基于熵与邻域约束的模糊C均值改进算法
2021-12-09冯俊淇张正军
冯俊淇,张正军,章 曼,严 涛
(南京理工大学理学院,江苏 南京 210094)
0 引 言
聚类分析是一种常用的无监督学习算法,对于一组未知类标签的数据集,它能够根据样本间的相似性,将样本划分到对应的类别,从而使同一类别中样本相似度较高,不同类别间样本相似度较低。近年来,随着数据爆炸式增长,聚类分析被广泛应用于图像处理、数据挖掘、机器学习等领域。
聚类方法发展至今,已有许多成熟算法:划分聚类算法K-means[1]和K-medoids[2]、密度聚类算法DBSCAN[3]、层次聚类算法CURE[4]、网格聚类算法STING[5]等。
根据隶属度取值方法,聚类算法可以分为硬聚类算法和软聚类算法。传统聚类算法中的K-means就是硬聚类算法,样本的隶属度取值是0或1,即样本只能属于一类,这种“非黑即白”的分类方法并不符合生活中的现实关系。1973年Dunn[6]将模糊关系引入到K-means算法,提出了模糊C均值(FCM)算法,1981年Bezdek[7]将模糊指数引入目标函数,扩展了算法的一般性。
尽管模糊C均值(FCM)算法应用于现实生活中的诸多领域,但是仍存在一些不足:1)算法中采用欧氏距离作为相似性度量,未考虑数据的各属性对聚类的影响不同,导致聚类效果不理想;2)聚类过程中仅考虑样本与聚类中心的距离,没能有效利用邻域样本的信息,造成边界样本和噪声样本错分率较高。近年来,许多专家学者针对FCM算法缺点提出了改进,取得了丰厚的研究成果。文献[8-11]通过对数据赋予权重的方法来优化算法,提高聚类性能;文献[12-14]利用不同的方法对聚类中心初始化,有效减小了噪声点对聚类过程的影响,提升了聚类的准确性;文献[15-16]从数据的空间邻域信息出发,通过改变目标函数进而修正了隶属度及聚类中心的迭代公式;文献[17-18]通过松弛样本隶属度约束条件,降低噪声样本对聚类结果的影响;文献[19-20]从模糊加权指数入手,提出各种方法以计算合理的模糊加权指数。
基于以上研究,本文提出基于熵与邻域约束的FCM算法,利用熵权法对样本加权,改进样本间的距离度量,利用邻域约束修正目标函数,从而提升聚类性能。
1 模糊C均值算法
模糊C均值(FCM)算法是一种基于目标函数的聚类算法,通过最小化目标函数使得类内平方误差达到最小值,其目标函数(1)和约束条件(2)如下:
(1)
(2)
其中,c(c>1)是聚类数目;V=[v1,…,vc]表示聚类中心;U=uij是c×n的隶属度矩阵;m∈[1,+∞)是模糊系数;uij是样本xj对于第i类的隶属度;‖xj-vi‖2表示样本xj与聚类中心vi的欧氏距离。
采用拉格朗日乘数法计算得到uij、vi的迭代公式如式(3)、式(4):
(3)
(4)
FCM算法具体步骤如下:
输入:聚类数目c、模糊系数m、最大迭代次数T、阈值ε
输出:隶属度矩阵U,聚类中心矩阵V
步骤1 初始化迭代次数t=0;
步骤2 初始化隶属度矩阵U;
步骤3 根据式(4)计算聚类中心矩阵V;
步骤4 根据式(3)计算隶属度矩阵U;
步骤5 如果‖U(t)-U(t-1)‖≤ε或t>T,停止迭代;否则,t=t+1,转到步骤3;
步骤6 完成上述步骤,得到最终的聚类中心矩阵V和隶属度矩阵U,据此划分数据集,完成聚类。
2 算法设计
2.1 熵值赋权法
FCM算法中样本隶属度仅由样本与聚类中心的欧氏距离决定,没有考虑数据的不同属性对聚类的影响不同。为了弥补这一缺陷,本文通过各属性的熵值来确定权重,最终以加权欧氏距离作为距离度量。
在信息论[21]中,熵是对系统不确定性的度量。熵值赋权法[22]的思想是根据属性的熵值来判断其变异程度,属性变异程度越大,熵越小,信息量越大,所以权重越大;反之,属性离散程度越小,熵越大,信息量越小,所以权重越小。
对于n个包含r维属性的样本,熵值赋权法步骤如下:
1)数据标准化。现实中的数据通常存在量纲的影响,通过计算样本xj第t维属性占所有样本第t维属性的比重将数据压缩到[0,1]:
(5)
其中,xjt为样本xj第t维属性值,j=1,2,…,n;t=1,2,…,r。
2)计算第t维属性的熵值:
(6)
3)计算第t维属性的差异性系数:
qt=1-Et
(7)
其中,qt为差异性系数。
4)计算第t维属性的权重wt:
(8)
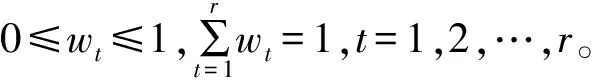
利用各属性权重,给出样本xj和样本xi的熵值赋权欧氏距离,计算公式如下:
(9)
权重系数wt表示各属性对于聚类的重要性,其作用是将各属性对聚类的影响进行放缩,使得对聚类过程影响大的属性权重更大,对聚类过程影响小的属性权重更小。
2.2 邻域隶属度约束
对于聚类问题,样本的隶属度除了与自身特征有关,还受邻域样本隶属度的影响。样本间的空间位置越近,则二者属于同一类别的概率越大。因此,邻域样本对于中心样本所属类别的影响取决于它们和中心样本的空间距离,距离越小,其对中心样本的影响越大,反之距离越大,对中心样本的影响越小。定义邻域样本xk对中心样本xj的影响系数如下:
(10)
其中,dkj表示邻域样本xk与中心样本xj的熵值赋权欧氏距离,熵值赋权欧氏距离能够区分不同属性在聚类过程中的重要程度。从式(10)可以看出,若dkj越小,则zkj越大,此时邻域样本xk与中心样本xj的隶属情况相似度较高,当dkj为0时,二者空间位置相同,zkj取到最大值1;若dkj越大,则zkj越小,此时邻域样本xk与中心样本xj的隶属情况相似度较低。
通过归一化中心样本xj邻域内的影响系数得到邻域样本xk对中心样本xj的邻域隶属度权重,定义如下:
(11)
其中,N表示邻域样本集。显然ωkj∈[0,1]且任意样本的邻域隶属度权重和为1,即:
(12)
根据式(11)可知,影响系数zkj越大,邻域隶属度权重ωkj越大,则邻域样本xk对中心样本xj的隶属度约束力越强。
利用邻域隶属度权重ωkj对邻域内的样本隶属度进行加权求和,得到邻域隶属度pij,定义如下:
(13)

(14)
邻域隶属度pij描述了样本xj的邻域样本对于第i类的隶属情况,pij∈[0,1],pij越大,表明邻域样本对第i类的隶属度越高,则中心样本xj属于第i类的可能性就越大;反之,pij越小,表明邻域样本对第i类的隶属度越低,则中心样本xj属于第i类的可能性就越小。
2.3 NEFCM算法
本文提出的算法称为NEFCM(Neiborhood Constraint and Entropy FCM)算法,其针对FCM算法的改进主要在距离度量和修正隶属度迭代这2个方面,主要思想为:通过计算各属性的熵值来为样本各属性赋予权重,从而改进欧氏距离;在隶属度迭代的过程中,根据样本的邻域隶属度对其自身进行修正,从而有效利用邻域信息,优化FCM算法性能。
结合式(9)的熵值赋权欧氏距离及式(14)的邻域隶属度,在原FCM算法的基础上提出基于熵与邻域约束的FCM算法(NEFCM),该算法的目标函数及约束条件如下:
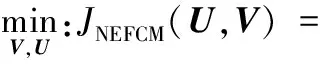
(15)
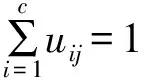
在FCM算法中,聚类过程仅考虑样本与聚类中心的欧氏距离,没能区分各属性对聚类过程的重要程度,同时忽略了邻域样本的信息,无法准确划分边界样本和噪声样本,导致聚类效果不理想。本文算法改进了距离度量,同时利用邻域隶属度约束目标函数,从而修正隶属度迭代过程,提高聚类性能。
NEFCM算法在约束条件下的拉格朗日函数为:
(16)

(17)
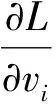
(18)
2.4 算法步骤
输入:聚类数目c、模糊系数m、最大迭代次数T、阈值ε、惩罚因子α
输出:隶属度矩阵U,聚类中心矩阵V
步骤1 初始化迭代次数t=0;
步骤2 初始化隶属度矩阵U;
步骤3 根据式(13)计算邻域隶属度矩阵P;
步骤4 根据式(18)计算聚类中心矩阵V;
步骤5 根据式(17)计算隶属度矩阵U;
步骤6 如果‖U(t)-U(t-1)‖≤ε或t>T,停止迭代;否则,t=t+1,转到步骤3;
步骤7 完成上述步骤,得到最终的聚类中心矩阵V和隶属度矩阵U,据此划分数据集,完成聚类。
3 实 验
为验证本文所提出的NEFCM算法的有效性,分别在人造数据集和UCI数据库中的多个真实数据集上进行实验。
本文实验采用的计算机硬件配置为Intel Core i7处理器(主频3.4 GHz),16 GB内存,Windows 10 64位操作系统,Python 3.7(IDLE)编程实现算法。
本文采用FCM、KFCM、PCM、KPCM及文献[12]提出的DSFCM(Density Peaks and Spatial Neighborhood FCM)算法作为对比算法,并选取2个经典的聚类性能指标:标准互信息(Normalized Mutual Information,NMI)[23]、兰德系数(Rand Index,RI)。定义如下:
(19)
其中,X表示样本真实划分结果,Y表示聚类划分结果。I(X,Y)表示X和Y的互信息,H(X)和H(Y)分别表示X和Y的信息熵。NMI的取值范围为[0,1],越接近于1,聚类效果越好。
(20)
其中,a表示不同类别中不同类标签的样本数,b表示同类别中相同类标签的样本数,n表示样本数。RI的取值范围为[-1,1],同样越接近于1,聚类效果越好。
3.1 人造数据集实验
N3数据集是本文人造的边界模糊数据集,包含3个簇,共400个样本点。同时,为验证NEFCM算法在噪声数据集上的效果,在N3数据集上添加40个噪声样本,主要参数如表1所示。
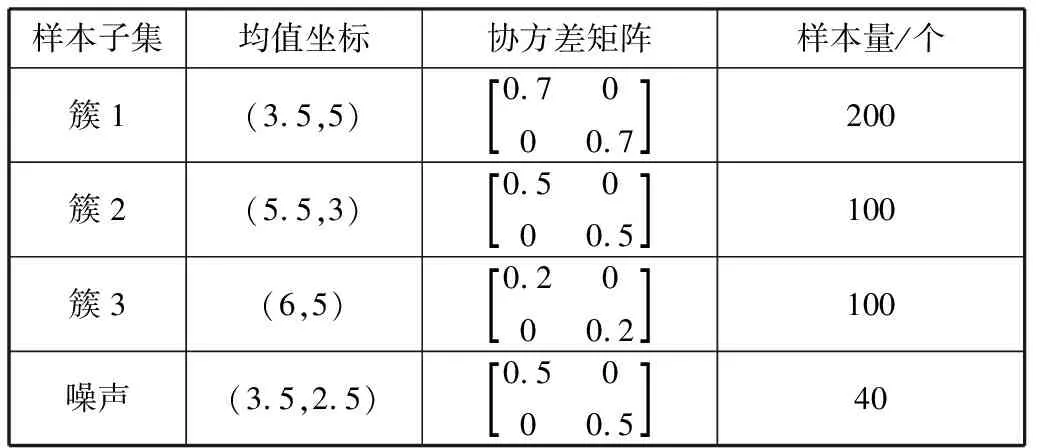
表1 人造数据集主要参数
使用上述2个数据集对FCM、PCM、KFCM、KPCM、DSFCM及本文提出的NEFCM算法进行实验,实验中模糊加权指数m=2,迭代终止阈值ε=1e-5,最大迭代次数为T=500,惩罚因子α=0.9,惩罚因子的取值和样本与聚类中心的距离有关,根据实际情况综合考虑。
图1和图2是6种算法分别在N3数据集和含噪声的N3数据集上的对比实验结果,每个数据都取算法运行10次后得到的平均值。
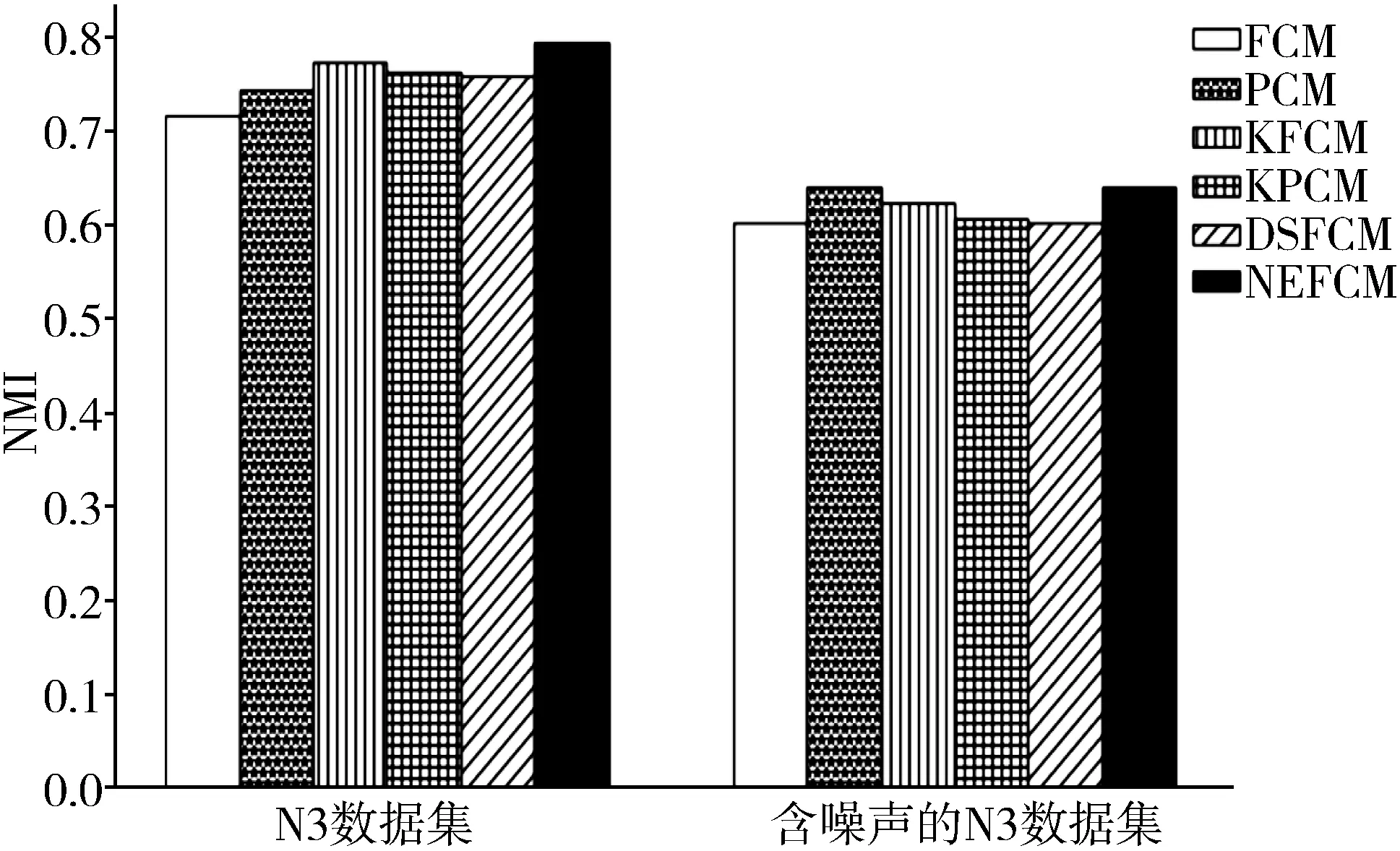
图1 NMI比较
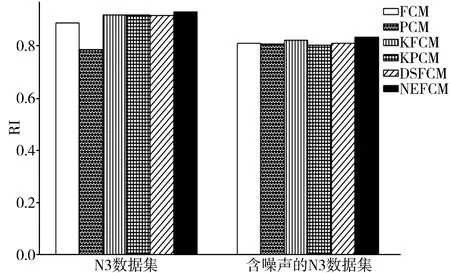
图2 RI比较
由图1和图2可以看出,在N3数据集上,本文提出的NEFCM算法在NMI和RI这2个指标上都优于其他5种算法,这说明NEFCM能够区分各属性在聚类过程中的重要程度,并且有效利用邻域信息,即使在边界模糊的数据集上,也能较为准确地聚类。同时,在加入噪声后,KFCM、DSFCM和NEFCM算法受噪声影响较小,仍能保持良好的性能,其中本文算法表现最优,表明具有较强的鲁棒性。
图3和图4是FCM算法和NEFCM算法在N3数据集上的聚类效果图,可以看到,FCM算法对于簇间边界处的样本错分率较高,而NEFCM算法对这部分样本划分效果良好,原因是2簇边界处的样本与2个聚类中心的距离相差不大,仅根据欧氏距离无法保证正确划分,NEFCM算法通过边界样本的邻域隶属度约束自身隶属度,综合考虑距离与邻域样本的隶属情况,提升了边界处样本的聚类效果。

图3 FCM算法在N3数据集上的聚类效果

图4 NEFCM算法在N3数据集上的聚类效果
3.2 真实数据集实验
上述实验均为人造数据集,为了进一步分析NEFCM算法的有效性,本节选取UCI数据库中Iris、Wine等6个真实数据集进行实验,选取数据集的详细信息如表2所示。

表2 实验使用的UCI数据集 单位:个
沿用FCM、KFCM、PCM、KPCM及DSFCM算法作为对比算法,NMI、RI作为聚类性能指标,每个算法在每个数据集上分别运行10次,取平均值作为实验结果如表3、表4所示。
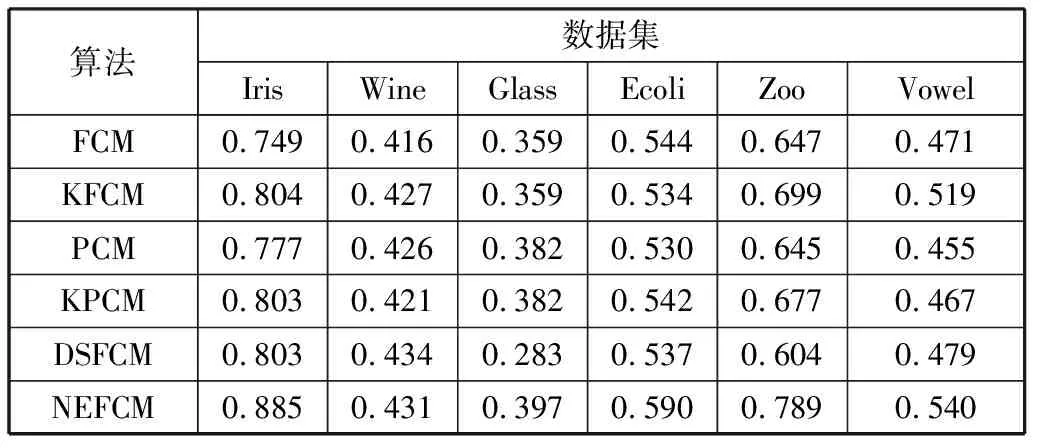
表3 各算法在UCI真实数据集上的NMI对比

表4 各算法在UCI真实数据集上的RI对比
在6个UCI数据集上,从NMI指标上看,FCM算法的平均值为0.531,KFCM算法的平均值为0.557,PCM算法的平均值为0.536,KPCM算法的平均值为0.549,DSFCM算法的平均值为0.523,而NEFCM算法的平均值为0.605,比FCM高出0.074,比KFCM高出0.048,比PCM高出0.069,比KPCM高出0.056,比DSFCM高出0.082。从RI指标上看,FCM算法的平均值为0.743,KFCM算法的平均值为0.8,PCM算法的平均值为0.78,KPCM算法的平均值为0.785,DSFCM算法的平均值为0.79,而NEFCM算法的平均值为0.825,比FCM高出0.082,比KFCM高出0.025,比PCM高出0.045,比KPCM高出0.04,比DSFCM高出0.035。这表明NEFCM算法不仅在处理边界模糊的数据集上展现出良好的性能,同时在处理真实数据集上有着不错的效果,进一步验证了本文算法的实用价值。
3.3 时间复杂度分析
NEFCM算法的时间复杂度主要包含2个部分。第1部分是计算样本的邻域隶属度权重,对于包含n个样本的数据集来说,NEFCM计算n次样本的邻域隶属度权重,因此这部分的时间复杂度表示为O(n×l),其中l表示样本的邻域数量;第2部分来自于算法聚类过程中,NEFCM分别迭代计算隶属度矩阵U、邻域隶属度矩阵P、聚类中心矩阵V,这部分的时间复杂度表示为O(n×c×T),其中,c为聚类中心个数,T为迭代次数。因此,整个NEFCM算法的时间复杂度为O(n×l+n×c×T)。
表5列出了NEFCM算法和其他对比算法的运行时间。从表5可以看出,大多数情况下FCM算法的运行时间比其他5种算法要短,其原因是FCM算法仅考虑样本与聚类中心的欧氏距离,且在聚类过程中仅对隶属度矩阵U、聚类中心矩阵V进行迭代。大多数情况下KFCM、PCM、KPCM算法耗时较高,NEFCM算法在达到最佳聚类效果的情况下,消耗的时间比DSFCM算法略长,但基本上都快于KFCM、PCM、KPCM算法。
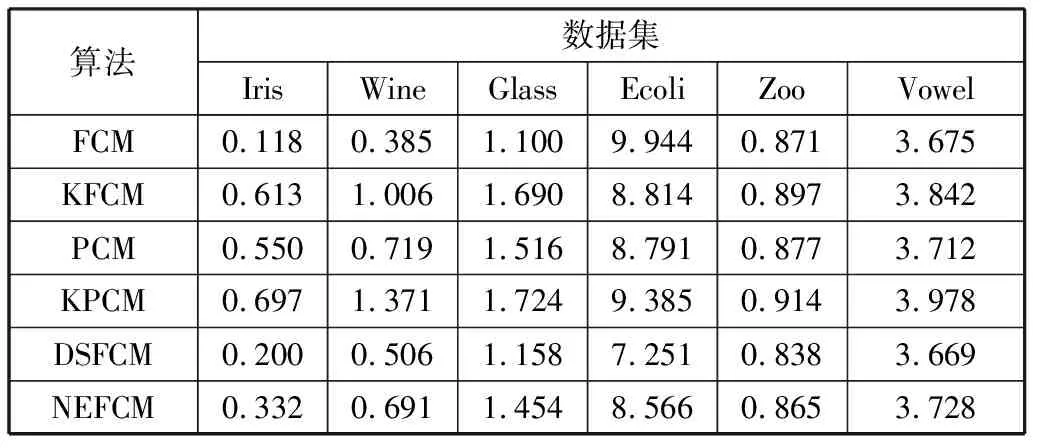
表5 6种算法的运行时间 单位:s
4 结束语
本文针对FCM算法不能区分样本各属性对聚类过程的影响以及未有效利用邻域信息的问题,提出了一种基于熵与邻域约束的FCM算法。该算法首先通过计算样本各属性的熵值来为各属性赋予权重,对距离计算函数进行了改进,然后利用样本邻域隶属度约束目标函数,进而修正隶属度迭代过程,最终达到提升FCM算法聚类性能的目的。本文从理论分析、人造数据集和多个UCI数据集上进行了实验,并与DSFCM、FCM及其他3种FCM改进算法进行了对比分析,验证了NEFCM算法的有效性。
