基于MapReduce微博数据清洗的研究与实现
2021-12-09王国珺
王国珺,林 峰
(福州职业技术学院 福建 福州 350000)
1 引言
采用任何方式抓取到的微博评论数据通常比较乱,其中有一些无用信息,而我们的目标是只提取其中的中文文字内容,因此抓取的数据在分析之前,必须进行清洗。数据清洗分为3个步骤,即抽取、转换、加载。当数据量增大时,传统的清洗技术已无法满足企业之间的技术支持,所以本文结合MapReduce分而治之的思想设计出分布式数据清洗系统[1]。
2 微博数据的理解
微博数据首先是以半结构化XML格式存储的,每个评论版块内容用


再看中间的具体内容结构,存储格式如下:
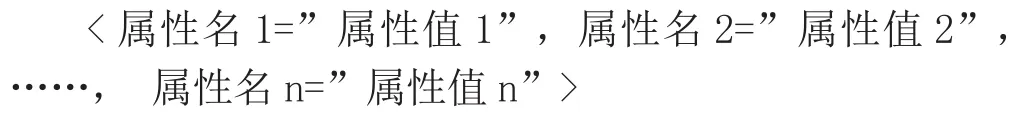
其中每对标签中对应的属性名个数并不一致,属性值用双引号(””)进行标识,属性值内容中也出现双引号内容时,用转义符号" "替代。如下面两行数据的举例中,有的属性值中有Score(评分)项,有的记录中没有。

3 微博数据清洗业务
微博数据统计分析中,对于某类评论内容较多,每天或每天中某时主题帖子评论的数量及长度,或哪些用户较活跃等,这些都需要将数据从XML存储的格式中提取出来,例如哪些内容是哪个主题的,每一条评论内容中指定属性值的提取等。该微博数据的结构决定了数据清洗大体是分两种情况。
情况1:针对XML标签进行主题清洗。
将不同主题数据以不同目录的形式生成,针对每个目录下存储相应主题的评论内容,即每对
情况2:针对<属性名1=”属性值1”>键值对数据的清洗。
获取内容指定属性值,例如获取Text(评论内容)或CreationDate(评论时间)的值。由于标签是成对出现,每个值用双引号进行标签,我们可以试着应用Map集合的方法进行提取。
4 微博数据清洗过程的实现
为了实现该微博存储结构数据清洗的目的,首先需要当前运行的Hadoop的分片API查询,看是否存储已有的功能接口可以实现我们的需求。本案例借助对系统要求较低的Eclipse免费工具进行编写,具体实现过程主要分3个大任务[3]。
任务1:Eclipse下建立项目并准备实验数据。
主要完成项目编程过程的前期准备工作,主要分两步完成:第1步:Eclipse下项目建立。例如建立一个名这BlogsCleanMRProject的项目。
第2步:实验数据准备。可将数据暂时放入当前项目的根目录下。
任务2:编写MapReduce程序实现XML数据清洗。
第1步:自定义分片的编写。
主要完成自定义RecordReader类(命名为XMLRecord Reader.java)和自定义InputFormat类(命名为XMLInput Format.java)的创建。Src下出现了设置的包名,包名下多出新建立的类文件XMLRecordReader.java,并且该文件在Eclipse工具中央窗口位置打开,可以在此进行代码的编辑,见图1。

图1 编程窗口
编写XMLRecordReader类文件程序,部分参考代码如下。


第2步:编写Mapper类实现XML指定标签内容读取与数据分箱。
(1)选中项目下包名com.apache.hadoop.mr.split,鼠标右键,依次选择New->class选项,在弹出的New Java Class窗口中配置包名和类文件名XMLMapper,单击Finish按钮。见图2。
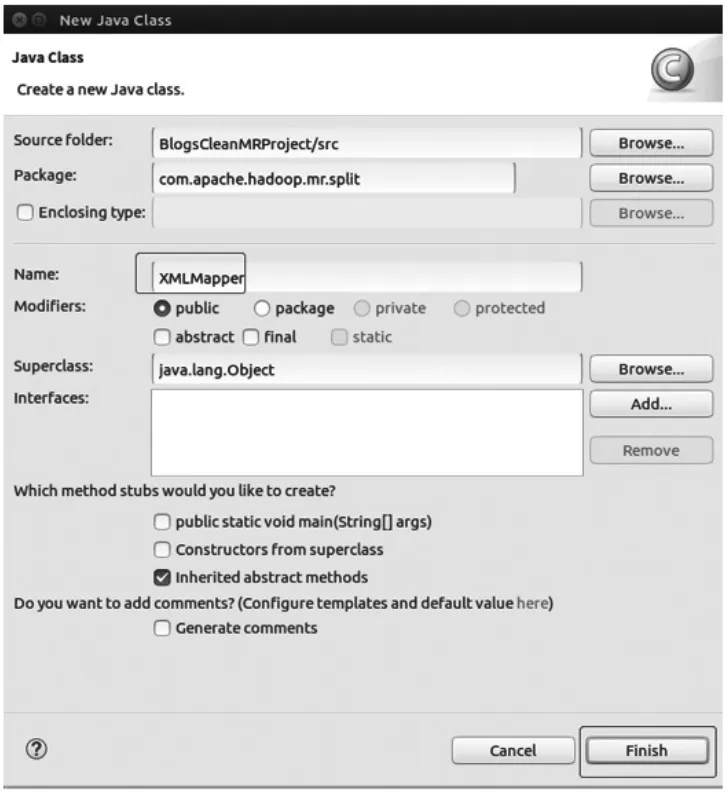
图2 配置XMLMapper
(2)在新建立的XMLInputFormat类文件中编写程序,参考代码如下。


任务3:编写MapReduce程序实现评论内容属性值的解析。
任务2中实现了Mapper中map方法读取的是一条一条的对应的值,即每一条评论的内容,这些内容是以<属性名1=”属性值1”,属性名2=”属性值2”,……,属性名n=”属性值n”>成对的方式出现的,每条数据量在本地Hadoop集群的节点中的Mapper进程中运行是绰绰有余的,故只需要编写一个解析<属性名1=”属性值1”>对的方法即可。由于中值的属性对个数并不统一,例如有的有Score评分项,有的没有,所以可将解析出来的内容以键值对的方式存储入集合中,供程序调用即可,故本任务实现过程主要分3步[4]。
第1步:编写解析每条评论内容的类文件,例如MRUtils.java。即将中值中每对属性的解析出来,以键值对的方式存储入集合中。
第2步:编写Mapper类读取评论中指定属性Text和CreationDate的值。在任务2的基础上在Mapper类中调用,并通过MRUtils类解析中值中每对属性值,做这map的K-V传入上下文中。
第3步:编写Job类运行MapReduce程序。在当前Eclipse工具的Hadoop环境下运行编写好的MapReduce程序,并观察运行过程,查看运行结果,验证程序正确执行。
5 结论
案例主要完成Eclipse工具下编写MapReduce程序实现微博数据的清洗工作。整个程序编写的过程中并不需要开启Hadoop环境,好处是节省系统资源,使程序编写调试过程更加流畅。实际应用时,可将写好的程序打成Jar包,启动Hadoop平台后,在Hadoop平台上运行。
