唇语识别的视觉特征提取方法综述
2021-12-13马金林巩元文马自萍陈德光朱艳彬刘宇灏
马金林,巩元文,马自萍,陈德光,朱艳彬,刘宇灏
1.北方民族大学 计算机科学与工程学院,银川 750021
2.图像图形智能处理国家民委重点实验室,银川 750021
3.北方民族大学 数学与信息科学学院,银川 750021
唇语识别是通过分析一系列唇部运动信息来推断说话者所说内容,涉及模式识别、语音处理、图像分类和自然语言处理等多个领域[1],具有广阔的应用前景。早期的唇语识别系统采用人工标注特征作为唇部视觉特征,一系列图像序列作为模型输入,此类方法仅保证了下游任务能进行分类识别,而不考虑获取特征的有效性,因此下游任务识别精度通常较低。近年来,随着人类需求的增加,仅采用图像序列作为模型输入的唇语系统获取的视觉效果远不能达到人类的期望值,人们开始寻求有效的视觉特征。
唇语识别系统一般由视觉特征提取和分类识别两个阶段组成,唇部视觉特征提取的有效性是下游任务获取良好表现的关键。理想情况下,视觉特征应包含足够多对识别有效的信息量,并对视频中的噪声表现出一定程度的鲁棒性[2]。但头部姿势、光照条件、视频拍摄角度等因素对提取的视觉特征质量具有很大的影响。因此,多年来学者们一直致力于对高效唇部视觉特征的研究。本文将唇部视觉特征提取方法分为传统提取方法和深度学习提取方法两类,这两类视觉特征提取方法的架构如图1 所示。
如图1(a),传统的视觉特征提取方法主要依靠人工标注,存在易受外界环境影响,耗时长、效率与精度低的问题。采用几何特征[3]、纹理特征[4]和外观特征[5]作为视觉特征的方法可以有效解决上述问题。几何特征采用唇部的高度、宽度和面积等作为视觉特征;外观特征则采用口腔和牙齿的张合度作为特征;纹理特征采用尺度不变特征转换或者方向梯度直方图等算法提取图像视觉特征,是常用的一种特征。上述方法虽然在一定程度上保证提取特征的有效性,但是存在很大的局限性,不能应用于真实自然环境中,且分类识别准确度也比较低。

Fig.1 Visual feature extraction structure图1 视觉特征提取结构图
如图1(b),基于深度学习的唇部视觉特征提取方法是目前的主流方法,这类方法使用深度模型自动提取唇部的视觉特征,最常使用的模型结构是卷积神经网络(convolutional neural network,CNN)。根据网络维数的不同,基于深度学习的唇部视觉特征提取方法可分为:基于二维卷积网络(2D convolutional neural network,2D CNN)、基于三维卷积与二维卷积网络相结合(3D convolutional neural network and 2D convolutional neural network,3D CNN+2D CNN)的提取方法和基于三维卷积网络(3D convolutional neural network,3D CNN)。除卷积神经网络架构以外,还包含其他结构用于提取视觉特征,如自动编码机制、前馈神经网络和深度置信网络。深度学习的特征提取方法是目前效果最好的方法,它解决了传统方法不能自动提取特征的问题,在提取高效性特征、算法性能、效率和泛化能力等方面得到一致认可。
1 唇语数据集
唇语数据集是推动视觉语音识别和唇语识别发展的关键[6]。早期的数据集专注于特定和简单的识别任务,例如:基于字母或者数字识别、基于句子识别等。优点是这些数据集可以很快地被用于唇语识别领域,但是由于存在受试者数量和记录数量有限、与真实环境存在差异的问题,而很难广泛应用于真实环境。后期的数据集更侧重处理复杂任务,并同时考虑了各种影响因素(例如:光照、头部姿势、分辨率、视角等)。本文根据拍摄视角将这些数据集划分为正视图数据集和多视图数据集两类。
1.1 正视图数据集
目前常用的正视图数据集包括:AVLetters[7]、GRID[8]、OuluVS[9]和LRW[10]。除此之外,还包含数据集IBMIH[11]和MOBIO[12]等。
GRID 数据集是视听双模态数据集,常用于端到端句子级水平的研究,该数据集句子结构遵循一定的规律,由六类单词构成,分别为“命令”“颜色”“介词”“字母”“数字”和“副词”,每一类单词都有固定的数量。
AVLetters 数据集同样为视听双模态数据集,主要用于研究说话者变化对唇语识别任务的影响,由5名受试者分别朗读26 个字母7 遍录制完成,缺点是该数据集仅能用于特定任务的研究。
不同于GRID 数据集和AVLetters数据集,OuluVS数据集结构不遵循规律,广泛用于日常生活用语自动唇语系统的评估,数据来源于10 个日常生活用语,收集过程分为两部分:第一部分收集10 个人的数据,10 人均来自不同国家,语速和发音存在一定差异;另一部分收集剩余10 个人的数据,但该数据集在构建过程中未考虑到受试者男女比例问题。
为满足大规模数据集的需求,LRW 数据集于2016 年被提出,共分为500 类,数据来源于BBC 广播电视节目,该数据集主要用于英文单词的识别任务,满足了研究者对数据量的需求。
1.2 多视图数据集
在自然环境中,唇语识别的研究并不能保证输入的图像总是正视图。实际环境中唇语识别系统需要解决多视图问题。此外,研究表明,使用非正视图在一定程度上能提高唇语识别性能[13],这是因为非正视图能更好地显示唇部的突起、唇部变化过程和唇部成圆效果等。Kumar 等人[14]在实验中也表明非正视图唇语识别的性能优于正视图。随着多视图研究的发展,涌现出许多基于多视图的数据集,常用多视图数据集有:CUAVE[15]、LILiR[16]、LTS5[17]、OuluVS2[18]、LRS2-BBC[19]、LRS3-TED[20]和LRW-1000[21]。
CUAVE 数据集是包含36 名受试者的数字数据集,数据集划分为两部分:第一部分由受试者说出50个孤立的数字,在说话过程中伴随着头部和身体的移动和倾斜,拍摄角度包含-90°、0°和90°;第二部分由受试者说出连续数字序列,但是未考虑头部角度对识别性能的影响。
基于此,LILiR 数据集和LTS5 数据集分别于2010 年和2011 年被提出,LILiR 数据集录制角度在CUAVE 数据集的基础上增加了0°、30°、45°和60°,共包含200 个句子。但LTS5 数据集在视频录制过程中未考虑到光照因素,导致视频唇部区域出现部分阴影,因此数据集的质量不高。
OuluVS2数据集、LRS2-BBC数据集和LRS3-TED 数据集均属于大规模句子级数据集,拍摄角度变化较大,适用于不同视图下的研究。
LRW-1000 数据集为解决中文数据集短缺而被提出,该数据集在拍摄过程中考虑了光照、姿态、年龄和性别等因素,贴近于真实环境,是目前研究者广泛使用的中文数据集,因其具有很大的挑战性,所以近年在该数据集上的识别率较低。
综上,这些开源数据集对唇语识别的发展起到了很好的推动作用,然而目前现存数据集仍存在一些不足。首先,不同的数据集收集来源、数据集结构、拍摄时所使用的设备和数据的维度等方面有所差异,因此,很难获取泛化性能较好的唇语识别模型;其次,不同的数据集考虑到不同的影响因素,与真实环境差异较大,这也是唇语识别领域目前所有数据集存在的普遍性问题。因此构建标准、统一和贴近于真实环境的数据集是推动唇语识别领域进一步发展的一项重要工作。表1 展示了两类相关数据集的详细信息。

Table 1 Datasets of lip reading表1 唇语相关数据集
2 传统的唇部视觉特征提取方法
为了贴近真实环境,目前大部分唇语识别研究均要求所提取的唇部视觉特征能够用来描述说话这个动态过程,而不仅仅是获取描述单帧静态图像的信息。传统唇部视觉特征提取方法有多种划分策略。荣传振等人[22]根据是否采用模型将特征提取方法划分为三类:像素点提取方法、模型提取方法、混合提取方法。Dupont 等人[23]根据不同的特征提取方法将特征提取方法划分为四类:基于图像的方法、基于动作的方法、基于几何特征和基于模型的方法。本文从不同的视觉特征角度将传统的唇部视觉特征提取方法进行归类总结,主要分为三类:基于像素点的方法、基于形状的方法和基于混合特征的方法。
2.1 基于像素点的方法
提取唇部视觉特征首先考虑的是充分利用视频帧中的所有信息,而基于像素点的方法将图像中包含唇部区域的所有像素点作为原始特征,采用系列预处理方法对原始特征降维,得到具有一定表现力的特征。目前,基于像素点的方法主要有多级线性变换法、光流法和局部像素特征法。
线性变换是常用的降维方法,这类特征提取方法通过对特征向量进行变换,降低特征向量的维数。由于单个线性变换方法不能提取到最佳特征,大多数基于像素点的方法都是由多级线性变换组成,包含帧内线性变换和帧间的线性变换。层次线性判别分析(hierarchical linear discriminant analysis,HILDA)[24]是典型的算法之一,其将二维可分离DCT 对唇部区域做变换后的24 个能量最高的系数作为唇部静态特征,由LDA 捕获帧间动态信息,MLLT 进一步改进数据建模,但是该方法采用单流的融合方法,限制了有效特征的获取,导致最终的识别精度不高。为进一步提高识别精度,Marcheret 等人[25]引入多流决策融合算法,提出对音频和视频流两个模态的可靠性特征进行选择,并加入对不同模态特征选择的动态权值估计,效果明显优于静态加权方法。上述提取的唇部视觉特征大部分依赖于说话者,为降低说话者依赖性,Almajai 等人[26]在训练过程中加入说话者自适应训练(speaker adaptive training,SAT),利用特定说话者数据对说话者无关的编码进行改造,针对说话者独立的识别取得了较高的识别精度,但是,由于数据集的限制,该方法在训练阶段并没有进行特征学习,导致结果存在一定的不合理性。
光流法是利用图像序列中像素在时域变化的前后帧之间的相关性,找出前后帧之间的对应关系,计算相邻帧之间的运动信息。Shaikh等人[27]将光流作为唇语识别任务的视觉特征,试图获取帧间唇部运动信息。但光流法对唇部轮廓亮度变化和说话者姿势变化非常敏感且对光流的提取较为昂贵。
早期为降低光照变化对唇部像素值的影响往往是采用像素的局部特征。典型的方法是局部二值模式(local binary patterns,LBP)[28],但是局部二值模式只能处理单个视频帧,无法处理连续视频帧。因此,采用三个原始平面的局部二值模式(local binary patterns from three original planes,LBP-TOP)[29]方法被引入,Zhao等人[9]从原始唇部图像和界面累积时间模式中计算LBP 特征,使用时空局部纹理特征来描述动态视觉信息,解决了说话者较大变化的特征选择问题,但在模式上具有相似性,丢失了更多精细的多分辨率特征,而且对输入视频长度要求较高。Zhou等人[30]在同样条件下,在计算LBP 特征前,分为手动和自动两种方式确定唇部位置,将数据划分为干净数据和噪声数据,分别采用LBP-TOP 方法提取唇部的时空信息,尽管获取了具有表现力的特征,但忽略了唇部检测和词语边界检测的精确性问题。方向梯度直方图(histogram of oriented gradients,HOG)特征结合运动边界直方图(motion boundary histograms,MBH)特征提取唇部时空特征也被广泛应用于唇部视觉特征提取任务中[31]。
上述方法可以有效地表示唇部的特征信息,保留大部分唇部信息,但基于像素点的方法由于使用所有的像素点信息作为特征空间,易出现特征维数冗余问题,而且对外界环境和唇部自身变化非常敏感,特征提取能力受限,使最终识别精度不高。
2.2 基于形状的方法
基于形状的方法是建立唇部轮廓模型,将构成模型的参数作为视觉特征。主要分为几何特征和轮廓特征,几何特征将唇部张开的高度、宽度和面积等作为视觉特征。一般采用自主选择关键点构成参数模型,Li 等人[32]和Alizadeh 等人[33]分别采用上外唇、下外唇、上内唇、下内唇四条轮廓线和唇部的高度距离线、宽度距离线、上外唇曲线和下外唇曲线上具有明显唇部运动的标志点作为关键点,但关键点所构成的参数模板复杂度较高,数据计算过程耗费大量时间。与之相似的是对Snake 模型改进,在唇部轮廓上选取6 个关键点,加入分割检测策略和错误检测恢复策略计算出5 个不同的几何特征,用于表示唇部视觉特征[34],相比Snake 模型,该方法所获取的视觉特征更为有效和稳定。
轮廓特征是采用唇部边缘的一些关键点坐标构成的特征向量作为视觉特征。采用轮廓特征描述唇部视觉特征常用的两类方法是Snake 模型[35]和主动形状模型(active shape model,ASM)[36],但ASM 方法在嘈杂环境下会陷入局部最小值。这两类方法适用于灰度图像处理,往往不能满足彩色图像的处理需求,在彩色图像的特征提取方法上,Chen 等人[37]利用Haar 特征定位口腔区域,将唇部区域变换到YCrCb颜色空间,再对唇部进行分割,并根据直方图熵选择阈值分割口腔,最后利用主动轮廓模型提取和跟踪唇部轮廓。虽然该方法有很好的可控性,但由于所选取的关键点大部分位于唇部边缘轮廓上,特征信息量的多少和识别精度的强弱易受其影响。
2.3 基于混合特征的方法
基于混合特征的方法是通过组合唇部的多种视觉特征来表示整个唇部的视觉特征。通过采用组合特征获取唇部运动的低级信息和高级信息,从而提取更精确的特征。混合特征方法常用的是主动表现模型(active appearance model,AAM)[38],AAM 在ASM的基础上将信息区域扩大,覆盖图像所有区域,结合形状和灰度信息来描述图像中目标的统计模型。Lan等人[13]将AAM 特征应用于唇语识别,结合像素和形状特点描述视觉特征,他们认为帧间动态信息也应包含在内,在后端加入LDA,用于捕获帧间动态信息[39]。非理想条件下,该方法所设计的唇语系统具有完备的理论性和简单的操作性,适用于简单词汇的识别,但是该系统需要复杂的训练模型,且对过长复杂的词汇识别易出错。真实环境中,说话者往往不是完全基于正面,因此需要从不同角度研究。在通常情况下采用最多的是三维主动表现模型(3D active appearance model,3D AAM)[40],其由传统的二维主动表现模型(2D active appearance model,2D AAM)从3个不同视角(正面、左侧轮廓、右侧轮廓)构建而成,从面部图像的3 个角度提取唇部视觉特征并进行识别,实验表明在交叉唇语识别任务中,同等条件下3D AAM 性能优于2D AAM,但3D AAM 对于人工特征点标定的精确度要求较高,且标定过程比较繁琐,需要多次迭代才能获取到准确的特征参数,很容易导致局部优化问题。为避免这种繁琐的标定过程和局部优化问题,Aleksic 等人[41]和Stillittano 等人[42]在唇部视觉特征提取过程中主要采用Snake 模型,采用PCA(principal component analysis)或唇部轮廓特征与Snake 相结合的方式,Snake 模型用来检测唇部内外轮廓的关键点,这些关键点用来初始化一个唇部参数模型,然后根据亮度和色度梯度的组合,对初始化模型进行优化并锁定最终的唇部轮廓,之后对图像采用基于唇部边界关键点跟踪方法对唇部分割或者是获取唇部的轮廓特征和灰度特征作为融合特征。基于混合的特征提取方法,虽然在一定程度上比以往特征提取方法效果好,但是始终不能从根本上解决特征提取有效性的问题。
综上,三种传统唇部视觉特征提取方法对比情况如表2 所示。通过对三种方法的描述和对比发现,基于像素点方法应用最多,其所有像素点作为原始特征,包含了较多的唇部视觉信息,但属于高维特征,且对图像光照变化、唇部变形和旋转非常敏感;基于形状的方法,自主选取关键点,属于低维特征,不易受图像旋转和变换的影响,但需要使用复杂的模型;基于混合特征的方法,组合多种特征,更加关注图像不同层次的不同信息,泛化能力更好,但对于自动提取特征仍是一个难题。
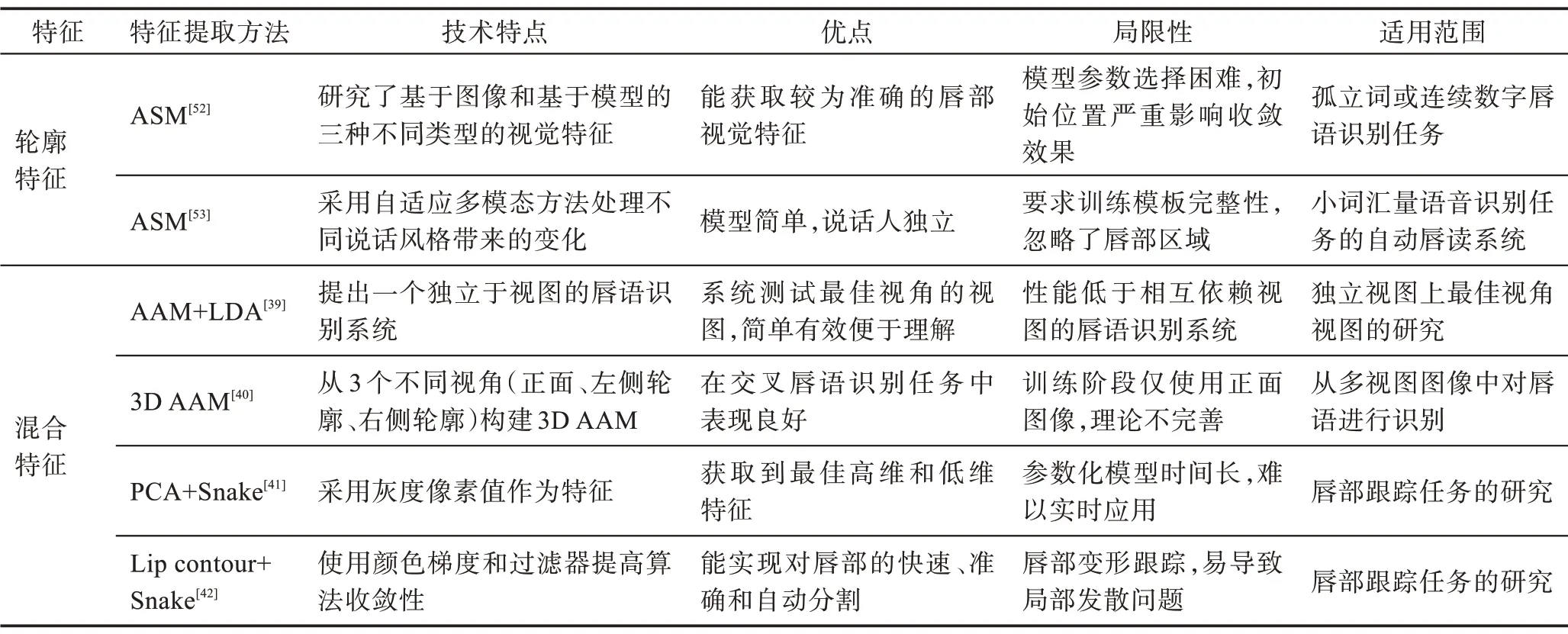
表2 (续)
3 深度学习唇部视觉特征提取方法
深度学习因其具有海量数据处理能力、强大的自主学习能力和灵活性等特点[6],被广泛应用于各个领域,并取得了显著性的效果。在唇部视觉特征提取任务中,深度学习逐渐成为主流研究方法,基于深度学习的多模态唇语识别更是成为广大研究者近年来主要的研究方向。基于深度学习的视觉特征提取也有很多划分策略,Zhou 等人[2]将视觉特征提取分为三类:基于说话者依赖、基于姿势变换和基于时空信息。本文按照卷积核的维数将基于深度卷积神经网络的唇部视觉特征提取进一步划分为四类:基于二维卷积神经网络的提取方法、基于三维卷积神经网络的提取方法、基于三维卷积与二维卷积神经网络结合的提取方法和基于其他神经网络的提取方法。图2 显示了基于深度卷积神经网络的特征提取方法。

Table 2 Comparison of three traditional extraction methods for lip visual features表2 三类传统唇部视觉特征提取方法对比
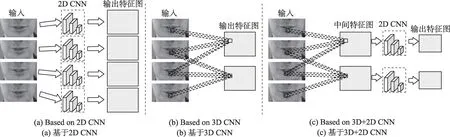
Fig.2 Visual feature extraction structure based on CNN图2 基于CNN 的视觉特征提取结构图
3.1 基于2D CNN 的视觉特征提取方法
基于2D CNN 的特征提取,是对每一帧图像分别利用2D CNN 来进行特征提取。其唇部视觉特征提取结构如图2(a)所示。针对传统视觉特征提取方法不能自动提取的局限性,Noda 等人[54]首次采用CNN作为唇部视觉特征提取机制,在AlexNet 网络模型的基础上采用包含6 个卷积层(卷积+非线性激活+最大池化层)和1 个全连接层的7 层CNN。利用唇部区域图像与音素标签相结合的方式训练CNN,并将CNN的输出作为唇语识别的视觉特征,后端采用隐马尔可夫模型和高斯混合观测模型对下游任务建模,该方法打破了传统视觉特征提取的局限性,但不能处理可变长序列。Garg 等人[55]对唇语模型进一步改进,采用VGGNet对可变长彩色图像序列处理,彩色图像序列拼接成一幅图像作为视觉特征提取模型的输入,后端采用长短时记忆网络(long short-term memory,LSTM)用于提取时间信息。但由于LSTM 性能低于门控单元(gated recurrent unit,GRU),作者使用最近邻插值的级联图像模型表现良好,对单词和短语的验证精度达到76%。该模型表现良好,但同时也面临着两个问题:如何获取更多视觉特征和降低模型计算量。
Lee 等人[47]认为多视图图像能在一定程度上增加视觉特征信息,他们在Noda 的基础上,采用多个视角图像作为输入,利用堆叠的卷积层提取多尺度视觉特征,后接LSTM 作为后续序列时间建模手段。与之不同,Noda 等人[56]考虑到单一模态有限信息的限制,他们在原有基础上又添加音频信号作为模型输入,用于研究视觉语音识别中无标签情况下音频特征和视觉特征之间的相关性,分别采用深度自动编码机制和CNN 提取音频和视频特征,后引入多流隐马尔可夫模型将双流特征信息融合。整个系统自适应地切换两个通道的特征输入,获取可靠的特征信息,但是没有实现双流的权重自动选择,难以用于实际应用。针对权重自动选择问题,Zhou 等人[57]采用额外的模态注意力机制整合音视频信息,对各模态上下文向量更为关注,通过调整注意力权重来自动选择更为可靠的模态信息,从而减轻了噪声的影响,实验表明:相比单一模态识别,该方法相对改善率从2%提高到36%,充分证明了多模态识别任务性能优于单一模态识别任务。Saitoh 等人[58]则采用一种新的级联帧图像(cascaded frame image,CFI),将所有帧拼接成一幅图像作为模型输入,使用3 个不同的模型提取视觉特征:第一个是Network in Network 模型[59],Network in Network 是在AlexNet 网络的基础上加入多层感知机层(multi-layer perceptron,MLP)和全局平均池化层(global average pooling,GAP),通过使用4层MLP 和GAP 提取视觉特征,但使用全局平均池化层易造成信息丢失;第二个是使用包含5 个卷积层和3 个全连接层的AlexNet 网络;第三个则是使用一个22 层的GoogLeNet 网络。该方法在原有特征的基础上又增加了整个图像序列的时空信息。
为进一步降低2D CNN 和深度学习带来的高计算量,Mesbah 等人[60]提出了一种基于Hahn 矩的CNN结构,通过小型体系结构提取和保留图像中的有效信息,减少冗余,降低模型的计算量。
采用基于2D CNN 的唇部视觉特征提取方法,很好地解决了自动提取特征问题,所提取的视觉特征比传统的维度压缩方法更具表现力。但此类方法仅可以对单帧图像处理,对连续帧图像处理能力较弱,忽视了连续帧之间的时空相关性。
3.2 基于3D CNN 的视觉特征提取方法
基于3D CNN 的特征提取方法则很好地处理了连续帧的时间维度问题,能同时提取连续帧的时间和空间信息。图2(b)所示为基于3D CNN 的唇部视觉特征提取结构图。LipNet[61]是第一个同时学习时空视觉特征和序列模型的端到端句子级唇语识别模型。该模型将T帧RGB 图像序列作为输入,送入由3层三维卷积层构成的时空卷积网络中,每个时空卷积神经网络后面都接有一个空间最大池化层,由该结构提取输入帧的时空特征。后端网络由两层双向门控单元(bi-gated recurrent unit,Bi-GRU)将提取的特征进一步聚合,最后连接主义时间分类(connectionist temporal classification,CTC)进行损失分析,但CTC 存在明显的缺点:要求输入序列必须大于输出序列,其次由于条件独立性假设的约束,导致类别间的远近程度无法更好地体现。Fung 等人[62]在视觉前端采用了相同的结构,不同的是他们使用8 层3D 卷积作为视觉特征提取器,虽然获得较好的效果,但是随着网络深度加深,梯度信息回流时易受到阻碍。对于CTC 和梯度信息回流的问题,Xu 等人[63]提出了LCANet视频编码器网络,将输入视频送至叠加的3D CNN,该网络通过3D CNN 对视觉短时信息进行编码,利用在3D CNN 中增加的两层Highway Network(后期残差网络的雏形),解决深层网络中梯度信息回流问题。为了能从较长的上下文中清晰地捕获信息,LCANet 将前端输出的编码信息输入级联注意网络中,注意力机制在一定程度上弱化了条件独立性假设对CTC 丢失的约束,提高了唇语模型的建模能力,同时也提高了下游识别任务的准确率。
唇语识别作为一项特殊的视频理解任务,高效的视频理解模型同样可应用于唇语识别中。针对大规模图像和视频数据集的训练,深度的三维卷积能提高分类精度,2019 年,Weng 等人[64]将视频理解领域的I3D 双流模型作为视觉前端,将灰度视频帧和光流作为视觉前端模型的输入,对两个分支提取的视觉特征信息进行通道上的拼接,后接LSTM 对融合后的特征进行建模。实验证明:在处理大规模数据集的条件下,将输入光流作为辅助手段能获取更多有效视觉信息,同时I3D 也有效地提高了后端识别任务的精度。为进一步提高识别精度,Wiriyathammabhum[65]采用动作识别的SpotFast 网络作为视觉特征提取网络,作者采用时间窗口作为慢路径,所有的帧作为快速路径。后端进一步使用结合记忆增强网络的Transformers 学习序列特征分类,记忆增强网络在不增加计算量的同时能有效提高神经网络的容量,处理变长序列输入。该网络相比于I3D 网络性能更优越。
3D CNN 虽然能够解决连续帧时空相关性问题,但在一定程度上也丢失了二维卷积对细粒度特征信息的提取。而且随着网络层数的加深,存在参数计算量大和存储开销大的问题,对硬件设备性能要求较高。针对上述问题,基于2D CNN 与3D CNN 相结合的模型则同时解决了时空特征和局部细粒度特征提取的问题。
3.3 基于2D CNN 与3D CNN 结合的视觉特征提取方法
为了提取到连续帧的时空特征同时能解决3D CNN 所产生的问题,人们提出基于3D CNN 与2D CNN 相结合的方式,其示意图如图2(c)所示。基于2D CNN 与3D CNN 相结合的方式有两种:第一种将深层2D CNN 的第一层卷积修改为3D CNN,由3D CNN 捕捉连续帧之间的时空信息,后连接深层2D CNN 提取唇部图像局部特征;第二种在使用深层2D CNN 之前首先采用浅层的3D CNN 对视频帧进行预处理。对于第一种方式,Stafylakis 等人[66]和Feng 等人[67]将标准的ResNet 架构第一层卷积由2D CNN 修改为3D CNN,用于处理连续帧图像序列,将提取到的特征映射接入时空池化层,降低三维特征映射空间大小。后接残差网络的剩余层提取局部细粒度特征。对于第二种方式,Afouras 等人[68]在2D CNN 前面添加一层时空3D CNN,然后使用ResNet网络作为局部特征提取机制,并通过调节说话者的唇部运动或声音将目标说话者从其他说话者和背景噪声中分离,实现一种视听语音增强网络。但是这种方法还是带来了大量的参数计算。为进一步降低参数计算量,Xu 等人[69]引入一个基于伪三维残差卷积(pseudo-3D residual convolution,P3D)的视觉前端来提取视觉特征,将ResNet 网络中的时间卷积全部由更适合时间任务的时间卷积(temporal convolutional network,TCN)代替,音频由短时傅里叶变换(short time Fourier transform,STFT)采样提取声谱图,后接语音增强模块,将增强后的特征信息输入多模态融合网络。在保证能提取到有效唇部视觉特征和降低模型参数的同时,又进一步提高了下游分类识别任务的精度。同样受卷积原理的启发,Luo 等人[70]提出了一种基于伪卷积策略梯度(pseudo convolutional policy gradient,PCPG)的序列模型用于唇语任务。为在每个时间步考虑到更多上下文信息,作者在激励和损失维度上进行伪卷积运算,该模型较以往其他唇语模型在准确率上有很大的提高。但是该方法采用单模态方法,因此获取的信息有限,且对受到破坏的信息无法补充。Xiao 等人[71]认为使用变形流网络(deformation flow network,DFN)从原始输入的灰度图像中获取变形流同原始视频帧作为模型输入,能在一定程度上弥补缺失信息。整个网络或分为原始视频分支和变形流两个分支,由3D CNN+2D CNN 和2D CNN 分别获取两个分支的有效唇部视觉信息,变形流网络直接捕获边缘区域内的运动信息,相比于光流法,变形流网络降低了计算复杂度,之后采用双向知识提取损失来联合训练两个分支,使得两个流在训练过程中相互学习。该方法不仅可以应用于唇语领域,同时还可以广泛用于其他人脸分析任务。但该方法对相邻帧之间的相关性未进行更多的关注,并且未对关键帧和无效帧之间进行有效区分。
为增强相邻帧之间相关性同时加强对关键帧的识别,Zhao 等人[72]采用相同的视觉前端网络,在局部特征层和全局序列层分别引入局部互信息最大化约束和全局互信息最大化约束,局部互信息约束每个时间步生成的特征,保持与语音内容之间的强关系,全局互信息约束注重区分和语音内容相关关键帧的识别,降低噪声产生的影响。所提出的方法对于提高了唇语任务的识别准确率具有较好的鲁棒性。但性能良好、泛化能力较强的唇语模型仍是研究者努力的方向。
基于2D CNN 与3D CNN 相结合的唇部视觉特征提取方法是近年来唇语研究的主流方法之一,该方法有效地解决了视觉特征提取效率低和下游任务识别准确率低等问题,但由3D CNN 对时空信息提取,后直接接入2D CNN 对局部细粒度信息提取,在一定程度上会影响特征编码的时间信息。
3.4 基于其他神经网络的视觉特征提取方法
近年来,端到端的训练模式成为唇语识别领域研究最常用的训练方式,而这些端到端结构并不是完全基于卷积神经网络。自动编码机制、前馈网络、深度置信网络也常被用于唇部视觉特征提取。自动编码机制类似于传统的PCA 方法,其通过神经网络自动地将高维数据转为低维编码,后通过解码机制恢复成原始信息。Petridis 等人[73]在自动编码机制基础上建立了基于句子级别的双流端到端系统。采用原始图像序列和光谱图像作为模型输入,两个分支模型均使用3 个隐藏层和1 个线性层构成的编码结构模型,分别提取不同的唇部视觉特征,为获取更加有效的视觉特征,提高分类识别精度。他们采用相同的网络结构,将光谱图替换为图像差分图[74],输入图像由模型的瓶颈层将高维输入图像压缩为低维表示,瓶颈架构的一阶导数特征和二阶导数特征附加到瓶颈层,以保证编码层能够学到更多有效特征。实验表明,该方法能有效提高下游任务的分类识别精度。之后,在采用双分支思想的基础上,为研究多视图唇语识别任务,其采用相同的网络模型,同时将30°、45°、60°和90°的原始图像分成两个分支同正视图图像一同作为模型输入[75],每个分支后接一个双向长短时记忆网络(bi-long short-term memory,Bi-LSTM)用于对每个流的特征时间动态进行建模。但由于对非正视图进行唇部检测时,检测精度并不是完全准确,导致模型在分类识别精度上并没有很大的提高。随后,他们采用相同的网络结构,将双流改为单流模型[76],并在有音频、噪声音频和无音频三种模式下进行实验,因唇部运动存在差异,在使用普通唇语模型对无音频下的唇部运动进行训练时表现较差。随着海量数据的增加和模型层数的加深,唇语领域对模型性能要求越来越高,但上述使用自动编码机制作为特征提取器,明显的缺点是难以获取深层次、多尺度信息。
前馈神经网络采用简单的全连接前馈层堆叠。Wand 等人[51]提出了一种由一个前馈网络层和两个LSTM 层构成的自动唇语识别模型。前馈网络层将输入的图像序列传递给输出单元,每层前馈网络层后面接一个Dropout 层,由梯度下降法进行训练,通过层间误差反向传播和权值调整,对字级水平的数据集分类。但该方法对已知说话人和未知说话人之间的差异未进行有效区分。为解决说话人之间的差异,作者又添加一层前馈网络层,同时在第二个前馈网络层前附加一个用于对原说话人和目标说话人进行逐帧分类的网络,并采用域对抗来训练,最终相当于两类任务,一类是对说话人的分类,另一类是对单词的分类[77]。但仅从单一模态(视频帧)中挖掘出来的视觉信息是有限的而且还具有不确定性(受其他因素干扰),因此从多模态方向入手,作者又添加音频作为辅助输入[78],音频和视频分支采用相同结构,每一个分支中堆叠多层全连接前馈网络层和Dropout层,以确保网络能提取到更深层次的视觉特征。上述模型在句子级训练上表现良好,但都没有涉及到句子级序列预测,同时也未考虑到说话人独立性问题,因此导致最终结果存在一定的不合理性。
深度置信网络和前馈神经网络一样采用堆叠的方式,主要由多层受限玻尔兹曼机堆叠构成,对每一层逐层训练,最后反向传播对模型进行微调。Moon等人[79]提出了一个采用两个独立的音频和视频分支来分别获取原始视频中特征信息的模型。每个分支都由具有相同数量的中间层构成的深度置信网络组成,通过学习每个神经网络中间层之间的语义映射,根据传输的数据达到对网络微调的目的。该网络结构不需要建立额外共享模型,仅需要调整目标网络的超参数实现目标网络的修改。
表3 从方法大类、特征提取方法、主要技术描述、数据集、识别任务、识别率和适用模式7 个方面总结近年来基于深度学习的唇部视觉特征提取方法。

表3 (续)

表3 (续)
4 总结与展望
唇语识别经过数十年的发展,传统方法和深度学习方法推动其迅猛发展,本文对唇语识别研究领域的视觉特征提取方法进行分析,并分别从数据集、视觉歧义、模型性能、多模态唇语识别和模态之间的相关性五方面介绍所面临的挑战与发展趋势。
(1)唇语识别数据集。唇语数据集是推动唇语领域发展的基础,如何建立更贴近真实自然环境、更规范且不限于特定任务的数据集是目前存在的主要问题之一。大多数数据集规模较小,且仅限于特定任务的识别,例如:数字、字母、单词和句子等,并且数据集在构建过程中很少考虑到真实环境下的各种因素影响,缺少泛化能力较强的数据集,尤其针对中文研究的数据集比较短缺。因此,需要选择来源可靠、正规数据资源,构建高质量且规模较大的唇语数据集来提高唇语模型的准确率。
(2)视觉歧义。在唇部运动过程中如何更好地反映说话人视觉信息的特征至今仍然是一个难题。由于说话过程中存在不同音素具有相似的口型,连续阅读和弱音现象等导致最终的视位缺少,最终严重影响着唇语识别任务的准确率。考虑到这个问题,可以尝试主要致力于研究不同音位到视位的映射、规范化音素,设计解决视觉歧义的算法,解决视觉歧义问题。
(3)模型性能。在唇语识别领域,模型设计方法由传统的方法过渡到深度学习方法,其准确率有大幅度的提升,但其计算复杂度也随之增加。现阶段的深度学习唇语模型大部分属于大规模模型,不便于研究人员的优化,且需要处理海量唇语数据,过程十分耗时耗力。针对模型上存在的问题,研究人员应致力于设计轻量级唇语模型,以降低设备负担。轻量级唇语模型也是接下来唇语研究领域的重点方向之一。

Table 3 Comparison of visual features extraction methods based on deep learning表3 基于深度学习的视觉特征提取方法对比
(4)多模态唇语识别。多模态是指采用两个或以上模式信号作为模型输入,其打破了单模态获取信息有限、识别率低和稳定性差等局限。其优势也是双重的。首先,由于各模态之间信息通常是互补的,多模态处理的信息结果比单模态处理结果具有信息性;其次,由于单模态信息并不总是可靠的,当一种模式损坏时,有可能从其他模态中提取丢失的信息,从而形成一个更可靠的系统。例如:当音频信号被噪声破坏时,这种多模态方式尤为有效,但当音频干净时,这种方法也能对最终识别率带来极大的提高。正是由于上述多模态的优点,该方法近年被广泛应用于各个领域,但是在唇语领域应用较少。因此多模态唇语识别也是该领域的一个重要研究方向。
(5)模态之间的相关性。利用从一个模态中提取的信息弥补另一模态的缺失信息,以此来提高另一模态的识别能力,其关键是在噪声水平变化的情况下,找到模态间的相关性,并且模型能自动选择可靠模态。现存方法中,对模态间相关性关注较少,因此如何找到模态间的相关性,自动选择可靠模态以提高识别准确率也是该领域未来的一个研究方向。
5 结束语
本文对近年来唇语识别领域唇部视觉特征提取的研究成果进行了总结。首先介绍了唇部识别相关数据集,并对相关数据集进行简单描述;然后将近年来唇语识别领域唇部视觉特征提取相关技术按照传统方式和深度学习方式划分为两类,并对每一类主要应用技术进行叙述;最后对该领域存在的挑战和发展趋势进行了讨论。
