适用于RPA工具的卷积序列推荐算法
2021-12-18候聪颖朱丽霞管晓宁
候聪颖,王 鹏,朱丽霞,管晓宁
(国电南瑞科技股份有限公司,江苏 南京 211000)
0 引 言
RPA是一类流程自动化软件工具,可以把常规工作任务自动化,提升工作效率。然而目前大多数RPA工具只能自动化一些重复性的操作,遇到人工判断(如筛选、判断、选择等)的任务,便难以执行。为了应对这一问题,通常使用推荐系统辅助RPA工具完成人为判断的过程,然而,目前大多数推荐算法只考虑用户的长期兴趣偏好,这不仅需要大量的用户信息,不利于RPA工具的使用,更会影响推荐性能。在实际生活中,考虑用户的短期兴趣和用户与项目之间的交互,不仅能够提升推荐系统的推荐效果,还能减少所需的用户信息。
在这种情况下,序列推荐应运而生,相比较传统的推荐方法,诸如协同过滤[1]利用海量用户中相似用户的兴趣偏好进行推荐,或是基于内容的推荐[2]为用户推荐其自身喜好物品的相似物品,序列推荐试图理解用户的行为习惯,进行更加准确、个性化和动态地推荐。比如情境感知递归神经网络(CA-RNN)[3],通过收集大量上下文的信息来提升推荐性能;或者增加自注意力机制的神经序列推荐系统[4];融合相似度方法和马尔科夫链的Fossil[5];将内存机制引入推荐系统中,并将其与协同过滤的推荐结果相结合的方法[6]。但它们在普通数据集上的表现低于预期,尤其是在稀疏数据集上的表现。
目前序列推荐中,性能较为优异的有引入了长短期记忆模型的记忆优先级模型[7];将自注意力机制与序列推荐相结合的SASRec[8]。但这2种模型偏向于用户的短期兴趣,在某些情况下会出现推荐效果差的情况。也有构建深度递归神经网络(DRNN)[9]用于序列推荐;结合因子分解机(FMs)和基于度量方法的TransFM模型[10];将基于RNN[11]与键值存储网络(KV-MN)[12]集成在一起,构建知识增强型序列推荐模型[13],另外还有二维卷积网络的序列推荐模型(CosRec)[14]以及卷积序列嵌入推荐模型(CASER)[15]。这些方法设计新颖,但在很多方面都有很高的改进空间,诸如扩展神经网络层,增加多层感知器等。
为了解决这些问题,本文构建了一种适用于RPA的卷积序列推荐模型。第一步,将用户行为序列构建的项目嵌入矩阵视为“图像”;第二步,借鉴Inception的设计思想,利用静态和动态2种不同的卷积层从多角度提取用户的短期兴趣偏好[16],并将用户的嵌入矩阵作为用户的长期兴趣偏好一起构建完整的用户兴趣偏好;第三步,通过全连接层将卷积层的输入和用户嵌入矩阵连接起来,将它们投影到有N个节点的输出层,进行推荐。
该模型的主要优点是不需要大量的训练数据,且推荐效果优秀;另外,该模型对序列信息较为丰富的数据具有出色的信息提取和用户偏好构建能力。而RPA工具由于使用场景限制,计算性能一般,并且需要实时做出判断,能够获取到的用户数据也有限,所以该模型的这些优点能够很好地提升RPA工具的应用前景。
1 关键技术理论概述
1.1 Inception网络
Inception网络首次出现在2015年提出的GoogleNet网络中[17],它的出现是卷积神经网络分类器发展史上的一个重要的里程碑。传统的卷积神经网络都是通过增加卷积层来提高分类效果,但这使得卷积网络越来越臃肿,并且会出现过拟合现象。Inception将稀疏特性引入网络中,把卷积神经网络中的全连接层更换为稀疏连接层,这样可以增加网络的深度和宽度,提升性能,并且由于是稀疏网络拓扑结构,可以降低计算量,保证了计算效率。与使用非Inception架构的类似神经网络相比,它的计算效率可以提升2~3倍。
1.2 序列推荐
序列推荐系统(SRSs)主要是通过对序列中的用户项目进行建模(例如观看的电影类别或在在线购物平台上购买物品),从而对用户可能感兴趣的项目提出建议[18]。传统的推荐系统大多都是基于内容和用户的协同过滤,对用户项目的建模方式是静态的,只能获取用户的一般偏好,相反,序列推荐系统将“用户-项目”的交互视为动态序列,并且考虑了顺序依赖性,以捕获用户当前和最近的偏好,基于此做出更为准确的推荐[6]。
序列推荐主要是针对用户的行为进行处理,而用户行为又可分为行为对象和行为类型2种[19]。序列推荐系统将用户行为作为输入,并对嵌入在用户-项目交互序列中的复杂顺序依赖关系进行建模,预测未来一小段时间内用户可能的行动。
2 基于Inception的卷积序列推荐模型
基于Inception的卷积序列推荐模型参考了CosRec[14]和CASER[15]这2种模型,并从Inception网络结构的设计中获得了灵感,其利用多种不同大小的卷积滤波器增加卷积网络的感受野,增强卷积网络提取图像特征的能力。笔者基于这种设计思想构建了本文的推荐模型,如图1所示。从图中可以看出,该模型结构主要分为Embedding查找层、卷积层和全连接层3个部分。
2.1 Embedding查找层

(1)
除了项目的嵌入矩阵外,还提取了用户u的嵌入矩阵Pu∈Rd,如图1所示,用它表示潜在空间中的用户特征,也就是用户的长期兴趣,以此来解决序列推荐模型中缺少用户长期兴趣偏好的问题。

图1 基于Inception的卷积序列推荐模型
2.2 卷积层
卷积层借鉴了Inception的设计理念,设立了动态和静态2种不同的卷积层,如图2所示。
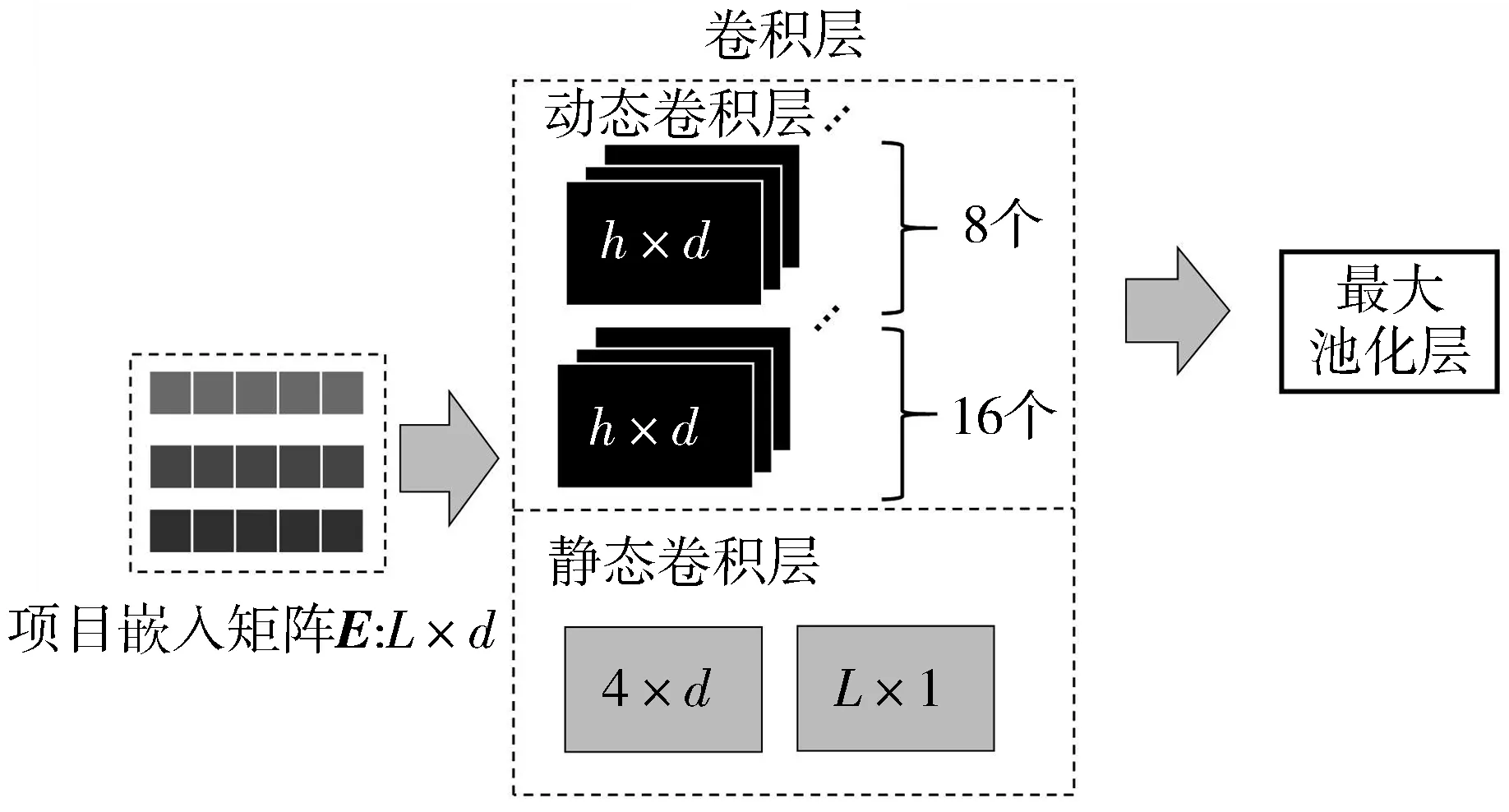
图2 卷积层结构图
动态卷积层中设置了2种不同数量的卷积滤波器Fk、F′k,分别为16个和8个,大小为h×d,其中,d代表潜在维度,h∈{1,2,…,L}。这种宽度会变化的卷积滤波器,可以比较全面地获取行为序列中的信息,同时使用2种卷积滤波器,增加感受野。卷积核中的滤波器数量不同,也就意味着最终输出向量的维数不同,这可以保存不同程度的特征数据,避免在卷积过程中忽略掉一些重要信息。以Fk为例,每一个Fk会在项目嵌入矩阵E上从上往下滑动,并与E中所有水平方向上的项目i进行交互,1≤i≤L-h+1。交互的结果是:
(2)
其中,⊙表示内积运算符,φc()表示卷积层的激活函数,Ei:i+h-1是Fk与项目嵌入矩阵E的第i到第i-h+1行形成的子矩阵之间的内积。最终卷积滤波器Fk的卷积结果为向量ck:
(3)
然后,联合另一种卷积滤波器的卷积结果一同输入到最大池化层中,以提取卷积滤波器产生的所有值中的最大值。对于动态卷积层中卷积滤波器,输出值o∈Rn:
o={max(c1),max(c2),…,max(cn)}
(4)
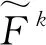
(5)
由于内积交互的作用,很容易验证该结果等于项目嵌入矩阵E的L行加权和:
(6)

(7)
静态卷积层与动态卷积层的不同之处在于:1)每个滤波器的大小固定,这是因为项目嵌入矩阵E的每一列对于推荐模型来说都是潜在的、有价值的;2)无需对静态卷积层的卷积结果应用最大池化操作,因为它们的潜在维度信息的聚合较弱,池化操作会破坏聚合信息。
2.3 全连接层
全连接层将动态卷积层和静态卷积层的输出连接起来,再结合用户的嵌入矩阵一起输入到全连接神经网络中,以此获得更为高级的抽象特征,并进行推荐:
(8)
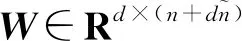
(9)

1)可以很好地把用户的长期兴趣偏好在最大的程度上展示出来。
2)可以将其他推荐模型的参数与其他广义模型的参数一起预训练,这种预训练可以很好地提升推荐模型的性能。
2.4 模型训练及模型推荐
为了训练网络,本文将输出层的值y(u,t)转换为概率表示:
(10)
其中,σ(x)=1/(1+e-x)是Sigmoid函数,令Cu={L+1,L+2,…,|Su|}为要为用户预测的时间步长集合。数据集中所有序列的概率为:
(11)
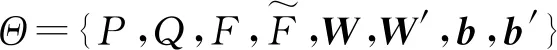
为了在时间步长t内为用户u进行推荐,本文使用u的潜在嵌入矩阵Pu,并从公式(1)中提取出u的最后的L项作为神经网络的输入,并把输出层y中具有最高值的N个项作为Top-N序列推荐的结果,把该结果推荐给用户。
3 实 验
3.1 数据集
本文选取3种公开数据集进行实验:
1)MovieLens 1M。MovieLens数据集是电影评分数据集。本文使用的MovieLens 1M数据集拥有6040个用户观看4000部电影时获得的近100万个评分数据,其中用户的主要的行为类型是观看的电影以及对电影的评分。
2)Gowalla。Gowalla数据集是由公共API于2009年2月至2010年10月间收集到的用户签到数据集[23],本次实验使用了这个数据集中的部分数据,包含6000个用户的526862条数据,其中用户的主要行为类型是在该社交网站上进行签到时的地理位置信息。
3)Steam。Steam是一个大型在线游戏网站,该数据集是从Steam网站上抓取得到的。本次实验使用其中的部分数据,包含21000个用户的1008629条数据,包括用户信息和其游玩的游戏信息,行为类型为游玩的游戏信息。
序列推荐模型着重于用户的行为序列,因此主要保留数据集中的用户信息(用户ID)和与用户进行交互的项目信息,如MovieLens中用户的观影信息、Gowalla中用户签到的地理位置信息、Steam中用户游玩的游戏信息,并参考文献[5,19,24]对数据集的处理,将所有评分数据都转换为隐式反馈1。同时,为了最终推荐效果的考虑和冷启动的因素,删除了冷启动用户和反馈少于n个的用户项,对于MovieLens、Gowalla、Steam,n分别设为5、15、15。处理后的数据集的规模如表1所示。

表1 处理后数据的统计信息
3.2 基准测试模型及评估指标
本文将基于Inception的卷积序列推荐模型与以下5种模型进行比较:
1)BPR[24]。将贝叶斯个性化排名与矩阵分解模型相结合,主要是针对隐式反馈数据进行的非序列项目推荐的最新方法。
2)FMC[25]。FMC将一阶马尔科夫转换矩阵分解为2个低维子矩阵,提取序列信息,进行推荐。
3)FPMC[25]。FPMC融合了FMC和LFM,允许在每一步中都有与一个购物篮中数量一样多的项目,对于本文的序列推荐问题来说,每个购物篮中只有一个项目。这2种方法都是比较新型的序列推荐方法。
4)GRU4Rec[26]。该模型是基于会话的推荐模型,该模型使用RNN提取顺序依赖关系,并进行预测。
5)CASER[15]。一种Top-N序列推荐模型,将用户的行为序列及其在隐藏空间的嵌入矩阵看作一个“图像”,利用卷积神经网络(CNN)的卷积滤波器提取图像的局部特征,以此构建用户偏好,进行预测推荐。
本文采用Top-N推荐的评价指标进行模型的性能评估,包括精确率(Precision@N)、召回率(Recall@N)和平均准确率的平均值(Mean Average Precision, MAP)这3种评测指标。本文设置N∈{1,5,10},以Top-1、Top-5、Top-10作为代表的评测指标。
3.3 性能分析
表2展示了5种基准模型与基于Inception的卷积序列推荐模型的最佳结果。加粗的是每一行的最佳结果,最后一列是本文提出的模型的结果result与5种基准模型中的最佳结果baseline的性能提升程度Improvement,用公式(12)进行计算:
Improvement=(result-baseline)/baseline
(12)
从表2可以看出,基于Inception的卷积序列推荐模型在各项评价指标上均明显领先于进行测试的基准模型。基本提升幅度在10%左右,部分指标能够提升14%,与基准模型BPR和FMC相比,基于Inception的卷积序列推荐模型的性能提升幅度较大,有非常显著的改进;与序列推荐模型FPMC相比,该模型的提升程度也十分明显;与最新的序列推荐模型GRU4Rec和CASER相比,也有一定的提升幅度。整体来看,模型的性能提升明显。
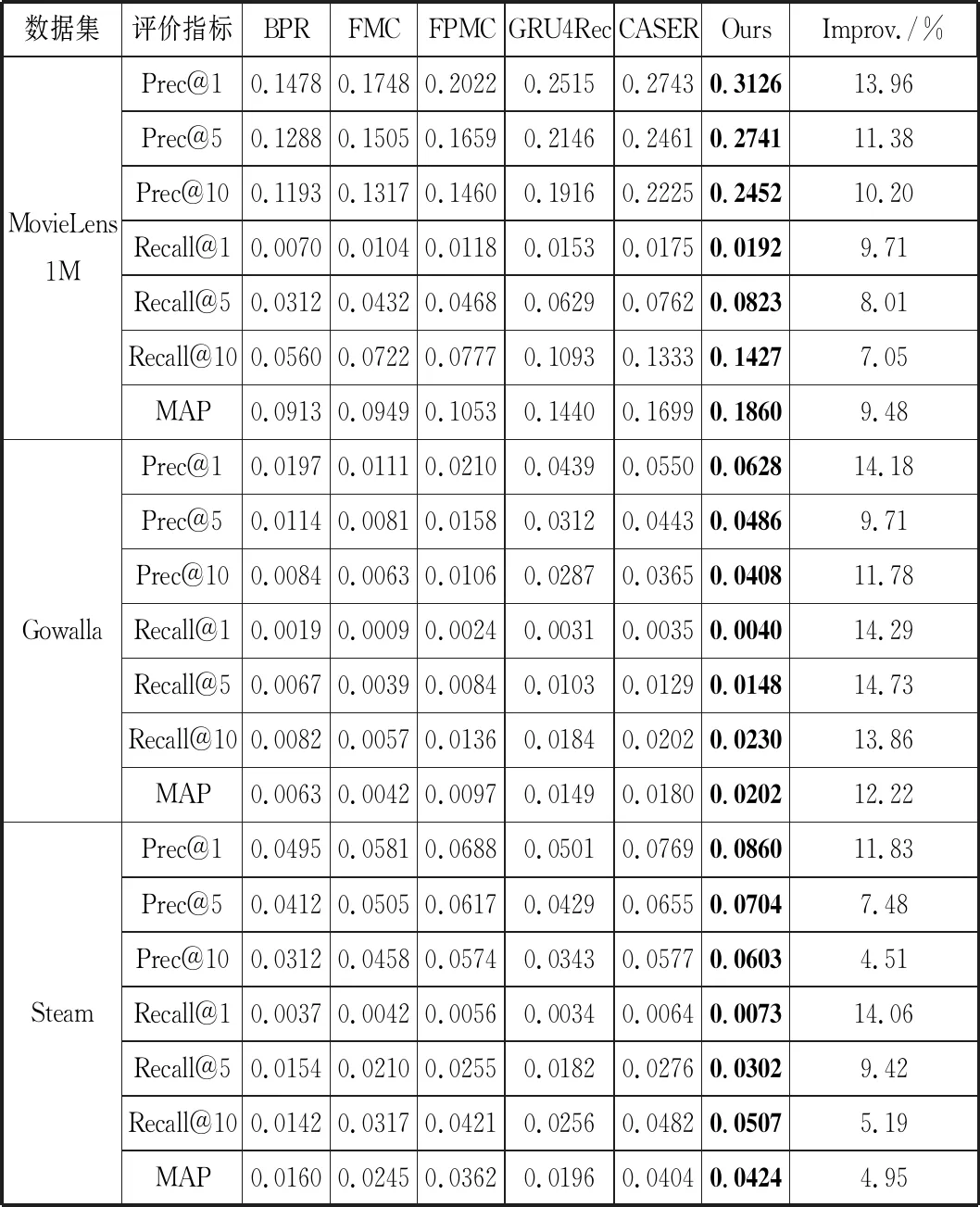
表2 3种数据集上的性能比较
另外,非序列推荐模型BRP在各项指标上均弱于本文提出的模型和序列推荐模型FPMC、FMC,这体现了推荐过程中序列信息的重要性。
3.4 潜在维度d的影响
图3展示了不同潜在维度d下,同时保持其他超参数在最佳设置下的性能变化情况,其中横坐标表示潜在维度d,纵坐标表示MAP。从图中可以看到,在所有实验数据集上,都需要更高的潜在维度才能达到最佳的性能,这是由于模型的复杂程度较大,再加上数据集过于稀疏,用户与项目的交互信息不充分,需要更高的潜在维度数。而对于CASER等其他推荐模型来说,由于本身卷积层设计得较浅,较大的潜在维度并不是总能实现更好的模型性能,如果潜在维度数过大,很可能出现过拟合现象,使模型的表现变糟。

图3 MAP随潜在维度d增长的变化情况图
3.5 卷积层组件分析
基于Inception的卷积序列推荐模型中最为重要的便是卷积层的设计,在2.2节中提到,卷积层是由静态卷积层和动态卷积层2种卷积层构成,共4种卷积滤波器。为了量化判断具体的影响效果,采用控制变量法,每次使用其中的3种卷积滤波器进行实验,对比分析每种卷积滤波器的推荐效果,在3种数据集上的实验结果如表3所示。

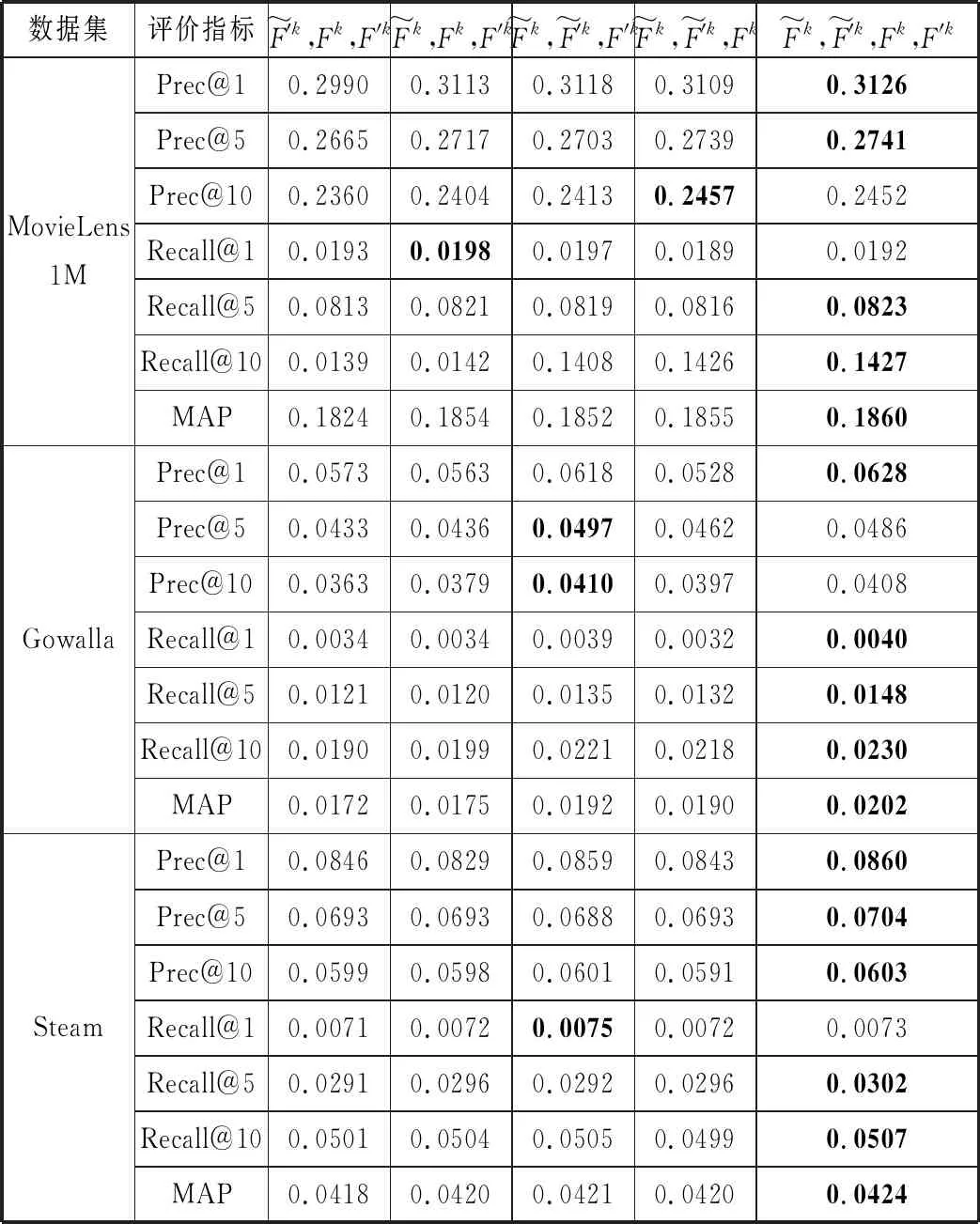
表3 卷积层组件分析
4 结束语
本文提出了一种适用于RPA软件的卷积序列推荐算法及其模型。该模型将用户的行为序列视为一个L×d的“图像”,把行为序列的序列模型信息视为该“图像”的局部特征,然后利用卷积神经网络提取这个局部特征,并结合Inception的设计思想,设计了动态卷积层和静态卷积层相结合的复合卷积网络层,使得模型可以更加全面地获取到序列模式信息。
模型在3种公开数据集MovieLens 1M、Gowalla和Steam上进行训练和性能测试,并与5种基准模型:BPR、FMC、FPMC、GRU4Rec、CASER进行对比,实验表明本模型在各个评价指标上均优于先进的推荐算法。在Top-N序列推荐的3种评价指标(精确率、召回率、平均AP值)中,平均提升幅度在10%左右,单个指标上的最大提升幅度为14%。
