基于多源信息特征的泰国香米快速鉴别
2021-12-17陈燕雨曹珍珍张宾佳刘也嘉林利忠贾才华赵思明
陈燕雨,曹珍珍,张宾佳,刘也嘉,林利忠,贾才华,牛 猛,赵思明*
(1 华中农业大学食品科学技术学院 武汉430070 2 金健米业股份有限公司 湖南常德415001)
泰国香米(Thai Hom Mali rice)是指经泰国农业合作部农业司确认的泰国当地种植的Kao Dok Mali105 和RD15 品种产生的非糯性香稻谷碾磨的香糙米或香米。泰国香米品质优良,是全球最受欢迎、价格最高的大米产品之一,近年来我国对泰国莱莉香米的进口量日益增加,然而进口和市场销售的泰国香米存在掺伪的问题[1]。《泰国香米检验标准》(编号B.E.2545)中指出不同类别和级别的泰国香米均符合香米含量不少于92%的标准。个别不良商家为降低成本,在泰国茉莉香米中混入廉价的普通大米牟取暴利,侵犯消费者权益,扰乱市场秩序,使得泰国茉莉香米的掺伪鉴别十分重要。
目前,泰国香米的鉴别方法主要包括感官法、水煮法、DNA 鉴定法、气味鉴定法等,然而这些方法存在着受主观因素影响大、成本高或受大米贮藏期影响等缺点。采用近红外光谱技术检测样品时,无需繁琐的前处理和化学反应过程,对测试人员无专业化要求,具有操作简单、测试快捷、无污染等优点。近年来,近红外光谱技术被广泛用于食品品种分类[2]、等级划分[3]、化学成分检测[4]等领域。在品种及产地鉴定方面,有学者应用近红外光谱技术结合偏最小二乘判别法对花椒产地[5]、葡萄酒醋产地[6]、杏仁种类[7]等进行定性鉴定。在化学品质预测方面,近红外光谱技术在对橄榄油甾醇和脂肪酸含量[8]、小麦粉中曲酸[9]等化学成分含量、大米直链淀粉[10]及蛋白质含量[11]预测方面取得较好的效果。在食品掺伪领域,近红外光谱技术被用于鸡蛋粉掺伪检测[12]、食用油真伪鉴别[13]、查哈阳大米真伪鉴别[14]等方面。由于近红外光谱分析主要是根据不同来源大米化学组成含量不同,在近红外光谱图中显示出的吸收峰不同来进行分析,因此用单纯的近红外光谱信息鉴别香米的结果可能并不准确。稻米的整精米率、粒长、垩白度、垩白率、直链淀粉(AC)含量、是影响稻米品质的主要因素[15],而大米的常规指标也具有潜在的鉴别作用,如泰国香米与普通大米相比,外观品质上也存在较大的差异。本研究通过泰国香米和非泰国香米的近红外光谱与常规指标建立多源信息的融合模型,以提高泰国香米识别的准确性和快速性,为泰国香米掺伪鉴别提供一种新的方法思路。
1 材料与方法
1.1 材料
1)主要试验用大米 四色菊泰国茉莉香米、泰玲珑泰国茉莉香米、金谷象泰国茉莉香米、两种乌汶泰国茉莉香米,均为纯种泰国茉莉香米,由金健米业股份有限公司提供。134 种不同品种非泰国茉莉香米产自不同国家和地区,其中金健顶佳泰香米、柬埔寨香米由金健米业股份有限公司提供,泰国大米购置于武汉中百超市,由武汉市嘉禾粮油有限责任公司生产。
2)泰国香米含量为100%的样品 取上述5种泰国香米中的任意两种排列组合,每种组合中两种泰国香米的含量比为9∶1,7∶3,5∶5,3∶7,1∶9,共50 份样品。取上述5 种泰国香米中的任意3种排列组合,每种组合中3 种泰国香米的含量比为1∶1∶1,1∶2∶2,2∶1∶2,2∶2∶1,共40 份样品。
3)泰国香米含量为92%~98%的样品 取金健顶佳泰香米、柬埔寨香米、泰国大米分别与5 种泰国香米配比,使混合后的大米中泰国香米含量分别为92%,94%,96%,98%,共60 份样品。
4)泰国香米含量为20%~80%的样品 取金健顶佳泰香米、柬埔寨香米、泰国大米分别与5 种泰国香米配比,使混合后的大米中泰国香米含量分别为20%,40%,60%,80%,共60 份样品。
1.2 仪器与设备
Supnir-2720 近红外光谱仪,杭州聚光科技股份有限公司;SC-E 大米外观品质检测分析仪,杭州万深检测科技有限公司;CR-400 色差仪,日本柯尼卡美能达公司。
1.3 试验方法
1.3.1 近红外光谱数据采集 仪器预热30 min后进行仪器自检、性能测试和白板参比,然后将大米样品倒入样品盒中,装满后用样品盒盖压平并放入指定位置,开始光谱测定。光谱测定条件:扫描温度为15~25 ℃,扫描波长为1 000~1 799 nm,扫描间隔1 nm,仪器带宽1 nm,光谱数据点数800,光谱重复性优于0.2 nm,信噪比优于2 000∶1,扫描次数3 次,每个样品重复装样扫描6 次,取平均值,作为该样本的原始数据。
1.3.2 大米常规指标检测 称取10 g 大米样品,平铺于大米外观检测仪的扫描仪上扫描大米外观图片,利用大米外观品质检测分析仪系统计算大米千粒重、面积、周长、长宽比、长、宽、整精米面积、整精米周长、整精米长宽比、完整米粒长宽比、整精米长、完整米粒长、整精米宽、完整米粒宽、整精米率、整精米千粒重、小碎米率、碎米率、透明度、精度、垩白粒率、垩白度、圆度及整精米圆度等24 个大米常规指标。
白度的检测使用色差仪。将样品放入石英比色皿中,用色差仪测量样品的L*、a*、b*,并用以下公式计算白度:

式中,L*——黑(0)至亮(100)范围变化值;a*——红色(60)至绿色(-60)范围变化值;b*——黄色(60)至蓝色(-60)范围变化值。
1.3.3 样本集划分 将样本集划分为校正集和验证集,采用Kennard-Stone 法,其中校正集样本数占80%,验证集占20%。Kennard-Stone(K-S)法基于光谱特征选取样本,考虑变量之间的欧氏距离,在样本光谱的特征空间中均匀选取样本,依次选取欧氏距离最远的点进入校正集,留下马氏距离居中的点在验证集中,使光谱差异较大的样本全部进入校正集[16]。
1.3.4 光谱预处理 大米样品近红外光谱的采集主要是利用漫反射光谱,大米颗粒的大小、表面散射及光程变化均会产生噪音。为了降低光谱的信噪比,消除基线和其它背景干扰,需要对近红外光谱进行预处理。研究表明,一阶导数处理可解决基线偏移[17],多元散射校正可消除颗粒分布不均匀及颗粒大小产生的光散射影响[18],去趋势校正可以消除漫反射光谱的基线漂移,基线校正可以消除基线漂移或偏移现象[16]。本试验采用MATLAB软件对样品的原始光谱进行光谱预处理,选用一阶导数、基线校正、多元散射校正、去趋势校正4种方法,并对原始及预处理数据后的光谱数据进行建模,通过对比建模结果,选取最优预处理方法。
1.3.5 主成分分析 主成分分析是一种通过降维技术将多个变量化为少数几个主成分的统计分析方法。能够在最大限度减少原始数据信息丢失的情况下,采用线性变换构造一组互不相关的新变量,并从中提取少数独立综合变量以降低维数、浓缩信息和简化结构,使分析问题的过程更加直观有效[19]。在模型建立之前,需要采用主成分分析对大米的常规指标以及预处理后的大米近红外光谱数据进行降维处理,提取特征数据,使各个主成分的特征值大于1、主成分累计贡献率大于85%[20],并根据累计贡献率确定主成分保留数,将主成分得分作为样本特征向量形成支持向量机分类器的输入向量矩阵,建立泰国香米的多源信息融合模型。
1.3.6 多源信息融合 多源信息融合技术根据不同的信息层面将信息融合的结构模型分为数据层融合、特征层融合和决策层融合。当传感器观测的是同一信息模式时,数据在数据层融合,融合过程结果最准确,数据损失量小且处理信息量大,对系统通信带宽要求较高[21]。当传感器检测得到的信息模式不同时,信息跨度大,可关联性小,宜采用特征层或决策层融合结构。特征层融合过程消除了大量干扰数据,相比于决策层而言,结果可靠性更高[22]。本试验的数据源为近红外光谱信息和大米常规指标信息,数据信息跨度大,数据量大,不适宜采用数据层融合。由于大米近红外光谱被用于识别泰国香米的技术并不成熟,缺乏先验知识组成的知识库,因此采用决策层融合结果准确度低。综上,较适合本试验验的选择是特征层融合结构。
本试验使用的多源信息融合方法是支持向量机(Support vector machine,SVM)算法。大量研究表明,采用支持向量机的算法进行系统辨识时,径向基核函数比其它核函数的辨识效果好,需要调节的参数主要是惩罚参数c和核函数参数g[23]。为了防止模型出现欠拟合或过拟合现象,先利用网格搜索法使c和g在一定范围内分别取m和n个值,然后采用K-折叠交叉验证(K-fold Cross Validation,K-CV)法在m×n个(c,g)组合中寻找最优参数c和g。本试验使用MATLAB 软件建立支持向量机的特征层融合模式分类器模型,采用K-S 法从194 份非泰国香米和155 份茉莉香米中选择155 份和124 份样品作为校正集,其余样品作为验证集。对校正集和验证集的样本数据进行归一化处理,采用径向基函数作为核函数,网格搜索法和K-CV 法确定径向基函数的惩罚参数c、核函数参数g,其中K 取5,c和g的取值范围定为[2-10,210]。用校正集样本对支持向量机分类器进行训练,用训练的模型对验证集进行预测,验证模型的准确率。鉴别模型公式为:
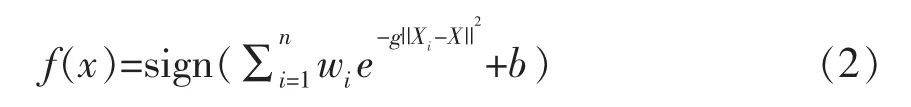
式中,Xi——样本的支持向量;X——待预测标签的样本的特征向量;n——支持向量个数;g——核函数参数;wi——支持向量的系数;b——支持向量对应的参数;f(x)为±1,当f(x)=1 时为泰国香米,当f(x)=-1 时为非泰国香米。
2 结果与分析
2.1 基于常规指标的泰国香米定性鉴定
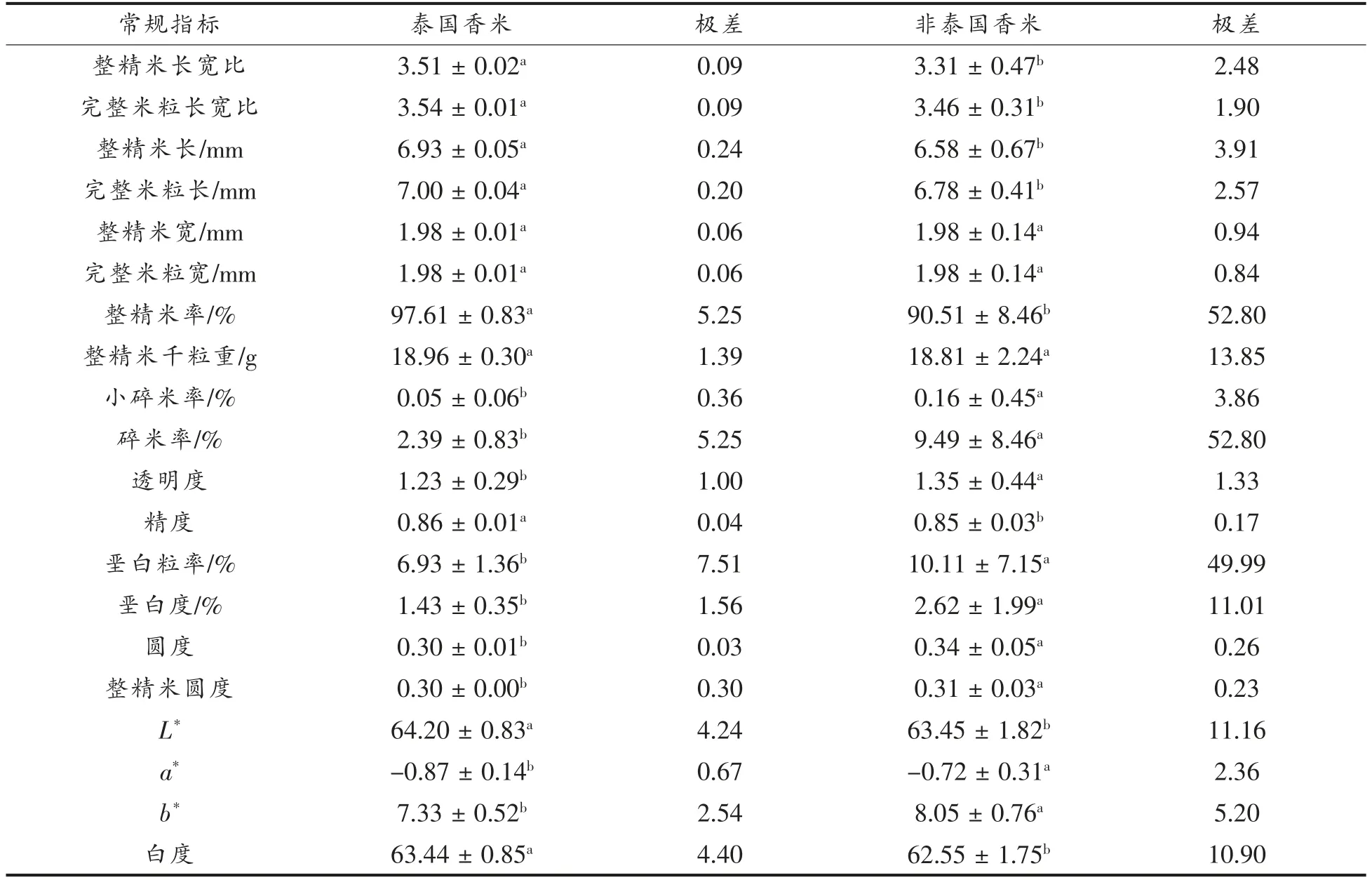
2.1.1 泰国香米和非泰国香米的常规指标 表1是泰国香米和非泰国香米的常规指标,结果显示两者仅整精米宽、完整米粒宽、整精米千粒重不存在差异,其它均存在显著性差异。泰国香米的各性质值变化范围较小,说明泰国香米的常规指标间差异较小。非泰国香米的各性质值变化范围较宽,幅度较大,基本上可以覆盖大米常规指标的范围,可以用于鉴别泰国香米和非泰国香米。

表1 泰国香米和非泰国香米常规指标特征的检测统计结果Table 1 Detection and statistical results of conventional index of Thai Hom Mali rice and Non-Thai Hom Mali rice
(续表1)
在模型建立之前,采用主成分分析对大米的常规指标进行降维处理,将原来具有一定相关性的多变量组合成一组新的相互无关的变量来代替原来的变量,结果见表2。由表2 可知,主成分PC1、PC2、PC3、PC4、PC5、PC6、PC7 的特征值大于1,累计贡献率为87.93%,包含了大米样本大部分信息,因此,可以将前7 个主成分作为数据分析的有效成分。
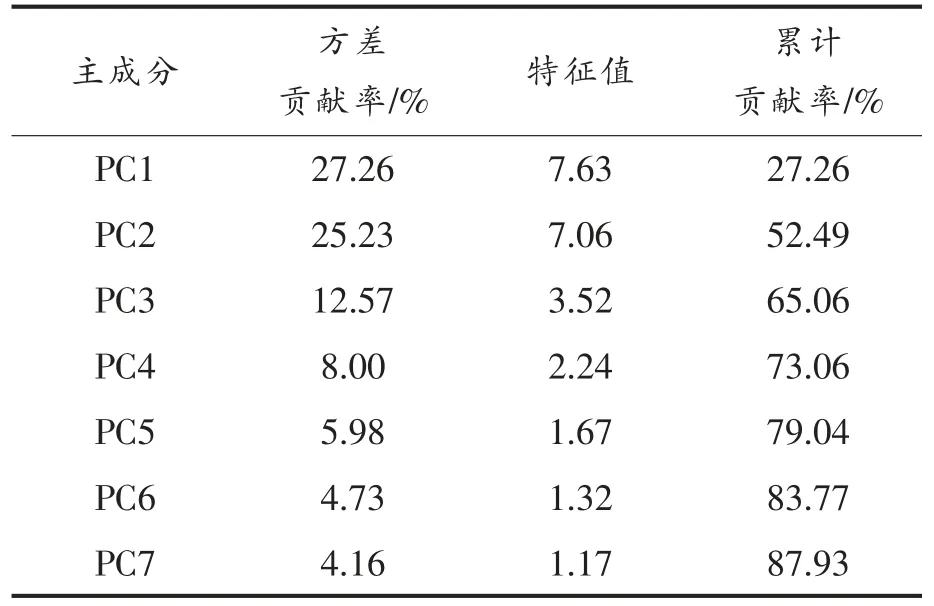
表2 7 个主成分的特征值、贡献率和累计贡献率Table 2 Eigenvalue,contribution rate and cumulative contribution rate of the first 7 principal components
2.1.2 基于常规指标模型的建立与验证 将选取的大米常规指标前7 个主成分的得分作为输入向量矩阵,泰国香米真伪作为输出标签,设定真实值“1” 代表泰国香米样品,“-1” 代表非泰国香米样品,应用支持向量机分类器建立泰国香米鉴别模型,鉴定结果见表3。模型校正集泰国香米样品124 个,样本识别率为100%,非泰国香米样品155个,正确识别151 个,样本识别率为97.42%,校正集总识别率是98.57%。验证集泰国香米样品31个,正确判别26 个,识别率为83.87%,非泰国香米样品39 个,正确判别37 个,识别率为94.87%,验证集总识别率为90.00%,识别效果好。

表3 基于大米常规指标建立的泰国茉莉香米鉴别模型判别结果Table 3 Discriminant results of Thai Hom Mali rice based on the conventional index of rice
2.2 基于近红外光谱的泰国香米定性鉴定
2.2.1 泰国香米和非泰国香米近红外光谱特征泰国香米和非泰国香米近红外光谱见图1。由图1可知,泰国香米和非泰国香米在波峰、波形上十分相似。在1 000~1 799 nm 波长范围内,非泰国香米的吸光值变化范围较大,泰国香米的变化范围较小。

图1 泰国香米和非泰国香米近红外光谱图Fig.1 Near-infrared spectra of Thai Hom Mali rice and Non-Thai Hom Mali rice
2.2.2 预处理后的大米近红外光谱 本研究采用一阶导数、基线校正、多元散射校正、去趋势校正4 种方法对原始光谱进行预处理,预处理后的谱图见图2。一阶导数处理后的近红外光谱重叠峰分开、分辨率提高、信息量增加。基线校正使光谱在1 000~1 400 nm 波长范围内的光谱重叠现象增强。多元散射校正处理使大部分波长内的光谱重叠现象增强,突出部分波长点下的光谱差异,去趋势校正使光谱中吸光值较大的重叠峰分开,平滑掉细小差异。
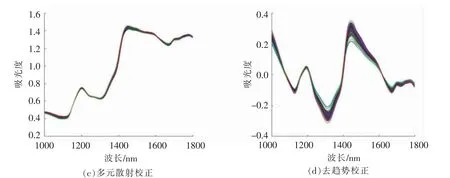
图2 预处理后的光谱图Fig.2 Spectra after preprocessing methods
模型建立之前,采用主成分分析对预处理后的大米近红外光谱数据进行降维处理,提取光谱的特征数据,不同预处理方法主成分分析累计贡献率见表4。由表4 可知,原来的800 个光谱点被压缩成3~8 个主成分,消除了大量重叠信息。

表4 不同预处理后主成分分析累计贡献率(%)Table 4 Cumulative contribution rate of principal component analysis after different preprocessing methods(%)

2.2.3 基于近红外光谱模型的建立与验证 将选取的大米近红外光谱主成分得分作为输入向量矩阵,泰国香米真伪作为输出标签,设定真实值“1”代表泰国茉莉香米样品,“-1” 代表非泰国香米样品,应用支持向量机分类器模型建立泰国香米鉴别模型,鉴别结果见表5。由表5 可以看出,近红外光谱数据预处理后所建模型的校正集和验证集样本总识别率均高于未处理光谱,且一阶导数预处理后的光谱鉴别效果最好,校正集和验证集模型的总识别率分别为99.28%,98.57%,较常规指标鉴别泰国香米效果更好,可能是因为大米近红外光谱不仅与大米中化学成分的组成情况有关,还与大米的常规指标之间存在一定的相关性。

表5 基于大米近红外光谱建立的泰国香米鉴别模型判别结果Table 5 Discriminant results of Thai Hom Mali rice based on NIR spectra of rice

(续表5)
2.3 基于多源信息融合的泰国香米定性鉴定
2.3.1 支持向量机参数优化 支持向量机的惩罚参数c和核函数参数g的优化过程如图3所示,采用K-CV 法优化支持向量机参数。K-CV 法主要是将原始数据均分为K组,使每组数据分别作一次验证集,其余的(K-1)组作校正集,以得到的K个模型最终验证集的分类准确率的平均数作为此K-CV 分类器的性能指标,取分类准确率最高时对应的c和g为最佳参数。图中等高线表示取相应的c和g后对应的模型识别正确率。由图3可知,c=27.8576,g=0.3299 时,模型的识别效果最好,识别正确率为100%。

图3 支持向量机的参数选择Fig.3 Parameter selection of the support vector machine
2.3.2 基于多源信息模型的建立与验证 将泰国香米和非泰国香米一阶导数预处理后的近红外光谱与常规指标特征向量融合构成349 行、14 列向量矩阵作为支持向量机分类器的输入向量矩阵,建立基于多源信息融合的鉴别模型,得到模型见式(3)。
模型中x1~x7表示待测样本常规指标特征信息提取的7 个主成分的得分,y1~y7表示待测样本一阶导数预处理后的近红外光谱特征信息提取的7 个主成分的得分。其中,x1~y7经过归一化处理,在MATLAB 中使用mapminmax 函数,将其数值归一化到[-1,1]。
基于近红外光谱与常规指标融合建立泰国香米鉴别模型的鉴别结果见表6。由表6 可知,校正集和验证集模型的正确识别率均是100%,比常规指标特征信息或近红外光谱信息建立的鉴别模型的识别率高,此模型能够有效鉴别泰国香米。


表6 基于多源信息融合建立的泰国香米鉴别模型判别结果Table 6 Discriminant results of identification model of Thai Hom Mali rice based on multi-source information fusion
3 结论
试验结果表明基于大米常规指标特征信息建立的泰国香米定性识别模型校正集总识别率为98.57%,验证集总识别率为90.00%,此时特征提取的主成分数为7,累计贡献率87.93%。基于大米近红外光谱信息建立的泰国香米定性鉴定模型校正集总识别率为99.28%,验证集总识别率为98.57%,此时适宜的预处理方式为一阶导数,特征提取的主成分数为7,累计贡献率87.88%。将大米近红外光谱及常规指标特征信息融合后建立的基于多源信息融合技术的泰国香米定性鉴定模型校正集、验证集总识别率均为100%,可解决近红外光谱等常用方法鉴别泰国香米时存在的准确率偏低的问题,为泰国香米掺伪鉴别提供一种快速、准确的方法,具有重要的应用价值。
