改进的深度编码器在多模态特征学习中的应用
2021-12-09徐凤平
徐凤平
多模态特征学习的关键在于如何挖掘不同模态之间的关联性.目前有许多基于传统统计机器学习的多模态数据分析方法,如支持向量机SVM、Latent Dirichlet Allocation(LDA)、Independent Component Analysis(ICA)等.这些方法都属于浅层模型,对高维关联的挖掘存在困难,很难获得准确的多模态特征表示.目前主流的基于深度学习的多模态特征融合模型往往采用单融合点结构,它们在最顶层空间仅仅进行了一次模态交互.
早期的研究人员主要是采用基于浅层模型来挖掘模态间的关联性.BLEI等人针对多模态检索问题的特点提出了面向“文本-图像”多模态数据的相关LDA模型[1].XING等 人提出了一种基于特殊的无向图模型的双翼式模 型(Dual Wing Model)[2].RASIWASIA等 人 提出了一种基于典型关联分析(Canonical Corre⁃lation Analysis,CCA)的多模态特征融合模型以进行跨模态检索[3].这些多模态特征学习方式可以归类为由一到两层结构组成的浅层模型.由于来自于不同模态的数据之间的数值形式及统计特性相差巨大,所以在浅层模型结构定义的低维空间中,不同模态数据特征之间关联性的耦合度不高.
随着深度学习的不断发展,神经网络在挖掘文本、图像等模态高维特征上的优越性充分得到了体现.SU等人使用LSTM和CNN搭建了一套基于音频和图像特征的多模态深度学习系统(audio-visual speech recognition sys⁃tems,ASVR),学习音频和图像间的跨模态关联[4].HU等 人借鉴循环 神经网络(Recurrent Neural Network,RNN)的思想,对传统的多模态受限玻尔兹曼机进行改进,提出了循环多模态受限玻尔兹曼机(Recurrent Temporal Multimodal Restricted Boltzmann Machine,RTMRBM),解决图像语音识别问题[5].HOU等人提出了基于CNN的多模态深度卷积神经网络强化学习,提高了语音和图像识别的准确率[6].
笔者认为,不同模态之间的关联性是立体的,不只是存在于顶层的高维空间.因此目前的方法存在对模态间关联性及其交互作用挖掘不充分的问题.目前的多模态特征学习方法采用的都是传统特征,如图像的sift和cedd及文本的lda和one-hot-representation等,这些特征包含的语义信息较少且不同模态的数据在数值形式、特征分布等方面相差巨大,影响了最终特征的性能.
为了解决上述问题,本文提出了一种基于多融合点深度神经网络的多模态特征学习.主要内容有:提出一种基于自编码器的多模态特征学习模型,在特征学习阶段,设计一种基于多融合点的特征学习网络结构;在训练阶段,设计了一种多通路解码网络结构,用输入自适应的交替式网络训练策略指导网络的训练;最后本文在多模态特征学习领域常用的多个数据集上进行实验,将模型输出的多模态特征应用于检索场景,用数据检索方面的性能指标作为评价指标,验证论文工作的有效性.
1 基于自编码器的多模态特征学习模型
1.1 多模态特征学习的总体框架
多模态特征学习过程可以分为三个阶段:第一阶段为特征提取及标准化阶段,首先通过基于大规模数据集训练出的CNN模型和Word2vec模型抽取图像和文本特征,然后通过一系列标准化措施使得两个模态的数据特征空间拥有相近的数值形式及统计特性,作为第二阶段的输入.第二阶段为多模态特征学习阶段,将不同模态的数据特征输入文中提出的基于多融合点结构的多模态特征学习网络进行特征学习.第三阶段为网络训练阶段,通过相关的目标函数指导模态内的数据关联性,以及模态间的数据关联性的挖掘.具体如图1所示.
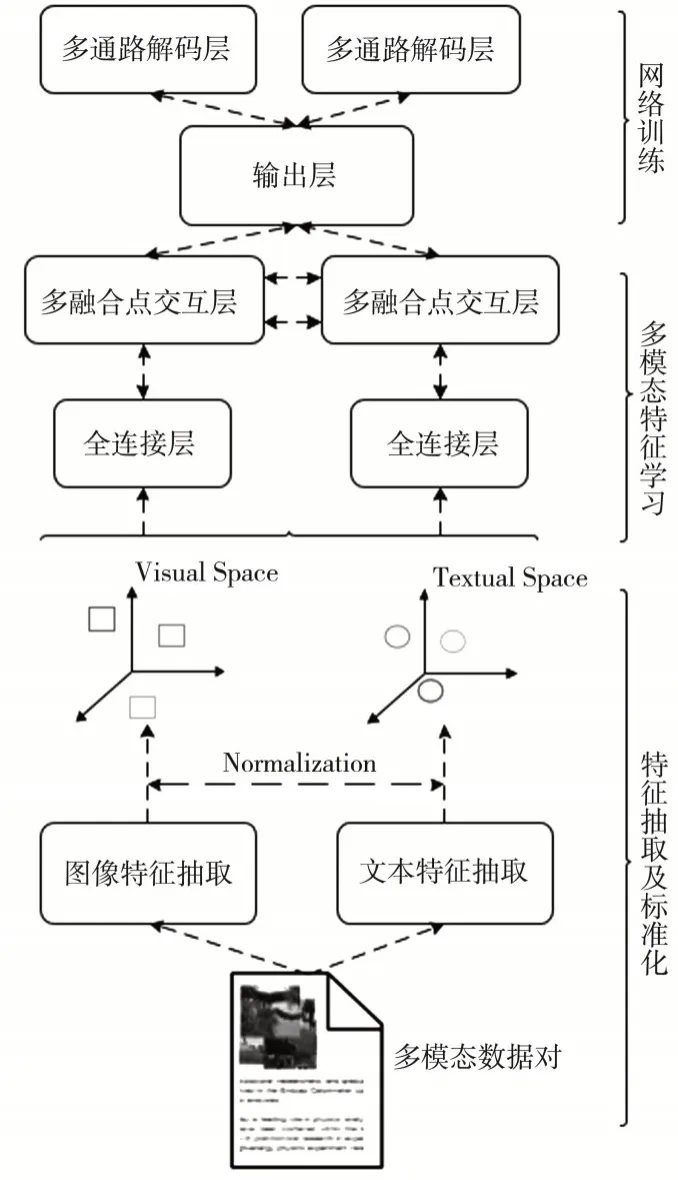
图1 多模态特征学习模型总框架
1.2 基于多融合点的多模态特征学习网络结构
多模态特征学习的关键在于如何有效地挖掘不同模态之间的关联性.目前有共享融合层自动编码器和独立通道自动编码器两大类结构,但它们仅仅在中间编码层中进行了一次跨模态交互.笔者提出一种基于多融合点的多模态特征学习网络结构,以单融合点多模态自动编码器模型为基础,在网络的不同层次设置多个融合点用来学习模态间的关联关系,并将这种关联关系从低维到高维递进地传递下去,使得不同层次特征空间中的数据都参与模态内及模态间语义关联挖掘.
多模态特征学习网络具体结构如图2所示.在网络层前采用了深度特征引入分布标准化措施,网络层包含了全连接层和多融合点交互层.深度特征使用Caffe深度学习框架中提供的基于ImageNet训练CNN模型提取图像特征;使用Wikipedia提供的开源语料集训练Word2vec模型提取文本特征,将特征提取模型的输出维度设置为相同值[7-8];采取Mean Cancellation、KL Expansion和Covariance Equalization等一系列分布标准化措施.全连接层先将两个不同模态的数据特征映射到相近的高维空间,然后在相对高维的特征空间中进行跨模态关联挖掘,减小了由于引入多融合点结构而带来的额外噪音,提高了跨模态语义关联挖掘的效果.多融合点交互层包含两种数据通路,分别是模态内数据通路(In⁃tra-modal channel)、模 态 间 数 据 通 路(Intermodal channel),其中模态内数据通路接受单个模态数据输入,负责将单个模态数据特征从低维向高维逐层映射,获得单个模态在多个特征空间中的特征表示.对于每个模态p,其第l个隐层的模态内数据通路特征计算方式为:
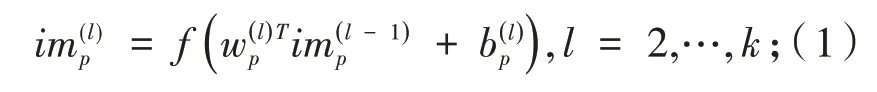
其中:f为激 活 函 数,w为连接权重,b为偏置参数.

图2 改进的多融合点特征学习网络
模态间数据通路即设置的多个融合点,通路中的每一层同时与两个单模态内通路的输出,以及前一层模态间通路的输出相连(第一层除外),其作用是在网络的各个层次挖掘两个模态数据特征的语义关联性,并将这种跨模态语义关联性逐层传递下去.在顶部的输出层形成编码阶段的最终输出.基于多融合点结构形成的模态间数据通路,可以让网络的多个层次参与到多模态特征的学习过程,强化了模态间数据的交互作用,丰富了最终生成的多模态特征包含的语义信息.对于模态p及模态q,网络第l个隐层的模态间数据通路特征计算方式为:
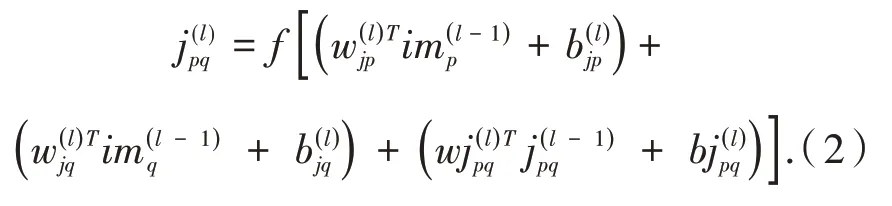
1.3 多模态特征学习模型的训练策略
对于多模态特征学习这一实际应用场景,定义了相应的模态内、跨模态相关损失函数并提出输入自适应的交替式训练策略指导模型的训练,确保了论文提出网络结构的合理性及可行性.
定义模态内相关性(intra-modal correlation)和跨模态相关性(cross-modal correlation)两个目标函数.
模态内相关性.借助解码的训练方式,以输出层为起点进行解码,重构两个模态原始的输入特征,通过计算原始特征与重构特征之间的损失来衡量输出特征的模态内关联性.
给定双模态数据对(xinz,xtnz),其中图像和文本特征都非空,记重构后的特征输出为(x′i,x′t),则模态内相关性定义为:
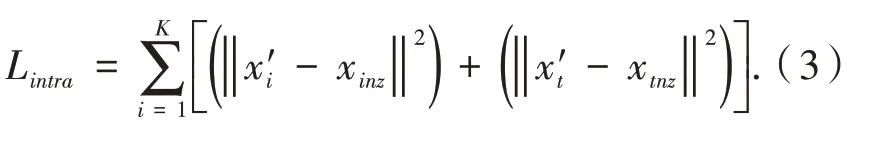
跨模态相关性.进一步挖掘不同跨模态的关联性,给定一个模态的数据输入,由模型还原得到模态的特征输出,将模态的重构特征与期望特征之间的距离定义为模态间关联性.
对于双模态数据对(xinz,xtnz),其中图像和文本特征都非空,固定一个模态特征,将另一个模态特征置为0,得到(xinz,xtz)和(xiz,xtnz)两个单模态数据对.以(xinz,xtz)为例,此时图像模态数据非空,文本模态数据为空,在仅有图像模态输入的前提下,重构后的文本特征输出为,计算重构特征与原始特征xtnz的距离作为跨模态相关性.

对于上文提出的两个目标函数而言,模态内相关性旨在训练网络的重构输出准确还原输入的数据特征,而模态间相关性则是训练网络由一个模态数据发散推出另一个模态的数据.为了解决两个目标函数不兼容导致单通路解码网络训练震荡的问题,本文提出了一种多模态特征学习场景下的解码网络模型,以堆自动编码器为基础,对两个目标函数采取了多解码通路的设计.为每个模态数据设计两条解码通路,分别负责计算模态内相关性和模态间相关性,如图3所示,以“图像-文本”多模态数据为例,解码网络包含四条通路,分别记为模态内图像通路(intra-image channel)、模态间图像通路(inter-image channel)、模态内文本通路(intra-text channel)和模态间文本通路(inter-text channel).
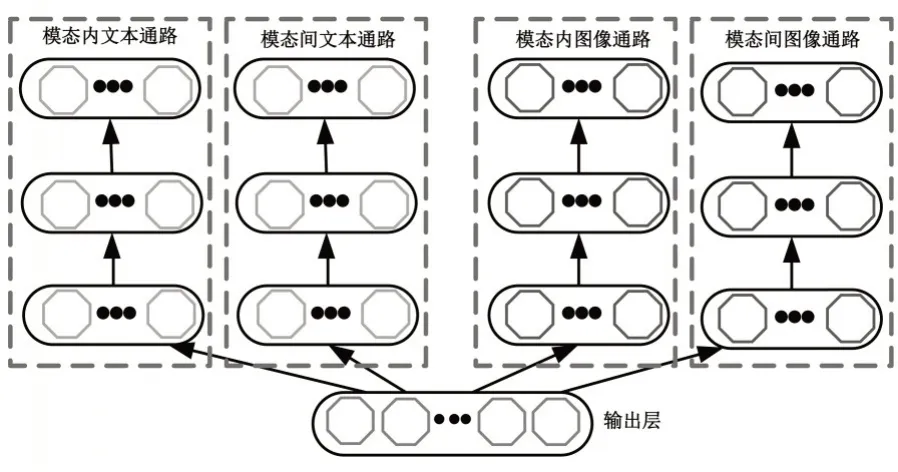
图3 多通路解码网络结构
多通路解码网络结构可以根据不同的输入场景选择对应的解码通路和目标函数进行参数的调整.具体而言,给定一对双模态数据(xinz,xtnz),为了训练网络的跨模态发散性,将其拆分为两组单模态数据(xinz,xtz)与(xiz,xtnz).以(xinz,xtz)为例,此时输入图像模态的数据为原始数据,而文本模态的输入置为0,重构层的期望输出仍为已知的双模态数据(xinz,xtnz).对应于模态间关联性的场景,此时选择“模态内图像数据通路”和“模态间文本数据通路”,计算两条通路的重构输出与原始双模态数据(xinz,xtnz)之间的距离作为损失进行网络的训练及参数的更新,选择的数据通路情况如图4所示.
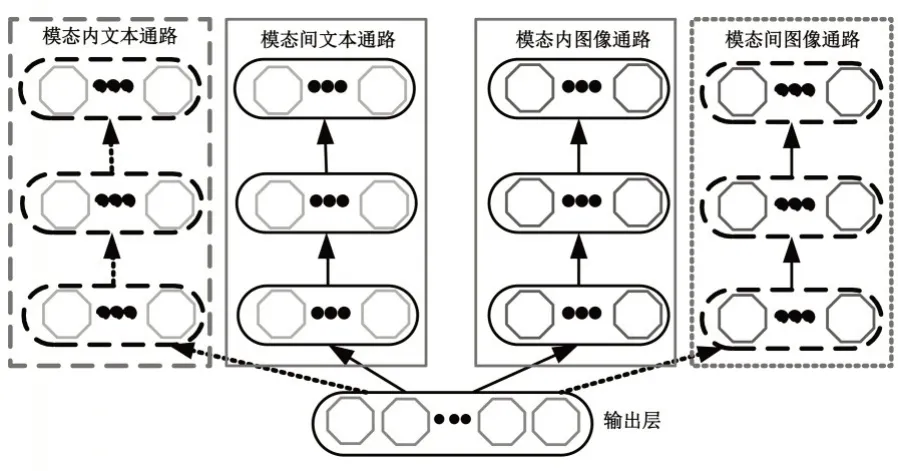
图4 跨模态发散性训练
输入为图像空文本非空(xiz,xtnz)的通路选择情况同理可得.
为了训练模态内数据关联性,此时输入为(xinz,xtnz),表示两个模态数据都非空,解码网络旨在还原两个模态的原始输入,对应于模态内关联性的场景.因此选择“模态内图像数据通路”和“模态内文本数据通路”,计算两条通路的重构输出与原始输入之间的距离进行网络的训练及参数的更新,对应的数据通路如图5所示.
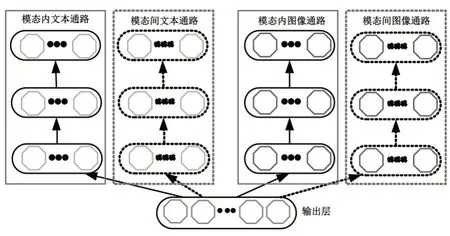
图5 模态内关联性训练
基于以上分析,多通路解码网络为每个模态设计了两条通路,分别用于计算模态内关联性和跨模态发散性.为了进行有效训练,需要扩充原始的双模态数据集,将双模态数据集进行拆分,从每一对多模态数据集中拆出两组单模态数据对加入到原始训练数据集,生成新的训练数据集X′.在网络训练阶段,网络的输入数据有可能是双模态数据对(两个模态的数据都为非空值),也有可能是单模态数据对(其中一个模态非空,另一个模态为空).在迭代训练过程中,以mini-batch为最小单位,在每一次迭代开始时,随机打乱数据对的分布(保证每一个mini-batch内的数据都是同类型的).首先判断这一批数据的输入形式,自适应地选择对应的解码通路及目标函数计算相关损失,然后将误差反向传播,从而进行神经网络的参数调整.兼顾模态内关联性和跨模态发散性的同时,达到根据不同输入自适应地选择合适通路的目的.
训练策略算法如下:

2 实验及分析
2.1 数据集和评价指标
主要有三个数据集,分别是Mir Flickr、Nus-wide和Pascal Sentence.
Mir Flickr一共包含1 000 000张从社交图像网站Flickr上爬取下来的图像,以及对应的用户附属的标签信息,每张图像的平均标签数是6个.在这1 000 000张图像中,有25 000张图像被人工标注到24个类别.对于有标签的25 000对数据,有4 551张图像没有对应的文本数据,20 449对数据是双模态都齐全的.在实验中,对无标签数据进行网络的训练,从这20 449对数据对中随机选取了5 000张图像作为测试集进行相关测试.
Nus-wide是一个网络图像数据集,共包含269 648张图像及其对应的文本标签.这些数据对一共被分成了81个类,每对数据至少属于其中的一个类.在实验中,筛选出至少包含5个文本标签的数据对,对每个类按照其类内数据对的个数进行排序,并选取了数量最多的前20个类作为测试集.
Pascal Sentence数据集包含20个类,共1 000对图像/文本数据,每个类包含50个数据样例.这些图像是从PASCAL 2008 development kit中随机选择的,每张图像都有5个描述性的句子描述图像内容.由于数据集规模较小,在实验过程中,将每张图像的每个描述性句子与该图像组成一对多模态数据对,将数据集规模由原始的1 000扩充为5 000.在实验中从每个类中随机选择了200对数据组成训练集,剩下的1 000对数据作为测试集.
由于模型的性能无法直接度量,将模型学到的多模态特征的检索性能作为模型性能的评价指标,包括准确率(Precision)、召回率(Recall)、MAP(Mean Average Precision).
准确率(Precision):在进行检索请求时,返回的结果中与query属于同一类别的样例数目与总返回样例数目的比值:

召回率(Recall):在进行检索请求时,返回的结果中与query属于同一类别的样例数目与库中该类别样例总数的比值:

MAP:多次检索的平均准确率的均值.MAP能够结合准确率与召回率综合评估检索系统的检索性能.
2.2 多融合点结构设计的有效性评估
2.2.1 实验设置
为了验证论文提出的多融合点交互层在强化模态间语义信息挖掘方面的有效性,以单融合点网络结构为基础,保持整个网络的层数固定不变,改变多融合点交互层的起始位置得到多个模型,通过实验对比这些模型的性能,进而验证多融合点结构设计的有效性.
进一步地,为了确保实验的全面性,对同一的实验数据集提取多种不同类型的特征,分别在单融合点模型及多融合点模型上进行了多组实验,通过模型输出的多模态特征的检索准确率及召回率比较现有单融合点特征学习网络与论文提出的多融合点特征学习网络的性能差异.
在实验中,固定网络层数为五层,各层节点数设置如表1所示.

表1 网络节点设置信息
2.2.2 结果与讨论
图6给出的是以固定层数的单融合点网络结构为基础,改变多融合点交互层的起始位置得到的各个模型的性能.其中横坐标表示的是多融合点结构开始的层数.从图6中可以看出,对于5层的多模态特征学习网络,融合点结构的起始位置对网络性能的影响是先升后降,在横坐标为3处达到最大值.从1到3性能提升说明在低层特征空间进行跨模态挖掘带来了更多的噪音累积向后传播影响了模型性能,与特征分布标准化的结论相呼应.从3到5性能下降说明减少融合点结构设计会减少跨模态语义信息的挖掘,降低了输出特征的信息量,影响了学习网络性能.实验数据证明了本文提出的多融合点结构设计对多模态特征学习有正向影响.
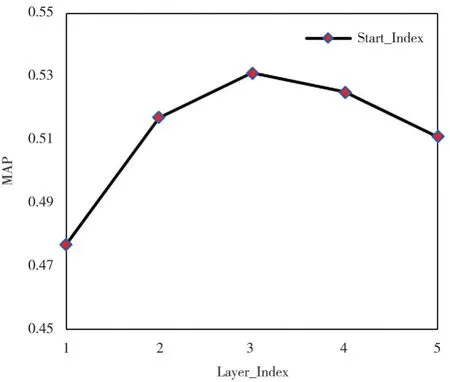
图6 多融合点起始位置对模型性能的影响
图7给出了不同输入场景下,单融合点特征学习网络与多融合点特征学习网络输出的多模态特征的检索性能差异.
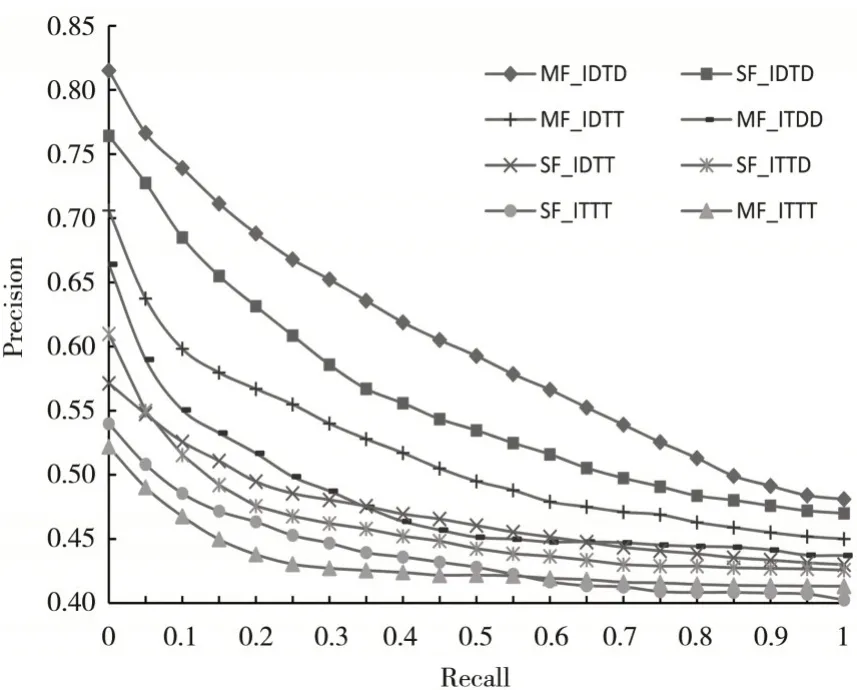
图7 单融合点与多融合点模型性能
当使用深度学习特征时,单融合点特征学习网络与多融合点特征学习网络的性能分别达到了各自的最优值,且多融合点模型的性能与单融合点相比具有明显的优势.
融合后的多模态特征比单模态特征性能更佳,且多融合点结构强于单融合点结构.说明多融合点的网络结构设计对多模态特征学习有正向影响.
当使用传统特征时,单融合点网络性能>两个单模态特征性能>多融合点网络性能.说明了传统特征模态间差异较大,多融合点网络结构由于进行了多次跨模态关联引入了额外的误差.
2.3 多模态学习模型训练策略的有效性评估
2.3.1 实验设置
在本实验中分别使用自动编码器经典的单解码通路训练策略与论文提出的基于多解码通路网络学习策略训练整个网络,对比各模型输出多模态特征的检索表现.多解码通路网络能够根据输入自适应选择对应的目标函数,而对于单解码通路的网络,为了将这两个相关性综合起来使用,将其组合起来作为网络总的目标函数.
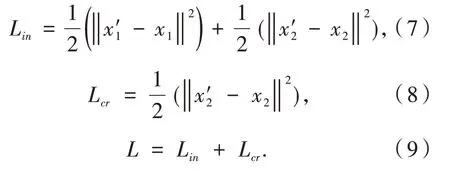
2.3.2 结果与讨论
比较多解码通路模型输出特征与单解码通路模型输出特征的检索性能,从图8中可以看出多解码通路模型输出特征的检索性能与单解码通路相比有显著提升,说明多解码通路能够有效地指导多模态特征学习场景下的网络训练,提升模型输出多模态特征的性能.

图8 模型性能对比
2.4 多模态特征学习模型整体性能评估
2.4.1 实验设置
在本实验中将多融合点的多模态特征学习网络模型与多模态特征学习场景下的网络学习策略结合起来,衡量整体模型的性能.将MFMDL(Multi-fusion Multimodal Deep Learning)与目前多模态特征领域的现有算法进行对比,包括DBM、DBN、Bi-AE(Bimodal-Autoencoder)和Cor-AE(Correspondence-Autoencoder).
实验中,为了减少随机性,采取多次独立实验去平均值的方式汇报实验结果.对于Mir⁃Flickr和Nus-wide数据集,采用一个8层网络模型:包含2层全连接层、3层多融合点交互层,以及3层多通路解码层.而Pascal Sentence由于数据集较小,采用了一个5层网络模型:包含1层全连接层、2层多融合点交互层及2层多通路解码层.
各网络每一层的神经元数目设置如表2所示.

表2 各数据集对应的网络结构
2.4.2 结果与讨论
从图9中可以看出,在相同的实验设置下,本论文提出的MFMDL算法在三个数据集上都有比较明显的优势.论文方法能提升多模态特征检索性能的原因主要有两个方面:一方面,提出了基于多融合点的特征学习网络,多融合点的结构设计在生成中间层特征表达过程中能够强化模态间关联关系,达到充分挖掘模态间语义信息的目的;另一方面,针对多模态特征学习这一具体场景对网络的训练及优化策略加以改进,提出了多通路的解码网络及配套的输入自适应交替式训练策略,在训练过程中能够兼顾模态内固有信息的挖掘与模态间语义信息的挖掘,两方面共同作用促成了性能更优的多模态特征学习模型.
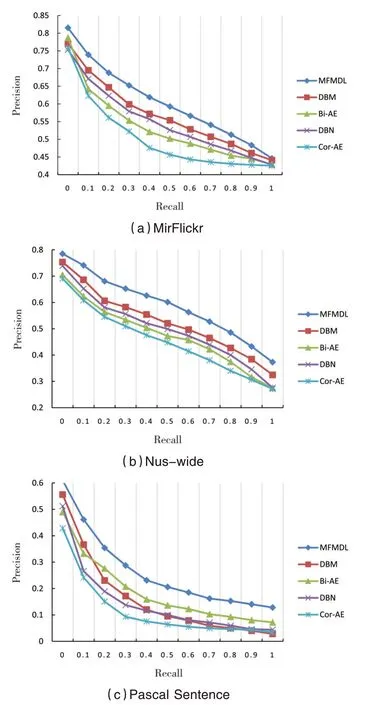
图9 检索准确率与召回率
3 结语
本文提出了一种基于多融合点的多模态特征学习网络结构,能够加强不同模态数据间交互作用,充分挖掘模态间语义关联.引入了深度特征并进行了一系列标准化措施平衡不同模态的特征分布上的差异,消除多融合点结构带来的关联误差.在训练阶段,文本针对多模态特征学习具体场景定义了网络训练的目标函数;提出了一种多模态特征学习场景下的多通路解码网络,对两个目标函数采取了多解码通路的设计;提出了一种基于多解码通路的输入自适应交替式训练策略,根据输入数据的具体情况选择相对应的通路进行训练和优化.
在实验阶段,选择了三个领域内常用的多模态数据集,采取控制变量法从多角度对本文提出的各算法实施有效评测.最终的实验结果证实了本文工作的有效性.
