基于多植被指数组合的BAS-ELM粳稻冠层氮含量反演方法
2021-12-09许童羽邢思敏于丰华郭忠辉刘亚帝
许童羽,邢思敏,于丰华,郭忠辉,刘亚帝
(1.沈阳农业大学信息与电气工程学院,沈阳110161;2.辽宁省农业信息化工程技术中心,沈阳110161)
氮是粮食作物维持有机生活的基本元素,水稻中的氮含量浓度可作为判断植物生长状态和产量的重要指标[1]。水稻缺氮时叶片数量减小、植株矮小、分蘖数减少,叶绿素合成受阻,根系机能减弱[2-3]。氮素营养过剩则会造成水稻贪青徒长,延长营养生长期而推迟出穗期不利于水稻稳产[4-5]。在水稻的培育管理过程中保持恰当的氮供给十分必要。然而,中国是世界上最大的氮肥生产和消费国,从1990到2015年,中国氮肥投入增加了732.2万t,但氮肥利用率只有35%[6-7]。过量使用氮肥带来的不仅是污染作物、肥料浪费问题,更为国民经济可持续发展敲响警钟[8]。利用更少的氮肥生产更多的粮食,这要求培育者对水稻氮素营养状况做出精确诊断,合理做出施肥决策。
高光谱遥感技术普遍应用于水稻等作物的生长营养检测上,为作物生产的动态监测与管理提供了有效的技术途径[9-11]。基于生物信息中光谱吸收和反射过程,实现实时、快速、无损检测氮素信息。李金敏等[12]通过地物光谱仪获取光谱反射率数据,建立了估测水稻叶片氮含量的深度森林模型。ROOSJEN等[13]利用无人机获取的成像光谱数据,改进对马铃薯作物叶面积指数和叶绿素含量的估计。刘昌华等[14]以多旋翼无人机搭载多光谱相机,较好地检测冬小麦氮素含量指导精准氮肥管理。而植被指数法作为光谱反演植物营养元素的重要方法,已被广泛应用于反演作物的生物物理与生物化学参量[15-17]。在国内外无人机的实际应用中,植被指数在无人机获取的高光谱波段反射率上普遍使用,而高光谱信息量巨大,因此恰当的植被指数选择与组合是应用其构建反演氮素含量模型的重要工作基础[18]。裴信彪等[19]基于无人机遥感平台获取的光谱信息,构建比值植被指数(RVI)和归一化植被指数(NDVI),分析了不同氮素水平下粳稻关键生育期内长势情况。曹英丽等[20]筛选出水稻叶绿素反演的特征光谱指数最优组合作为多元回归模型的输入特征。董羊城等[21]基于40个植被指数,利用逐步回归法建立了植被指数组合对水稻不同生育期生物量进行估算。
极限学习机作为一种简单高效的单隐层前馈神经网络,应用于高光谱反演作物氮素方面的研究逐渐增多[22],但其反演氮素含量仍存在模型精度不够、误差较大的问题。许童羽等[23]研究了基于遗传算法优化的极限学习机模型,提升了水稻叶片缺氮量反演的精度及泛化能力。智能优化算法是依据生物系统的进化和自适应现象而形成的,因其不依赖严格数学关系而被广泛应用优化极限学习机算法的问题。天牛须搜索算法[24-25]是一种受天牛觅食原理启发、具有较好全局搜索能力的智能优化算法。鉴于此,以挑选得到的不同的植被指数组合作为模型的输入量,本研究采用能够高效寻优的天牛须搜索算法对ELM进行优化,对比得到一个更加精准的北方粳稻冠层叶片氮素反演模型,检测氮素含量,进而为施肥管理提供决策依据。
1 材料与方法
1.1 试验区域与试验设计
试验于2019年5月在辽宁省沈阳市沈北新区镇柳条河村(东经123°38′,北纬42°01′)进行,供测试的水稻品种为“粳稻653”。水稻试验田培养标准采用控制变量法设4个氮肥梯度处理,N1为当地标准施氮量,在N1的基础上分别增加和减少50%的施氮量设置N1(45kg·hm-2)、N2(22.5kg·hm-2)、N3(67.5kg·hm-2)3个梯度,N0(不施用基肥)为空白对照梯度,各试验小区之间采取隔离措施,保证小区之间水肥不互相渗透,其他按高产栽培管理(图1)。
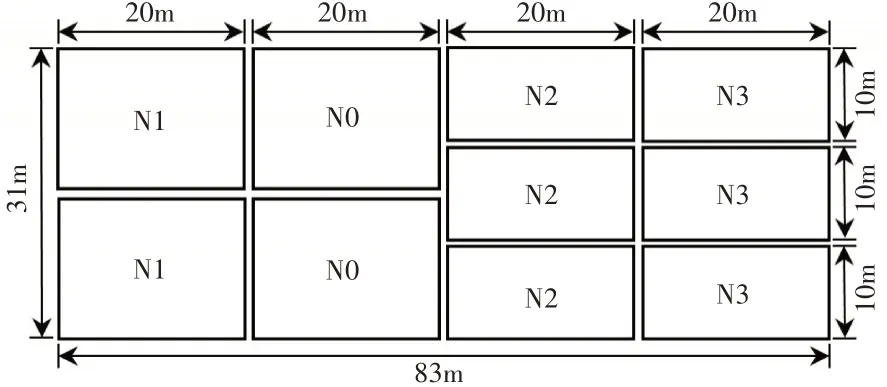
图1 试验小区设计Figure 1 Test plots design
1.2 数据获取及预处理
1.2.1 水稻叶片高光谱信息获取 采用的无人机为深圳大疆创新公司制造的M600 PRO六旋翼无人机,搭载的高光谱成像系统为四川双利合谱公司的GaiaSky-mini,高光谱的波段范围为400~1000nm,分辨率为3nm,单幅影像获取时间为15s,帧速率为162帧·s-1,设置无人机飞行高度为100m。粳稻分蘖期稻田内水体面积较大,正午强光下水体部分易产生耀斑现象,干扰数据采集,将无人机高光谱数据采集时间选择在08∶00-08∶30之间。试验小区在高光谱数据采集之前无虫害、病害,未喷施药剂,所获取的光谱数据未受到外界胁迫影响。运用ENVI5.3工具软件对获取的高光谱遥感影像进行小区高光谱数据提取。
1.2.2 SG平滑处理 无人机获取的光谱数据易受到自然背景、光程变化以及表面散射等因素的影响。对高光谱数据进行SG平滑处理,增强光谱数据信噪比、降低随机噪音和高频噪音的干扰,设置窗口点数为10,多项式阶数为2。
以样本中的一条数据为例,如图2左小图,黑色线条为原始光谱数据,红色线条为经平滑处理后的光谱数据,从放大后的右小图可见,采用SG平滑方法处理一定程度上滤除了光谱中存在的毛刺,光谱曲线变得较为平滑、噪声明显减少。

图2 经平滑处理的光谱数据图像Figure 2 Smoothed spectral data
1.2.3 水稻叶片氮素浓度测定 在每个试验小区采样点破坏性采样,分装入自封袋中并标注小区名称和编号,带回实验室。经过对叶片进行洗涤、除灰尘等清洁步骤,在105℃条件下杀青60min,再以65℃烘干至恒量。烘干后的样品称量质量后粉碎,并放入自封袋做好标记,用于检测叶片含氮量(mg·g-1)前统一存放于干燥器皿内。检测叶片含氮量采用的方法是传统的凯氏定氮法。最终共得到粳稻叶片氮素含量有效数据221组,呈正态分布,同时采用Kennard-Stone算法(KS)将样本按照训练集与验证集3∶1的比例进行划分,氮素含量统计结果表1。

表1 训练集与验证集粳稻叶片氮素含量统计结果Table 1 Nitrogen content statistics of japonica rice leaves in the training and validation sets
1.3 高光谱特征波段的提取
采集得到的高光谱波段是具有高维度的数据集,存在大量无用和干扰波段,为筛除无用信息,便于下一步利用特征波段构建植被指数,研究采用无信息变量消除法(uninformation variable elimination,UVE)选择最优变量子集,筛除无效波段信息。无信息变量消除法(UVE)最初由CENTNER等[26]提出的一种基于偏最小二乘法模型回归系数的波段筛选方法。首先将光谱矩阵X(n×p)和随机产生噪声矩阵N(n×p)相加得到混合矩阵XN(n×2p)。并将混合矩阵XN作为模型输入,粳稻冠层叶片氮素含量矩阵Y作为输出,构建基于交叉验证的PLS回归模型,得到回归系数矩阵b(n×2p)。
计算回归系数矩阵的平均值M(i)与标准偏差S(i),并求其比值E(i),即:

计算E(i)在区间中的最大绝对值,并在[ 1,p]区间内去除矩阵中数值小于Emax的波段,剩余的波段即为筛选出的特征波段。
1.4 植被指数的构建
植被指数作为对植被状况的简单、有效和经验的度量参数,常常被用来遥感监测植被生长状况和生物量信息等植被信息,它可以区别水体、自然环境等非植被信息,增强植被信息。研究参考IndexData-Base(IDB)数据库内已有高光谱遥感植被指数的构建方法,结合已有的文献[27-28]对氮素含量反演效果较好的植被指数研究,得到常用于检测和估算植物营养元素含量的指数:比值植被指数(ratio vegetation index,RVI)、差值植被指数(difference spectral index,DSI)、归一化植被指数(normalized deference spectral index,NDVI)、转换型植被指数(conversion vegetation index,TVI)、再归一化植被指数(renormalized vegetation index,RDVI)、宽动态范围植被指数(wide dynamic range vegetation index,WDRVI)、校正比值植被指数(the normalized ratio vegetation index,NRVI)、对数比率指数(log ratio index,LogR)。以上8种指数结构公式如下。

式中:ρi、ρj分别为不同波段的反射率。
基于1.3中的方法筛选得到的特征波段,通过特征波段反射率的两两随机组合构建植被指数,选取与水稻氮含量相关性较优的植被指数组合作为氮素含量反演模型的输入量。
1.5 反演建模方法
极限学习机模型(extreme learning machine,ELM)是HUANG等[29]依据摩尔-彭罗斯理论提出的一种单隐层前馈神经网络,目前在高光谱反演作物氮素浓度方面的研究也逐渐增多。极限学习机算法与同类型的机器学习类算法如BP神经网络(back propagation neural network)、支持向量机(support vector machine,SVM)相比,具有训练速度较快、泛化性能较好的优势;与深度神经网络(deep neural network,DNN)相比,ELM无需通过大量的数据来满足训练要求,能够通过较少的样本量以较快的速度解决简单任务。然而该算法的输入层与隐含层的连接权值、隐含层神经元阈值具有随机性,影响该算法所建立的反演模型的稳定性及泛化能力。本研究采用一种通过模仿天牛觅食原理而提出的一种高效智能的天牛须搜索算法对ELM进行优化。具体方法如下(确定ELM的隐含层神经元数量后)。
(1)对天牛须搜索算法的参数进行初始化,参数包括起始步长step、步长更改系数eta、迭代次数n等。
(2)初始化N维参数自变量X,由神经元的个数与输入量的维度决定N的大小,其计算公式如式(11)。通过目标函数的定义,求取其对应的函数值F(X)。
(3)依据正态分布的方式,得到每一维自变量Xi在每次迭代的过程中变化的方向向量dire。
(4)X向量通过依步骤(3)得到的方向向量向左迈一小步。

其对应的函数值为F(Xleft)。
(5)X向量通过依步骤(3)得到的方向向量向右迈一小步。

其对应的函数值为F(Xright)。
(6)判断F(Xleft)和F(Xright)大小关系,以决定X应当往哪一方向走一大步。公式为:

(7)重复步骤(3)至(6),迭代n次获得最优解。
整体技术路线如图3。最终依据模型的决定系数R2和均方根误差RMSE来检验模型的精准度和可靠性,挑选最优的粳稻叶片含量反演模型。
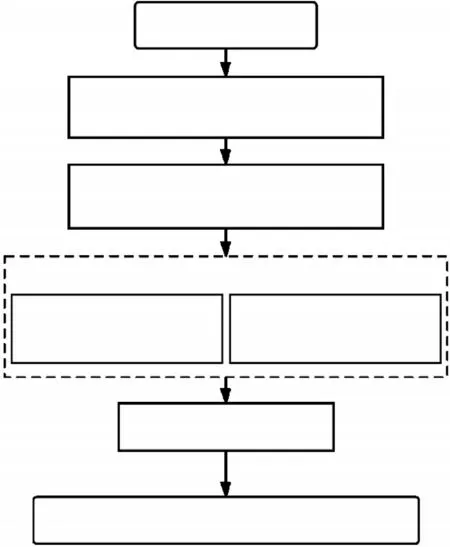
图3 研究技术路线图Figure 3 Research technology roadmap
2 结果与分析
2.1 光谱特征波段筛选结果
UVE算法的筛选结果如图4,竖虚线为波段序数分隔线,分割线左右两侧分别为601个混合信息矩阵和UVE算法随机产生的601个噪声信息矩阵的稳定性分布曲线,两条横实线为UVE方法选择的正负阈值,位于两条横实线之外的变量作为筛选出的特征波段,共计266个。从结果来看,UVE算法能够较好的保留有信息的波段,剔除无用和冗余信息,提升构建植被指数的效率。
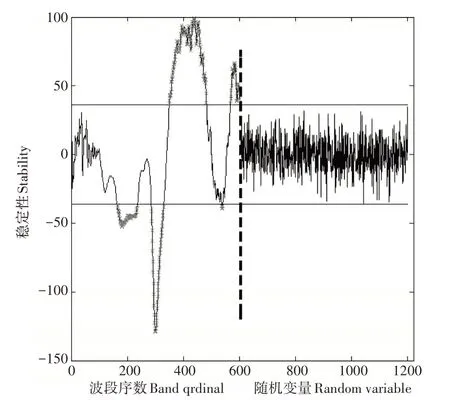
图4 UVE算法的特征波段筛选结果Figure 4 Results of feature band screening for UVE
2.2 植被指数与粳稻氮含量相关性分析
为准确、高效筛选出与粳稻叶片氮含量相关性较高的植被指数,将由UVE算法提取的266个波段的反射率两两随机进行组合,构建所有可能组合NDVI、DSI、RVI、RDVI、TVI、NRVI、WDRVI、LogR,分析粳稻叶片氮含量与植被指数之间的相关性,并将对应的决定系数R2构建成分布矩阵(图5)。以图5a为例,图像是由266个特征波段两两组合构建的RVI指数与氮素含量的相关性分布图,由深蓝至深红的颜色区别代表该指数与粳稻冠层叶片氮素含量的决定系数R2由低到高的变化,可得最佳指数为RVI(ρ574,ρ695)。以此类推,其余7种指数中与氮素含量相关性最佳指数分别为DSI(ρ696,ρ576)、NDVI(ρ694,ρ574)、TVI(ρ694,ρ574)、RDVI(ρ697,ρ574)、NRVI(ρ801,ρ754)、WDRVI(ρ574,ρ694)、LogR(ρ696,ρ577)决定系数R2分 别 为:0.7283,0.7552,0.7283,0.7580,0.7284,0.7283,0.7288,0.7332。以上指数与氮素含量均存在显著相关关系。
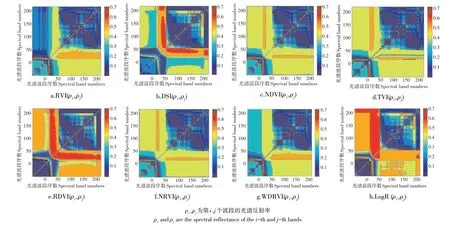
图5 水稻植被指数与氮含量的相关性等势图Figure 5 Isopotential plot of correlation between rice vegetation index and nitrogen content
2.3 天牛须搜索算法优化极限学习机反演模型
为比较不同植被指数组合作为模型输入量的模型差异,本 研 究 挑 选 出NDVI、DSI、RVI、RDVI、TVI、NRVI、WDRVI、LogR共8种植被指数中与氮素含量相关性最高指数的组合以及每种植被指数与氮素含量相关性最高的8个指数的组合分别作为模型的输入量,具体组合情况如表2,以9组植被指数组合为输入量,以实测水稻叶片含氮量作为输出,建立基于天牛须搜索算法优化的极限学习机反演模型。

表2 不同植被指数作为模型输入量的组合Table 2 Combinations of different vegetation indices as model inputs
结合表2的输入量组合,由图6可知,基于9组不同输入量建立的BAS-ELM反演建模效果均较好,训练集与验证集的R2均在0.646以上,RMSE均低于0.564mg·g-1。在9组不同的输入量组合中,以8种植被指数的组合作为模型输入量建立的BAS-ELM反演效果最好(图6i),训练集与验证集的R2分别为0.756和0.753,RMSE分别为0.431mg·g-1和0.466mg·g-1。综合模型结果来看,BAS-ELM具有较好的模型的稳定性和预测能力。
在单一结构的植被指数组合当中,以RVI指数组合为输入的模型反演结果最好(图6a),训练集与验证集的R2分别为0.748和0.740,RMSE分别为0.431mg·g-1和0.483mg·g-1;以LogR指数组合为输入的模型效果最差(图6h),训练集与验证集的R2分别为0.651和0.646,RMSE分别为0.516mg·g-1和0.564mg·g-1。对比不同输入量的结果,8种植被指数的组合优于单一结构的植被指数的建模结果,这是由于8种植被指数的组合能够综合每种植被指数的结构特点、囊括较为全面波段反射率信息。

图6 不同植被指数组合作为输入量的粳稻含氮量预测模型检验结果Figure 6 Test results of the model for predicting nitrogen content of rice with different vegetation index combinations as inputs
2.4 与其他反演模型的比较
将天牛须搜索算法优化的极限学习机(BAS-ELM)与目前在高光谱反演中应用较为广泛的极限学习机(ELM)模型进行比较,选取与建立BAS-ELM模型相同的9组植被指数组合作为输入量,将模型参数均调整至最佳状态,建模结果如表3。
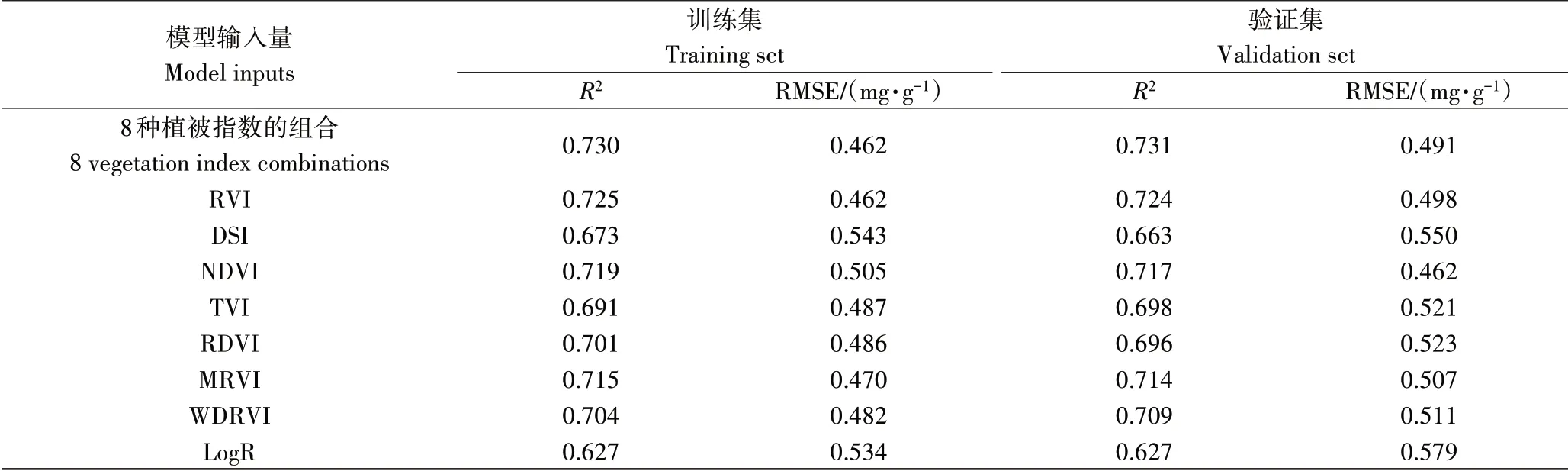
表3 不同指数作为输入量的ELM结果Table 3 ELM results for different indices as inputs
不同植被指数组合作为输入量的ELM预测模型检验结果中,采用8种植被指数的组合结果建立的ELM预测模型检验结果最好。总的来看,ELM预测模型的预测效果普遍低于BAS-ELM模型的预测效果。9组不同的输入量下,BAS-ELM预测模型的训练集与验证集的R2更高,均方根误差RMSE更低,泛化性更好。这是由于ELM模型的连接权值及阈值无需调整,易使结果局限于局部最优值,而BAS具有较好的全局搜索能力能够改进这一问题。经对比分析得出,BAS-ELM预测模型的预测能力和模型稳定性均优于ELM方法所建立的反演模型。
3 讨论与结论
无人机遥感技术已成为作物氮含量快速无损监测的有效手段[30-31],本研究以东北粳稻为研究对象,基于粳稻冠层叶片无人机尺度的光谱反射率构建了多种植被指数,初步确立了粳稻叶片含氮量的预测模型。在数据获取与处理部分,考虑到稻田水体镜面反射的影响,所以在特定的时间采集光谱数据,用SG平滑处理方法降低光谱数据中的噪声影响。在数据降维部分,采用UVE算法对光谱进行特征波段的提取,有效剔除无信息的光谱波段。基于UVE算法提取的特征波段任意两两组合分别构建NDVI、DSI、RVI、RDVI、TVI、NRVI、WDRVI、LogR指数,依据不同波段光谱反射率组合形成的指数与氮含量的相关性,挑选出了8种植被指数中与氮素含量相关性最高指数的组合以及每一种结构的植被指数中与氮素含量相关性较高的前8个指数的组合分别作为BAS-ELM模型的输入量,以8种不同指数的组合作为输入量建立的BAS-ELM预测模型反演效果最好,训练集和验证集决定系数分别为0.756和0.753,RMSE分别为0.431mg·g-1和0.466mg·g-1。由于每种植被指数均为单一的物理结构,其波段选择能力和对光谱信息的代表能力具有一定的局限性,所以以每一种指数的最优组合和8种植被指数的组合分别作为输入量构建的反演模型进行对比。9组不同的输入量条件下,采用ELM和BASELM方法建模时,基于8种植被指数组合作为输入量的反演效果均最好,而采用单一结构的植被指数组合建模得到的结果略差。ELM与BAS-ELM两种建模方法运行速度接近,无显著差异。ELM模型用非线性函数输入输出数据训练神经网络,可以有效解释非线性的问题,反演效果比较理想,而BAS-ELM建模结果优于ELM,原因在于BAS的优化训练可以为ELM的初始权值进行赋值,对ELM随机产生权值的问题进行优化,提高了模型精度、稳定性和泛化能力。与传统的研究方法不同,本文中以多种植被指数的组合作为建模自变量的结果表明,不同构造、囊括不同波段信息的植被指数的组合能够为反演氮素模型的建立提供新思路。此外在构建植被指数过程中发现,比如由叶绿素导致的光谱变化主要体现在红、蓝波段[32],而红边波段范围内的波长位置与一阶微分光谱反射率也能反映粳稻的生理特征[33],因此在下一步的研究中有必要考虑依据可见光、近红外区域的不同吸收特征来构建植被指数[34]。
以粳稻分蘖期叶片高光谱数据、氮素含量为数据源,经SG平滑处理后,采用UVE算法筛选得到的266个特征波段构建植被指数,依据与粳稻叶片氮素含量的相关性选定9组不同的植被指数组合(8种植被指数中与氮素含量相关性最高指数的组合共一组,每种植被指数中与氮素含量相关性最高的前8个指数的组合共8组)作为模型输入量,构建BAS-ELM、ELM粳稻叶片氮素含量反演模型并对比分析。本研究分别采用以RVI(ρ574,ρ695)、DSI(ρ696,ρ576)、NDVI(ρ694,ρ574)、TVI(ρ694,ρ574)、RDVI(ρ697,ρ574)、NRVI(ρ801,ρ754)、WDRVI(ρ574,ρ694)、LogR(ρ696,ρ577)的组合和每一种植被指数的最优组合作为模型输入量,构建9种粳稻叶片氮素含量反演模型。对比分析得出,8种不同结构的指数作为模型输入量的估测效果要优于单一植被指数作为输入量的估测效果。验证集决定系数R2为0.753,均方根误差RMSE为0.466mg·g-1。将天牛须搜索算法优化得到的BAS-ELM模型与ELM的预测结果进行比较,发现9组输入量下,BAS-ELM反演模型均获得了较好的预测结果,提高了建模精度,为准确检测粳稻叶片含氮量提供一种新的方法。
