演化的汉语同现网络的Laplacian谱分析
2021-12-17张子涵
张子涵,梁 伟
(河南理工大学数学与信息科学学院,河南 焦作 454003)
人类语言是一个经过长期演化而形成的复杂系统[1].语言的许多重要特性都可以利用复杂网络来描述.近年来,语言网络成为复杂网络研究的热点问题之一,它为我们进一步了解语言的特性提供了新思路和新方法[2-3].
谱分析方法能够揭示大规模且复杂环境下相互作用的实体之间的全局结构模式[4].实践经验表明,谱分析方法可能更适合于缺乏规律性的数据[5].近年来,在社团探测、互联网、生物网和社会网络等方面,利用谱分析方法来研究网络的结构信息已经引起了越来越多的研究者的关注[5-8].
在语言网络邻接矩阵特征谱的研究方面,已经取得了非常丰硕的成果.2007年,Cancho等在语法网络中利用谱分析法将同类的单词进行了聚类[9].2009年,Mukherjee等研究了语音网络的特征谱,发现谱密度中间呈三角形分布,而尾部却服从幂律分布[4].2010年,Choudhury和Chatterjee研究了英语、法语等词同现网络的特征谱密度,发现它们都具有三角形分布[10].2015年,笔者研究了由诗歌构建的1 010个中、英文同现网络的特征谱密度,发现在1 007个网络中出现了“M”-型分布,而其它3个字网络则呈三角形分布[11-12].2016-2017年,笔者研究了由四种文学体裁构成的中、英文同现网络的特征谱,并比较了它们的异同[13-14].近年来,又研究了演化的汉语网络的统计参数之间的关系,发现特征谱的行为不会随着时间的变化而改变[15].最近,我们研究了11个不同历史时期的汉语网络的特征谱,并得到了一些有趣的结论[16].
邻接矩阵的特征谱包含了网络的局部信息,而Laplacian特征谱却反映了网络的全局属性[17].对于一些难以计算或估计的网络而言,Laplacian谱可以提取一些有用且重要的信息[18].如今,Laplacian谱在解决实际问题中已经得到了非常好的应用[7,17-21].
但是,在语言网络中对Laplacian谱的研究却很少.2002年,Belkin和Goldsmith利用特征向量分解法研究了英语和法语网络模型的Laplacian矩阵的特征向量[22].除了文献[22]之外,没有发现语言网络中有关Laplacian特征谱的其它研究成果.演化的汉语网络的Laplacian谱有什么特性?这些特性是否会随着时间的演化而改变呢?演化的汉语网络的邻接谱和Laplacian谱之间有何异同?通过研究演化的汉语网络的Laplacian谱能否得出有意义的结论呢?本文尝试解决这些有趣的问题.
本文基于不同大小和类型的语料库,建立了演化的汉语同现网络,并利用Laplacian谱分析法对这些网络进行了系统的研究.
1 基本概念
如果网络包含n个节点,那么它的邻接矩阵A定义为(aij)n×n[23],其中如果节点i、j之间有边相连则aij=1,否则aij=0.ki=∑jaij为节点i的度.设
D=diag(k1,k2,…,kn)
是一个对角线上元素为节点度的对角矩阵,则矩阵
L=D-A
称为该网络Laplacian矩阵[24].λ是L的特征值,如果存在一个n-维非零向量x,使得
Lx=λx.
L的所有特征值构成的集合称为Laplacian谱.对于无向网络而言,L是实对称矩阵,因此它具有n个(可能各不相等)实特征值,并且对应的n个特征向量是相互正交的[23].它的最小特征值λ=0,其它特征值全为正[25].因此,可以将L的特征值排序为:
λ1≥λ2≥…≥λn-1≥λn=0.
谱密度[17]定义为
其中,
2 主要结论
在字(词)同现网络中,节点表示字(词),若两个字(词)至少在一个句子里连续出现,则它们之间用一条边相连[15].文献[15]研究了演化的现代汉语网络的邻接矩阵的特征谱.邻接矩阵和Laplacian 矩阵的特征谱不同.Laplacian谱反映了图的全局属性,而邻接谱却只包含了其局部属性[17].演化的汉语网络的Laplacian谱有什么特性?这些特性是否会随着时间的演化而改变呢?演化的汉语网络的邻接谱和Laplacian谱之间有何异同?通过研究这些网络的Laplacian谱能否得出有意义的结论呢?为了解决这些问题,本文分别从散文、小说、科普和新闻中随机选取了200篇中文文章,它们也是文献[13,15]中的基本语料库.10、30、50、100、150和200篇文章分别合在一起,构建了12个字、词同现网络,分别用Net10、Net30、Net50、Net100、Net150和Net200 表示.在这些网络中,前者中的文本是后者的子集,即Net10⊂Net30⊂Net50⊂Net100⊂Net150⊂Net200.它们可以看作是演化的汉语语言网络[15].我们计算了这些网络的Laplacian谱,并在表1中列出了部分数据.
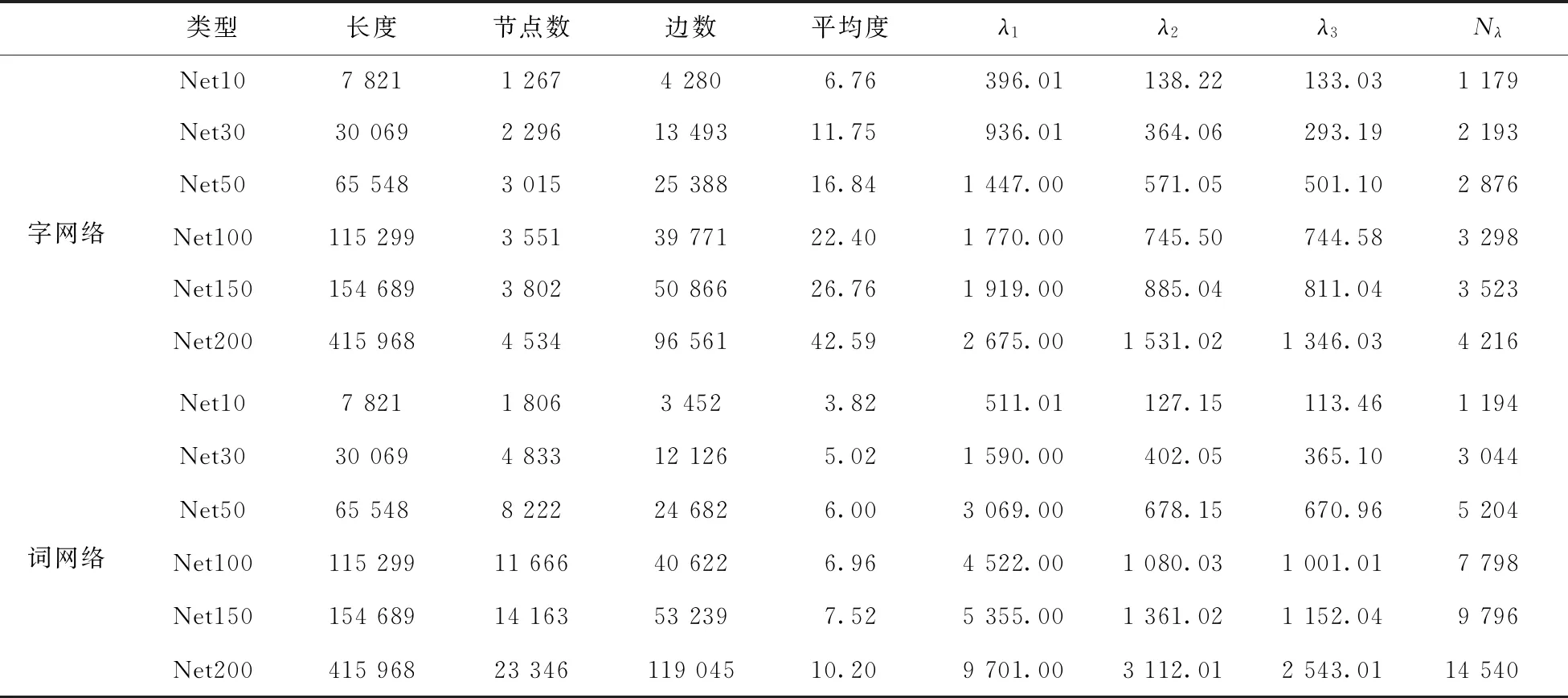
表1 演化的汉语字、词网络的统计参数Tab.1 Statistical parameters of the evolving Chinese character and word co-occurrence networks
2.1 谱密度
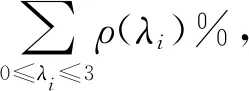

图1 演化的汉语网络的谱密度Fig.1 Spectral densities of the evolving Chinese co-occurrence networks
在字网络中,52.72(Net10)>41.16(Net30)>34.43(Net50)>32.84(Net100)>31.98(Net150)>26.03(Net200);在词网络中,74.86(Net10)>71.98(Net30)>68.76(Net50)>64.20(Net100)>61.68(Net150)>41.98(Net200).显然,随着网络规模的增加,[0,3]上ρ(λ)的和逐渐减小.
ER随机图[26]、WS小世界网络[27]和BA无标度网络[28]的邻接矩阵和Laplacian矩阵的谱密度之间有何异同?ER图的两个谱密度都趋于Wigner半圆形分布[8,29].对于WS网络,随着p的增加(p为边相连的概率),邻接矩阵的ρ(λ)趋于半圆形分布[8],而Laplacian的峰值却接近于平均度[29].在BA网络中,邻接矩阵的ρ(λ)关于0对称且呈三角形分布[8,29-30];Havel-Hakimi无标度网络的Laplacian谱的最大值偏向于较小的特征值[29].显然,我们网络的ρ(λ)与无标度网络是相似的.BA网络是增长和优先连接共同作用的结果[28].演化的汉语网络中也存在增长和优先连接,且度较大的节点为“的”“了”和“是”.这可能是汉语网络与BA网络的ρ(λ)相类似的主要原因.
研究发现,汉语字(词)网络的邻接矩阵的ρ(λ)呈三角形(“M”-型)分布[15];如果网络规模足够大,那么单个网络的ρ(λ)的最大值出现在λ=0处,在λ=±1处有两个小的高峰,并且在λ=0的两侧几乎是对称的[15].显然,Laplacian矩阵和邻接矩阵的ρ(λ)是不同的,产生这些差异的原因是什么呢?学者Chung等指出,不同的矩阵可以产生不同的特征谱分布图[19].Laplacian矩阵的特征值是正的,但是邻接矩阵的有正有负,这可能是造成差异的原因之一.为了便于比较邻接谱和Laplacian谱的异同,在表2中对这些异同进行了归纳.
2.2 谱排序
字、词网络的所有特征值的范围分别为:
0~396.01(Net10),0~936.01(Net30),0~1447.00(Net50),0~1770.00(Net100),0~1919.00(Net150),0~2675.00(Net200);
0~511.01(Net10),0~1590.00(Net30),0~3069.00(Net50),0~4522.00(Net100),0~5355.00(Net150),0~9701.00(Net200).
显然,最小特征值为0,最大特征值λ1随着网络规模的增加而变大.另外,字网络的λ1的值小于相应的词网络的值.
为了更好地研究Laplacian谱的特性,将每个网络的所有特征值进行了降序排列,并利用Matlab绘制了λi与i的关系(见图2),其中特征值λi按降序排列;左侧小图是双对数坐标下非常大的特征值的排序图,右图是半对数坐标下较大特征值的排序图;最后四个图是半对数坐标下中间部分特征值的排序图.
大的特征值是如何分布的呢?研究发现非常大的特征值和其它较大的特征值的分布完全不同.因此,在图2的每个大图中截取了具有明显变化的部分,并制作了两个小图(见图2的插图),其中左边是前9或11大特征值(不包括λ1)在双对数坐标下的排序图,而右边是从第11或13至100的特征值(一般随着网络规模的增加,选取的特征值的数量也会增加)在半对数坐标下的排序图.图2表明,前9或11大特征值的分布可以用双对数坐标下的一条直线来拟合(见图2的左侧插图),即
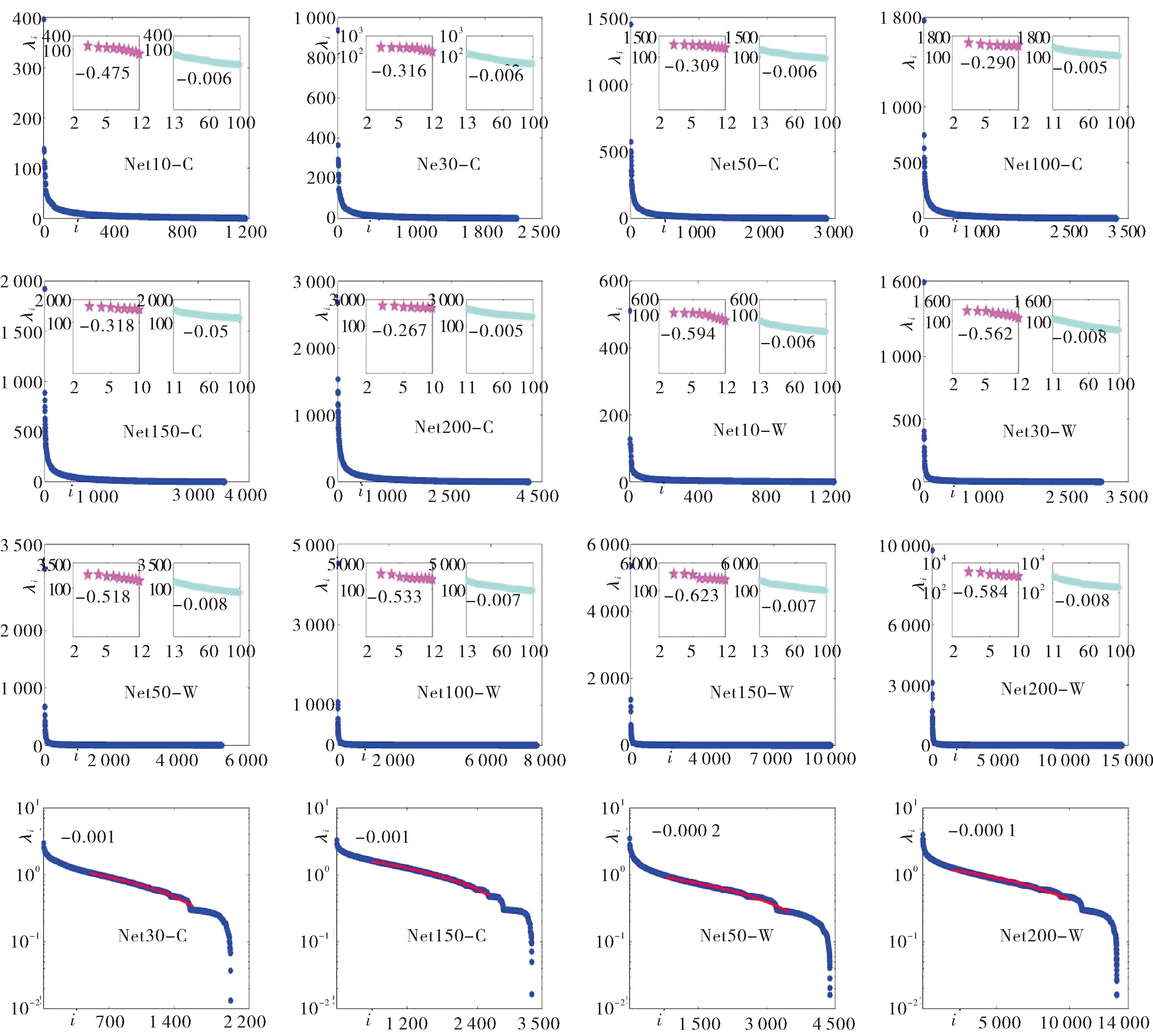
图2 网络的谱排序图 Fig.2 Spectral ordering graph of the network
λi∝i-α,i=2,…,10或12,
其中,α>0,并且斜率-α的值有如下排序.
字网络:
-0.27(Net200)>-0.29(Net100)>-0.31 (Net50)>-0.32(Net30,Net150)>-0.48 (Net10);
词网络:
-0.52(Net50)>-0.53(Net100)>-0.56(Net30)>-0.58(Net200)>-0.59(Net10)>-0.62(Net150).
显然,随着网络规模的增加,字网络的斜率一般也会随之增大,但是词网络并没有显示出单一的增长或下降趋势.对于从第11或13到100的特征值,它们在半对数坐标中呈线性分布(见图2的右侧插图),即
λi∝e-β i, 11≤i≤100,
其中β>0.此外,字、词网络的斜率-β分别有如下排序:
-0.005(Net200,Net150,Net100)>-0.006 (Net50,Net30,Net10);
-0.006(Net10)>-0.007(Net100,Net150)>-0.008(Net50,Net30,Net200).
显然,在字网络中,当网络规模增加时,斜率一般会变大,但是在词网络中,这种趋势并不明显.
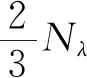
其中γ>0.在字网络中,γ=0.001,但是在词网络中,其斜率-γ的排序如下:
-0.0001(Net200,Net150)>-0.0002 (Net100,Net50)>-0.0004 (Net30)>-0.0009 (Net10).
显然,在词网络中,随着网络规模的增加,斜率一般也会随之变大.
在演化的汉语网络中,邻接谱和Laplacian谱的排序之间有何异同呢?对于邻接谱而言,前150个特征值的分布满足λi∝-clogi(c>0),c的值会随着网络规模的增加而变大;然而中间部分的谱排序却满足λi∝-0.01i[15].显然,邻接谱和Laplacian谱的排序分布是不同的(见表2).但是,在字网络中,当网络规模增加时,邻接谱和Laplacian谱排序的斜率一般都会增大.

表2 演化的汉语网络(Net10,Net30,Net50,Net100,Net150,Net200)的邻接谱和Laplacian谱的异同Tab.2 Summary of the adjacency and the Laplacian spectra of the evolving Chinese networks (Net10, Net30,Net50,Net100,Net150,Net200)
2.3 度与特征向量
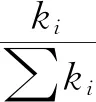
由图3可知,度和V1的变化趋势不明显,而邻接矩阵的最大特征值对应的特征向量分量的最大值位于度最大的节点处[13].度和V2的变化趋势一般是相反的.度和V3之间的变化趋势在不同的网络中是不同的.当N很小时,度和V3的变化趋势不明显,但是当N足够大时,它们的变化趋势在字网络中是一致的,而在词网络中却相反.
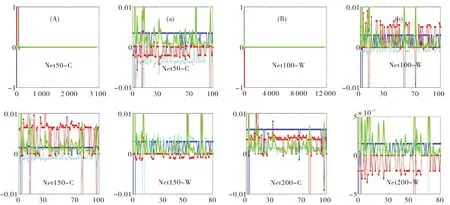
图3 度(绿色,-)和三大特征向量V1(蓝色,×),V2(青蓝色,+)和V3(红色,*)的关系图Fig.3 Plots of the normalized degrees and the top three eigenvectors V1 (blue,×),V2 (cyan-blue,+)and V3 (red,*),respectively
3 总结
通过分析演化的汉语网络的Laplacian谱,发现了网络的一些统计特征,为进一步了解汉语的特性提供了一些有用的见解.显然,仍然有许多问题需要探索.例如,得到的有关汉语的结论是否也适用于其它语言?如何建立一个合理的网络模型来刻画语言的演化?解决这些问题还需要后续做大量的研究.
