信息融合后,7 种表情的平均识别率提高了1 个百分点。其中,悲伤和蔑视的识别率分别比MHBP 网络提高了0.05 和0.09 个百分点,而其他表情的识别率基本相同。实验结果表明,通过反卷积对多层信息进行融合分类并恢复丢失的低频特征信息,能够提高表情识别率,此结果验证了多层信息融合的有效性。
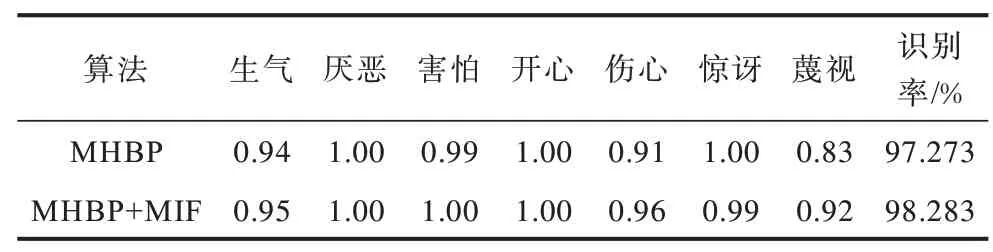
表9 在CK+数据集上多层信息融合的性能分析Table 9 Performance analysis of multi-layer information fusion on CK+data set
2.4 不同算法的识别率比较
为更好地评估本文方法的有效性,选取几个较新的算法在CK+和FER2013 数据集上做比较,结果如表10 所示。TURAN 等[19]提出了一种新的更有效的流形学习方法—软局部保持映射(Soft Locality Preserving Map,SLPM),该方法旨在控制不同类的扩散水平,能有效降低特征向量的维数,并增强所提取网络对表情识别的区分能力。ZHOU 等[20]改善了Softmax 层,使识别率得到了一定的提升。YANG等[21]提出了一种基于残差表情的人脸表情识别方法。残差学习法用于生成模型中间层的残差,该残差包含输入表情图像任何生成模型的表情成分。实验结果证明了从模型中间层提取表情成分的有效性。TIAN 等[22]提出一种新的基于类别感知容差和孤立点抑制的Triplet 损失函数。根据特征距离分布,对每一对表情,如快乐、恐惧等分配自适应容差参数,以剔除异常Triplet。SHAO 等[23]提出3 种不同架构的新型卷积神经网络(CNN)模型:6 个深度可分离的残差模块构成的浅网络,双分支并行提取传统LBP 特征和深度学习特征的CNN 模型和采用转移学习技术设计了预训练的CNN 模型。实验结果具有竞争力和代表性。FENG 等[7]提出小尺度核网络,LIU 等[8]引入课程学习(Curriculum Learning,CL)到卷积神经网络,这些均使识别率得到了一定程度的提升。LAN 等[24]提出了联合过滤器响应正则化和批量正则化(Joint Normalization Strategy,JNS)训练模型,弥补了单一正则化的不足,提高了表情识别率。
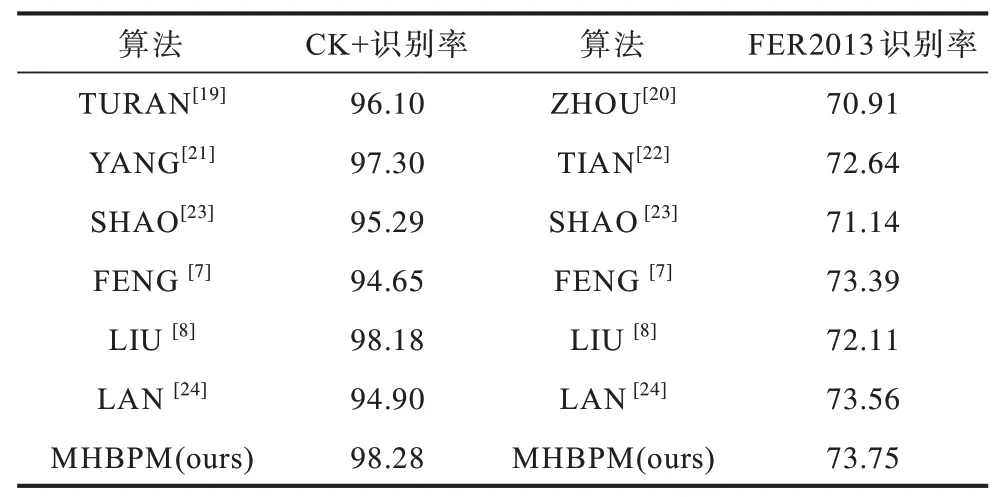
表10 不同算法在CK+和FER2013数据集上的识别率对比Table 10 Comparison of recognition rates of different algorithms on CK+and FER2013 data sets %
FENG 等[7]和LAN 等[24]对FER2013 数据集的识别率较高,但对CK+数据集的识别率较低。相反,LIU等[8]对CK+数据集的识别率较高,但对FER2013 数据集的识别率较低。这说明以上算法均不具备普适性。然而,本文方法在CK+和FER2013 这2 个数据集上均取得了较好的效果。这是因为本文方法集成了多跨层的多尺度表情特征,能够捕捉表情深层次的微妙变化,且通过反卷积融合多层特征,恢复了表情图像逐层传递过程中的特征信息损耗,从而解决了模型层间交互以及多层特征融合的问题,因此更适用于表情分类。
3 结束语
本文设计3 种不同尺度的网络作为提取人脸表情特征的主干网络,通过在网络中加入多尺度特征融合模块实现主干网络多尺度特征的自主融合,同时引入分层双线性池化网络集成同一网络及不同网络的跨层表情特征,以获取有区分度的细腻表情特征属性。在此基础上,进一步探究不同通道数及维度空间对所提MHBP 算法的影响,提出一种多层信息融合方法。实验结果表明,多层特征融合方法能有效利用丢失的信息,提高表情分类精度,且基于多尺度双线性池化的网络能捕获具有明显辨识度的人脸表情特征,提高人脸表情识别率。下一步将设计轻量级神经网络,并利用金字塔池化改进多层特征融合的方式,以获得更高的运行效率和更好的识别效果。
