图对抗防御研究进展
2021-12-13李鹏辉翟正利
李鹏辉,翟正利,冯 舒
青岛理工大学 信息与控制工程学院,山东 青岛 266525
在现实系统中,从基因序列到社交网络、从化学分子到通信网络都可以被抽象为图数据,因此对于图数据的研究一直受到广泛的关注。图神经网络(graph neural networks,GNN)[1-3]由于同时考虑了图中节点的属性信息和节点间的拓扑信息,对于描述图数据中节点间的关联性存在天然的优势,在节点分类[4]、链路预测[5]、社团探测[6]等领域表现出优于其他方法的效果,在实践中也得到了大规模的部署应用[7]。
尽管GNN 在图建模任务中表现出色,但与其他深度学习一样,易受到微小扰动的误导而致使模型的性能严重下降[8-9],仅通过添加或删除少量的节点或边就能够使模型产生完全错误的结果。具体而言,图对抗攻击是指通过在图中添加微小扰动(通常扰动量限制在一定的预算范围内)来降低模型性能。按照攻击算法在图中添加扰动的不同阶段,攻击算法可以分为“逃逸攻击”和“投毒攻击”两类,其中逃逸攻击指攻击者构造对抗样本在模型测试阶段欺骗目标模型,而投毒攻击指攻击者在模型训练阶段向训练集中注入对抗样本使得训练后的模型具有误导性;也可以根据攻击目标的不同将攻击算法分为“定向攻击”和“非定向攻击”,定向攻击的攻击目标是预先设定的,而非定向攻击只需要令攻击后的模型产生错误的预测结果。
经典图对抗攻击算法主要包括:Nettack[10]是对属性图进行攻击的算法,其利用图卷积网络(graph convolutional network,GCN)的梯度信息修改图数据,使得目标节点被错误分类为指定类别;metattack[11]利用元学习将图作为优化目标产生用于攻击的图数据;RL-S2V[12]将强化学习引入图对抗攻击,把攻击过程抽象为马尔可夫决策过程(Markov decision process,MDP);Q-Attack[13]是一种利用遗传算法攻击链路预测模型的攻击方法。以上攻击算法已经成为多数防御算法评估防御性能的基准,图对抗攻击引发的安全性担忧阻碍了GNN 在更广泛领域的应用。
虽然深度学习模型的高精确性和高效性近年来在各个领域都发挥出令人瞩目的表现,但为了使GNN 模型在遭受对抗攻击的情况下,仍然能够得到正确的结果,增强模型的鲁棒性已经成为深度学习充分发挥潜力的另一个关键点,因此对于图对抗防御算法的研究亟待更多的关注。
深入研究图对抗防御理论,设计出行之有效的防御策略,不仅可以增强GNN 模型在受到攻击时的鲁棒性,同时对于提高模型的可解释性和泛化能力也有着重要的推动作用。本文介绍了图对抗防御的基本概念及研究进展,根据防御算法的不同防御策略将其分为攻击检测、对抗训练、可认证鲁棒性和免疫防御四类,并系统地介绍和对比了不同算法采用的防御方法、目标任务及其优缺点等;最后对防御模型进行总结,探讨图对抗防御面临的挑战并对未来的研究方向进行展望。
1 定义与符号
图是一种关系型数据结构,本文使用G=(V,E)表示包含节点集合V={v1,v2,…,vN}和边集合E={e1,e2,…,eM}的图,其中N和M分别表示图中节点和边的数量;图中节点间的连接使用邻接矩阵A∈RN×N表示,当节点vi和vj之间存在边的连接时Aij=1,否则Aij=0;使用特征矩阵X∈RN×d表示图中节点的特征或属性,如果将其表示为向量形式X=[X1,X2,…,XN],则其中每个元素Xi∈Rd表示节点vi的d维特征向量。
在图对抗学习领域,通常将未被攻击的图数据称为原始图,而采用某种攻击算法后被成功攻击的图称为对抗样本或扰动图G′。攻击算法添加或删除的边称为扰动边,修改图中的边等价于改变了图的邻接矩阵,扰动图的邻接矩阵表示为A′,改变邻接矩阵的攻击算法也称为拓扑攻击;而如果攻击算法修改了图的特征矩阵,则扰动图中的特征矩阵使用X′表示,改变特征矩阵的攻击算法也称为特征攻击,fθ表示参数为θ的GNN 模型,本文常用符号及其含义在表1 中列出。
随着图对抗攻击引发的担忧,提高GNN 的鲁棒性显得愈加重要,图对抗防御工作已经开始得到关注和研究,纵观现有图对抗防御相关文献,可以总结定义图对抗防御如下:

Table 1 Symbols and descriptions表1 符号及含义
图对抗防御是指通过一定的策略,使GNN 模型即使受到对抗攻击,依旧能够得到正确的输出结果,从而保证模型鲁棒性:
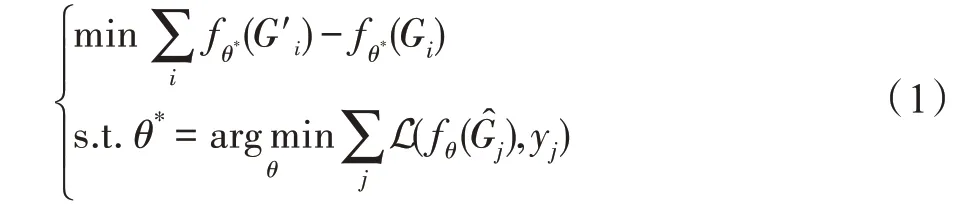
其中,fθ*表示具有防御策略的模型,表示GNN 的输入可以是扰动图也可以是原始图。
2 图对抗防御算法
当前,图对抗攻击算法可以分为逃逸攻击和投毒攻击[10],已经研究出多种防御算法用于提高GNN模型的鲁棒性。针对逃逸攻击,增强GNN 鲁棒性的方法主要包括攻击检测和对抗训练,其中攻击检测通过检测并消除图数据中的恶意节点和边,从而恢复近似原始图的数据来提高GNN 模型的鲁棒性[14-20];对抗训练则是通过在训练数据集中添加扰动样本进行训练以增强模型的泛化能力[21-23];除此之外,也有部分算法从其他角度出发,通过验证GNN 或节点的鲁棒性来了解图数据的攻击容忍度,此类算法称为可认证鲁棒性[24-26],但是这类方法并没有直接提高GNN 的鲁棒性。
而针对投毒攻击,目前多数防御算法采用修改模型的策略,具体而言包括在模型中添加注意力机制惩罚扰动节点和边的权重以区分恶意边和节点与正常边和节点[27-28],修改模型架构以获取更强的鲁棒性[29-31],修改图卷积算子取代GNN 模型中的经典拉普拉斯算子[32]等;也有部分算法利用净化数据的策略提高模型性能[33],由于投毒攻击将扰动样本添加到训练数据中,净化数据方法首先修改训练数据消除训练数据集中对抗样本的影响,然后在净化后的数据集上训练GNN 模型。这几种策略由于可以防御针对模型训练阶段的攻击,统称为免疫防御。
综上,根据现有模型采用的不同防御策略,将图对抗防御分为算法攻击检测、对抗训练、可认证鲁棒性和免疫防御四类,如图1 所示。
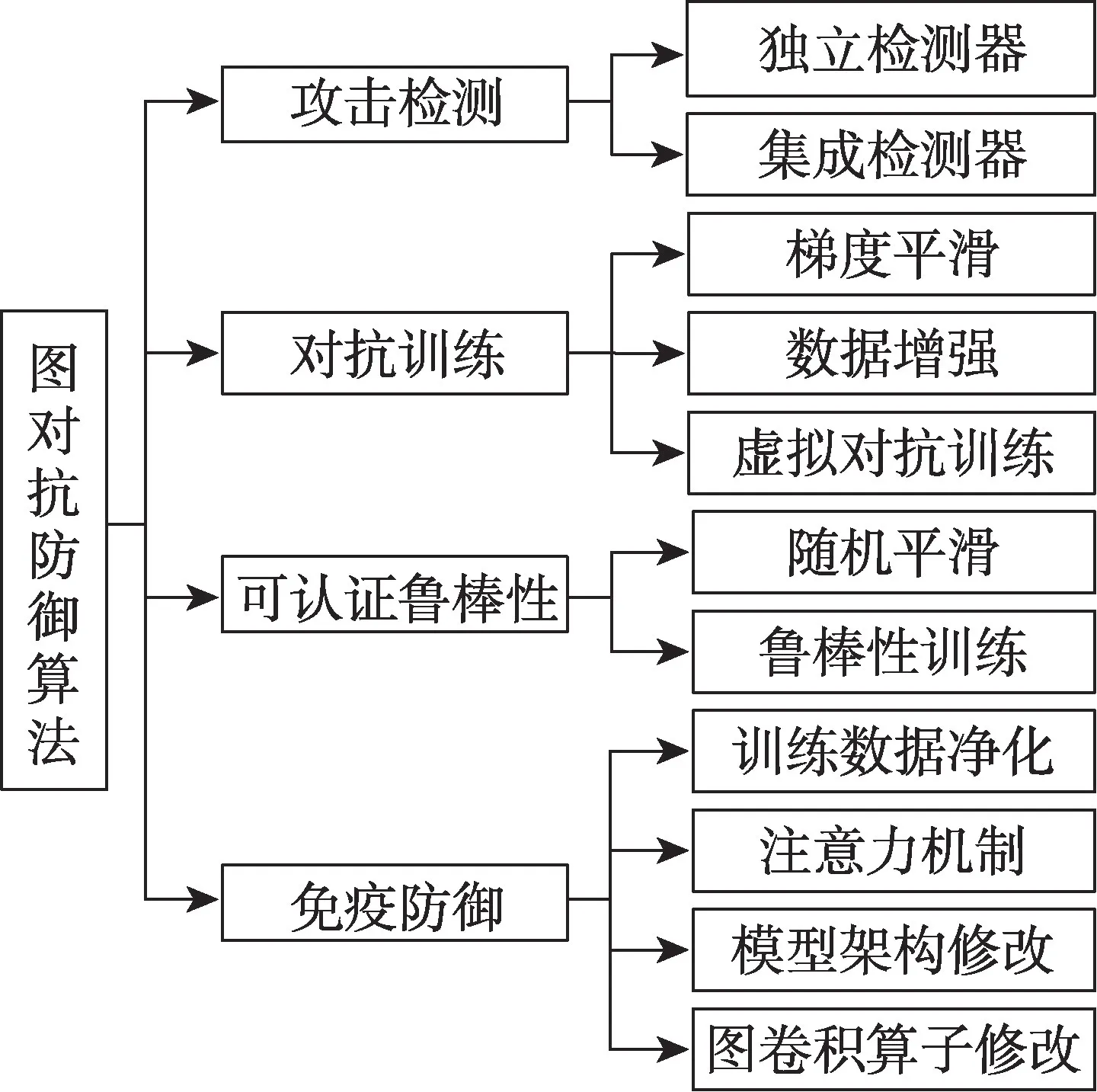
Fig.1 Classification of graph adversarial defense algorithms图1 图对抗防御算法分类
2.1 攻击检测
攻击检测通过在模型中添加独立检测器[14-17]或集成检测器[18-20]来检测输入的测试图中是否含有对抗性扰动。攻击检测方法的比较如表2 所示。
Zhang 等[17]深入研究了随机攻击与Nettack 对图深度学习模型的影响,提出针对Nettack 攻击的检测器。GraphSAC[19]是一种通过随机子图抽样和共识机制来检测大规模图中异常节点的算法,通过限制随机抽样的次数来保证算法的高效性。
攻击检测可以针对不同应用特点,对检测策略进行特定设计。Pezeshkpour 等[34]分析了应用于知识图谱链路预测模型的鲁棒性和可解释性,基于梯度算法识别知识图谱中改变目标预测的“扰动事实”,同时为了提高算法的效率,构造解码器还原知识图谱嵌入的拓扑信息和特征信息。为了检测系统中注入的恶意软件,Hou 等[18]研究了针对恶意软件检测系统的对抗攻击的特征。在社交网络中,与检测长期存在的虚假用户[35]不同,SybilEdge[16]通过利用新用户与其他用户之间的交互来检测其是否为虚假用户。
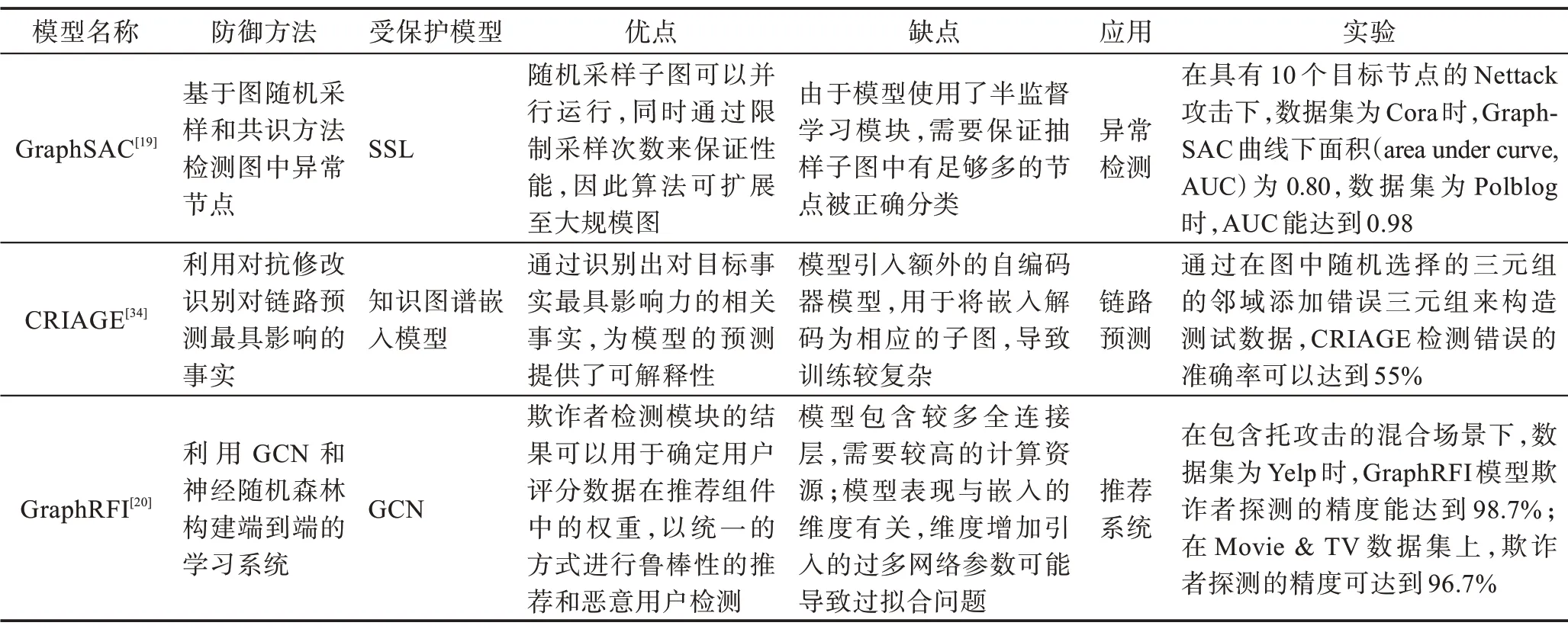
Table 2 Comparison of attack detection methods表2 攻击检测方法比较
而在推荐系统中,为了防御潜在对抗攻击的威胁,Fang等[14]设计了基于用户行为进行检测的二元分类器来阻止虚假用户的干扰;Zhang 等提出的GraphRFI[20]是由GCN 和神经随机森林组成的端到端系统,其中GCN 模块利用用户信息和评价信息来捕获用户的爱好信息,随机森林模块用于检测恶意用户。
2.2 对抗训练
对抗训练本质上是一种对模型进行正则化的方法,通过将动态生成的对抗样本添加到训练集中,使训练后的模型具有更强大的鲁棒性和泛化能力,优化目标可以表述为:

其中,Φε表示扰动空间,可以将上述min-max问题表述为最小化含有最佳扰动效果的对抗样本的预测损失。
Feng 等[21]通过实验证明了对抗训练本质上是降低了连接节点间的差异。与全局正则化的对抗训练方法[36]不同,Dai 等[37]采用局部正则化来提高图嵌入模型的泛化能力,同时还通过限制嵌入的扰动方向来提供可解释性;文献[26,38-40]从多个角度研究了拓扑攻击,并提出了在输入层注入扰动进行对抗训练的其他几种变体。
与添加离散空间扰动[12,39-40]进行对抗训练不同,Wang 等[22]提出通过添加连续空间的扰动来获得对抗样本用于对抗训练,并且证明了扰动特征矩阵和扰动邻接矩阵进行对抗训练的效果是等价的;LATGCN(latent adversarial training GCN)[23]通过对模型第一隐藏层的输出添加连续扰动进行对抗训练:

其中,H1表示模型第一隐藏层的输出,δ∈D表示扰动是在连续空间进行的,可以同时进行特征扰动和结构扰动。图2显示了对抗训练中注入扰动的不同方式。

Fig.2 Different methods of injecting perturbations in adversarial training图2 对抗训练中注入扰动的不同方式
Sun 等[41]和Feng 等[21]将虚拟对抗训练引入GCN中用于半监督节点分类,提高GNN 分类器的平滑度,从而增强模型的泛化性能。Deng 等[42]认为直接将虚拟对抗训练用于图数据,会导致对某一节点产生的全局扰动并非最坏情况下的虚拟对抗扰动,降低虚拟对抗训练的效果。为了解决这一问题,提出了批虚拟对抗训练(batch virtual adversarial training,BVAT),其利用随机采样彼此距离较远的节点子集或设计更有效的优化算法获得虚拟对抗扰动,从而平滑分类器模型的输出。对抗训练防御算法的比较如表3所示。
在链路预测问题中,Zhou 等[43]将攻击与防御问题建模为Bayesian Stackelberg 博弈,其中防御者选择要保证预测准确性的目标链路集,攻击者则删除图中边集合的子集;Minervini等[44]将训练目标定义为零和博弈问题,其中链路预测模型目标为最小化包含对抗样本数据集上的预测损失和不一致性损失,而攻击者则通过改变输入集最大化不一致性损失。
2.3 可认证鲁棒性
可认证鲁棒性并不针对特定攻击方法,而是对不同学习模型计算输入图数据最坏情况下的攻击容忍度。
在计算机视觉领域,可认证鲁棒性已经得到了深入的研究[45],Zügner 等[24]首次在图数据建模中进行了可认证鲁棒性的数学验证。节点上的可认证鲁棒性表示在所有允许的攻击下模型关于节点t的预测都不会改变,具体而讲,其目标是为节点t提供一个鲁棒性证书,该证书可以确保在任何允许的扰动下模型对于该节点的预测都是可靠的。为了实现这一目标,需要验证是否存在可以改变目标节点t的允许扰动X′,假定节点t的类别为y*,最坏情况裕度定义为:
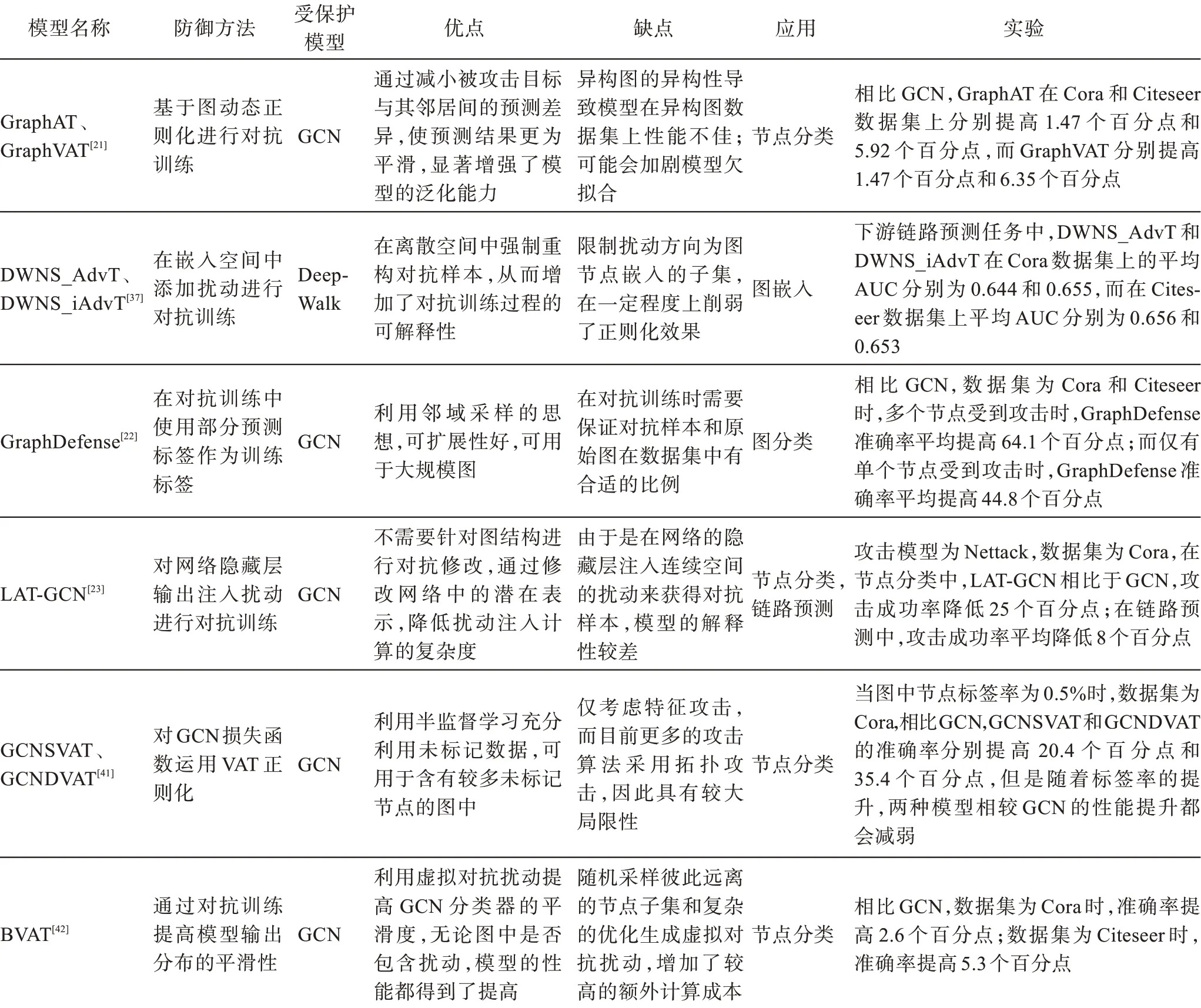
Table 3 Comparison of adversarial training methods表3 对抗训练方法比较

其中,X 表示所有允许的节点特征扰动集合,当对于任何y≠y*,都有ht(y*,y)>0,则此模型fθ关于节点t和X 具有可认证鲁棒性。换句话说,在定义的扰动内,不存在改变模型预测类别的对抗样本。
与针对节点特征扰动提供鲁棒性证书[24-25]不同,Bojchevski等[26]对拓扑攻击下的可认证鲁棒性进行了研究,同时扰动需要满足全局和局部预算,全局预算限制扰动边的总数量,局部预算限制单个节点上的扰动边的数量,最坏情况裕度可以通过简单修改式得到,将寻找最坏情况下的对抗样本过程建模为MDP,其中图中每个节点对应一个状态,动作定义为选择包含容易被成功攻击的边的集合,奖励函数设计为:

Bojchevski 等[46]同时考虑了拓扑攻击和特征攻击,提出了基于随机平滑的离散数据稀疏性感知认证,并且鲁棒性证书的计算复杂度与输入图数据的大小无关,从而提高了可认证鲁棒性防御方法的可扩展性。除了GNN 的节点分类任务外,Jia 等[47]提出了针对社团探测任务的可认证鲁棒性算法以防御拓扑攻击。可认证鲁棒性防御算法的比较如表4 所示。
2.4 免疫防御
以上三类防御策略都是针对逃逸攻击设计的,而免疫防御是一类防御投毒攻击的策略,通过删除训练图中的扰动、修改模型结构或添加注意力机制等达到防御目的。免疫防御算法的比较如表5 所示。
Wu 等[48]基于观察到攻击的特征:(1)修改边的有效性高于修改特征,且增加边的攻击性高于删除边;(2)度越高的节点攻击难度越大;(3)攻击倾向于在目标节点和具有不同特征和标签的节点间构建连接。提出在训练前删除图中相似度较低的节点间的边,在有效提高GCN 鲁棒性的同时几乎不会增加模型的训练时间。
针对Nettack 攻击模型,Entezari 等[49]研究了其攻击特性,表明Nettack 生成的不易察觉的扰动会改变邻接矩阵的小奇异值,因此通过奇异值分解得到邻接矩阵和特征矩阵的低秩近似用于训练GCN;Miller等[50]提出了修改分类器和改变训练集两种方法防御Nettack 攻击。Jin 等[33]通过研究Nettack 和Metattack攻击,发现攻击破坏了原始图的低秩、稀疏性和特征平滑度,因此提出Pro-GNN 同时学习原始图拓扑结构和鲁棒性的GNN 模型,其模型架构如图3 所示。
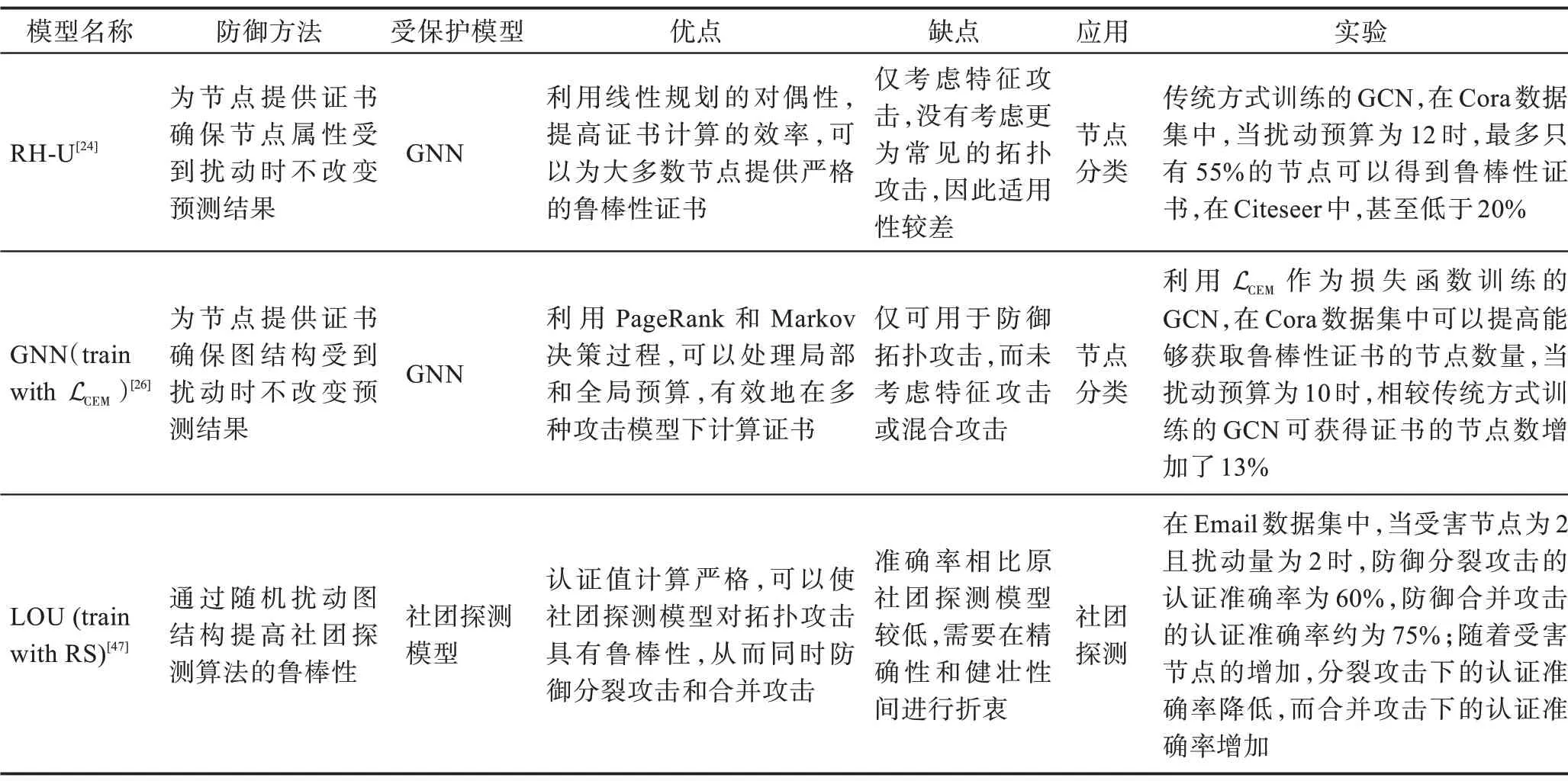
Table 4 Comparison of robustness certification methods表4 可认证鲁棒性方法比较
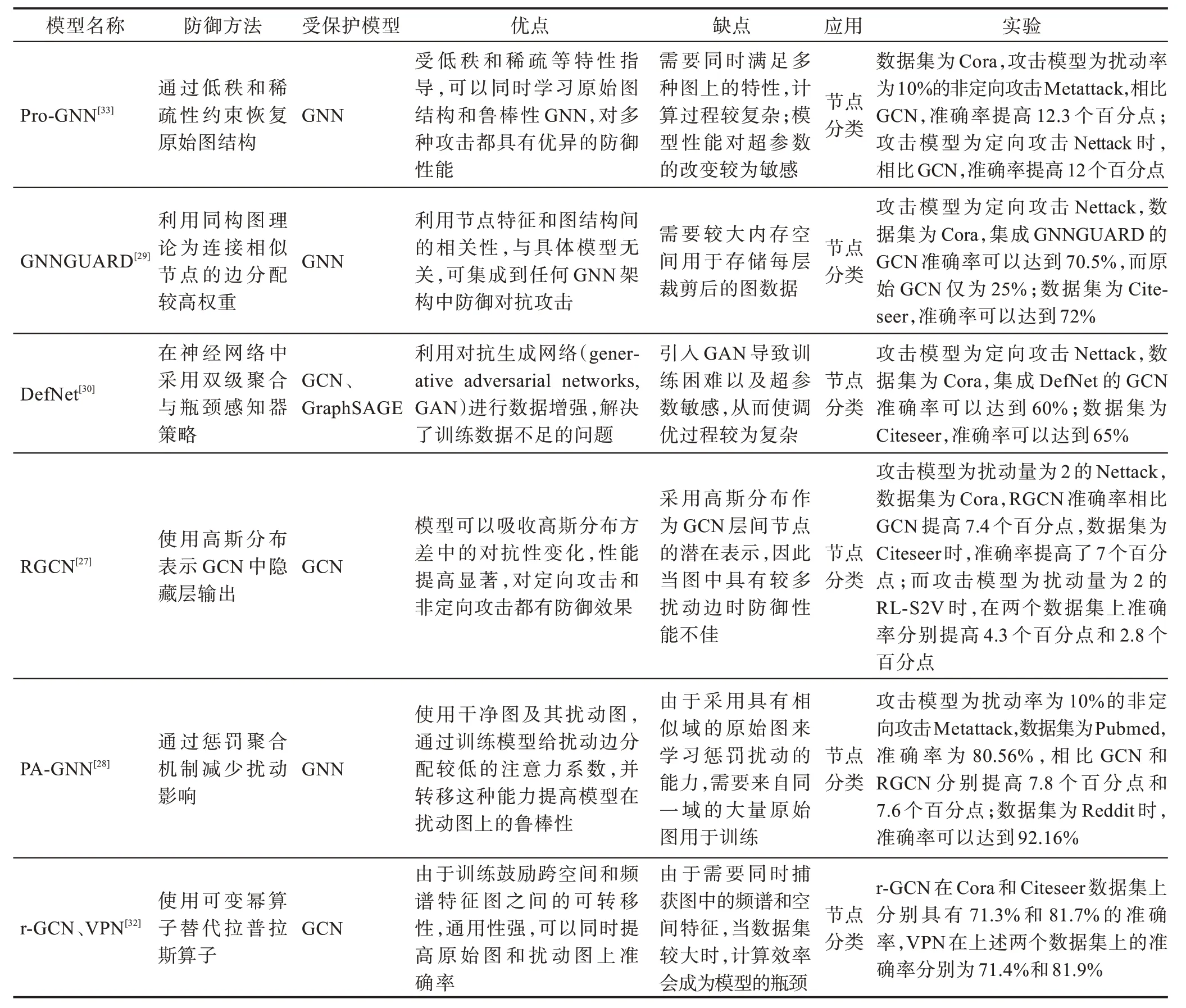
Table 5 Comparison of immunologic defense methods表5 免疫防御方法比较
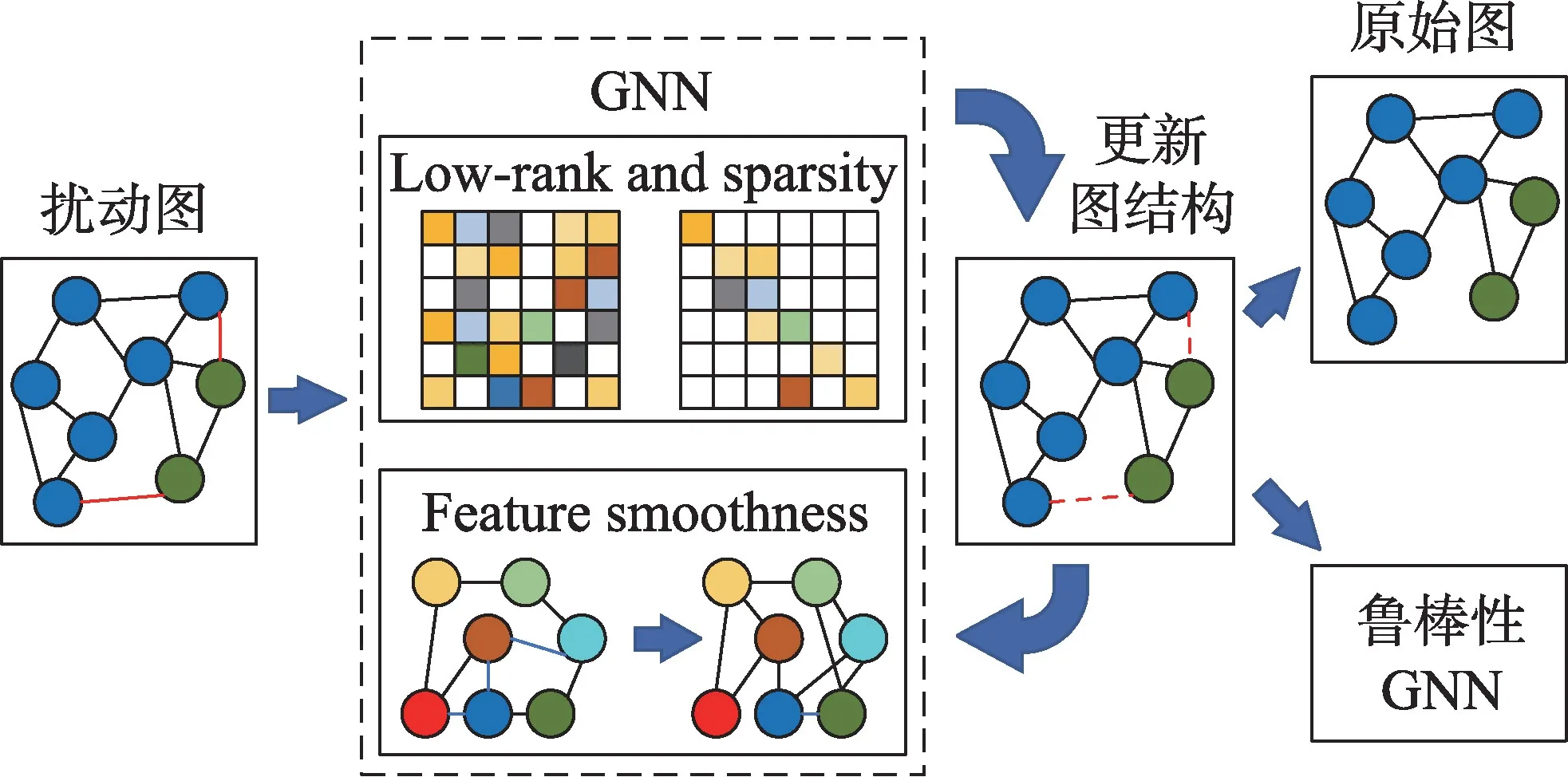
Fig.3 Framework of Pro-GNN图3 Pro-GNN 架构
PTDNet[51]通过参数化网络过滤掉与任务无关的边,限制了输入图中边的数量,同时应用正则化方法对得到的稀疏图施加低秩约束,避免扰动在GNN 中的聚集与传递。
GNNGUARD[29]通过修改图神经网络的消息传递结构使模型能够防御对抗攻击,利用重要性估计动态调整节点局部邻域的相关性,对于可能的扰动边,将其丢弃或分配较低的权重,利用分层图存储器保存图神经网络每层的前一层网络信息。DefNet[30]利用双层聚合和瓶颈感知器来解决GNN 中聚合层和感知层的漏洞,其中双层聚合借鉴了DenseNet[31]架构聚合来自不同阶的邻居信息,瓶颈感知器利用神经网络模型的脆弱性随着输入数据维度的增加而增加这一事实将输入数据映射到低维空间,同时为了防止在训练集中生成无效的对抗样本导致模型受攻击时鲁棒性被削弱,利用条件GAN 进行对比学习解决训练数据集较少的问题,DefNet 的架构如图4。文献[52-53]对于GCN 聚合层中存在的漏洞进行了深入研究,并提出了不同的聚合函数,用来解决现有GCN 使用求和函数作为聚合函数容易被恶意构造的单个异常值扰乱消息传递的问题。
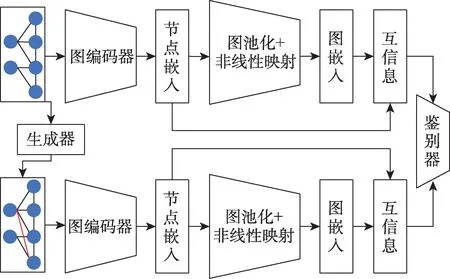
Fig.4 Framework of DefNet图4 DefNet架构
RGCN(robust graph convolutional networks)[27]是用于增强GCN 鲁棒性的模型,由于受攻击节点在传播其影响时通常其方差较大而权重较小,将隐藏层中的输出表示为高斯分布会吸收扰动图中高斯分布方差的变化:


其中,γ是超参数,表示第l层中节点vi的注意力权重,根据卷积运算中节点邻域的方差为节点邻域分配不同的权重。
PA-GNN(penalized aggregation GNN)[28]首先利用Metattack[11]在图中注入扰动边,然后使用获得的扰动图训练具有惩罚性聚合机制的模型,惩罚性聚合机制通过分配低注意力系数限制扰动边对模型的影响。通过元学习将这种惩罚机制转移到目标扰动图,构造M个初始状态不同的模型,通过目标函数进行元优化:
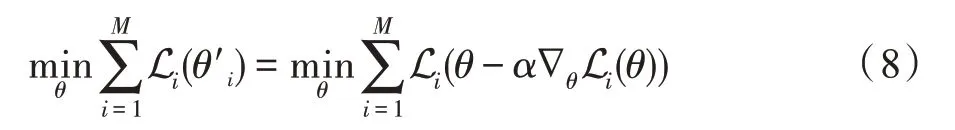
其中,α表示学习率,通过随机梯度下降更新模型参数θ,经过元优化,PA-GNN 成功地利用对抗样本进行训练来惩罚扰动,并可以转移惩罚目标图数据中的不同扰动,从而提高鲁棒性。
除了从架构上修改模型外,Jin 等[32]认为经典的图拉普拉斯算子能够聚合的邻域信息有限,因此提出了可变幂算子来增强GCN 的表达能力,r阶可变幂算子定义如下:

其中,A[k]表示k阶邻接矩阵,当且仅当原始图中节点vi和vi间的最短距离为k时=1,参数θk表示全局影响因子,当幂r>1 时可以在卷积操作中增加邻域信息聚合的范围。
针对链路预测问题中存在的隐私泄露问题,Yu等[54]利用启发算法和遗传算法来保护目标隐私链接不被泄露,对于大规模图算法的效率不高;相反,Lim等[55]通过强化学习重建被恶意隐藏的链接。
3 存在的问题与发展方向
纵观现有图对抗防御算法,大部分算法是针对节点分类任务的防御,在链路级别和图级别任务上的对抗防御研究仍寥寥无几,缺乏在动态图和异构图上防御机制的研究,且只有少数算法考虑大规模图上的扩展性[20,26]。
与针对特定攻击算法进行防御的研究[17,50]相比,独立于特定攻击算法设计的防御模型[32,37,40,43]具有更加广泛的适用性。多数防御算法,当测试图数据未被攻击时,模型的性能反而不如原始模型,即以牺牲模型性能的方式换取鲁棒性,只有少数算法考虑了此缺陷[26,30,32,42],因此亟待设计更多不会将降低模型性能作为提高鲁棒性的代价的算法,同时提高在原始图和扰动图上的模型性能。已经有研究考虑理论上对模型的鲁棒性进行证明[24-25,32,56],但是鲁棒性认证只是节点鲁棒性的评估方法,下一步应当研究提高GNN 可认证鲁棒性[57];或者提出多角度评估标准度量模型的鲁棒性[58];但是大多数防御算法仍然是通过基于原始模型的修改达到防御效果,这种修改缺乏可解释性,同时容易被攻击者设计新的针对性攻击。除了在安全性方面,防御算法也应当关注数据的隐私保护问题[54,59]。
总体而言,防御算法在多样性任务、可扩展性、隐私保护等方面仍存在诸多限制,针对目前图对抗防御存在的问题和挑战,需要在以下方向进行重点研究和突破:
(1)理论研究:尽管GNN 已经得到了广泛的应用,但是对于图滤波器的稳定性分析仍然缺乏关注,这对于设计鲁棒的GNN 模型至关重要,虽然文献[56]弥补了这一空白,但其严格假设扰动不会改变节点的度,对于更加复杂的扰动下的图滤波器稳定性分析仍然有待研究;同时,GNN 容易受到对抗攻击的原因仍没有得到全面的分析,文献[52-53,60]指出非鲁棒性的聚合函数导致GCN 在面对拓扑攻击时的脆弱性,而更加复杂攻击背后的原理有待深入挖掘;最后,当前大多数图对抗防御算法仅利用实验来说明其有效性,或者通过总结图对抗攻击算法的缺陷设计防御模型,而从理论上证明防御算法的有效性仍缺乏深入的研究,若可以从理论上阐述防御算法有效性的依据[32],将极大地推动防御算法在更广泛的图分析、学习模型中得到应用。
(2)可扩展性:防御算法的可扩展性包含三方面,首先是在动态图和大规模图上的扩展性,由于现实世界的图通常具有较大规模且会随时间不断扩大,因此降低算法的时空复杂度以提高其可扩展性是图对抗防御的发展趋势;然后是在不同攻击算法中的可扩展性,针对特定攻击算法设计的防御由于具有更广泛的攻击假设,相较于与具体攻击算法无关的防御通常具有更高的适用性;最后是在不同任务中的可扩展性,目前防御算法集中于研究在节点分类任务中的应用,在链路预测、社团探测和推荐系统等方面的研究仍然较少,同时由于多数防御算法是针对不同应用设计的,开发可应用于多种任务中的防御算法应当是未来研究工作的重点。
(3)数据纯化:在现实世界的图数据中,除了可能受到对抗攻击导致图中拓扑结构与特征信息发生变化外,图数据中的信息也可能因噪声等原因存在标注错误或缺失的情况[61],随着GNN 对邻域信息的聚合,网络将逐渐适应这类异常的数据,导致性能和泛化能力较差,未来的研究可能通过图对比学习[62]等自监督学习模型来捕获图数据中对任务影响最主要的信息,移除冗余和异常信息,得到近似纯净的图数据用于下游任务。
(4)正则化:除了对抗训练外,其他正则化技术在防御算法中的应用也有待研究。在GNN 模型中施加正则化本质上是为了限制扰动在网络中的传播,可以通过惩罚梯度,或者强制约束权重范数与梯度范数来实施正则化;文献[63]指出对抗性攻击的存在源于模型对弱相关特征的利用,因此可以通过稀疏性减少弱相关特征的影响达到类似Dropout 正则化的效果。
(5)隐私保护:随着GNN 优异拟合能力的展现,其强大的邻域聚合能力也向希望获取节点敏感属性的使用者暴露了一些附加的危害,例如社交平台可以根据用户在社交网络中的显式内容进行推断,得到用户的隐式信息;或者攻击者也可以根据用户信息或者用户在网络中好友的信息获取目标用户的敏感信息[59]。在隐私保护日益重要的今天,帮助用户保护隐私是研究者应该持续关注的问题,在保持GNN 模型性能的同时保护用户的敏感信息免受恶意预测攻击。
(6)模型鲁棒性与泛化能力的权衡:当前的防御算法研究中,多数更注重实现模型的鲁棒性,而忽略了泛化的影响,针对目前多数算法以牺牲模型性能来提高其鲁棒性的问题,需要防御算法能够保证无论模型是否受到攻击其性能均能得到保持甚至提高,例如设计新的损失函数来训练神经网络,用以同时提高模型的鲁棒性和泛化能力,或者根据实际应用场景在两者之间取舍。
4 结束语
图对抗防御致力于解决图对抗攻击导致的模型性能下降问题,提高模型的鲁棒性和泛化能力,增强GNN 应用的安全性。本文首先介绍了图对抗防御的研究背景和目的,并通过对现有相关文献的归纳,总结出图对抗防御的统一表述;然后根据现有防御算法采用的不同类型的防御策略,对其进行分类,分别为攻击检测、对抗训练、可认证鲁棒性和免疫防御。然后全面、系统地总结了现有图对抗防御算法的核心思想和实现策略,对典型算法进行了比较分析。最后,从对抗防御算法的理论证明、可扩展性、数据纯化以及隐私保护等方面出发,分析了图对抗防御领域目前存在的问题以及未来可能的发展方向。
