基于机器学习的比特币去匿名化方法研究
2021-12-20郭文生冯志淇张露晨杨菁林
郭文生,杨 霞,冯志淇,张露晨,杨菁林
(1.电子科技大学 信息与软件工程学院,成都 610000;2.成都链安科技有限公司,成都 610000;3.国家互联网应急中心,北京 100000)
0 概述
比特币是世界上第一个点对点加密货币系统,其并非纸币或金币银币那样独立的个体,而是一套电子现金系统,与支付宝有一定的类似之处。比特币存在于网络中,可以不经过任何中心机构就完成全球转账,且其发行、支付以及验证自成系统,因此,比特币是一种总量有限、无国界、无发行中心、无管理中心、遍布全球且自由流通的全新货币。此外,比特币具有匿名化的特点,不需要用户进行实名认证,更不需要身份验证,只要有比特币地址就可进行比特币交易,且比特币地址无需复用,一个用户可以拥有多个比特币地址。比特币具有无国界、去中心化、匿名化的优点,因此,近年来其价格大幅提升,达到上万亿美元的市值,形成了一个遍布全球却没有管理中心的社区,并成为加密货币的主流币种。比特币便捷低廉的跨国交易、潜在的投资价值等因素,是人们积极参与比特币投资的主要原因。但是,比特币地址的匿名性使交易用户的真实身份得以隐藏,导致比特币被一些不法分子应用于各类非法活动中。例如,2017年5月有上百个国家和地区超过10万台电脑被感染勒索病毒WannaCry[1],病毒制造者利用比特币获取了大量赎金。在面对比特币存在的非法交易问题时,执法部门需要获取比特币和用户之间的关联信息,将其作为犯罪证据,然而在比特币资金追溯的实现过程中主要依靠人工进行分析,存在自动化程度低、时效慢等问题。因此,非常有必要设计一种针对比特币交易地址的身份识别机制,以遏制不法分子利用比特币实施犯罪行为。
相对于传统的金融系统,比特币独有的地址匿名化、交易分散化等特征,使其交易具有较强的反溯源能力,也导致比特币交易地址的身份识别机制面临更多挑战:第一,比特币地址是用户参与比特币交易使用的账号,该地址是由用户自行创建,与身份信息无关联,并且创建过程中不需要第三方参与;第二,比特币支付系统支持用户每次交易后生成不同的地址,因此,用户的交易信息分散在不同的地址中,且这些地址都涉及海量的比特币交易,很难通过分析单个比特币地址的交易行为数据来识别比特币地址的身份。
本文通过分析比特币交易记录,发现不同交易地址之间的关联关系,并构造比特币地址集群,对比特币地址聚类后的集群进行研究,根据比特币地址与地址集群的交易行为提取其交易特征,并设计交易特征的融合方案。在此基础上,基于所有的交易特征,利用集成学习算法进行模型训练,得到模型构建的新特征,将新的特征引入多分类模型中进行比特币地址的身份识别。具体地,本文提出比特币交易系统中比特币地址聚类的关联规则,在地址集群海量的链上交易数据中抽取与地址集群相关的交易特征。设计比特币地址身份识别机制中的特征提取与融合方案,分别从比特币地址、地址集群、地址集群交易网络结构3 个方面进行特征构造与融合。基于集成学习算法对原始的交易特征自动进行特征工程,将新的特征输入多分类模型中进行模型训练,从而有效识别比特币地址的身份。
1 相关工作
近年来,随着比特币支付系统的不断成熟、比特币价格的大幅攀升以及比特币用户数的持续增加,比特币的匿名性与安全性逐渐引起国内外研究人员的广泛关注。针对比特币交易地址进行身份识别的研究主要分为3 种方法,分别为无监督式、半监督式以及监督式。
1)无监督式比 特币身份识 别研究:THAI 等[2]使用K 均值聚类、马氏距离、无监督式支持向量机这3 种无监督学习算法,判断比特币地址是否异常,从而识别出比特币网络中的异常交易行为;RACHANA 等[3]介绍比特币的详细交易流程,采用时序相似度算法DTW 替代K 均值聚类中的欧式距离,得到改进的K 均值聚类,以识别比特币异常节点与违法交易;THAI 等[4]分别从用户地址与交易的角度进行特征构造,并将无监督式的K 均值聚类与离群点监测算法LOF 相结合,以识别指定的异常交易,但是该方法识别效果不佳,且只能识别30 种已知异常交易案件中的1 种案件。
2)半监督式比特币身份识别研究:吴嘉婧等[5]结合交易网络结构构造特征数据,采用半监督机器学习算法PU learning 建立混币识别模型;MIT-IBM沃森人工智能实验室[6]使用半监督机器学习算法GCN(Graph Convolutional Networks)进行比特币反洗钱分析,该方法从每个交易地址的所有邻居地址处获取该交易地址的特征信息,包括其自身特征,并对所有节点进行同样的操作,在此基础上,将这些地址特征输入神经网络中进行模型训练,最后将该方法与逻辑回归(LR)、随机森林(RF)、多层感知器进行实验对比,结果表明,RF 算法的性能优于LR、多层感知器与GCN。
3)监督式比特币身份识别研究:HU 等[7]通过无监督式学习算法中的Deepwalk 与Node2vec 图嵌入学习算法,使用特定规则的游走方式在交易拓扑图中进行序列构建,在获得足够数量并满足一定长度的节点序列之后,使用与word2vec 类似的方式将每个点作为单词,将点的序列作为句子,从而进行训练,最后采用Adaboost算法对embedding 进行二分类模型训练,并识别混币服务商,实验结果表明,该模型准确率为92.29%,F1-score 为93%;KENTAROH 等[8]将比特币地址作为单位,从海量交易数据中抽取地址相关交易特征,采用多种监督式学习算法进行多分类模型训练,实验结果表明,该模型达到72%的准确率;PRANAV 等[9-10]采用RF、XGBOOST、LR、支持向量机等算法进行比特币违法活动识别,实验结果表明,机器学习算法(RF、XGBOOST)性能优于LR、支持向量机,最终模型准确率为91%;MASSIMO 等[11]采用RIPPER 算法、贝叶斯网络、RF 算法进行比特币庞氏骗局地址识别,实验结果表明,RF 算法的性能优于其他2 种监督式算法;文献[12-13]多次采用梯度提升算法进行比特币身份类别识别,模型准确率为80.42%,F1-score 为79.64%;STEPHEN 等[14]针对比特币交易路径结构进行模体(2-motif)构造,提取比特币交易地址的交易特征并分别采用RF、Adaboost、SVM、LR 进行模型训练,实验结果表明,采用2-motif 特征进行模型训练的效果优于仅采用比特币地址交易特征的模型;MARC 等[15]通过比特币交易地址聚类,形成以地址集合为单位的比特币交易实体,从海量交易数据中抽取比特币交易地址特征、实体交易特征、中心度量特征、多阶motif 特征等,采用LR与LightGBM 这2种算法进行多分类模型训练,从而识别比特币交易地址身份。
除上述文献外,还有研究人员[16-17]聚焦于将链上与链下信息相结合从而进行比特币地址身份识别,其中,监督式学习算法相关研究较多,集成学习算法识别效果较优。本文提出一种基于RF 的自动特征工程方法,并采用Softmax 多分类算法进行模型训练,从而识别比特币地址身份类别。
2 图模型
2.1 比特币交易图模型
比特币交易系统采用UTXO(Unspent Transaction Outputs)模型,所谓的钱包余额实际上是一个钱包地址的UTXO 汇总。因此,在比特币网络中,存储比特币余额的是未使用过的交易输出,而每一笔交易的输入实际上是上一笔交易的输出。这样成千上万个比特币交易汇聚在一起,相互交织构成一个巨大的交易拓扑图。比特币地址交易图如图1(a)所示,数据直接来源于区块链全节点,并展示出比特币的流向,图中的各顶点代表比特币链上的地址(α1,α2,…,αN)与相关交易(tx1,tx2,…,txN),介于地址与交易之间的箭头代表交易转出方向,每个箭头包含交易金额、时间等信息。

图1 比特币交易示意图Fig.1 Schematic diagram of Bitcoin transaction
在比特币交易系统中,一个用户会使用单个或多个地址,本文引入实体的概念,实体(E1,E2,…,EN)指逻辑上属于同一个用户的地址集合,也可理解成一个实体代表一个用户。文献[18-20]提出在实体聚类过程中,可以认为比特币一笔交易中的所有输入地址都被同一个用户(实体)拥有。当用户支付额度超过用户钱包中每一个可用地址中比特币的数量时,为避免执行多笔交易支付造成交易费用损失,用户会从钱包中选择多个比特币地址聚合在一起进行匹配支付,从而实现多输入交易。此外,在比特币交易中,使用每一个地址中的资金都需要单独签名,可以反过来认为一个多输入交易中的所有输入地址来源于同一个用户,如图1(a)所示,α1,α2,…,α5理应属于同一个实体E1。因此,地址交易拓扑图可以根据地址聚类转化成实体交易拓扑图,如图1(b)所示。
2.2 模体
模体(motif)可以通俗地理解为网络中频繁出现的局部连接模式。近年来,模体已经在生物学、神经科学、生态学、社交网络、论文引用网络等领域得到广泛应用。motif的定义来源于,在复杂网络中发现某种相互连接的模式个数显著高于随机网络中的个数。相互连接的模式表示指定数量的节点所组成的有向图,其中某种模式在复杂网络中出现的概率明显高于随机网络中出现的概率,就可以看成一个模体。文献[19]阐述了motif 在比特币区块链中的应用,motif在比特币交易网络中的异常交易监测场景中发挥着较大作用,二阶motif 结构如图2 所示。根据motif 的构造方式,本文分别建立一阶motif、二阶motif、三阶motif,并针对不同的结构进行相应的描述统计,包括不同结构的记录条数、交易费用、输入与输出方向的地址数量等。
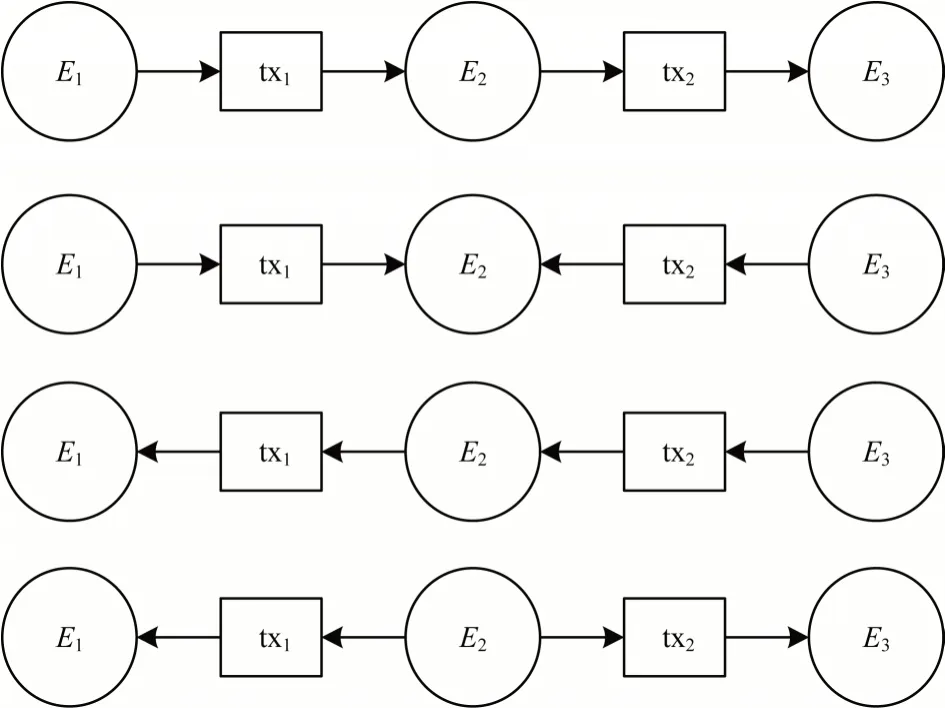
图2 二阶motif 结构Fig.2 Second order motif structure
3 联合特征实体分类方法
针对比特币交易实体类别识别问题,本文提出一种联合特征提取与RF、Softmax 相结合的分类方法,该方法主要包括2 个模块:联合特征提取模块,RF 和Softmax 分类模型构建模块。联合特征指每个比特币钱包地址在进行交易时的地址特征,其为实体特征与网络结构特征的整合:地址特征指比特币地址对应的描述性统计特征;实体特征指通过地址聚类后的地址集合,每个集合对应一个实体,然后计算每个实体的描述性统计特征;网络结构特征指通过motif 结构在实体交易网络中提取对应的结构特征。将以上特征组成特征向量用于RF、Softmax 的输入,通过训练学习构建交易实体分类器。
3.1 联合特征
比特币的每笔交易信息主要包含比特币转出地址、转出金额、所属区块号、所属区块创建时间、接收地址、接收金额等信息。本文从地址、实体、网络结构3 个方面进行联合特征提取。
3.1.1 地址特征
在比特币交易数据中,一个用户可以在每次交易中生成找零地址,也可以对单个地址进行重复使用,因此,有必要根据比特币地址进行用户交易行为统计性描述,构造基于单个比特币地址的特征。为了较为充分地描述比特币交易行为,本文通过统计交易金额、交易方向、交易频次、交易时间、与该地址有过交易的交易对手信息等,构造比特币地址行为原生特征,特征明细如表1 所示。

表1 地址特征Table 1 Address features
3.1.2 实体特征
在比特币交易过程中,会出现交易输出的金额超过用户想要支付的金额的情况,此时,比特币客户端会创建一个新的比特币地址,并将差额发送回这个地址,也可以将差额发送回输出地址,该过程就是比特币的找零机制。正是比特币的找零机制导致大部分的比特币地址使用过后就被废弃,此外一个实体在业务逻辑上代表一个用户,并且一个实体包含多个比特币地址,因此,统计单个比特币地址的特征不能全面地描述用户的交易行为。本文首先通过地址聚类进行实体构造,然后基于实体构造相关的实体特征,对比特币实体的所有关联地址,分别从交易金额、交易方向、交易频次、交易时间方面进行汇总统计,得到比特币实体的原生特征。由于单独通过比特币实体的原生特征无法较为充分地阐述实体的交易行为,因此本文通过构造多个中心性度量特征来衡量实体在交易拓扑网络中的重要性,比如,间接中心性是指某节点出现在其他节点之间的最短路径的个数,如果这个比特币实体的间接中心性高,那么它对整个交易网络图的转移会有很大的影响,间接中心性考察的是节点对于其他节点信息传播的控制能力。实体特征明细如表2 所示。
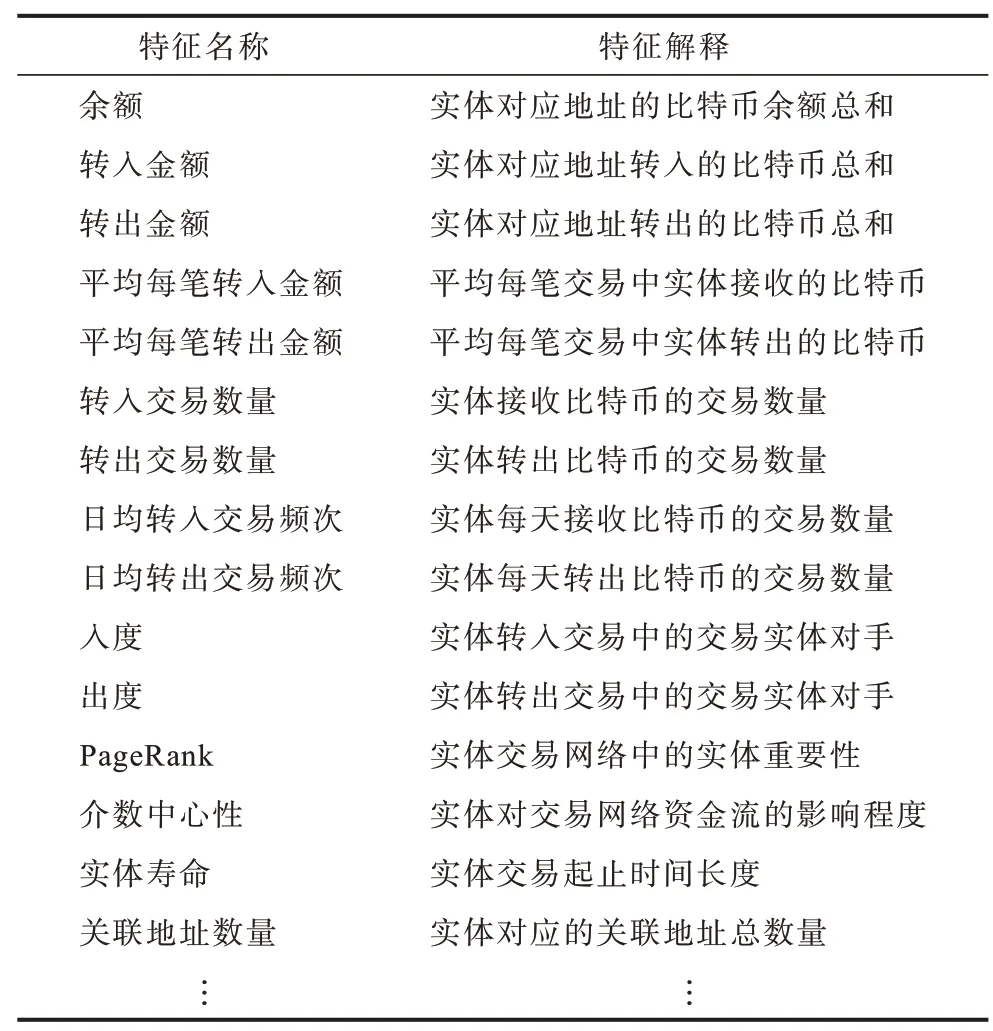
表2 实体特征Table 2 Entity features
3.1.3 网络结构特征
在复杂的交易网络结构中,不同的交易对象采用不同的交易方式,通俗理解为局部统计显著的连接模式,会造成交易网络全局特征不同,而这些特征在仅观察局部交易网络时无法显现。motif 使得交易网络研究不仅局限于交易节点角色或交易网络的整体结构,而是考虑交易网络的微观结构。由于通过motif 可以在复杂网络中发现某种相互连接的模式个数显著高于随机网络,如果特定相互连接模式在网络中出现的概率明显高于随机网络,就可以看成一个模体。由于交易行为不一致,导致不同身份的比特币实体在交易网络拓扑图中具有不同的相互连接模式,因此本文采用motif 的方式进行网络结构相关特征提取。通过一阶motif、二阶motif、三阶motif 抽取的特征明细如表3 所示。

表3 网络结构特征Table 3 Network structure features
3.2 分类方法
在比特币实体类别识别场景中,主要面临从海量交易数据中提取高维数据特征并选择有效特征进行建模、标注样本数据集极度不平衡这2 个问题。为此,本文提出一种RF结合Softmax的方案进行分类模型训练。在该方案中,RF 算法具有随机性的特征,主要体现在训练每棵树时从全部训练样本中进行N次有放回的抽样,每次抽样1 个样本,最终形成有N个样本的训练数据集进行训练,同时随机选取所有特征的一个子集,用以计算最佳分割方式,因此,该方法能够处理高维度的数据并且无需做特征选择,对于不平衡数据集而言,其可以在一定程度上平衡误差。此外,RF 属于典型的集成学习算法,其本身不是一个单独的机器学习算法,而是通过构建并结合多个机器学习器来完成学习任务。将RF 与Softmax 相结合,可以通过集成学习发现多种有区分性的特征并组合特征,将其作为Softmax 模型中的特征从而提升结果的准确性,同时避免单一算法的局限性。该方法在Facebook广告点击预测方面已经被成功应用,文献[21]中阐述了其详细实现过程。基于RF与Softmax 的多分类模型流程如下:
输入样本集D={(X1,y1),(X2,y2),…,(Xn,yn)}
1)对于t=1,2,…,T:
(1)完成模型初始化并进行第t次随机采样,得到包含m个样本的采样集合Dm。
(2)用采样集合Dm训练第m个决策树模型Gm(x),在训练决策树模型的节点时,在节点所有样本特征中选择一部分样本特征,在这些随机选择的样本特征中选择一个最优的特征进行决策树的左右子树划分。
2)对每个样本对应的m个决策树模型的输出进行整合,输入Softmax 进行多分类模型训练,在每一个Epoch(一个Epoch 为对所有训练数据的一轮遍历)结束时,计算验证集的正确率,当正确率不再提高时,停止训练。
目前,用来选择决策树特征的比较流行的指标是信息增益、增益率、基尼系数(Gini)和卡方检验。本文主要介绍基于基尼系数的特征选择方法,原因是RF 采用的CART 决策树就是基于基尼系数选择特征的。基尼系数的选择标准是每个子节点达到最高的纯度,此时基尼系数最小,纯度最高,不确定度最小。对于一般的决策树,假如总共有K类,样本属于第k类的概率为pk,则该概率分布的基尼指数如下:
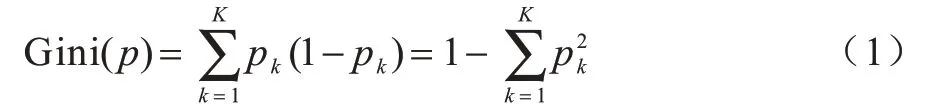
为更好地分析RF+Softmax 模型的分类效果,本文采用RF、LR、LightGBM 这3 种算法进行对比实验:
1)在第一个实验中,建立一个比较简单的分类器,分别采用RF、LR、LightGBM、RF+Softmax 训练模型,得到实体特征分类器,如图3 所示。在这个分类器中,模型训练数据特征只包括从海量交易数据中提取的实体特征,即只将实体相关的特征输入算法中进行训练。
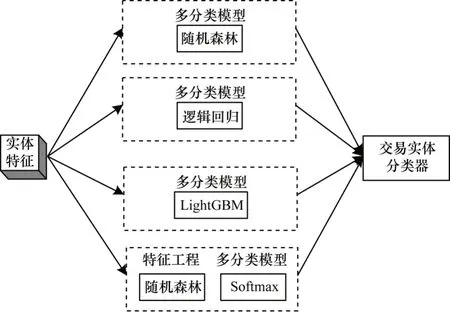
图3 实体特征分类器结构Fig.3 Entity features classifier structure
2)在第二个实验中,本文基于实体特征分类器,构建一个复杂的分类器,称为联合特征分类器,如图4 所示。联合特征分类器主要结合从海量比特币交易数据中提取出的地址特征、实体特征与网络结构特征,将它们输入到4 个不同的算法中进行训练。

图4 联合特征分类器结构Fig.4 Joint features classifier structure
4 实验与结果分析
4.1 比特币实验数据集
本文实验中的所有数据均来自于区块高度小于等于640 000 的交易数据,相当于在交易时间2020 年07 月20 日15:41:09 之前打包完成的区块,大概包括700 000 000 个比特币地址。地址标签数据通过WalletExplorer(https://www.walletexplorer.com)获取,并通过一定的方式进行扩展,所有的数据分析工作均在内存为64 GB 的阿里云服务器上执行。最终标注实验数据集包括6 个类别,367个实体,27 614 172个地址,详细数据如下:
1)交易所:148 个实体,对应12 685 680 个地址。
2)服务商:56 个实体,对应10 139 646 个地址。
3)赌博:77 个实体,对应2 678 281 个地址。
4)暗网:22 个实体,对应1 646 237 个地址。
5)混币:37 个实体,对应369 695 个地址。
6)矿工:27 个实体,对应94 633 个地址。
通过观察各类别的数据可以看出,交易所与服务商的地址数据超过总数据的80%,矿工对应的地址数据占比仅为0.34%,样本数据出现了极度不均衡的情况。
4.2 评估指标
本文对比特币交易实体进行多分类识别,评价指标如下:
1)精确率(P),又称查准率,表示实际为正的样本占被预测为正的样本的比例。
2)召回率(R),又称查全率,表示实际为正的样本中被预测为正的样本所占的比例。
3)F1-score 是精确率和召回率的调和平均值。精确率体现模型对负样本的区分能力,其值越高,模型对负样本的区分能力越强;召回率体现模型对正样本的识别能力,其值越高,模型对正样本的识别能力越强。F1-score 是两者的综合,值越高,说明模型越稳健。F1-score 计算公式如下:

4.3 结果分析
为了方便比较,本文在RF算法的每次建模过程中,将RF 种树的个数统一设置为100,其他算法参数均采用sklearn 与LightGBM 的默认参数。利用比特币特征数据进行2 次不同的实验,结果如表4 所示。从表4 可以看出:联合特征分类模型的结果普遍优于实体特征分类模型;对比联合特征分类模型的准确率、召回率与F1-score 这3个评价指标,RF+Softmax效果最优,LightGBM 次之,RF 效果居中,LR 效果最差;对比RF 与RF+Softmax 的评估指标,RF+Softmax 的精确率与召回率相比RF 分别高出2 个与4 个百分点,表明采用RF 进行特征工程能够抽取出有效的特征,结合多分类模型Softmax 进行训练,更能提升分类器的准确率,避免单一算法存在的局限性。

表4 实验的总体结果Table 4 Overall results of the experiment
联合特征分类模型的实验总体结果优于实体特征分类模型,原因是前者结合多方面的数据特征,能够充分学习到比特币交易实体的多种交易行为。RF、RF+Softmax这2种模型的分类结果明细如表5所示。从表5可以看出:在RF+Softmax 模型下,交易所、服务商、赌博、暗网、混币与矿工能达到0.92 以上的精确率;在所有的实验中,混币类别的实验结果最佳,无误判无漏判,主要因为混币的行为模式较为固定,且大多采用自动化交易,所以模型能够充分学习到混币行为,服务商类别的交易实体召回率只有0.73,通过核查误判结果发现,剩余0.27 的交易实体大部分被误判为交易所,说明交易所与服务商的交易行为存在一定的相似性。

表5 实验的详细结果Table 5 Detailed results of the experiment
5 结束语
本文提出一种RF 与Softmax 相结合的模型训练方案,并利用联合特征构造方法从海量比特币交易数据中抽取地址特征、实体特征与网络结构特征,整合所有的数据特征形成特征向量,输入模型进行训练得到实体特征分类器与联合特征分类器。其中,联合特征分类器的性能优于实体特征分类器,原因是联合特征分类器中新增网络结构特征与地址特征,网络结构特征构造方法在数据特征中引入当前实体的邻居信息,使得模型能够学习到实体更多的交易行为。实验结果表明,通过RF 实现特征工程能够获取到更有效的特征,结合Softmax 进行多分类模型训练可以进一步提高模型的准确率。但是,本文没有考虑到每个交易类别中包括的热钱包、冷钱包、充币地址这3 种类型实体,此外,暗网实体中部分交易实体复用次数较多,然而有少数交易实体在接收账款后几乎再也没有交易,数据特征较少,因此,下一步将对类别标签数据进行细分,从而提升比特币区块链去匿名化的准确率。
