复杂属性条件下基于Spark的clique社区搜索算法
2021-12-20何震瀛
佘 鑫,何震瀛
(1.复旦大学 软件学院,上海 200441;2.复旦大学 计算机科学技术学院,上海 200441)
0 概述
社区搜索有利于对网络进行分析,具有重要的应用价值。在网络中,节点表示实体,边表示实体之间的关系[1]。社区结构作为网络的重要组成部分,是内部节点连接紧密的子图[2]。例如:在Facebook中,社区可由具有朋友关系的用户组成[3];在万维网中,社区可以是一些具有相似主题的网站[4];在蛋白质-蛋白质相互作用网络[5]和代谢网络[6]中,社区可以用于生物功能模块发现;在企业社会化网络中,社区可用于分析企业团体的拓扑特征和功能特性[7]。
早期的社区搜索算法仅考虑网络拓扑结构,即给定一组节点,从网络中寻找包含这组节点的社区。常见的社区结构有clique[5]、k-core[8-10]、k-truss[11]等。文献[5]利用clique 结构来寻找网络中的重叠社区。文献[9]提出了寻找包含给定节点集的k-core 社区问题及对应算法。文献[10]提出了复杂条件下的k-core 社区搜索方法,旨在找到满足给定复杂条件的k-core 社区,但该方法使用由节点变量组成的布尔表达式定义复杂条件,在搜索过程中仅考虑网络拓扑结构,不适用于节点包含属性信息的网络。文献[11]给出了k-truss 的社区定义。文献[12]提出了寻找包含给定节点的k-truss 社区问题,并设计了基于TCP-Index 的搜索算法。
近年来的社区搜索算法研究出现了同时考虑网络拓扑结构和节点属性的情况。文献[13]提出基于k-core 结构在属性图上进行社区搜索,旨在寻找内部节点间共享尽可能多的属性的社区。文献[14]在给定节点集和属性集的情况下,设计了一个属性评价函数来度量属性在社区内部的流行程度,进而寻找基于属性的k-truss 社区。文献[15]提出了寻找包含给定属性集的最小且紧密的k-truss 社区的问题。文献[16]提出了以关键字为中心的社区搜索问题,通过定义属性间的距离来度量子图中的属性紧密度,进而寻找满足要求的最大k-core 社区。文献[17]建立内聚属性社区搜索模型以寻找结构和属性紧密度高的社区。文献[18]提出了属性多样化的社区搜索问题,提出了属性多样化模型和基于k-core 的剪枝算法。
上述社区搜索算法可以寻找包含给定属性集的社区,但仍难以满足实际应用的复杂需求。本文将包含给定属性集的这类条件之外的属性条件称为复杂属性条件(如包含属性集中任意一个属性、包含某些属性而不包含另一些属性等),进而提出复杂属性条件下的clique 社区搜索问题。
clique 社区搜索问题难以在多项式时间内被解决,枚举极大clique 的问题已被证明是NP-Hard的[19],该问题具有指数级别的复杂度其中,n为网络图的节点数目。文献[20]提出的经典BK 算法是后续算法的基础。文献[19]提出了一个运行速度更快的算法,但是总体复杂度仍然与BK 算法接近。文献[21]提出了一种在大型网络中枚举clique的近似算法,该算法基于随机的方式实现,但是没有提供clique 枚举的准确计数。文献[22]提出了一种误差小于2%的clique 计数的近似算法,但该算法在大型网络中无法扩展。
目前多数解决clique 问题的算法都是在单机环境下运行的,很少有分布式环境下的解决方案。文献[23]提出了一种分布式解决方案,该解决方案使用结合MapReduce 框架的多路联接来枚举clique,但是该方案存在严重的I/O 性能瓶颈,并且在大型网络中的效果较差。文献[24]提出了基于Spark 的利用多阶段分区策略来寻找最大clique 的算法,但该算法无法扩展至存在复杂属性条件的情况。
本文提出基于Spark 适用于复杂属性条件的clique 社区搜索算法。利用布尔表达式形式化地定义复杂属性条件,进而基于clique 结构给出复杂属性条件下clique 社区搜索问题的定义,并说明该问题的复杂性。通过使用Spark 并行计算框架,根据考虑网络结构和内容属性的先后顺序,分别提出结构优先的社区搜索算法SF 和属性优先的社区搜索算法AF。同时考虑到SF 算法未充分利用属性信息和AF算法属性计数成本较高的问题,结合网络结构和内容属性,进一步提出融合属性和结构的社区搜索算法AS。
1 复杂属性条件下的clique 社区搜索问题
传统的属性社区搜索问题都是以属性集的形式作为输入,旨在寻找包含给定属性集的社区,但是无法适用于以下两种情况:一种是不包含给定的若干属性的情况;另一种是至少包含给定的若干属性中一个的情况。本节首先基于布尔表达式形式化地定义复杂属性条件,然后提出复杂属性条件下的clique社区搜索问题定义并给出问题示例,最后说明该问题的复杂性。
1.1 问题定义
布尔表达式由逻辑运算符和布尔变量组成[10]。布尔变量的取值为真(1)和假(0),逻辑运算符包括与(∧)、或(∨)、非(﹁)。确定式中每个布尔变量的取值并结合逻辑运算符即可判断整个布尔表达式的真假。因此,本文利用布尔表达式形式化地定义复杂属性条件。
对于一个社区C,给定布尔变量A(对应属性A)。如果社区包含属性A,那么该属性对应的布尔变量为真;反之,如果社区不包含属性A,那么该属性对应的布尔变量为假。将这样的布尔变量称为属性变量,利用属性变量和逻辑运算符组成的布尔表达式,可以完成复杂属性条件的形式化定义。
定义1简单属性条件
1)单个属性变量A 是简单属性条件;
2)如果属性变量A 和B 是简单属性条件,那么A∧B 是简单属性条件;
3)当且仅当有限次地应用条件1)、2)所得到的布尔表达式称为简单属性条件。
定义2属性条件
1)单个属性变量A 是属性条件;
2)如果A 是属性条件,那么﹁A 是属性条件;
3)如果A 和B 是属性条件,那么A ∧B、A ∨B 是属性条件;
4)当且仅当有限次地应用条件1)~3)所得到的布尔表达式称为属性条件。
定义3复杂属性条件
将满足定义2 但不满足定义1 的布尔表达式称为复杂属性条件。
定义4单项属性条件
对于一个属性条件,如果有且仅有一组属性变量的取值能满足该条件,那么称其为单项属性条件。
定义5clique 社区
给定一个网络图G=(V,E),其中:V 为节点集;E 为边集。图G 中的clique 社区C 满足:对于任意节点u∈C,v∈C(u≠v),存在一条边(u,v)∈E。图G 中如果不存在一个clique 社区C’使C ⊂C’,那么称clique 社区C 为图G 中的一个极大clique 社区。
定义6复杂属性条件下的clique 社区搜索问题
给定一个网络图G=(V,E),其中:V 为节点集;节点数n=|V(G)|;E 为边集;边数m=|E(G)|。用T表示图G的属性集,用attr(v)表示节点v的属性集,v∈V,attr(v)⊂T。对于任意属性A ∈T,用VA表示包含属性A的节点集,即VA={v ∈V|A ∈attr(v)}。输入复杂属性条件Q,寻找满足以下条件的社区C:1)C ⊂V;2)C 是连通的,且为极大clique 社区;3)复杂属性条件Q 在给定社区C 的情况下为真。
以 从DBLP(http://dblp.uni-trier.de/db/)中抽取的论文合作网络(使用clique)为例,如图1 所示。在该网络中,节点表示作者,边表示作者间的合作关系,每个作者有若干属性标签,如作者的研究领域Data Mining、Data Security、Big Data Analytics 等。此时需要组建一个具有Data Mining 和Data Security背景且合作紧密的团队。对于寻找一个满足何种条件的clique 社区这一问题,从社区的角度来解释,此问题即为需要在给定学术合作网络中找到包含属性Data Mining 和Data Security 的社区。图1 中包含的极 大clique 社区有3个,分别是{v1,v2,v4,v6}、{v3,v4,v5,v6,v7,v8}和{v7,v8,v9,v10,v11},其中,满足包含属性Data Mining 和Data Security 这一条件的极大clique 社区为{v3,v4,v5,v6,v7,v8}。

图1 复杂属性条件下的社区搜索示例Fig.1 Example of community search under complex attribute condition
1.2 复杂性
极大clique 的枚举问题是NP-Hard 的[12],该问题的复杂度为其中,n为图的节点数目。假设考虑最简单的属性条件,即求包含单个属性的极大clique,那么就相当于是要求出所有极大clique,然后再判断是否包含该属性。这样极大clique 的枚举问题,即复杂属性条件下的clique 社区搜索问题是NP-Hard 的。
2 复杂属性条件下的clique 社区搜索算法
本节提出结构优先的社区搜索算法SF和属性优先的社区搜索算法AF。在此基础上,结合图的结构特征和内容属性,提出融合属性和结构的社区搜索算法AS。
2.1 结构优先的社区搜索算法
结构优先的社区搜索算法SF 设计思想为:首先枚举出图中所有的极大clique,然后判断每一个极大clique是否符合给定的属性条件,若不符合,则删除不符合属性条件的节点,反之则保留该极大clique,最后选出所有满足属性条件的极大clique。但该算法由于在计算过程中需要枚举出图上所有的极大clique,因此时间开销很大,已被证明是NP-Hard 的。因为复杂属性条件下的社区搜索结果与输入的属性条件有很大关系,一般情况下不会涉及到全体结果,所以没有必要枚举出所有的极大clique。因此,本文结合属性信息提出属性优先的社区搜索算法。
2.2 属性优先的社区搜索算法
本文基于Spark 并行计算框架提出属性优先的社区搜索算法AF,其伪代码如算法1 所示。该算法根据复杂属性条件对每一个点进行属性计数,进而利用Spark GraphX 提供的操作进行图分割,最终找到所有满足条件的社区。
算法1属性优先的社区搜索算法AF


AF 算法的主要步骤如下:
步骤1读取数据加载图。
首先给定文件路径从HDFS 中读取数据集,生成点集合对象VertexArray 和边集合对象EdgeArray,然后通过Spark 的parallelize 算子生成VertexRDD 和EdgeRDD,最后 使用Spark GraphX 的Graph 方法构造出图G。
步骤2获取图的辅助信息。
在步骤1 得到的图G 基础上,调用Spark GraphX中的aggregateMessages方法获取NeighborVertexRDD。aggregateMessages 操作的对象是triplet,其结构为一个五元组,包含源顶点号、目的顶点号、源顶点属性、目的顶点属性和边的属性。triplet 中的操作包含sendMsg和mergeMsg 这2 个阶段。在sendMsg 阶段,源顶点和目的顶点之间会互相发送各自的编号和属性;而在mergeMsg 阶段,会将每个顶点收集起来的编号和属性进行合并。最终,返回NeighborVertexRDD。
步骤3简化复杂属性条件。
在进行实际社区搜索时,输入的属性变量数目通常比较少,因此,可以通过枚举属性变量取值的形式来找到满足复杂属性条件的所有取值集合。用1和0 分别代表属性是否存在于社区中。例如:满足条件A ∧﹁B ∧C 的属性变量组合为A=1,B=0,C=1。如果输入的属性变量数目较多,那么可以采用求解可满足性问题的快速算法,如GRASP 算法[25]。
在得到满足复杂属性条件的所有取值集合后,可以得到与该条件等价的主析取范式。例如:对于复杂属性条件(A ∨﹁B)∧C,可以先枚举出A=1,B=0,C=1、A=1,B=1,C=1 和A=0,B=0,C=1 这3 种取值组合使条件的结果为真,进而该条件可以化简为3 个合取式的析取式,即(A ∧﹁B ∧C)∨(A ∧B ∧C)∨(﹁A ∧﹁B ∧C),然后对每个合取式进行一次单项属性条件社区搜索,最后将每次得到的结果合并去重得到最终结果。
此外,化简得到的主析取范式还可能存在冗余的情况,如(A ∧B ∧C)∨(﹁A ∧B ∧C),由于属性变量A 对结果不会产生任何影响,消除冗余后可以得到B ∧C,因此利用奎因-麦克拉斯基(QM)算法[26]消除这一类的冗余,从而减少搜索的开销。
步骤4根据单项属性条件进行搜索。
枚举出所有的可能取值以后,根据每一组的取值进行社区搜索,即单项属性条件社区搜索。根据每个单项属性条件是否存在逻辑非运算符,把属性分为必要属性和禁止属性,即如果单项属性条件中的属性变量取1 时为真,那么其对应的属性为必要属性;反之,如果单项属性条件中的属性变量取0 时为真,那么其对应的属性为禁止属性。对于一个单项属性条件P,记P.RAS(Required Attribute Set)为其必要属性集,记P.FAS(Forbidden Attribute Set)为其禁止属性集。例如,对于单项属性条件A ∧﹁B ∧C ∧﹁D,其必要属性集P.RAS={A,C},禁止属性集P.FAS={B,D}。
单项属性条件社区搜索过程如下:
1)根据单项属性条件对图中的每个节点进行属性计数。属性计数规则为:若节点包含当前单项属性条件的禁止属性,则该节点的属性计数直接为-1,并且忽略该节点的其他属性;若节点不包含当前单项属性条件的禁止属性,则该节点的属性计数为当前单项属性条件的必要属性集和该节点的属性集的交集的属性数目。上述过程通过在图G 和NeighborVertexRDD 上的outerJoinVertices 操作和mapVertices 操作实现。
2)为每个节点构造子图,调用Spark GraphX 的aggregateMessages 方法生成子图。在sendMsg 阶段,对于相邻的2 个节点,属性计数较小的节点将发送其编号和属性到属性计数较大的节点,如果2 个节点的属性计数相等,那么编号较小的节点将发送其编号和属性到编号较大的节点;在mergeMsg 阶段,每个节点合并收到的消息,与发送消息的邻居节点形成一个子图。
3)在每个节点生成的子图中寻找满足单项属性条件的极大clique。
步骤5合并社区结果。
在得到每个单项属性条件的社区搜索结果后,将其合并就能够得到最终的复杂属性条件社区搜索结果。
2.3 融合属性和结构的社区搜索算法
融合属性和结构的社区搜索算法AS 是基于AF算法的第4 步进行改进的。该算法同时考虑了图的内容属性和结构特征,并且可以根据不同的单项属性条件采取不同的搜索策略,利用属性的搜索成本和扩展成本进行局部优化,从而加快搜索过程。
简化后的复杂属性条件是由若干单项属性条件组成的析取式,单项属性条件一般会包含必要属性和禁止属性,因此,一个单项属性条件会出现以下3 种情况:1)只包含必要属性;2)既包含必要属性又包含禁止属性;3)只包含禁止属性。
首先考虑第1 种情况,即只包含必要属性。在clique 问题中,每个clique 的求解可以分为2 个步骤:
1)找到初始扩展节点。从该节点开始扩展,至少能够找到一个极大clique。
2)扩展社区。以初始扩展节点的邻居节点为候选集,不断添加新节点到初始扩展节点所在集合,形成最终的极大clique。
在通常情况下,社区搜索问题中用户输入的属性条件涉及到属性数目比较少,同时,网络图中的节点包含的属性有限,并且包含同一个属性的节点数目不会太多。因此,结合必要属性必须被包含在社区结果中这一情况,提出属性的搜索成本的概念。
定义7属性的搜索成本
给定图G=(V,E)及其属性集T,对于任意属性A ∈T,其属性搜索成本COST(A)为包含属性A的节点数目与图中节点数目的比值,即COST(A)=|VA|/|V |。
根据必要属性的搜索成本可知包含某个属性的节点数目。因为包含该属性的节点数目越少,以其作为扩展节点时就越能避免考虑不必要的节点。因此,选择具有最小搜索成本属性的节点作为初始扩展节点。
在扩展社区的过程中,需要考虑的问题是将何类节点添加到社区结果中。例如,假设当前属性条件为A ∧B ∧C,在扩展社区时,候选集为{V1,V2,V3},其中,节点V1包含属性A、D,节点V2包含属性A、B,节点V3包含属性B、C,那么在这一轮扩展社区时,包含属性A的节点有2个,包含属性B 的节点有2个,包含属性C 的节点有1 个,因为被包含在更少节点的属性是更稀缺的,该属性更可能在后续扩展过程中消失,所以选择被包含在更少节点的属性作为这一轮扩展社区的属性,进而包含该属性的节点作为本轮的扩展节点。因此,提出了属性的扩展成本概念。
定义8属性的扩展成本
给定图G=(V,E)及其属性集T,当前扩展时的单项属性条件为P,对于任意属性A∈P.RAS,属性A 的扩展成本为候选集中包含属性A 的节点数与候选集中节点数的比值,即EXPAND(A,R)=|VA∩R|/|R|,其中,R 为当前扩展时的候选集。
在扩展社区的过程中,依次选择包含具有最小扩展成本的属性的一个节点加入到包含初始扩展节点的集合中,完成后续扩展,由此可以得到融合属性和结构的社区搜索算法,如算法2 所示。
算法2融合属性和结构的社区搜索算法AS

在选定初始扩展节点后,以初始扩展节点进行扩展,进而得到局部的clique。clique 局部扩展算法FindClique如算法3所示。
算法3clique 局部扩展算法FindClique

下面考虑第2 种情况,即属性条件中既包含必要属性又包含禁止属性的情况。在这种情况下,使用必要属性进行社区搜索,使用禁止属性进行节点过滤。根据过滤操作的作用先后顺序,可以分为3 种策略:预先搜索策略,预先过滤策略和搜索时过滤策略。
1)预先搜索策略即先搜索后过滤的策略。具体过程如下:首先根据必要属性进行社区搜索,得到若干包含必要属性的社区;然后检查每个社区的内部节点是否存在禁止属性,若存在,则删除包含禁止属性的节点,若不存在,则保留该社区;最后检查过滤后的社区是否符合clique 结构的定义,若符合则保留。
2)预先过滤策略即先过滤后搜索的策略。具体过程如下:先根据禁止属性删除图中所有包含禁止属性的节点;再根据必要属性进行社区搜索,这样得到的社区结果不再包含禁止属性,所以一定能够满足搜索条件。
3)搜索时过滤策略即根据必要属性进行搜索,并且在搜索过程中避开包含禁止属性的节点,直到找到满足属性条件的社区,且不再需要对社区结果进行检查。
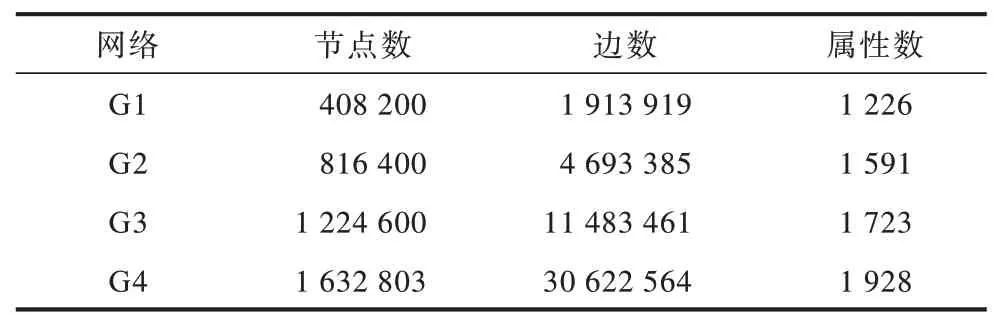
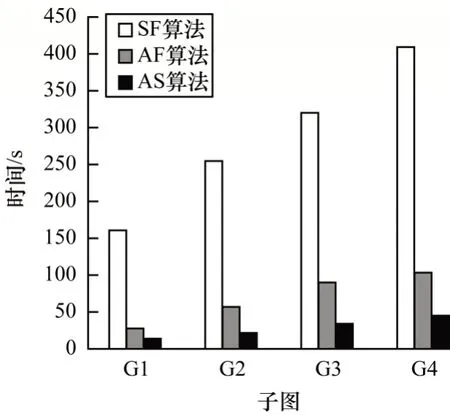
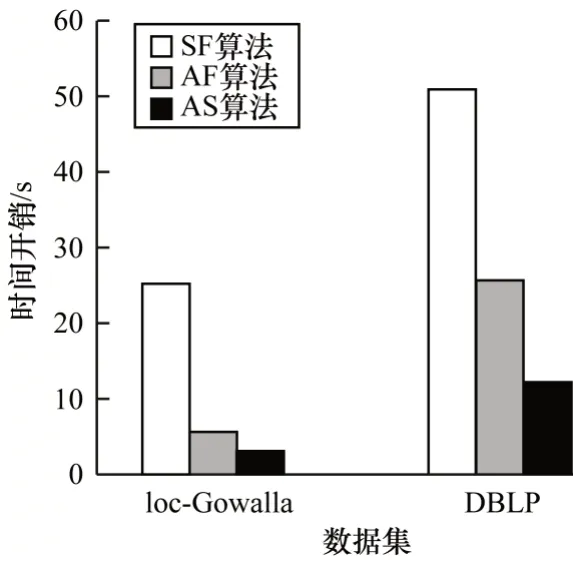
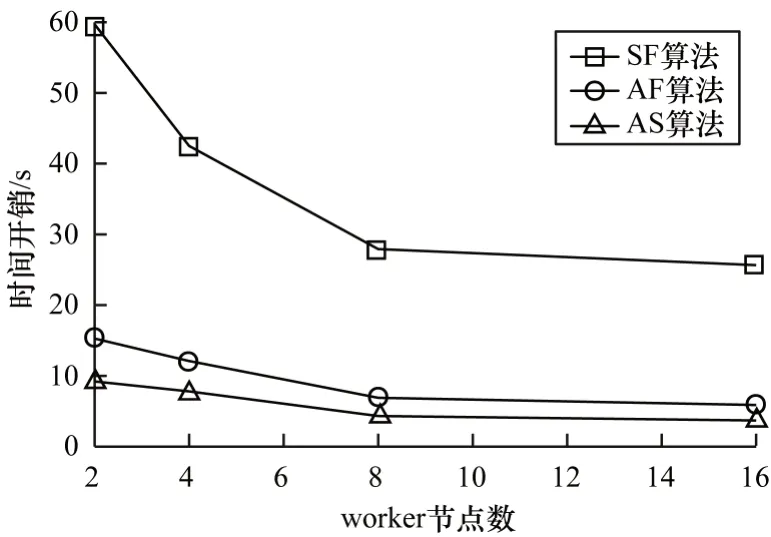
针对单项属性条件同时包含必要属性和禁止属性的情况,在社区搜索的过程中需要做出选取何种搜索策略的决策。在删除包含禁止属性的节点前后,根据所有必要属性中最小搜索成本的大小变化可以做出决策。现给定某个属性条件,假设使用预先搜索策略时,所有必要属性中的最小搜索成本为a,使用预先过滤策略时,所有必要属性的搜索成本为b。如果a>b,那么采用预先过滤策略;如果a 还有一种特殊的情况是属性条件中只包含禁止属性的情况。这种情况由于没有必要属性,因此没有根据属性进行搜索的过程,只需要将包含禁止属性的节点删除后在剩余图中枚举出所有极大clique即可。 在Spark集群上进行实验,其中包括1个master节点和2个worker节点。硬件配置如下:Intel Xeon Silver 4280 CPU @ 2.10 GHz;64 GB 内存。软件配置如下:Linux Ubuntu 18.04,JDK 1.8.0_151,Scala 2.11.12,Spark-2.4.5版本。 本文实验中使用的数据集如表1 所示,其中包括loc-Gowalla、DBLP、Youtube 和SocPokec,这4 个数据集都来源于Stanford Large Network Dataset Collection(http://snap.stanford.edu/data/)。 表1 实验数据集Table 1 Datasets for experiment 实验1对比不同属性条件下SF、AF 和AS 算法的时间开销。 设计6组不同的属性条件,如表2所示,在DBLP和Youtube 数据集上测试3 种算法在各组属性条件下的时间开销。 表2 属性条件Table 2 Attribute conditions 在DBLP 数据集上的实验结果如图2 所示,在Youtube 数据集上的实验结果如图3 所示。通过第1 组和第2 组属性条件的对比实验结果可以看出,属性条件中的属性数目越多,3 种算法的时间开销越大,这表明算法时间开销与属性条件中涉及到的属性数目呈正相关。通过第3 组和第4 组属性条件的对比结果实验结果可以看出,当属性条件中涉及到的必要属性数目和禁止属性数目比较接近时,3 种算法的时间开销也比较接近,这表明算法的时间开销与涉及到的属性总数目有关,如果涉及到的属性总数目接近,那么算法的时间开销也接近。通过第5 组和第6 组属性条件的对比实验结果可以看出:在只包含必要属性的条件下,3 种算法的时间开销与相同必要属性数目的其他类似条件的时间开销接近。在只包含禁止属性的条件下,SF 算法和AF算法的时间开销接近,这是由于缺少必要属性,导致AF 算法在属性层面失效。此外,AS 算法在只包含禁止属性的条件下的时间开销要比其他情况时间开销稍大,这是由于删除包含禁止属性的节点需要额外时间,并且需要在剩余图中进行全局搜索。 图2 不同属性条件下的时间开销(DBLP)Fig.2 Time cost under different attribute conditions(DBLP) 图3 不同属性条件下的时间开销(Youtube)Fig.3 Time cost under different attribute conditions(Youtube) 实验2对比不同网络规模下SF、AF 和AS 算法的时间开销。 采用SocPokec 数据集(记为G4),由该数据集生成3 个G4 的子图,分别是G1、G2 和G3,其中,G1 子图的节点数是G4的1/4,G2子图的节点数是G4的1/2,G3子图的节点数是G4 的3/4,具体信息如表3 所示。 表3 SocPokec 及其子图Table 3 SocPokec and its subgraphs 在本实验中,属性条件中搜索的属性项数量为5,其中包含3 个必要属性和2 个禁止属性。实验结果如图4 所示,可以看出:在同一个网络下,网络规模越大,3 种算法的时间开销就越大,且时间开销随着网络规模的变化而线性变化;在4 种不同的网络规模下,AS 算法的性能优于AF 算法,AF 算法的性能优于SF 算法。 图4 不同网络规模下3 种算法的时间开销Fig.4 Time cost of three algorithms under different network scales 此外,进一步对比在不同网络中SF、AF 和AS 算法的时间开销。在实验中,属性条件中搜索的属性项数量为5,其中包含3 个必要属性和2 个禁止属性。实验结果如图5 和图6 所示,可以看出,在同一网络数据集中,AS 算法的时间开销小于AF 算法,AF 算法的时间开销小于SF 算法,具体地,AS 算法速度比AF 算法快约1.5~2.5 倍,AF 算法 速度比SF 算法快约2~4 倍。 图5 loc-Gowalla 和DBLP 上3 种算法的时间开销Fig.5 Time cost of three algorithms on loc-Gowalla and DBLP 图6 Youtube 和SocPokec 上3 种算法的时间开销Fig.6 Time cost of three algorithms on Youtube and SocPokec 实验3对比不同worker 节点数量下SF、AF 和AS 算法的时间开销。 采用Docker虚拟化技术进行搭建,模拟3个worker节点数目不同的Spark 分布式集群,其中worker节点数目分别为2、4、8 和16。本实验在loc-Gowalla 数据集上进行,属性条件中搜索的属性项数量为5,其中包含3个必要属性和2 个禁止属性。实验结果如图7 所示,可以看出,3 种算法的时间开销随着worker节点数目的增多而减小,但最终趋于稳定,这表明,在一定的范围内,Spark分布式集群提供的计算资源越多,算法的性能就会越好。同时,在这3 种分布式环境下,AS 算法的性能均优于AF 算法,AF 算法的性能均优于SF 算法。 图7 不同worker 节点数目下3 种算法的时间开销Fig.7 The time cost of three algorithms under different number of worker nodes 上述实验结果表明,融合属性和结构信息的社区搜索算法的性能优于于其他2 种算法,且AS 和AF 算法的时间开销都与给定的属性条件相关,算法的时间开销与网络规模呈正线性相关,分布式环境提供的计算资源越多,算法的时间开销越小,但最终将趋于稳定。 针对复杂属性条件下clique 社区搜索问题求解复杂度高、属性条件通用性差等问题,本文基于布尔表达式给出复杂属性条件下的clique社区搜索问题定义,并说明该问题的复杂性。在此基础上,结合Spark 并行计算框架分别提出结构优先的社区搜索算法和属性优先的社区搜索算法,并对属性优先的社区搜索算法进行改进,进一步提出融合属性和结构的社区搜索算法。该算法在社区搜索过程中同时考虑图的结构特征和节点的内容属性,并结合3 种不同的搜索策略大幅减少需要访问的节点数,从而加快搜索过程。在真实数据集中的实验结果验证了所提算法的正确性和有效性。下一步拟基于Spark GraphX 提出一套社区搜索的通用API,以解决复杂属性条件下社区搜索的通用问题,而不仅限于clique 结构,同时还使算法能够处理k-core、k-truss 和用户自定义的结构。3 实验结果与分析





4 结束语
