基于改进残差网络的柑橘病害识别
2021-12-17帖军罗均郑禄莫海芳隆娟娟
帖军,罗均,郑禄,莫海芳,隆娟娟
(中南民族大学 计算机科学学院 & 湖北省制造企业智能管理工程技术研究中心,武汉430074)
近年来,随着人工智能技术的快速发展,研究人员们将目光聚焦到了农业领域,使用人工智能技术对农作物的生长信息、健康情况进行监测与识别,极大地推动了农业信息化的发展.一些研究人员利用卷积神经网络(Convolutional Neural Network,CNN)强大的特征提取能力在计算机视觉领域进行研究,并在人脸识别[1-3]、手写字符识别[4-6]、人体行为识别[7-8]以及农作物识别[9-13]等领域取得了较好的成绩.因此本文基于ResNet[14]网络对柑橘病害图像多类别识别问题进行研究,通过筛选并舍弃对识别结果有较大消极影响的残差结构中的identity映射得到S-ResNet模型,然后在此基础上引入首层卷积核为3×3的M-ResNet模型提取柑橘病害图像中更具表达力的特征,最后使用模型融合方法对2者进行融合.最终对5种柑橘病害的类型识别准确率达到93.6%.
1 数据采集与处理
1.1 数据采集
本文所采集到的实验图像由网上公开数据集与自建数据集2部分组成,共14637张.其中,网上公开数据集的来源为PlantVillage,PlantVillage是一个通用的农作物病害数据库,主要用于供研究人员进行农作物病害检测算法研究,其包含黄龙病病害图像共4643张.自建数据集由在桂林市灵川县九屋镇果园中拍摄的图片,包含溃疡病病害图像4672张、正常叶片图像4864张、疮痂病病害图像175张、黑斑病病害图像283张.为尽量模拟现实拍摄场景,所采用的拍摄设备是三星S10手机,拍摄光照条件为自然光照,聚焦模式为自动聚焦模式,不进行光学缩放与数字缩放,所拍摄的图像像素大小为4032×3024(大小约为3.9M).为最大限度模拟现实中的拍摄场景,保证图像角度、光照与背景的复杂性,在拍摄图像时选择在阴天、晴天以及不同角度对柑橘病害叶片进行拍摄.本文收集到的实验图像由黄龙病、黑斑病、溃疡病、疮痂病以及正常叶片5种类别组成.收集到的部分样本图像如图1所示.

图1 柑橘病害样本图像Fig.1 Sample images of citrus disease
1.2 数据集处理
为保证实验图像的复杂度以及多样性,避免因数据集中某种类别图像数量过少而导致的模型效果不佳问题,需要使用图像增强方法进行处理.常见的图像增强方法有调整大小、图像翻转、图像校正、阴影消除、增强光照度等[15].本文共采用6种方法对数量较少的病害类别图像进行图像增强:旋转(旋转角度分别为90°、180°、270°)、翻转(翻转方式为上下翻转、水平翻转)、光照度处理、对比度处理、色彩平衡处理以及锐度处理.对应的参数调整算法如公式(1)所示:
result=image×α(α∈(0.7,1.3)),
(1)
式中result为结果图像,image为原始图像,α为光照、对比度、色度和锐度的系数.
为使实验数据匹配模型的输入规格,将所有病害图像的宽高调整为256×256,而在调整图像宽高时改变图像的原始宽高比会导致病害区域发生形变从而影响识别准确率,本文在图像的宽或高大于256像素时才进行调整,否则使用零填充(Zero-padding)对不足256像素的图像进行填充.所用数据集在数据增强前后的对比情况如图2所示,数据集在进行图像增强后各类病害的图像数量.无斜线的柱状图表示未进行图像增强前各类病害的图像数量,有斜线的柱状图表示数据集在进行图像增强后各类病害的图像数量.
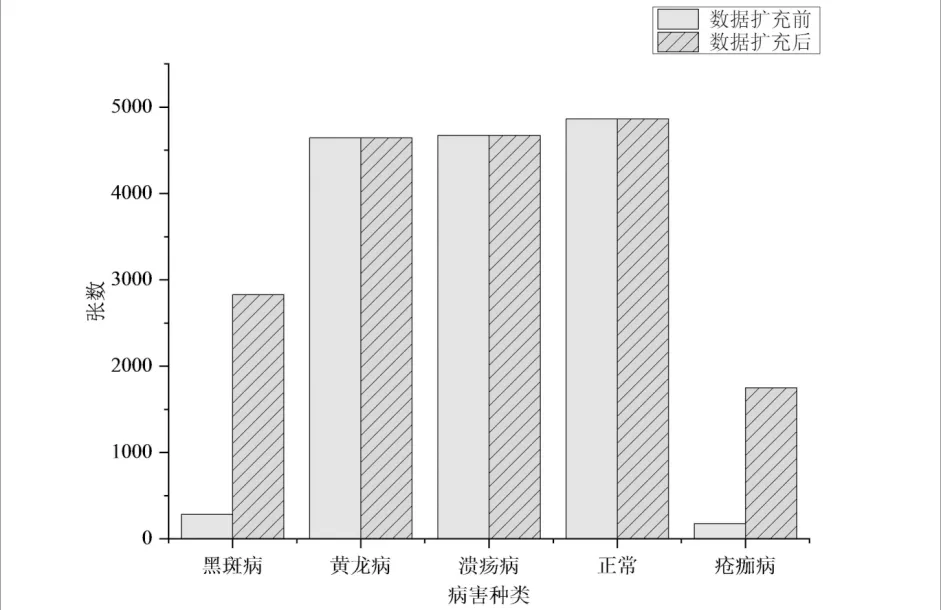
图2 数据集扩充前后的对比Fig.2 Comparison before and after data expansion
2 F-ResNet模型
2.1 ResNet模型
在图像分类研究中,ResNet网络在植物病害分类领域[16-17]取得了较好的效果.ResNet网络通过在残差结构中添加identity映射来解决深度神经网络中的梯度消失问题,因此ResNet成为了计算机视觉领域的主流网络之一.ResNet网络的残差结构主要由identity映射(shortcut连接)与主干网络组成,并使用特征融合方法将主干特征和shortcut特征进行融合,融合方法如公式(2)所示:
H(x)=F(x,{wi})+x,
(2)
式中H(x)为最终输出,F(x,{wi})为主干网络的输出,x为原始输入,wi为第i层卷积层的线性投影.
以ResNet34网络结构为例,其每块残差块结构均相同,因此也称为残差结构.如图3所示.
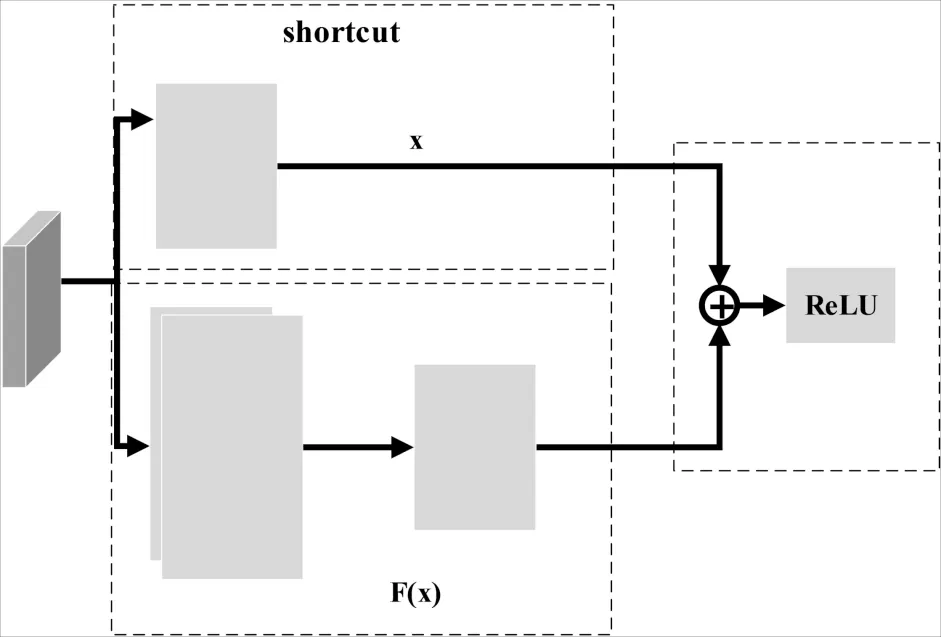
图3 残差块基本结构Fig.3 Basic structure of residual block
2.2 损失函数

(3)
对所有的m个柑橘病害样本,n种病害,当病害图像样本j为病害种类i时,yji=1,否则为0.总损失函数Lcs可以表示为:
(4)
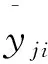
2.3 分类模型结构设计
2.3.1 M-ResNet模型
在卷积神经网络中,不同层卷积核所提取的特征表征信息的强弱程度并非相同,越低层(即输入层)的卷积核所提取的分类信息越弱,空间信息越强;而越高层(即输出层)的卷积核所提取的分类信息越强,空间信息越弱.对ResNet34所提取的特征信息进行可视化展示的结果如图4所示.
根据图4中的(b)可以明显发现,低层的网络特征提取层此时的主要关注点并不在柑橘叶片上,而是聚焦在叶片的周围(颜色越红表示关注度越高,颜色越蓝表示关注度越低),在图4中的(c)可以看出高层的网络特征提取层的关注点已经转移到叶片的病害部位.在柑橘叶片的病害类型不同会呈现不同的表征,最主要的表征是病害部位的颜色和形状不同,但是在模型低层所提取到的柑橘病害图像特征中,空间信息占比更多,影响分类结果的分类信息相对较少.而在卷积神经网络中卷积核越大所提取的特征信息越多,但计算量也会越大,从而导致性能降低.因此卷积核的大小会极大影响模型的识别精度与速度,本文通过将ResNet34网络最低层所有7×7大卷积核按照1∶3的比例替换成3×3小卷积核来提取病害图像在低层中具有更强的表征信息局部特征.假设输入图像的大小为T,则使用3个3×3大小的卷积核的参数计算方式如公式(5)所示,1个7×7大小的卷积核如公式(6)所示:

图4 ResNet34特征信息Fig.4 Feature information of ResNet34
sum3=3×(3×3×T)×C,
(5)
sum7=(7×7×T)×C,
(6)
式中sum3为3×3卷积核的参数总和,sum7为7×7卷积核的参数总和,C为卷积核的个数.
根据公式(5)和公式(6)可知,使用3个3×3的小卷积核来替换7×7大卷积核后可以减少50%的计算量,本文将替换小卷积核后的ResNet34命名为Mini-ResNet,简称为M-ResNet.
2.3.2 S-ResNet模型
现有研究表明[18-19],由卷积网络提取的特征并非都对结果有积极影响,因此HU[20]和WOO[21]等人引入注意机制抑制消极的通道特征,他们的方法比dropout和随机深度(Stochastic Depth)更具有适应性,但在每个构建块中新增额外的分支会增加网络的性能开销.ResNet的identity映射作用是在网络得到最优解后降低信息的冗余度以防止梯度消失,但低层卷积核所提取的空间特征信息较多,因此舍弃掉低层某些残差块中的identity映射可以减少传向高层的空间特征信息,加速网络提取更高维度的分类样本特征,降低消极特征与空间特征信息在网络中的占比,获得比在所有残差块中都使用identity映射更好的效果,并减少网络的性能开销.本文通过消融实验发现在舍弃第5、6、7个残差块(即Conv3_x层,x={1,2,3,4})的identity映射后,模型的准确率相对于未舍弃identity映射之前提高了3个百分点.舍弃identity映射后的残差块的对应公式定义如下:
H(x)=F(x,{wi}),
(7)
公式(7)由公式(2)舍弃原始输入x(即identity映射)后演化而来,其中:
F(x,{wi})=ReLU(BN(H(x)i-1)),
(8)
式中ReLU为第i层的激活函数,BN为批量归一化处理.
其中,ReLU的具体表示如下:
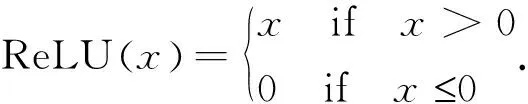
(9)
本文将舍弃部分残差结构identity映射的ResNet34命名为Sparse-ResNet,简称为S-ResNet.S-ResNet网络可以表示如下:
(10)
式中type为病害类型,f为全连接层,F为残差映射函数,p为网络的层数.
S-ResNet的算法流程步骤如下:
Step1:使用大小为7×7×64、步长为2的卷积核对病害图像进行初步特征提取,并使用批量标准化函数和激活函数ReLU对病害特征进行标准化处理,然后使用步长为2的最大池化层对特征进行最大池化.
Step2:使用3组大小为3×3×64、步长为1的主干网络提取深层特征并与identity映射传递过来的特征信息进行融合.
Step3:使用4组大小为3×3×128、步长为2的主干网络提取特征.
Step4:使用6组大小为3×3×256、步长为2的主干网络提取特征并与identity映射传递过来的特征信息进行融合.
Step5:使用3组通道数为512、大小为3×3、步长为2的主干网络提取特征并与identity映射传递过来的特征信息进行融合.
Step6:使用1×1大小的平均池化层将S-ResNet的预测值平铺成一维映射后与M-ResNet的预测值进行特征融合,然后使用完全连接层和softmax函数将融合预测值映射到分类结果矩阵rq中.rq表示为:
rq=soft(fc(ReLU(avgpool(xq)))),
(11)
式中rq为存储预测分类结果概率的矩阵,soft为softmax函数,fc为全连接层,ReLU为激活函数,avgpool为平均池化层.
S-ResNet算法流程中的Step3对应着Conv3_x层的处理流程,在Conv3_x中的残差块不再使用identity映射进行特征传递,具体的结构如图5所示.
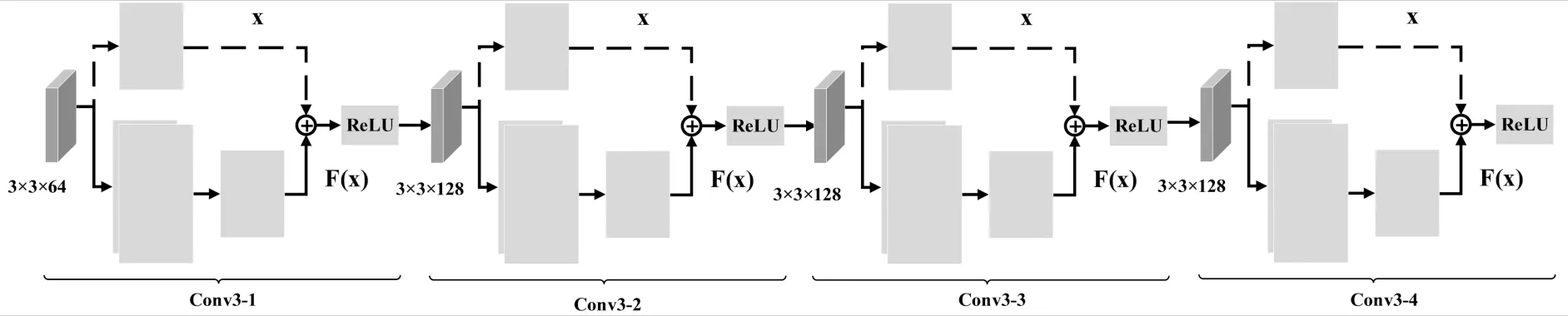
图5 S-ResNet的Conv3_x层网络结构Fig.5 The network structure of S-ResNet in Conv3_x
图5中主干网络(实线部分)与ResNet34中的主干网络一致,identity映射(虚线部分)则用虚线标记为被舍弃状态.在S-ResNet中,经过Conv3_x层的特征需要经过主干网络后才会传递给下一个残差块,并通过线性投影解决残差块之间的输入和输出尺寸不匹配问题.
2.4 模型融合
在图像分类研究中,受光照、背景、拍摄角度、特征区域大小等客观影响,单一模型往往很难在所有场景中均找到最优解.而模型融合方法则可以解决单一模型中存在的识别场景单一问题,常用的模型融合算法有交叉融合法(Blending)、瀑布融合法(Waterfall)、堆叠法(Stacking)、线性加权融合法等.本文使用线性加权融合法将M-ResNet和S-ResNet进行融合,具体的过程为:将两个模型的最顶层的输出特征进行汇总,然后使用不同的算法赋予不同的权重从而进行特征融合,从而得出最终的识别结果,如公式12所示:
(12)
式中Target为融合后的结果,s为模型数量大小,t为要进行融合的特征数量大小,τ为模型k中第a个特征所占的权重,ϑ为模型k中第a个特征值.
在对两个模型进行线性加权融合后得到融合模型Fusion-ResNet,简称F-ResNet.F-ResNet的结构简图如图6所示.
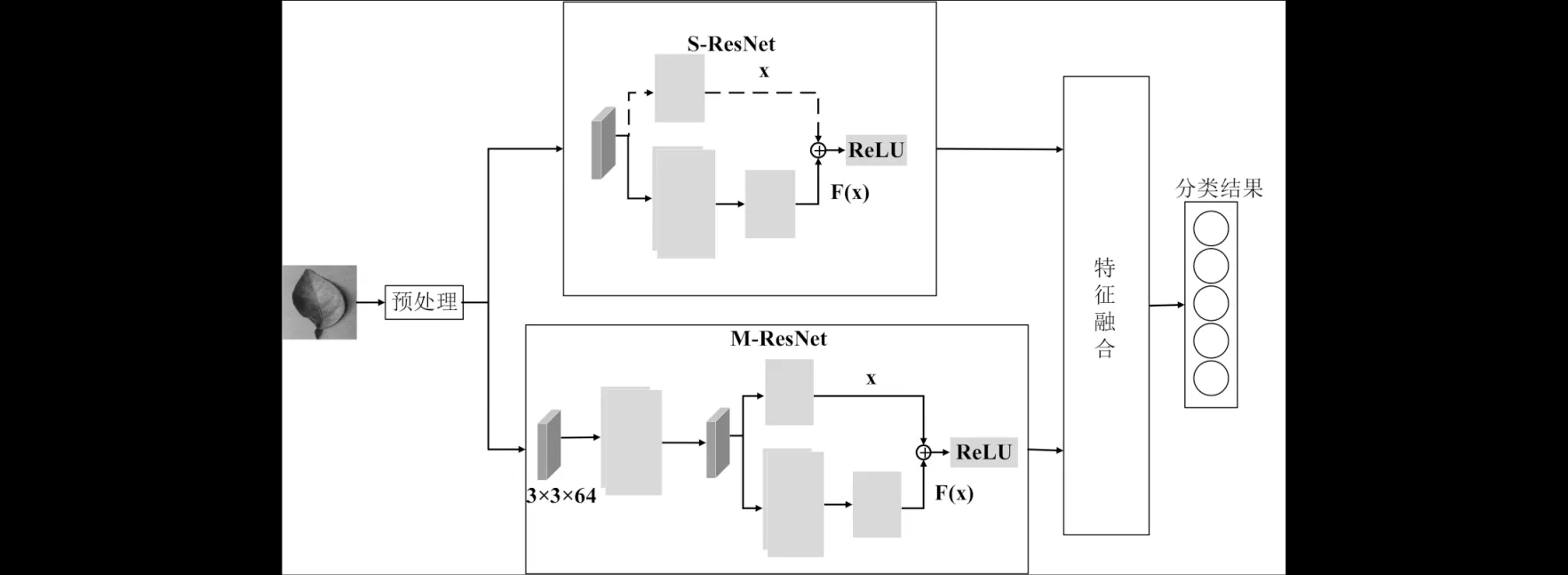
图6 F-ResNet结构简图Fig.6 Diagram of F-ResNet
F-ResNet可以提取并融合不同角度的柑橘病害图像的病害特征,增加柑橘病害识别网络病害特征的多样性,提高模型的泛化能力与识别准确率.相对于S-ResNet,F-ResNet网络的识别准确率提高了2%,同时增加了模型在自然复杂环境下的可用性.
3 实验
3.1 实验环境
本文实验环境如表1所示.所有实验均训练1000个epoch,选用Momentum为优化器,动量值为0.9.学习率为动态学习率,初始值为0.01,在模型准确率不再提升时,动态降低学习率提高模型的学习能力.受硬件设备限制,batch值为80并采用L2正则化在损失函数上增加惩罚项约束参数大小,防止网络过拟合.
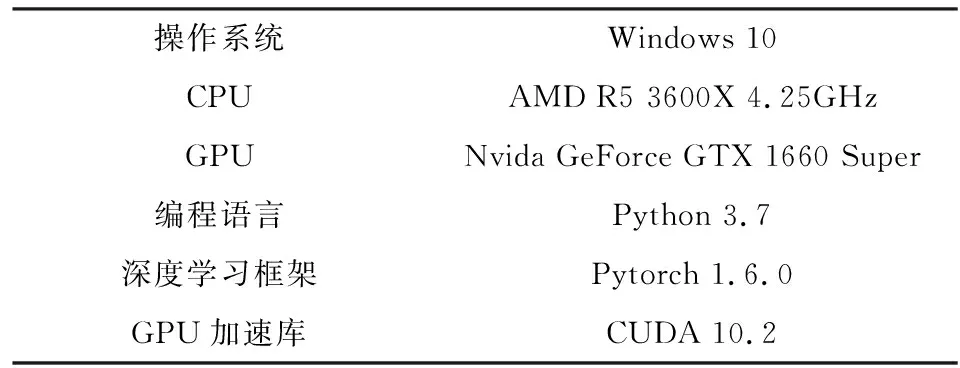
表1 实验环境Tab.1 Experimental environment
3.2 实验评价指标
本文使用精确率(precision)和准确率(accuracy)和混淆矩阵3个评价指标评估网络的性能.精确率和准确率的计算方法如公式(13)和公式(14)所示:
(13)
(14)
式中P为精确率,A为准确率,TP为正样本被正确识别的数量,FP为负样本被错误识别的数量,FN为正样本被错误识别的数量,TN为负样本被正确识别的数量.
为避免评估指标的偶然性,对多次实验取平均值,平均精确率和平均准确率的计算公式如式(15)和式(16)所示:
(15)
(16)
式中u为重复实验的次数,u=10.
混淆矩阵(Confusion Matrix)是用来总结分类模型预测结果的分析表,以矩阵的形式来显示分类模型对每一类的预测结果正确与否,其中对角线上的元素表示各类别病害被正确识别的概率,其它元素则表示被错误识别的概率.
3.3 实验设计
本文将数据集分为训练集与测试集两部分,根据FERENTINOS[22]的工作可知,在将训练集与测试集的划分比定为8∶2时模型的性能最好,因此本文的训练集占比为80%,测试集占比为20%.
为比较ResNet34相对于其它网络的性能,本文选取VGG16[23]网络和DenseNet121[24]网络与ResNet34网络在本文的数据集中进行对比实验,结果如表2所示.
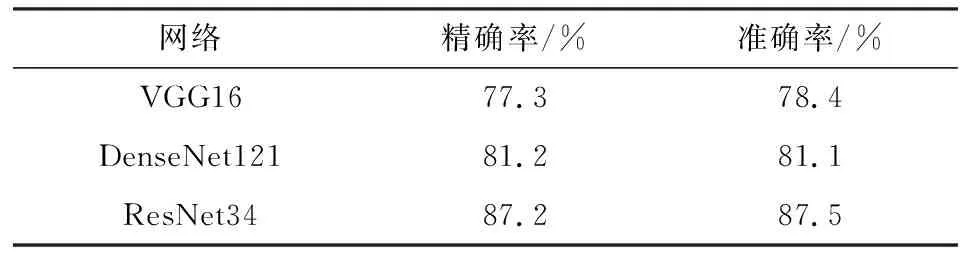
表2 不同网络对比实验Tab.2 Comparative experiment of different network
由表2可知,ResNet34的精确率与准确率在3个模型中最佳,分别为87.2%和87.5%,因此本文选用ResNet34作为自然复杂环境下柑橘病害识别研究的基础网络.ResNet34模型的柑橘病害识别可视化过程如图7所示,ResNet34模型提取病害图像特征后得到5个大小分别为64、64、128、256、512的特征图,对512大小的特征图进行平均池化与全连接操作后,将预测结果映射到输出层.

图7 柑橘病害识别的可视化过程Fig.7 Visual process of citrus disease identification
3.4 实验结果与分析
为比较S-ResNet、M-ResNet与F-ResNet的性能,使用本文的柑橘病害数据集对3个网络进行训练,训练过程的准确率曲线变化如图8所示.
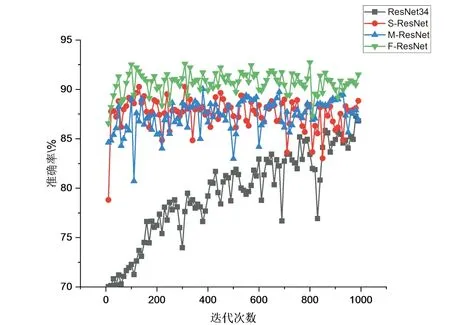
图8 模型训练过程曲线Fig.8 Model training curve
从图8中可以看出,S-ResNet模型与M-ResNet模型的平均准确率相对于ResNet34模型有不错的提升,并且准确率曲线更加平滑,而F-ResNet模型的平均准确率相对于S-ResNet模型与M-ResNet模型均有较好的提升.
3.4.1 不同残差结构对比实验
为验证ResNet34模型在舍弃哪些残差块中的identity映射后可以达到最好的效果,本文通过消融实验进行对比,即舍弃不同的残差结构中的identity映射并训练1000次.若舍弃某个残差结构的identity映射后,模型的准确率变高则说明该残差结构所提取的消极特征较多,反之消极特征较少.实验结果如表3所示.

表3 80%数据集的对比实验Tab.3 Comparative experiment of 80% dataset
由表3可知,将Conv5_x层残差结构的identity映射舍弃后,ResNet34模型的准确率变低,在舍弃Conv2_x层、Conv3_x层残差结构的identity映射后,模型的准确率变高.实验结果表明高层残差结构所提取的积极特征信息较多,低层残差结构所提取的消极特征信息较多,因此舍弃低层的identity映射后有助于提供模型的识别准确率.
3.4.2 不同测试集对比实验
为验证ResNet34模型在使用小数据集时舍弃哪些残差块中的identity映射后可以达到最好的效果,本文使用每种病害为200张的训练集进行消融实验,实验结果如表4所示.

表4 每种病害200张训练集的对比实验Tab.4 Comparative experiment of 200 pictures per disease in training set
从表4中可以看出,在使用小数据集对模型训练时,舍弃Conv3_x层identity映射的ResNet34模型,即S-ResNet,依然表现出最好的性能.
为了对比ResNet34与S-ResNet对不同类别病害的识别效果,通过使用不同大小的训练集以及不同类别病害的测试集进行对比实验,实验结果如表5所示.
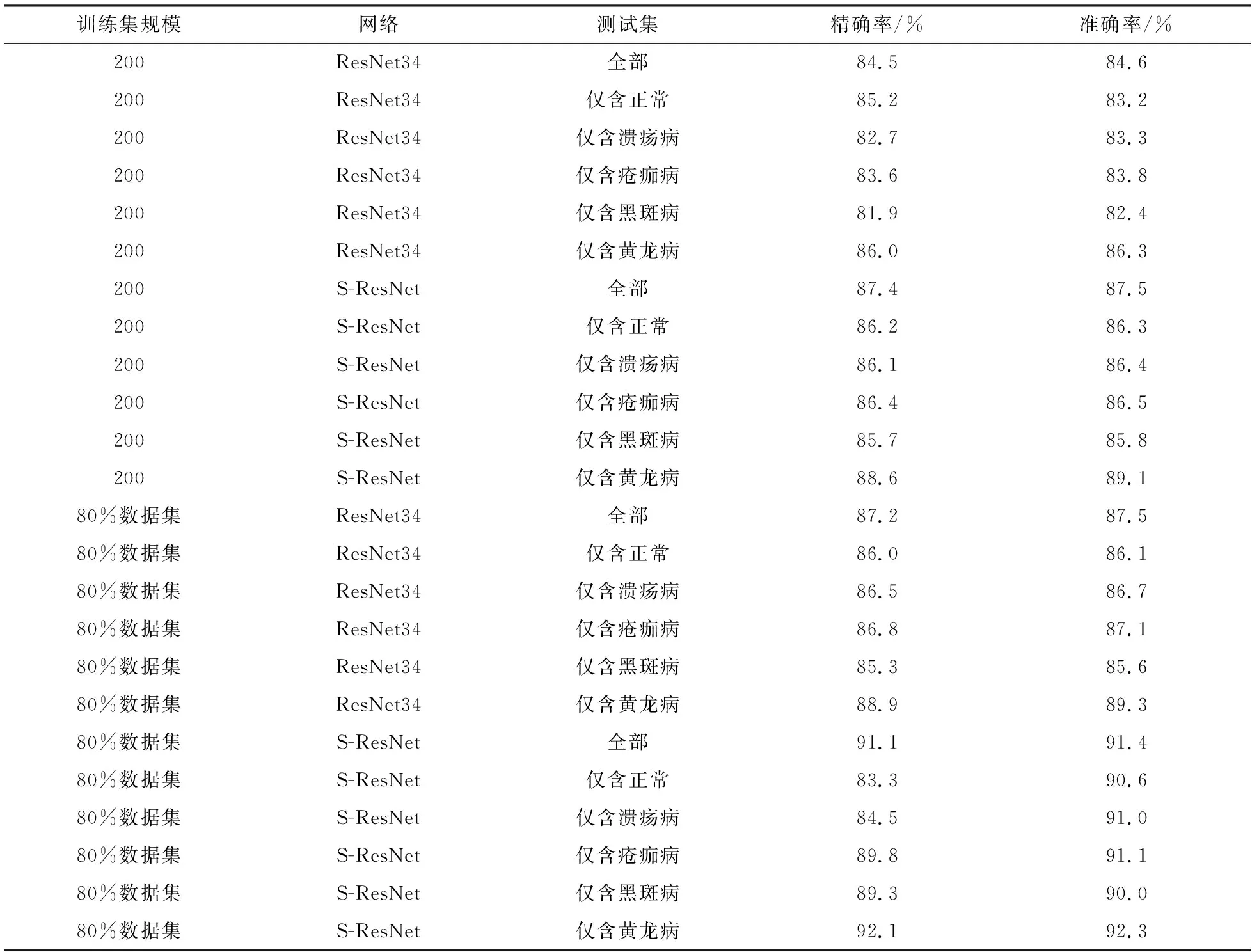
表5 ResNet34与S-ResNet在不同测试集与训练集下的准确率对比Tab.5 Accuracy comparison of ResNet34 and S-ResNet in different test sets and training sets
根据表5可以发现,本文改进的模型S-ResNet在对不同类别病害进行识别时的准确率相较于的ResNet34模型均有较好的提高.
3.4.3 不同数据预处理对比实验
在本文所用数据集中,黑斑病与疮痂病图像数量较少,本文通过使用旋转变换、翻转处理、光照度处理、对比度处理、色彩平衡处理、锐度处理等操作扩充这两种病害的图像数量.为验证这6种方法对F-ResNet的性能是否有影响,同时验证不同数据增强方法的合理性,本文通过不同的数据增强方法组合进行消融实验,观察不同的数据增强方法对模型性能的影响,训练集与测试集的划分比均为8∶2,实验结果如表6所示.

表6 不同预处理的对比实验Tab.6 Comparative experiment of different preprocess
根据表6中结果可以发现,未进行任何数据增强时模型的精确率与准确率偏高,这是由于黑斑病和疮痂病的测试集图像数量过少而导致的.在使用所有数据增强方法对图像进行扩充后,随着测试集图像的数量与复杂度增加,模型的准确率相对于原来有所降低,最终准确率为93.6%,相应的混淆矩阵如图9所示.根据图9可以发现此时模型对各类病害的识别准确率已经分布比较均匀.因此使用不同数据增强方法对数量较少的病害图像进行扩充后,可以更好地提升模型的泛化能力,并取得较好的识别性能.

图9 使用数据扩充后的数据集下的混淆矩阵Fig.9 The confusion matrix under the expanded dataset
为更好观察数据集扩充前后对模型性能的影响,本文使用未进行数据增强的数据集、采用所有数据增强方法的数据集以及随机选取的只经过锐度处理的数据集对模型进行训练,训练过程中的Loss值变化对比结果如图10所示.

图10 不同预处理方式的Loss变化值对比Fig.10 Comparison of loss changes in different preprocess
在图10中,“全部”表示对数据集采用所有数据增强方式,即6种数据增强方式;“无”表示未进行数据增强,“锐化处理”表示仅进行锐化处理.从图10中可以看出,在未进行任何预处理时,Loss值下降得最快,但波动幅度也很大,这是由于未进行数据增强时,数据集中的黑斑病与疮痂病图像数量较少,模型产生了过拟合.经过初步锐化处理后,模型的Loss值变化开始变平滑,在使用所有数据增强方法后,Loss值变小,模型性能也进一步改善.
4 结论
本文针对实际生产活动的柑橘病害识别研究,提出基于ResNet34的柑橘病害检测方法,主要的创新点如下:
(1)通过舍弃ResNet34中Conv3_x层残差块的identity映射,以加强网络低层对图像中的病害特征的提取,相对于ResNet34的识别精度提高3.9%.
(2)使用小卷积核替换大卷积核来提取图像中更具表达力的病害特征,并采用模型融合的方式对所提出的S-ResNet模型与M-ResNet模型进行融合从而得到比单一模型更好的性能.
