文档级无触发词事件抽取联合模型
2021-12-13李瑞轩李玉华辜希武
王 雷,李瑞轩,李玉华,辜希武,杨 琪
华中科技大学 计算机科学与技术学院,武汉 430074
网络空间里每天都会产生大量的文本信息。这些信息的增量发展在给人类带来便利的同时,也让人类完全消化理解它们变得困难。对此,相关学者针对事件抽取任务展开了广泛研究。
作为事件抽取领域最具影响力的测评会议,自动内容抽取(automatic content extraction,ACE,https://www.ldc.upenn.edu/collaborations/past-projects/ace)会议给出了计算机所要抽取的事件的定义:事件就是发生在某个时间、某个地点,由某些角色参与完成的某个动作或状态的改变。由此可以引申出,在任何一个领域,一个事件都可以用时间、地点、对象、动作等几个预先定义的结构化事件要素进行表示。如表1所示,一个由非结构化文本描述的股权质押事件,可以由右边的几个事件要素进行表示。

Table 1 Example of document-level event extraction表1 文档级事件抽取示例
通常,事件抽取中涉及到的专业名词包括:
实体(entity):具有特定语义的基本单元,如时间、人物、地点、数量、组织机构等。
事件触发词(event trigger):标志了某种类型事件发生的词汇。如表1 中的“质押”是股权质押事件的触发词。
事件类型(event type):所发生的事件的类别。
事件论元(event argument):参与事件发生的要素,由实体构成,在表1 中用斜体加下划线表示。
论元角色(argument role):事件论元在事件中扮演的角色,如表1 中的“质押人”“质权人”等,每种事件类型均预定义了多个不同的论元角色域。
1 事件抽取问题分析
作为自然语言处理中的一个重要方向,事件抽取研究的内容是如何从非结构化文本中抽取出用户感兴趣的事件,并将事件信息以结构化要素的形式表示出来。事件抽取不仅提高了人类从海量文本中获取有用信息的效率,并且其抽取出的结构化事件要素也便于计算机去理解和处理,进而为构建知识图谱、事件关联检索等高级人工智能应用提供便利。
尽管当前的事件抽取研究已经取得了巨大进展,但现有方法仍然存在两方面的不足:一方面,当前研究大多着眼于句子级事件抽取,即假设一个事件的全部论元均出现在单一句子之中。然而,事件表述的复杂性和灵活性决定了在现实场景下通常需要联系上下文的多个句子才能抽取到一条完整的事件信息。以表1 为例,S1和S2是一篇金融公告中的两个句子。从句子S1中可以检测到描述了一件股权质押事件,并抽取出质押人和质权人信息。但S1中的质押份额“38 348 000 股”是两次股权质押份额的总和,需要结合句子S2才能抽取出第一次股权质押的实际份额为“12 780 000 股”,开始日期为“2015 年12 月30 日”,结束日期为“2018 年1 月4 日”,最终得到一条完整的事件结构化信息。另一方面,由于事件抽取领域最广泛使用的ACE2005 数据集标记了事件触发词,当前研究大多通过触发词判断事件类型。但实际的无结构化文本中有时并未出现明显的触发词(如例1 描述的交通事故事件中没有出现任何事件触发词),并且依赖触发词的事件抽取将进一步加大事件抽取数据集的标注难度。
例1一辆长途客车在从巧家县开往鲁甸县的途中不慎侧翻坠入江中。
针对以上两个难点,本文提出一个文档级无触发词事件抽取联合模型(attention based document-level event extraction,ATTDEE),该模型包含联合训练优化的三个子模块:(1)实体识别模块。利用含有多头自注意力机制[1]的序列标注模型输出文档中所包含的实体及其类型。(2)事件类型检测模块。基于定义的论元角色对事件类型的重要度,在无触发词条件下定位提及事件发生的事件中心句,并判断事件类型。(3)事件论元抽取模块。利用实体类型信息和实体到事件中心句的距离信息,在文档范围内抽取事件论元,并判断论元角色。
本文的主要贡献包括:
(1)提出ATTDEE 模型,将事件抽取的粒度从句子级提升到文档级。实验结果证明了该模型在单事件条件下具有总体上最优的F1 值。
(2)实现了文档级无触发词事件抽取,既解决了触发词不存在时事件检测失败的问题,也减轻了数据集标注的难度。
(3)ATTDEE 是一个联合训练优化的完全由深度学习模块组成的端到端模型,避免了管道式方法的误差传递,也提升了模型的易用性。
2 相关研究
事件抽取在研究方法上经历了从基于模式匹配的方法,到基于特征提取工程的统计学习方法,再到基于深度学习方法的转变。早期基于模式匹配的方法,包括AutoSlog[2]、AutoSlog-TS[3]和GenPAM[4]等依靠事件模板的匹配实现了较好的事件抽取准确率。但这类方法的事件召回率低,领域迁移性差,且模板的生成往往依赖大量的人工操作,因而难以在通用事件领域取得更好的效果。基于特征提取工程的统计学习方法[5-7]则主要依赖自然语言处理中的文本分词、语义信息、词性标注、句法依存分析等工具,先抽取适当的文本特征,再结合最大熵模型、支持向量机等分类器实现事件抽取。这类方法不仅需要人工设计特征工程,且外部自然语言处理工具的依次使用往往会造成误差的传递。随着深度学习模型在多个人工智能领域展现了强大的自动特征表示能力,事件抽取研究进入了新的阶段。Chen 等[8]提出了一种动态多池化卷积神经网络,以捕捉更多文本信息。Yang 等[9]为每一种事件论元都定义一个单独的分类器,并通过整数动态规划解决了论元角色重叠的问题。Nguyen 等[10]和Sha 等[11]提出了触发词和论元的联合抽取模型。Chen 等[12]利用知识库和远监督[13]方法自动标注事件抽取数据集,并利用FrameNet(https://framenet.icsi.berkeley.edu/)标记事件触发词,以提升事件抽取效果。Zeng 等[14]提出利用关键论元判断事件类型,以减轻远监督方法中标注触发词的工作量。
当前事件抽取方法大多关注于句子级事件抽取。为了从文档范围内抽取完整的事件信息,Yang等[15]在句子级事件抽取的基础上提出一种启发式算法,在关键事件句附近补全缺失的论元。在此基础上,仲伟峰等[16]利用整数线性规划进行全局推理实现文档级事件抽取。但上述两种方法利用了事件触发词信息,且管道式方法增加了误差传递。Zheng 等[17]提出一种Doc2EDAG 模型,实现了无触发词的事件类型检测,并在论元抽取阶段将每种事件包含的全部论元角色按照既定顺序生成有向无环图进行依次识别,实现了文档级的多事件提取,但该模型在训练时需要消耗巨大的硬件算力资源。
3 ATTDEE 模型
ATTDEE 模型处理的是单事件条件下的文档级事件抽取。该模型假设当一篇文档中包含了一条事件信息时,总是存在一个提及事件发生且包含了最多关键论元的事件中心句,其他事件论元则有规律地分布在事件中心句附近。ATTDEE 模型包含实体识别、事件类型检测和事件论元抽取三个模块,其结构如图1所示。
3.1 文档输入表示
为避免分词工具带来的模型复杂度增加和误差引入,本文以汉字为单位输入模型。对于每一篇文档D,可以用句子序列S={s1;s2;…;sNs}表示,其中Ns表示最大句子数量。对每一个句子si又可以用汉字序列{ci,1,ci,2,…,ci,Nc}表示,其中Nc表示最大句子长度。对于第i个句子中的第j个汉字ci,j,其向量实际上由两部分拼接而成:(1)预训练的汉字向量,维度为dw;(2)该汉字在句中位置j的向量编码,维度为dp。为了使汉字能够在向量空间上充分体现语义信息,本文使用FastText[18]预训练的中文300 维词向量模型获得汉字的向量查找表。
3.2 实体识别模块
实体识别是一个常见的序列标注任务,通过标注BIO 标签的方式可以准确识别出实体的范围及其类型。相关学者对此提出了大量成熟且性能优良的方法。Zhang 等[19]针对中文在不同分词情况下会产生不同语义的特点提出了一种Lattice LSTM 网络。Zheng 等[17]在实体识别阶段使用了Transformer[1]模型。Yan 等[20]则指出,原始Transformer 模型使用的三角函数位置编码只能建模距离的远近关系,但无法建模位置是在左边还是右边,因而在实体识别任务中的效果并不比双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM)提升多少,反而显著增加了模型复杂度。该团队提出一种命名实体识别Transformer 编码器模型(transformer encoder for named entity recognition,TENER),通过修改位置编码和调整注意力权重提高实体识别效果。
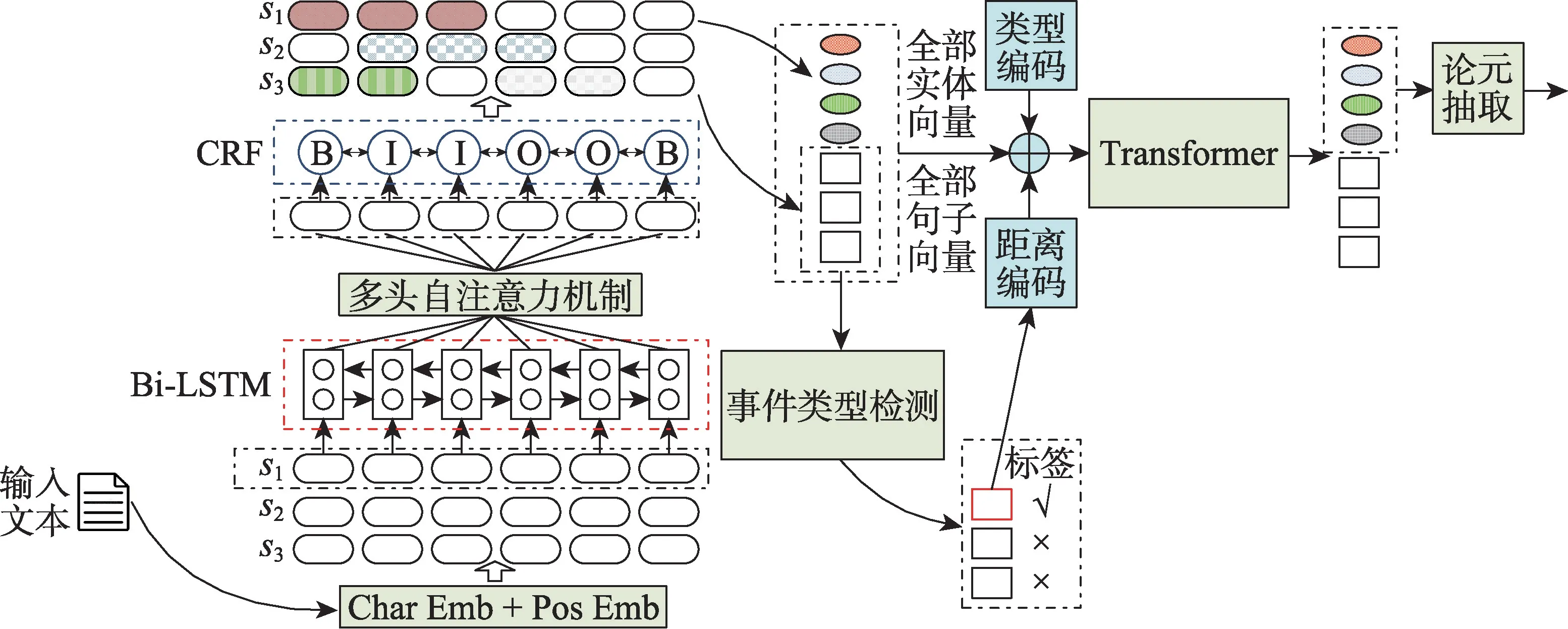
Fig.1 Structure of ATTDEE model图1 ATTDEE 模型结构图
然而,本文提出的ATTDEE 模型是一个联合学习模型,实体识别阶段的效果好并不等价于模型整体的效果好,还需要结合其他两个模块整体考虑模型复杂度和训练后的最终效果。特别的,在单一实体识别任务中,SOTA(state of the arts)模型总是希望强化实体内部的字符信息,而淡化实体以外的字符信息,因为实体以外的字符在实体识别模型评价时不起作用。但是在事件抽取任务中,实体以外的连接词文本对于检测事件类型、推断实体间关系和判断论元角色有着重要价值。因此在ATTDEE 模型的实体识别模块中,需要合理分配实体内和实体外的信息权重。
多头自注意力机制已被证明可以在多维空间上自动丰富向量所蕴含的文本信息。本文采用基于多头自注意力机制的Bi-LSTM 网络来依次建模每个句子的文本特征表示。将每一个句子si={ci,1,ci,2,…,}输入Bi-LSTM,并在每一个汉字处取正、反两个方向的隐层向量拼接作为多头自注意力机制的输入hi,t=。在每一个句子处,记Hi=[hi,1,hi,2,…,]。在单头自注意力机制中,模型随机初始化三个可训练的矩阵Wq、Wk、Wv来将Hi映射到不同的空间中。三个矩阵的向量维度为,其中,dk是一个超参数。
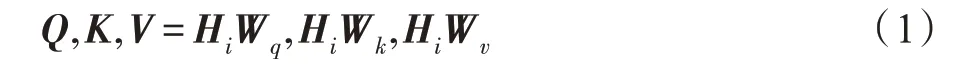
则自注意力计算结果为:
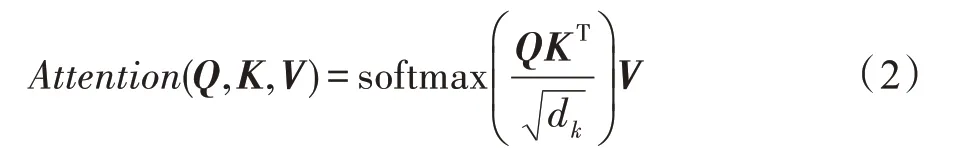
当使用几组不同的可训练矩阵Wq、Wk、Wv来加强自注意力的效果时,就构成了多头自注意力机制,其公式如下:

其中,n表示注意力头数,h表示注意力头的序号,[head(1) ;head(2);…;head(n)]表示向量在最后一个维度上的拼接,且dk=(dw+dp)/n。可训练矩阵。
最后,模型使用BIO 标签直接标记实体的范围和类型,并使用条件随机场(conditional random fields,CRF)建立多头自注意力机制的输出和BIO 标签的联系。在模型训练阶段,使用负对数似然计算实体识别模块的损失Lossner,在模型预测阶段,使用Viterbi算法求解最优标签序列。
3.3 事件类型检测模块
事件类型检测模块以文档中的每个句子为对象,寻找提及某个事件发生的事件中心句,并输出事件类型。记每一个句子si在多头自注意力机制后的输出为,则可得到句子的向量表示为:

记V表示训练集中所有事件类型的集合,对任一事件类型v∈V,ATTDEE 均定义了一个可训练的全连接层Wv,用来对句子向量G={g1;g2;…;}进行二分类(“1”表示“是”,“0”表示“否”),以判断句子si是否为事件类型v的表述中心句。二分类下句子触发事件类型v的概率为:

为了避免对触发词的使用,本文定义了论元角色对事件类型的重要度。论元重要度的定义基于数据挖掘领域中经典的TF-IDF(term frequency-inverse document frequency)思想,包含了论元角色频率(role frequency,RF)和反事件频率(inverse event frequency,IEF)两部分。记R表示训练集中所有论元角色域的集合。对于r∈R,则有:


对全部v∈V,可以利用事件的真实论元情况生成一个句子标签。当文档D不包含事件v时,labels,v全部由“0”构成;当文档D包含事件v时,labels,v在事件中心句的坐标处为“1”,其余地方为“0”。事件中心句为文档中权重最高的句子。句子权重则通过对句中实际包含的论元的重要度加权获得。
最终,事件类型检测模块的交叉熵损失函数为:

3.4 事件论元抽取模块
设实体识别模块得到的第l个实体覆盖了汉字区 间{ci,j,…,ci,k},对{mi,j,…,mi,k} 进 行MaxPooling 可以得到实体的向量表示。本文同样使用了Transformer 加强实体与文档间的信息交换,但在实现方式上与文献[17]有较大不同。在每一个实体向量后面,本文拼接一个dtype维的实体类型编码和一个ddist维的绝对距离编码,绝对距离的定义是实体所在句子序号和事件中心句序号的差值。最终,文档中全部实体的向量可以表示为,其中,Ne表示文档中实体的个数,且。对每一个句子向量gi,模型同样拼接一个dtype维的“0”编码表明这是句子向量,以及拼接一个ddist维度的当前句子到事件中心句的绝对距离编码,最终得到与实体向量维度对齐的全体句子向量。之后通过一个多层Transformer 网络,可以得到充分交换了文本信息后的实体向量Ed和句子向量Gd:
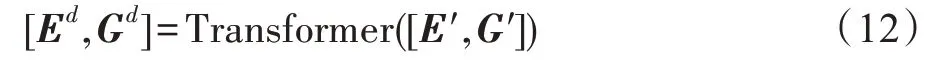
对每个事件类型v下的每个论元角色域r,模型均预定义一个可训练的全连接层Wv,r,对以所有实体Ed组成的候选论元进行二分类(“1”表示“抽取”,“0”表示“不抽取”),判断是否将候选论元抽取到当前论元角色域r中。在模型训练阶段,根据论元的真实标签,通过交叉熵损失计算事件论元抽取模块的损失为Lossarg,且为了平衡抽取每个论元时负例过多的影响,引入了一个正例补偿系数β。在模型预测阶段,当检测到某种事件类型发生时,则依次对该事件类型所包含的全部论元角色域从候选论元中进行抽取。若存在归一化抽取概率最高且概率超过50%的候选论元则抽取;否则,当前论元角色域为空。
3.5 模型训练优化
ATTDEE 模型的总损失如式(13)所示,其中λ1、λ2和λ3是超参数。之后通过选择优化器并设定合理的学习率训练模型,可以将模型整体优化,实现端到端的文档级事件抽取任务。

4 实验
4.1 数据
本文采用Zheng 等[17]公开的中文文档级金融事件数据集进行实验。该数据集包含五种类型的金融事件:股权冻结(equity freeze,EF)、股权回购(equity repurchase,ER)、股权减持(equity underweight)、股权增持(equity overweight,EO)和股权质押(equity pledge,EP)。每种事件类型均定义了多个不同的论元角色域。由于ATTDEE 模型处理的是单事件抽取任务,本文从原始数据集中抽取只包含单一事件的文档作为最终的数据集。数据集中的文档数量统计情况如表2 所示。

Table 2 Document statistics of dataset表2 数据集中的文档数量统计
本文在评价模型时将文档级事件抽取视为一个对事件中不同论元角色域的填空任务,并直接使用事件抽取模型得到的结果与真实事件情况比对进行效果评价,按照结果的最大化匹配原则计算准确率(precision,P)、召回率(recall,R)和F1值,其定义如下:

模型评价的最终结果取全部训练轮数中验证集F1 值最高的测试集结果。
4.2 实验设置
ATTDEE 模型的超参数设置如下:Ns为64,Nc为128,dw为300,dp为12,dtype为8,ddist为8,LSTM隐层维度156,注意力头数为8,Transformer层数为4,batch size为64,学习率为2E-4。由于实体识别模块的收敛更快,且事件类型检测、事件论元抽取两个模块对事件抽取总效果的影响更大,模型总损失中各模块的权重设置成λ1为0.15,λ2、λ3为0.85。dropout为0.1,β为3。模型采用Adam 优化器训练100 轮。
实验所采用的服务器硬件配置如表3 所示。

Table 3 Configuration of server表3 服务器硬件配置
4.3 实验结果与分析
本文采用相同的模型设置,与两种最新的文档级事件抽取模型进行对比实验。
DCFEE[15]:基于句子级事件抽取和启发式论元补全的文档级事件抽取模型。
Doc2EDAG[17]:将论元角色按照既定顺序编织为有向无环图来实现文档级事件抽取。
最终,事件抽取的结果如表4 所示,模型训练时间如表5 所示。可以看出,ATTDEE 在合理的训练时间下实现了最好的单事件抽取效果。

Table 4 Evaluation results of document-level event extraction表4 文档级事件抽取评价结果 %
同DCFEE 相比,本文模型没有简单地将论元数量最多的句子作为关键事件句,而是引入了论元的重要度。因为在观察数据集时,发现不同论元角色在事件中出现的频率不同,且同一论元角色可能同时定义在不同事件类型下,因此每种论元角色对不同事件类型的判定作用存在差别。论元角色重要度的应用显著降低了贫信息论元的影响,提高了模型准确率。在文档级论元补全阶段,DCFEE 基于管道的启发式方法将实体类型符合要求且距离关键事件句最近的实体直接作为论元抽取,其方法过于简单且无法消除实体识别阶段的误差传递,而ATTDEE的联合学习模型则将实体类型和实体到事件中心句的距离作为辅助信息供论元抽取模块使用,通过深度学习方法捕捉不同论元相对于事件中心句在方位和距离两个维度上的表述习惯,使得最终的F1值提高了19.9个百分点,而模型训练时间仅为DCFEE模型的1.6倍。
同Doc2EDAG 相比,ATTDEE 在进行实体和文档间的信息交换时,使用了额外的向量维度去表示实体类型和到事件中心句的距离,避免了信息混淆。模型通过“0”编码作为句子向量的类型编码,使句子向量的维度对齐实体向量,并指明矩阵中句子向量的范围,提升Transformer 交换文本信息的效果。在单事件的前提下,ATTDEE 基于事件中心句的抽取思想也更加简单有效,从而使准确率P提升了5.4 个百分点,F1 值提升了0.8 个百分点。同时,相较于Doc2EDAG 逐个论元角色依次建模抽取的链式过程,ATTDEE 可以方便地在多显卡条件下进行并行化计算,从而大幅缩短模型的训练时间。
5 结束语
本文提出了一个端到端的文档级无触发词事件抽取联合模型。模型由三个模块组成:基于多头自注意力机制的实体识别模块、基于论元重要度的事件类型检测模块和文档级事件论元抽取模块。通过对三个模块联合训练,避免了管道式方法的误差传递,也降低了模型使用的复杂度。另外,该模型不依赖任何事件触发词,既减轻了数据集标注的难度,也解决了实际场景下触发词可能不存在的问题。模型在公开数据集上取得了总体最优的F1 值。
然而,本文模型目前仅能处理一篇文档中只含有一个事件的情况。如何改进模型的特征学习方式,提升多事件抽取效果,是下一步的研究方向。
