深度连接的超轻量化子空间注意模块
2021-12-18张宸逍王效灵
张宸逍,潘 庆,王效灵
(浙江工商大学信息与电子工程学院,浙江 杭州 310018)
0 引 言
卷积神经网络(CNN)的诞生使极具挑战的图像识别任务取得了远远超越人类的准确性。ILSVRC作为计算机视觉领域最具影响力的竞赛,诞生了包括AlexNet[1]、VGG[2]、GoogleNet[3]、ResNet[4]和SENet[5]在内的许多经典模型。然而,CNN前所未有的准确性能的背后,网络模型的层数逐渐变得更深更宽,更深更宽的层数带来了更高的计算成本和大量的参数,这使得在资源受限的情况下部署CNN变得非常困难。
为了更好地权衡速度与精度,出现了专门为移动设备和资源受限的环境而设计的紧凑型卷积神经网络,如MobileNets[6-8]、ShuffleNets[9-10],使用深度可分离卷积的方式,在尽可能保持模型性能的情况下大大降低了计算成本。此外,人们发现在CNN中引入注意力机制可以在参数量增加不大的情况下明显地提高网络性能。
然而,对于深层CNN而言,现有包括SENet、CBAM[11]、SKNet[12]、GENet[13]在内的大多数注意力机制带来的计算和参数开销相对较小,但对于紧凑型CNN而言,这种性能的提高所带来的计算和参数开销代价是难以忍受的。
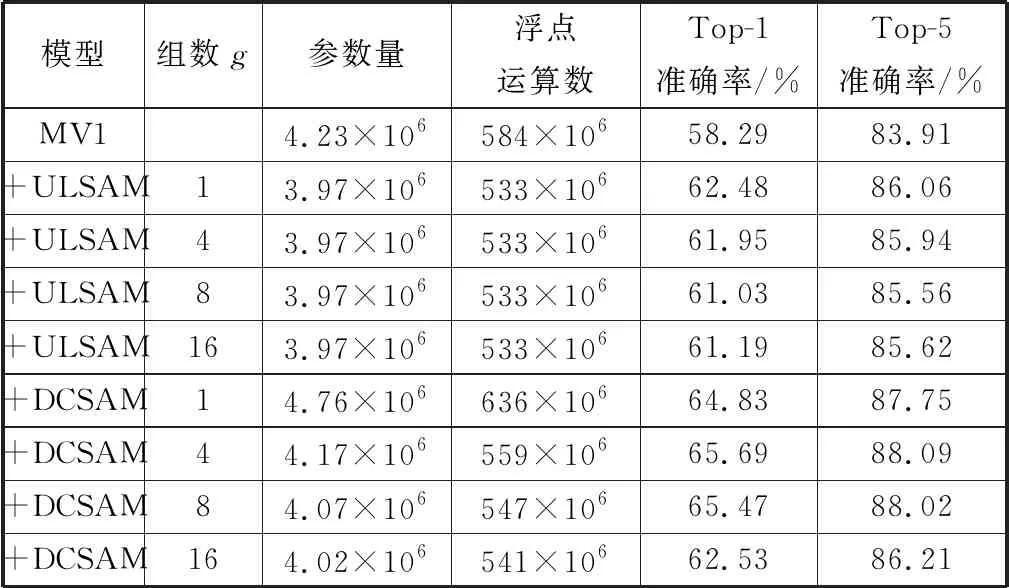
本文继承ULSAM[14]中使用子空间注意机制来提高紧凑型CNN效率的尝试,改进特征子空间的空间校准方式,在特征子空间引入注意连接[15],实现了前后特征子空间的信息流动,相比ULSAM,DCSAM可以更好地学习各个子空间的不同注意映射,实现了多尺度、多频率的特征学习,在细粒度图像分类上取得了比ULSAM更优秀的表现,在ImageNet数据集上也实现了更好的性能。
本文的工作主要体现在以下2个方面:
1)提出了一种新的用于紧凑型CNN的注意模块DCSAM,它可以高效地学习特征子空间的注意映射,并建立前后特征子空间的连接。
2)通过以MobileNetV1和MobileNetV2为骨干网络在ImageNet-1K数据集和2个细粒度图像分类数据上的大量实验,验证了DCSAM的有效性。
1 相关工作
1.1 注意力机制
计算机视觉中的注意力机制从本质上和人类的选择性视觉注意力类似,目的都是为了从庞大信息中凸显出更为关键的信息。目前注意力机制应用在视觉模型中的方法主要有3种:通道注意力、空间注意力和自注意力。
通道注意力针对通道的相互依赖关系,SENet使用了一种全新的“特征重标定”策略,重新对每个通道的权重进行标定,自适应地调整通道间的特征响应。在其基础上,SKNet利用多卷积核分支在不同尺度下自适应地学习特征图注意力,从而聚焦重要的尺度特征。
空间注意力针对空间上的像素级成对关系,BAM[16]和CBAM在关注通道注意力的同时添加了空间注意力模块,自适应地加权关键区域的特征表达,同时弱化背景区域,相比单一的关注通道注意力取得了更好的效果。
自注意力探索输入特征之间的相互依赖关系,通过对输入数据赋予不同的权重,使网络能够自行从复杂的数据中学习到值得关注的区域。NLNet[17]利用自注意力建模远程依赖关系,提出了一种非局部信息统计的注意力机制,GCNet[18]在其基础上结合SENet机制提出了新的全局上下文建模框架,有效节省了计算量。
1.2 子空间注意机制
为了有效节省参数和计算量,使用深度可分离卷积的紧凑型CNN的冗余度相比常规的卷积模型较低。显然,紧凑型CNN更加需要一种能够在低参数量和低计算量的情况下高效学习语义和空间信息的注意力机制。
子空间注意机制的主要思想是将输入特征图分解成若干组,每组子空间独立地进行空间上的重新校准,最后将子空间依次拼接成输出特征图。其中子空间指的是特征图的一部分特征,它是由网络中某一层的特征图按照通道维度分组得到的。包括SENet、CBAM、SKNet等前文所述的注意力模块都致力于更好地提高CNN的表征能力,然而这些注意力机制的计算和参数开销代价[14]对紧凑型CNN来说是难以忍受的。图1为MobileNetV2应用DCSAM和其他注意模块的参数量和计算量的对比图。

图1 注意模块参数量和计算量对比图
本文提出的DCSAM注意模块在参数量和计算量方面都远低于其他注意模块,并且高效地实现了特征子空间跨通道依赖关系的学习。此外,这种模块与现有的视觉模型中的注意力机制是正交和互补的。
1.3 注意连接机制
虽然残差连接已经被广泛应用在CNN模型中,但将残差连接的概念集成到注意力机制的做法直到最近才引起人们的关注。在文献[19]中,RANet在注意模块内部引入了残差连接,利用残差连接来更好地学习注意区域。
在文献[15]中,研究了注意块之间的残差连接,提出了一种连接相邻注意力模块的注意连接机制,通过相邻注意力模块的前馈信息流动来指导注意学习。该注意连接机制实现了对所有注意块的联合训练,注意力学习的能力得到了明显提升,验证了注意力模块间信息交流的重要性。
2 DCSAM注意模块
2.1 改进子空间校准
特征子空间注意模块的思想是将输入特征图分解成若干互斥的组,再对每组子空间特征重新校准,最后将所有校准后的特征依次拼接到一起。但ULSAM子空间校准仅依靠最大池化和Pointwise卷积整合跨通道信息,这虽然在一定程度上减少了计算量,但没有很好地学习到子空间的跨通道依赖关系。为了尽可能减少计算量,使特征子空间在空间层面上更好地加权关键区域的特征表达,同时弱化背景区域,DCSAM利用子空间特征的空间关系生成空间注意图,即对输入通道分别在通道维度上做平均池化和最大池化操作,接着将得到的2个一维的特征图按通道维度拼接在一起,再对通道数为2的输出特征图使用传统卷积进行跨通道信息的整合,实现对子空间的重新校准。
对于给定的输入特征图F,定义经过通道维度上的最大池化和平均池化操作后的特征图为Favg∈1×H×W,Fmax∈1×H×W。该部分的数学处理可以用以下公式表示:
M(F)=softmax(Conv7×7[(AP(F);MP(F))])
=softmax(Conv7×7([Favg;Fmax]))
(1)
其中,softmax代表Softmax激活函数,Conv7×7代表使用卷积核为7×7的卷积,AP和MP分别代表通道维度上的平均池化和最大池化。
此外,DCSAM能够多尺度、多频率地学习跨通道信息。这种使用特征子空间进行注意力学习的方法,不同于采用不同感受野滤波器的多尺度特征学习方法,是一种多尺度特征学习方法的补充。此外,DCSAM可以更为精细地赋予图像中低频和高频分量不同的权重,更适合高度关注高频特征的细粒度分类任务。
2.2 融合子空间注意连接
现有注意机制的设计主要是将注意块插入到某个卷积块后面,这使得每个注意块只能学习到当前特征图的信息而不能将学习到的关键信息传递到其他注意块中,即单一的注意块不能有效地决定关注什么区域。文献[15]认为现有注意机制的协作不足,因而设计了一种连接机制来允许注意块相互协作。
借鉴注意力连接机制的原理,DCSAM将前一子空间唯一生成的单通道特征图Ct-1和当前子空间的特征图进行拼接、融合,之后生成当前子空间的单通道特征图Ct,Ct将作为后一子空间的输入的连接特征图。这种设计也保证了所有注意块之间的信息流以一种前馈的方式流动,防止前后注意信息变化过大,实现了前后特征子空间注意块的相互协作。当然,第一次进入特征子空间时不存在上一环节输出的连接特征图,将跳过合并这一操作。
考虑需要更好地适配紧凑型CNN,DCSAM仅将通道数为1的注意力特征图与之后的子空间进行连接学习。值得强调的是,虽然特征图会被划分为若干特征子空间,但前后子空间的连接是一一对应的。子空间注意连接融合方式如图2所示。

图2 DCSAM子空间网络结构
由于CNN生成的特征图不同,与之相应生成的注意力图也不同,因此在连接子空间注意力时,会遇到通道匹配和空间分辨率匹配的问题。对于通道匹配,DCSAM仅输出单通道特征图用于连接学习,通过直接拼接在后一子空间输入特征图,再调整通道数,可以很轻易地解决通道匹配的问题。对于空间分辨率匹配,为了节省参数,DCSAM使用平均池化来调整,而没有使用引入更多参数的卷积操作。
2.3 DCSAM网络结构
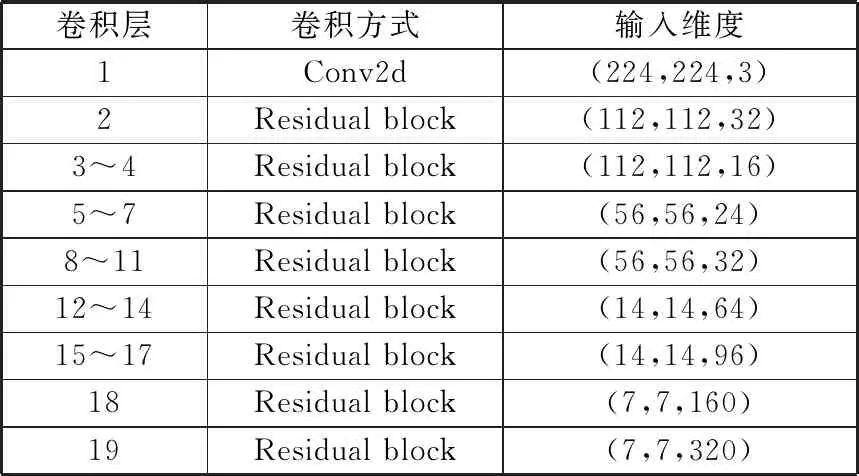
结合前文提出的子空间校准和子空间注意连接,DCSAM子空间网络结构如图2所示,首先对于给定的输入特征图F被分成g个互斥的组[F1,F2,…,Fn,…,Fg],每组包含G个特征图。设Fn∈G×h×w为其中一组特征图,G为输入的通道数,h、w是特征图的空间维度。DCSAM对Fn进行如下操作:
(2)
(3)
(4)
在上述公式中,DW1×1代表卷积核为1×1的Depthwise卷积,PW1×1代表卷积核为1×1的Pointwise卷积,Ct-1代表前一子空间输出的注意连接特征图,⊗代表element-wise product,⊕代表element-wise summation,最终的输出是通过将g组的特征图拼接得到的。
DCSAM通过3种情况来考量分组数g的大小:
1)如果分组数为1,即g=1。此时只有一个子空间,且该子空间包含特征图的全部特征信息,直观地讲,只通过一张注意力图很难完整地学习到整个特征空间的复杂关系。
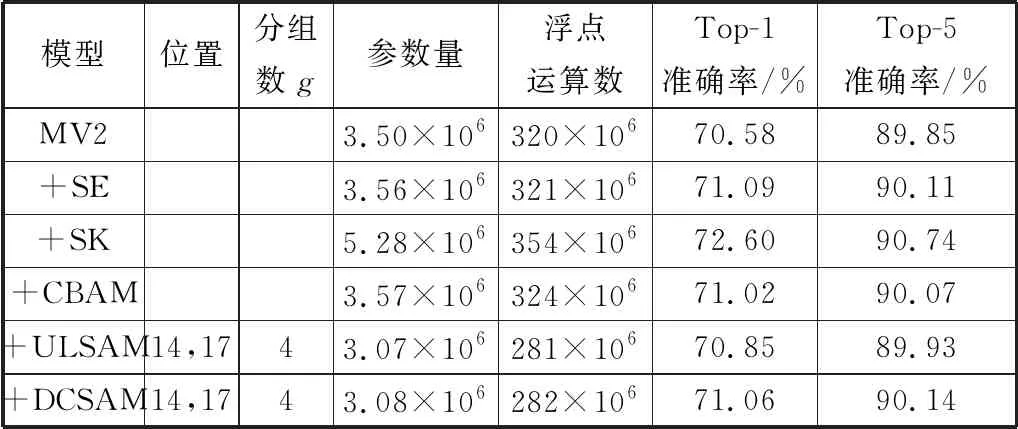
2)如果增加分组数g,即1 3)如果分组数等于通道数,即g=m。此时子空间内只有单通道的特征图,在该子空间内学习到的注意力图不包含任何跨通道信息。显然,此时注意力图能学习的特征很少,注意力图的生成过程沦为了特征图本身的非线性变换。 为了验证本文提出的DCSAM,在ImageNet-1K[20]和细粒度分类数据集Stanford Cars[21]和Stanford Dogs[22]上进行图像分类实验。在实验中,使用Pytorch深度学习框架,以MobileNetV1(简称MV1)和MobileNetV2(简称MV2)作为基线网络。实验所用GPU为2块TITAN XP。为了尽可能公平地比较,将MV1和以MV1作为基线的模型的batch设置为128,SGD优化器的动量设置为0.9,在ImageNet-1K数据集训练90个epoch,在细粒度图像分类数据集训练150个epoch,初始学习率为0.1,每30个epoch后下降到原来的1/10。类似地,将MV2和以MV2作为基线的模型的batch设置为98,设置0.9动量和4e-5权值衰减的SGD优化器,细粒度图像数据集上训练200个epoch。初始学习率设为0.045,每一个epoch后衰减98%。 在应用注意力模块时,网络的深层相比初始层能更好地学习全局特征。且由于网络深层的特征图空间更小,在深层应用自注意力机制比初始层计算量更小[23]。为了更好地适配紧凑型CNN,需要选择DCSAM插入的位置。如表1和表2所示,发现网络中存在许多重复的卷积层,其中MV1网络中重复的8~12卷积层浮点计算数量占其总数的46%,MV2网络也存在大量相同配置的逆残差块。因此,为了更有效地学习跨通道信息,对于这些带来大量计算开销的重复层,将把DCSAM插入到某一层后面,或直接替换掉某一层。例如,在MV1中的第8、9层后插入DCSAM,将第11层替换为DCSAM,在表中就表示为(8:1,9:1,11)。 表1 MV1网络结构 表2 MV2网络结构 通过实验,在细粒度数据集上与子空间注意模块ULSAM进行对比的实验结果如表3~表5所示。 表3 MV1插入位置(8:1,9:1,11)在Cars数据集上的实验结果 表4 MV2插入位置(14,17)在Cars和Dogs数据集上的实验结果 表5 MV2插入位置(13,14,16,17)在Cars和Dogs数据集上的实验结果 MV1+DCSAM在Cars数据集上的对比实验结果如表3所示。 对于MV1,将DCSAM分别插入第8层和第9层后面,同时替换掉第11层。通过替换重复卷积层,使得网络的参数量和浮点运算数都有了明显的下降。对比基线网络,MV1+DCSAM在参数量和浮点运算数普遍下降的同时,Top-1准确率提高超过了4个百分点。其中,MV1+DCSAM(g=4)对比基线网络,在参数量减少1.4%和浮点运算数减少4%的情况下,Top-1准确率提高了7.4个百分点。对比同类型ULSAM,MV1+DCSAM在保持轻量化的同时,由于分组数的不同,Top-1准确率提高达到了1~4个百分点。其中,MV1+DCSAM(g=8)在参数量仅提高1×105的情况下,Top-1准确率提高超过了4个百分点。MV1+DCSAM(g=4)的Top-1准确率最高,达到了65.69%。 MV2+DCSAM在Cars和Dogs数据集上,应用在不同位置的对比实验结果如表4和表5所示。 MV2用DCSAM替换掉第14层和第17层(表4),对比基线网络,网络在参数量和浮点运算数明显下降的同时,Cars数据集上Top-1准确率提高了2~4个百分点。其中,MV2+DCSAM(g=4)对比基线网络,在参数量减少12%的情况下,Top-1准确率提高了4个百分点以上。对比同类型ULSAM,DCSAM在保持轻量化的同时,由于分组数的不同,Cars和Dogs数据集上Top-1准确率提高了1~3个百分点。 MV2应用DCSAM替换掉第13层、第14层、第16层和第17层(表5),对比基线网络,网络参数量减少25%的情况下,Top-1准确率提高了1~4个百分点。其中,MV2+DCSAM(g=4)的Top-1准确率提高了4.71个百分点。对比同类型ULSAM,DCSAM在参数量几乎不增加的情况下,Top-1准确率普遍超过ULSAM。 实验结果表明,在MV1和MV2中插入DCSAM确实获得了更高的准确率,尤其是当g=4时,DCSAM往往能取得最高的性能提升,表明此时生成的注意力图高效利用了相应子空间的跨通道信息。当g≥8时,增加分组数并不能进一步提高模型预测性能,反而略有下降,表明分组过多导致子空间内注意力图能够提取的跨通道信息减少,预测性能提升不多。 为进一步验证本文算法的有效性,在ImageNet-1K数据集上对应用不同注意模块的MV2网络进行了实验,将MV2插入DCSAM时选用了性能提升最多的分组,即g=4。实验结果如表6所示。 表6 MV2应用不同注意模块在ImageNet-1K数据集上的实验结果 MV2应用子空间注意模块的组合在参数量和计算量上明显少于其他类型的注意模块。与基线网络对比,MV2+DCSAM(g=4)在参数量和计算量分别减少了12%和24%的情况下,Top-1准确率提高了0.48个百分点。与添加了SE模块和CBAM模块的组合对比,在参数量和计算量明显降低的情况下,准确率相仿。与同类型ULSAM对比,在参数量和浮点运算数相仿的情况下,Top-1准确率提高了0.21个百分点。 通过实验进一步验证了本文提出的DCSAM注意模块的有效性。DCSAM能够使紧凑型CNN网络在更为轻量化的基础上高效地进行多尺度、多频率特征的学习。 图3利用可视化工具Grad-CAM++[24]展示了MV2网络上应用ULSAM和DCSAM注意模块的热力图。通过对比能够发现,DCSAM更能聚焦目标图像,这更好地解释了DCSAM的有效性。 图3 Grad-CAM++可视化 本文提出了一种新的子空间注意模块,它能够使网络在保持更为轻量化的基础上进行多尺度、多频率特征的学习。这种注意力机制十分适合插入到紧凑型CNN网络中,且与现有的注意力机制是正交和互补的。 但本文提出的方法也存在一定不足,本文方法更关注通道的相互依赖关系,对于空间上的像素级成对关系利用得还不够。下一步工作中,将试图找到一种结合通道注意力和空间注意力的算法来提高子空间注意模块的性能。3 实验结果与分析
3.1 数据集及实验设置

3.2 细粒度分类实验结果


3.3 ImageNet-1K分类实验结果
3.4 可视化

4 结束语
