基于SMOTE和RNN的肾移植排斥反应预测
2021-12-09杨欣怡侯凌燕杨大利崔丽艳
杨欣怡,侯凌燕,杨大利,崔丽艳
(1.北京信息科技大学计算机学院,北京 100101;2.北京大学第三医院,北京 100191)
0 引 言
肾移植排斥反应是移植肾和受者产生免疫病理反应所致病症[1]。由于被移植者和移植者在生理上存在差异,肾移植可能会受到抗体的排异形成排斥反应[2]。术后护理就成为了一个特别重要的阶段,于是便产生了对肾移植的排斥反应预测的需求[3]。在之前,大多数预测使用人工筛选的方法,但手工录入信息绘制图表的方法耗时长,对病人来说,可能随时面临着风险。
现今,疾病预测中常用的几种数学模型的方法有时间序列预测法(Time Series Prediction Method)、灰色预测法、Markov预测法、人工神经网络法等[4]。现今机器学习方法在疾病预测中运用逐渐变得广泛。
肾移植排斥反应预测的难度,在于排斥反应在越早的时间段发现,对于病人的风险也就越小[5]。利用机器学习方法进行肾移植排斥反应的难点在于:
1)样本量不足,这是由于真实进行肾移植手术的病人不多且数据难获取,肾移植手术数据样本数量不足,给研究造成难度。
2)手术前对病人进行周密的调查,排除一些手术风险高的病人,因此有无排斥反应的病人样本数量不均衡。
3)病患的排斥反应数据存在时序性,为了从数据中更好地提炼预测信号,必须对数据的时间序列信息进行分析挖掘,对疾病进行早期的干涉。
针对这3个问题,本文采取如下措施:
1)将数据的分布进行改变。本文使用SMOTE算法,将肾移植排斥反应的样本数据进行上采样,实现样本数量的均衡。
2)选取恰当的预测算法,进行参数的调整和算法的优化。本文选取RNN算法并进行参数的调整优化。
3)选取合适的算法评价准则。不只考虑机器学习算法的角度,还从医学的角度去选取评价准则,从特异性、灵敏度、准确率去衡量[6]。
1 样本特征
围绕肾移植后从病人提取的指标,在前期的调研中发现与肾损伤有重要关联的指标如表1所示。

表1 与肾损伤有重要关联的指标
依据这些指标,可以建立排斥反应预测模型。本文从患者的各项指标中选取8维指标,并利用指标的5维时间维度:8 h、16 h、24 h、48 h、72 h的指标数据组成向量作为循环神经网络的输入向量对肾移植排斥反应进行预测。
2 基于SMOTE与RNN的预测方法
2.1 基于SMOTE与RNN的集成预测方法

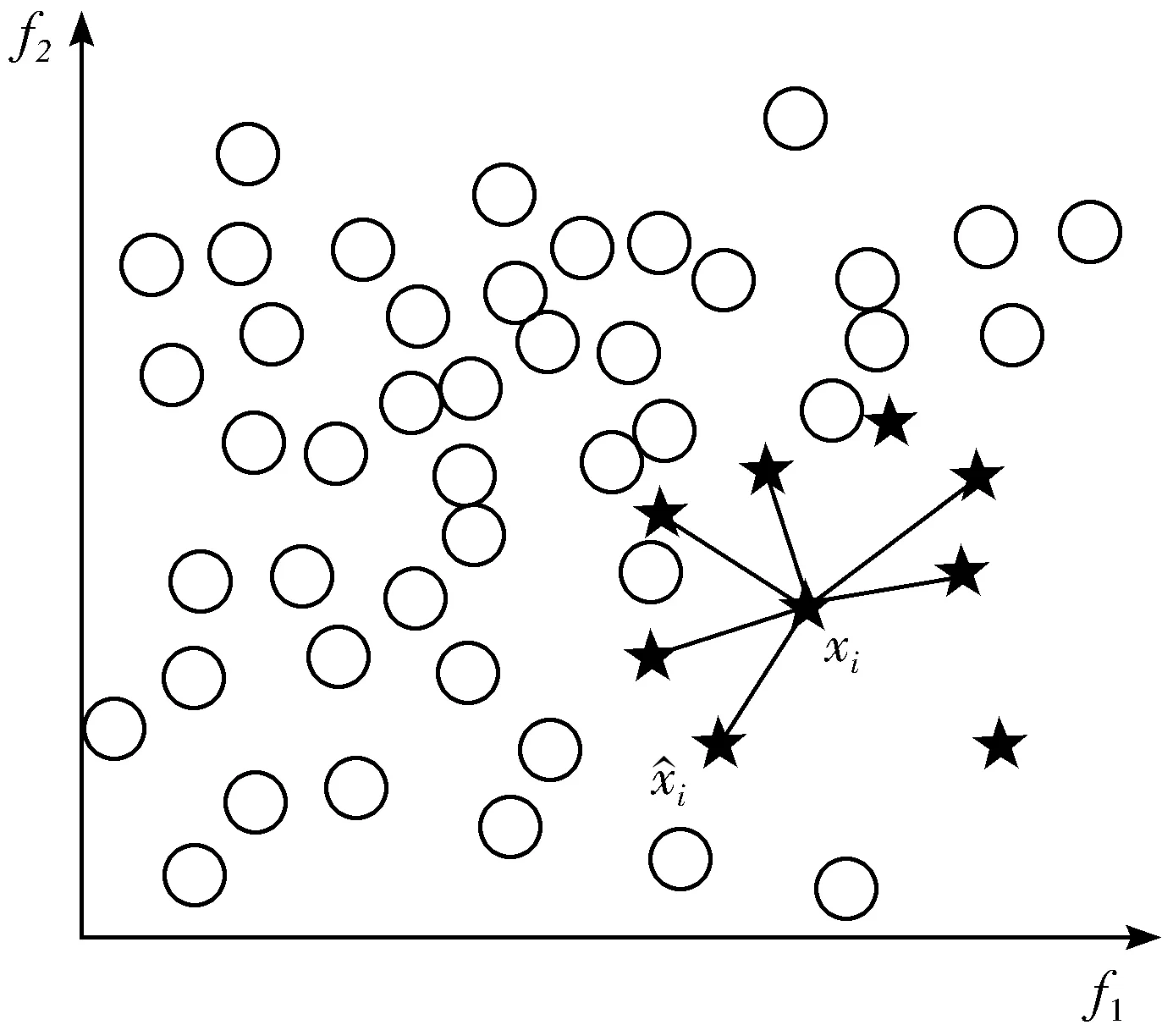
图1 SMOTE算法的原理
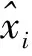
2.2 循环神经网络(RNN)
本文使用算法的结构是N-to-one的RNN结构,这种结构通常使用于序列分类问题,每个隐藏层都有作为输入,每一个xt是同一时间下指标数据融合而成的向量[11]。N-to-one结构的RNN算法结构如图2所示。

图2 N-to-one的RNN结构
图2中,X={x1,x2,…,xt}代表输入的样本集合,也就是输入层;W代表输入层与隐藏层间权重;H={h0,h1,…,ht}代表t时刻的隐藏层的输入;U代表上一时刻和此时刻的隐藏层的权重;V代表输出层与隐藏层间的权重;最终,Y代表输出层的结果。
在当前问题下,RNN的结构可使用公式表达如下[12]:
ht=f(Uxt+Wht-1+b)
Y=Softmax(Vht+c)
公式中的b和c是常数,表示偏置。每次只对最后一个隐藏层状态ht做计算,因此和普通的RNN方法有所区别。每个隐藏层存在神经元,它们会对上一时刻输入的向量做线性变换,随后使用激活函数进行激活[13]。
以E作为交叉熵误差,lr作为网络的学习率(learning rate),以下是权值的更新方法:
图3为在RNN网络中每个节点的结构。
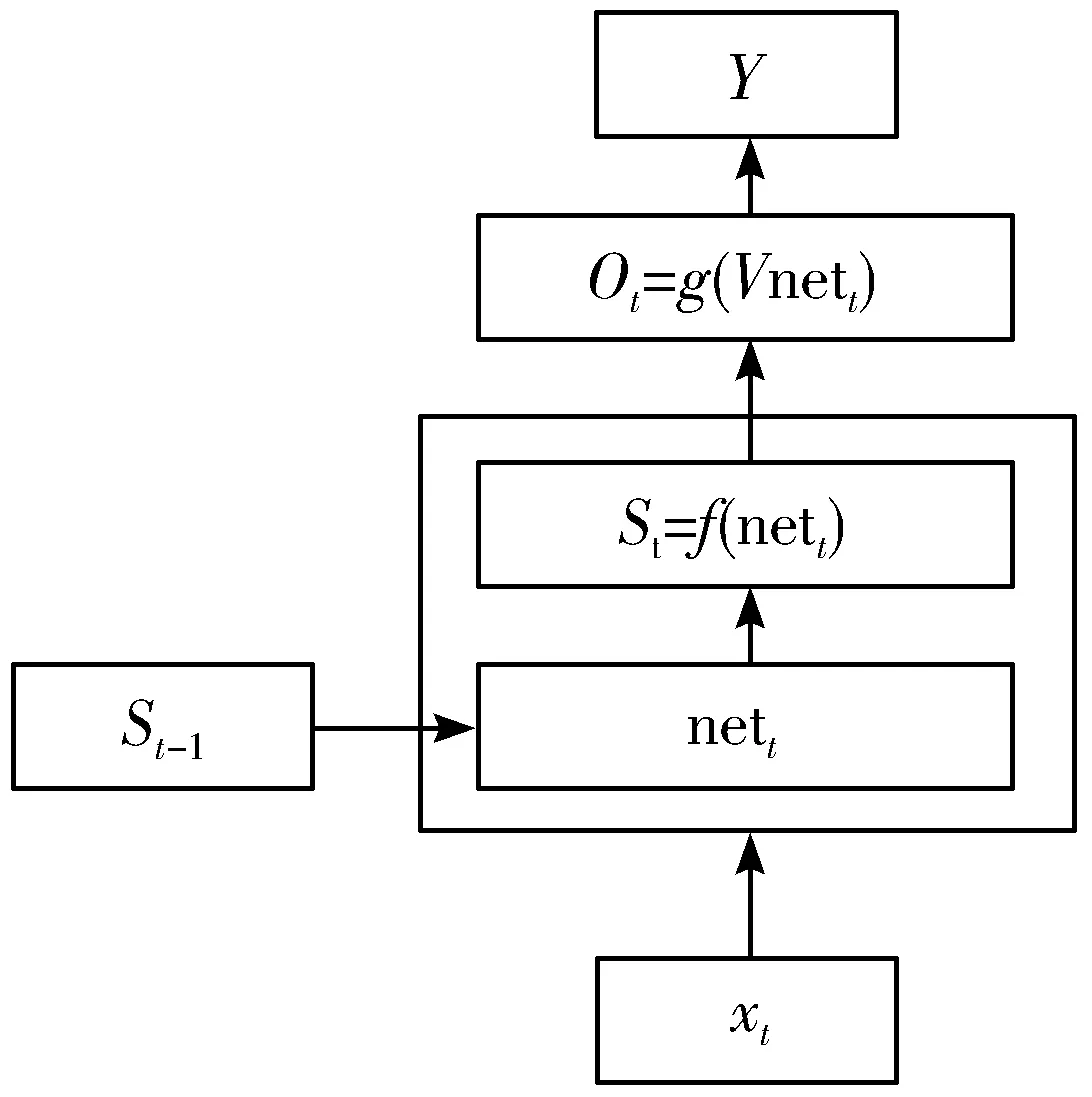
图3 每个节点的运算结构
图3中,St-1是t时刻隐藏层的输入,nett=St-1W+XtU,则经过nett计算后得到t+1时刻隐藏层的输入St与t时刻输出标签Ot。
在使用SMOTE-RNN算法时,具体算法结构如下:
1)依据SMOTE上采样算法计算样本间距离,取临近样本合成负类样本,使样本比例达成1∶1,计算公式为:

2)处理输入层n维数据在m个时间段的时间向量,其中训练集中加入SMOTE算法合成的数据,形成x的形状包含数据编号、输入最大长度以及输入数据。
3)在隐藏层中保存上一时间的隐藏变量,对隐藏层进行Softmax激活。计算公式为:
这一步的目的是将向量转换为概率,t时刻的隐藏层变量由当前时间步的输入和上一时间步的隐藏变量共同决定。
4)激活后的输出向量和样本的实际标签做一个交叉熵,计算公式为:
HY′(y)=-∑iy′ilog(yi)
其中,y′i表示实际的第i个的值,就是激活后的输出向量{y1,y2,y3…}中第i个元素的值[14]。
5)输出的结构为数据编号与预测得到的分类组成的数组。
其中,激活函数的时间复杂度为O(n),则对n行进行激活的时间复杂度为O(n2)。N×n与n×d运算作为加权和,得到n×d矩阵,复杂度为O(n2d)。所以最后RNN网络计算的算法复杂度是O(n2d)[15]。
3 实验与结果分析
3.1 实验数据
本次实验选取的数据样本由北医三院采集获得,均为肾移植手术后的真实数据,如表2所示。
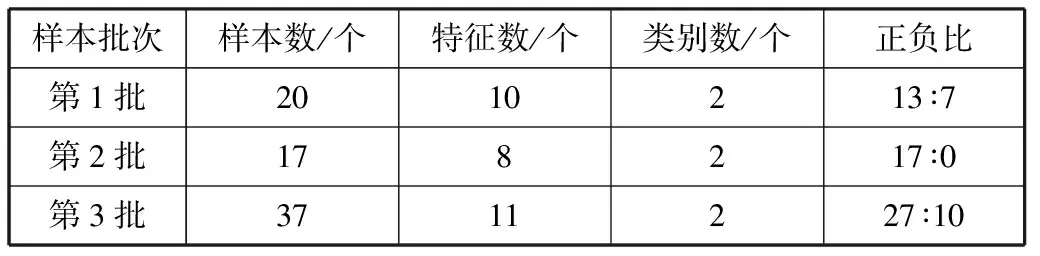
表2 肾移植排斥反应数据样本
实验选取了所有指标中的8种,分别为KIM-1、L-FABP、mAlb/Cr、nag/Cr、cystatin C、b2-MG、ngal、IL-18共8种尿液标志物,将每个病人的5个时间维度的数据相结合,组成一个向量作为训练网络的输入。将输出分为2类,“-1”表示阴性样本,“1”表示阳性样本。前期的数据处理分为以下几步:1)去除存在数据缺失的数据;2)对数据分组标记;3)对数据进行归一化,保证运算时算法的效率。
本文使用了八折交叉验证的方法来验证本文算法的效果,因此训练集和测试集数据的比例是7∶1,交叉进行8次。
3.2 RNN函数定义及参数
本网络中定义了3个占位符,这为模型提供了输入输出数据:X表示输入的数据集合,Y表示输出的分类结果。seqlen表示输入数据的个数。
本文使用TensorFlow框架进行实验方案的编写。首先,定义一个LSTM_cell[16],它是一个长短时记忆单元的循环网络单元,使用tf.nn.dynamic_rnn进行时间维度的扩展。接着,使用函数dynamic_rnn,它可以用来实现递归神经网络(RNN)。输入数据X,然后使用tf.nn.dynamic_rnn运行cell,相当于调用max_seq_len次call函数[17]。由于时间序列为5个时间段,应使用第5隐藏层的输出来计算分类。在TensorFlow中,不能直接使用seqlen获取相应位置的输出,因此需要定义一个索引变量与tf.gather函数获取相应位置的输出值。最后,再利用之前定义的权值和偏离率(bias)对输出值进行变换,得到logits进行分类,logits表示模型未进行缩放前的返回值,也就是进入Softmax函数之前的值。之后,就可以使用它和正确的分类Y来定义损失和训练[18],此处的Y就是数据集中的分类。
RNN参数值的设置对训练效果影响很大,因此在定义时需要结合理论知识及实验情况进行调整。表3为使用控制变量法得到的实验准确率结果。
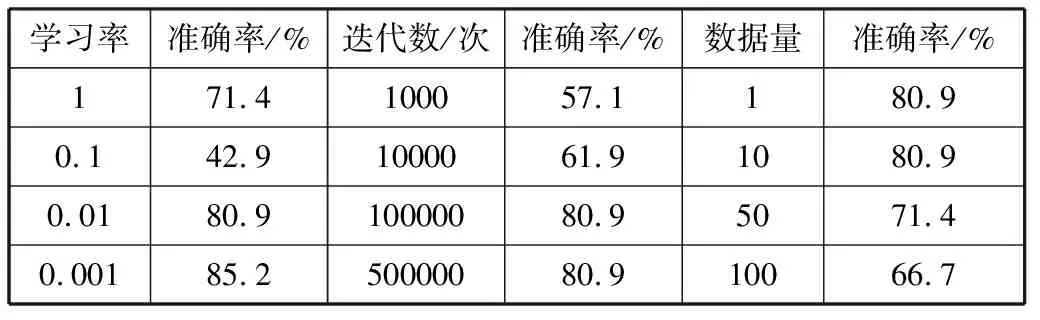
表3 使用控制变量法测试各参数设置的实验效果
经过综合考虑,此次训练的参数确定为learning_rate=0.01、training_iters=100000、batch_size=10、display_step=10。
3.3 预测准确率的检验方法
在医疗评价指标中,特异性(Specificity, SPE)、灵敏度(Sensitivity, SEN)和准确度(Accuracy, ACC)是常见的评价指标[19]。以下是3种评价指标的计算公式。
其中,真阴性(TN)代表阴性数据的真分类,即为未发生排斥反应的数据被划分正确的数据。真阳性(TP)代表阳性数据的真分类,即是发生排斥反应且被划分正确的数据。而FN代表假阴性样品,最后使用FP代表阴性样品的假分类。换句话说,TN、TP、FN和FP分别对应于正确拒绝、正确识别、不正确拒绝和错误识别[20],具体解释如表4所示。
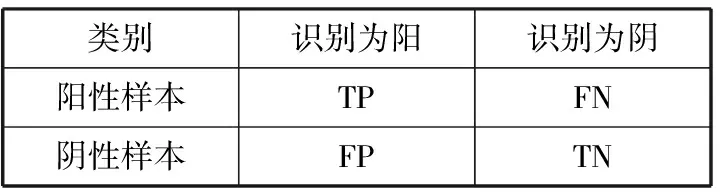
表4 数据集分类混合矩阵
性能指标SEN、ACC和SPE可用于生成可靠的结果估计。另外,还引入相对错误率(Relatively Classified Fault Rate,RCFR)作为评价指标。
3.4 实验结果分析
肾移植排斥反应样品分别使用马尔可夫预测法及RNN预测法这2种方法进行对比实验,在实验时,根据数据特点分别增加实验:根据3个时间段的指标进行预测实验、根据数据变化率的预测实验、根据数据变化量的对比试验。对比实验的加入是为了消除个体差异[21]。经过几组实验后,实验结果如表5所示。
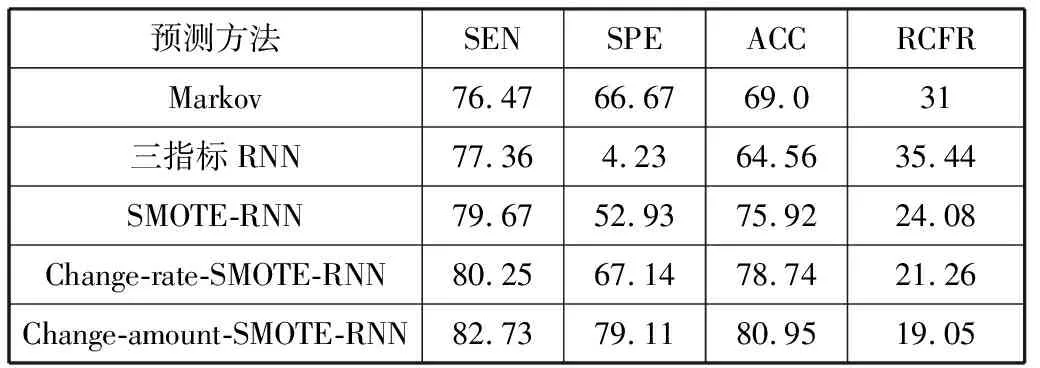
表5 各预测方法的特异性、灵敏度、准确度、相对分类错误率对比 单位:%
由实验结果可以发现:
1)通过本文方法得到的预测算法的准确率达到了75.92%,与马尔可夫分类模型相比更优。
2)数据本身的数据量不充足且正负比例不够均衡,导致其特异性相对较低,实际预测效果并不是非常理想。
由于在肾移植排斥反应预测中,对于阳性的病人误诊,很有可能耽误病情,甚至危及生命,因此需要对参数进行调整并增加对阳性样本的识别率。使用数据变化率进行预测的准确率达到了78.74%,使用数据变化量准确率达到了80.95%。实验结果表明,通过数据变化量的方法进行预测时,准确率达到最大。这可能是由于使用数据变化量会放大数据变化的特征,从而使算法的预测效果更明显。
在进行SMOTE-RNN实验预测法时,部分会发生肾移植排斥反应的数据在前3个指标便可以顺利预测出来,于是可以在这之后进行拓展方案:前3个指标预测为排斥反应时,可以将肾移植排斥反应判断为超急性排斥反应[22]。5个指标预测出排斥反应时,可判断为急性排斥反应。按此进行分类减少病人因未及时救治而使病情加重的风险[23]。
从之前的实验结果可知,使用数据变化量预测的准确率最高,因此使用基于数据变化量的SMOTE-RNN预测法进行3个时间段的预测,结果如表6所示。
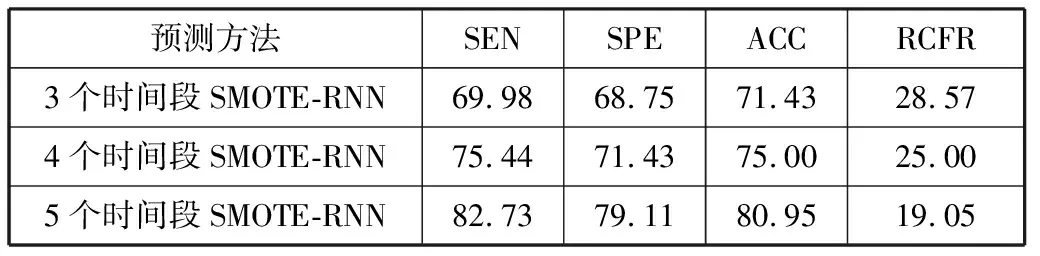
表6 基于3种时间段数据变化量预测的特异性、灵敏度、准确度、相对分类错误率对比 单位:%
由表6可见,在数据时间段分别在24 h/48 h/72 h时,使用RNN进行排斥反应的分类预测,特异性、灵敏度、准确度均有提升。也就是时间段越多,网络对于肾移植排斥反应的预测就越准确[24]。本次验证的74个样本中的17个负类样本中,10个样本被分类为超急性排斥反应,还有4个病例在24 h内未检测出存在排斥反应,在24 h后检测出排斥反应,因此被划分为加速性排斥反应,结果如表7所示。
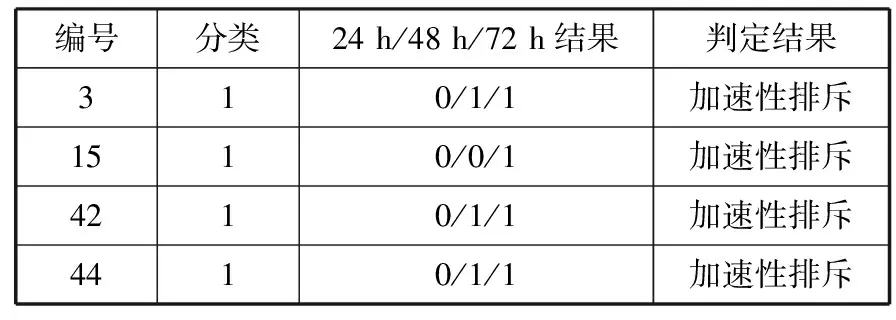
表7 被判定为加速性排斥反应的病患
经过分析,该4名病患在24 h内身体各指标的数值居高不下,在48 h后有所好转,表明该方法可以有效地为病人的排斥反应分级,有限筛选出超急性排斥反应的病患。
4 结束语
本文针对肾移植排斥反应的数据特点,提出了一种基于SMOTE和RNN结合的方法,先使用SMOTE算法,通过取近邻的负类样本,随机合成部分少数类样本,降低了正负样本间的不平衡度,然后对RNN网络中的激活函数进行了研究,最后对网络的关键参数的选取进行研究和实验,并针对特异性低的实验结果选择了数据增长率和数据增长量的预测实验。实验结果表明,当使用肾移植排斥反应的变化量进行RNN算法的预测时,准确率达到了最高,与传统的马尔科夫预测法相比,准确率提高了11.95百分点,特异性提高了12.44百分点,这表明阳性样本的准确率有相当大的提升,使用机器学习方法可以有效地对肾移植排斥反应进行预测。
