人机耦合反洗钱监测系统构建与机器学习算法优化
2021-12-07郑迎飞陶文纳王生金
郑迎飞,陶文纳,赵 旭,王生金
(1.上海对外经贸大学 金融管理学院,上海 201620;2.上海交通大学 安泰经济与管理学院创业学院,上海 200240;3.上海城建职业学院,上海 201415)
中国反洗钱监管的核心是可疑交易报告制度,这个制度由中国人民银行发布的《金融机构大额交易和可疑交易报告管理办法》(中国人民银行令〔2006〕第2号发布)确定下来,要求金融机构向中央银行报告大额交易和可疑交易,然后由中央银行下设的反洗钱监测中心进行分析。近几年,随着电子支付交易数量快速增长,基层金融机构需要从海量交易数据中找出可疑交易,人工筛查数据的工作量非常大,于是有了以结构化查询语言(Structured Query Language,SQL)为主的机器筛查。但是有了机器筛查之后,人工筛查只作为机器筛查结果的一个验证步骤。这样就导致了高度的系统依赖,使得监测系统变得易于被规避,系统识别的准确性和适应性因为规避技术的发展而降低。因此,越来越多业界人士呼吁加强人工筛查。但若不能将人工筛查的经验传递给机器,要靠人工在浩若烟海的数据中去寻找可疑交易,将是十分困难的。与此同时,不能与时俱进、学习新洗钱特征的机器将成为越来越无用的机器。如果将人工筛查发现的异常交易标记为“可疑交易”,然后归入机器学习的数据库,则机器预测能力可以自动升级。人工甚至可以根据最新洗钱趋势,修改机器学习模型的特征变量,完成机器算法的快速升级。因此,构建基于机器学习加上人工反馈形成的人机耦合可疑交易监测系统十分必要。
国际反洗钱监管呈现如下几方面的趋势[1]:首先,反洗钱监管的重要性日益增强。各国当局将反洗钱监管逐渐提高到了维护国家经济安全和国际政治稳定的战略高度,政治色彩较为浓厚。其次,监管渠道和监管对象不断拓宽。反洗钱监管对象正逐渐由传统银行类金融机构向其他金融机构和非金融机构延伸。从业务范围来看,反洗钱监管已拓宽到数字货币等新兴金融业务。最后,监管前移,“KYC”成为重点1)KYC 是“Know Your Customer”的英文首字母缩写,意为“了解你的客户”。反洗钱合规监管思路由“规则为本”向“风险为本”转变,后者强调“预防为主、打击为辅”原则,注重对洗钱风险提前监测和有效防控。
反洗钱监测技术方面,随着信息化和数字化的发展,可疑交易识别技术的研究及应用已经取得了较大进展。关于如何提升可疑交易监测能力的学术研究主要分为两类,一类文献研究反洗钱监测系统的整体设计和系统构建;另一类文献研究可疑交易监测中重要环节的具体识别技术和方法[2]。
关于反洗钱监测系统的整体设计和系统构建,代表性的研究有:陈云开等[3]构建了包括逻辑层次结构、系统基本框架和系统基本流程的分布式异构计算环境下基于数据挖掘技术的反洗钱监测系统;汤俊[4]设计了利用风险评估工具及合规工作流程辅助工具从客户风险、交易风险和综合风险3个方面识别可疑交易的反洗钱监测系统;宋媚等[5]提出了基于聚类分析的反洗钱组织多层次监测体系。上述文献注重了反洗钱监测系统结构性和层次性,为本文构建基于人机耦合的反洗钱监测系统奠定了基础,但上述文献未明确提出计算机监测系统和人工以及外部系统之间的耦合关系。
关于反洗钱监测系统中可疑交易的具体识别技术和方法的研究中,基于机器学习的模型已经有较多研究成果[6]。各种有监督模型,以及网格聚类、孤立点挖掘、距离聚类等无监督模型,在反欺诈和反洗钱领域均具有有效性[7]。代表性的研究有:基于决策树算法的反洗钱监测模型[8],贝叶斯分类和聚类分析相结合的复合模型[9],利用聚类算法和孤立点挖掘的反洗钱改进算法模型[10],基于IF-THEN 规则和决策树算法的降低可疑交易预警模型[11],基于Logistic回归分析的用户违约评估模型[12],基于GBDT 算法的线上交易欺诈侦测模型[13],基于改进稀疏编码模型的图像分类算法[14],利用扫描统计判别账户交易片段异常的流程和算法模型[15],基于时间压力条件下的最小风险最大洗钱量模型[16]以及基于大数据分析的反洗钱方法[17]等。上述文献的经验为本文优化机器学习算法缩小了试错范围。又因为本文构建了基于人机耦合监测系统,所以需要针对该系统继续优化机器学习算法。
1 人机耦合反洗钱监测系统构建
支付机构现有反洗钱可疑交易筛查的第1个步骤是对交易数据进行SQL筛查,通过这个程序可以去掉大部分单笔金额以及30日累计金额均非常小的交易,同时筛查出单一指标达到可疑水平的交易。例如,账户单日收款交易金额占前30日日均收款金额的400%,单笔金额大于5万元,信用卡交易笔数占总交易笔数的比例较大,或一周内交易金额大于50万元等,均可能是可疑交易。
第2个步骤是对SQL 筛查后余下的交易数据进行人工筛查。筛查的标准通常包括:
(1)短时间内交易频繁,且交易资金量突增,涉及资金来源均为网站虚拟商品消费。
(2)账户涉及资金交易与网站商品价值、交易量明显不符。
(3)资金涉及快进快出,且账户几乎无余额。
(4)短期内交易极其频繁,交易金额递增,且呈现大额整数金额特征。
(5)客户基本信息情况缺失或可疑。
上述机器筛查和人工筛查分离的系统存在弊端。机器筛查规则单一、固定,很容易被犯罪分子规避。虽然近期引入人工智能之后,筛查系统具有学习能力,但在迭代速度和灵活性上不及真正的人工。这是因为仅凭账户信息和交易信息很难确定洗钱行为,金融机构若不想“防卫性报送”,则需要查询外源信息进行辅助判断,这时人工往往占优势。首先,信息来源复杂多样,需要从各个渠道、各种形式(包含文字、图片、视频)、对商户不同角度的评论等做判断。其次,信息判断难。多样化的数据很难通过技术手段做判断,而且洗钱行为本身是不断变化的。最后,虽然随着技术水平的发展,人能做的查询和判断都可以用机器来实现,例如通过爬虫获取这些信息,再用自然语言处理(NLP)、计算机视觉(CV)以及多模态的深度学习技术来做识别,但这时数据采集和模型的搭建、维护成本都很高。面对变化的需求,人可以灵活判断,而深度学习模型则需要根据业务变化不断迭代[18]。
面对不断演化升级的新型洗钱方式,反洗钱监测部门人员可以从外部或内部协作中掌握这些变化,快速更新模型数据处理规则,并把新型洗钱案例加入机器学习数据库,让机器学习模型实现快速升级。若依靠机器学习自动实现迭代,则需要积累一定的案例量,更新速度较慢。而且人工辅助机器升级并不妨碍机器学习模型独立发现新的洗钱规律。
因此,在现有机器筛查和人工筛查步骤基础上,本文改进了传统洗钱筛查流程,建立了基于人机耦合的反洗钱监测系统流程,如图1所示。
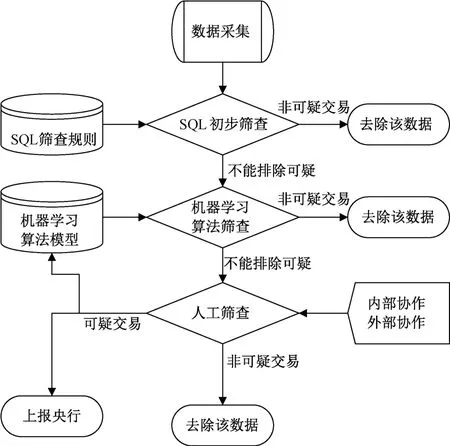
图1 支付机构人机耦合反洗钱监测流程图
改进后的系统中,人工筛查不仅作为机器筛查之后的“下一步骤”,而且“人工”还会不断地接受来自本机构其他部门和外部的新型洗钱案例的信息[19]。基于这些新信息,更新人工筛查标准的同时,将发现的新型案例添加到机器学习算法的学习库中,必要时还可以修改、添加机器学习模型的特征变量,这样就形成了一个人机耦合的系统(见图2)。之所以称之为“耦合”,是因为在该系统中人与机器之间不仅是一种基于发挥各自特长的协作关系,而且是人与机器各自对信息处理的结果会影响对方的行为,相互形成数据控制,所以属于耦合关系。
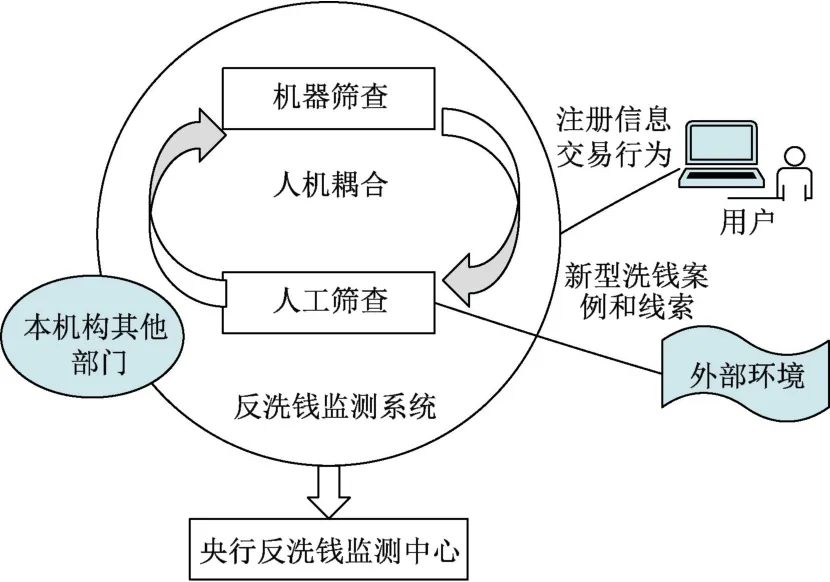
图2 基于人机耦合的支付机构反洗钱监测系统
在人机耦合系统框架中,机器学习算法模型对系统识别准确性和效率而言非常重要。比较了常见的几种机器学习分类算法的特点及其对于反洗钱可疑交易监测的适用性之后[7],初步判断基于随机森林分类算法的模型最可能适合用于支付机构反洗钱可疑交易监测。而Logistic回归分类法和梯度提升算法(GBDT)也具有一定的可实施性。下文将对基于这3种算法的模型进行测试和比较。
2 机器学习算法选择
随机森林算法属于典型的组合分类器算法,最早是由Breiman[20]提出的。基于随机森林算法的模型构建包括特征和标签提取、特征预处理、样本内训练、交叉验证和样本外测试等步骤,如图3所示。
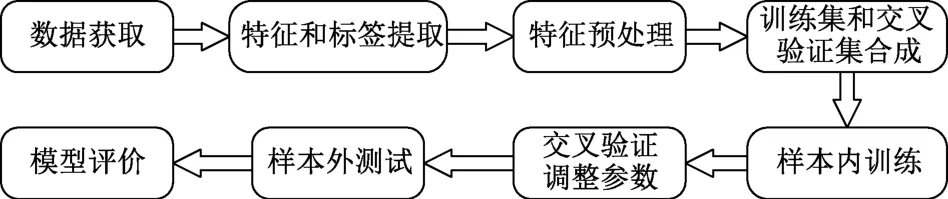
图3 随机森林模型构建示意图
2.1 数据获取
以支付公司的客户基本信息(静态信息)和交易信息(动态信息)为研究样本,时间选取为2018-01-01~2018-09-31共9个月数据,其中,1~6 月的数据用于训练模型,7~9月的数据用于验证模型。经过SQL筛查后,研究样本共包含12 538 72条交易记录,其中有洗钱嫌疑上报央行反洗钱监测中心的交易记录有124 851 条,标为正样本,标签记为1。没有洗钱嫌疑的交易记录有1 129 021条,标为负样本,标签记为0。
根据宋媚等[5]提出的多层级监测体系,监测数据分为交易层、账户层和实体层3个层次。本文将3个层次的数据根据支付机构的实际数据归类方法,分为客户基本信息(对应账户层和实体层)和交易信息(对应交易层),共找到70个变量。经数据探索,去掉空值较多、数据质量差的变量,最终选择了12个初始变量。关于客户基本信息的变量有9个,包括商户名称、单位个人标识、地址信息、组织机构代码、依法设立或经营的执照名称、依法设立或经营的执照号码、法定代表人或负责人姓名、法定代表人或负责人证件种类以及法定代表人或负责人证件号码;关于客户交易信息的字段有3 个,包括交易时间、资金收付标志和交易金额。
2.2 特征和标签提取
反洗钱监测模型的监测主体是交易可疑的客户,主要是针对交易层面进行的数据挖掘[21],但是也要综合考虑客户的基本信息[22-23]。
反洗钱人工筛查人员根据既有洗钱案例的线索,积累了从数据的复杂关系中整体判断交易是否可以的经验。但在数据量越来越庞大之后需要将经验传递给计算机。在本文提出的人机耦合系统下,若把支付机构人工筛查的重要变量直接传递给计算机系统,则意味着要将一部分原始基本信息和交易信息进行加工处理。首先,将样本的交易信息按照每个客户以日为最小研究单位进行统计,衍生出新的交易变量。统计后的数据总量为228 036条,其中,负样本数据量为219 399条,正样本数据量为8 637条。
交易信息特征包括如下5类:客户日交易信息统计情况、日收付款统计情况、月收付款统计情况、白天和夜晚时间段统计交易信息以及衍生月交易数据的处理。共25 个交易信息特征,具体如表1 所示。客户基本信息的变量处理方式如表2所示。
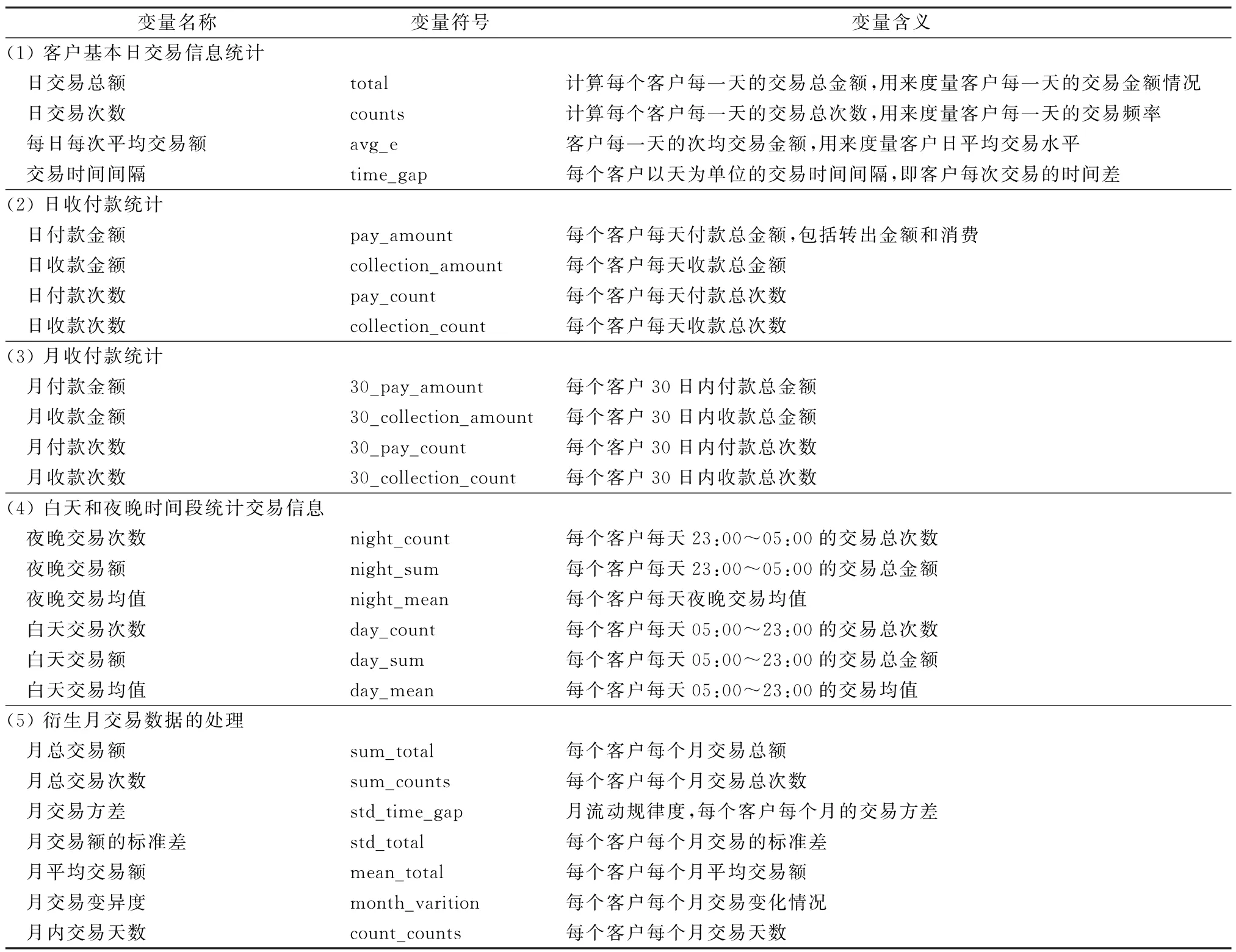
表1 交易信息变量的处理

表2 客户基本信息的变量处理
因变量也是按照天为单位,进行客户归集。上报央行的可疑交易作为正样本,标签设为1;没有上报的正常交易作为负样本,标签设为0。样本情况如表3所示。
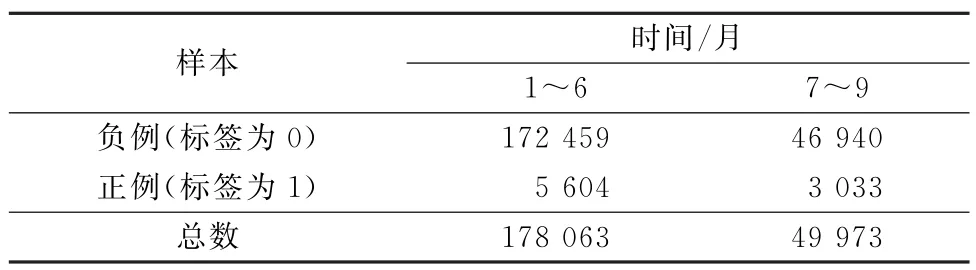
表3 正负样本情况
2.3 特征预处理
2.3.1 自相关性检验 使用皮尔逊相关系数,判断变量之间的线性相关程度,并剔除相关性较强的变量。皮尔逊相关系数数值介于1和-1之间,数值越接近于1,表示正相关性越强,数值为1时,表示完全正相关;数值越接近于-1,表示负相关性越强,数值为-1时,表示完全负相关。皮尔逊相关系数数值为0,表示两个变量线性无关。据此筛选出相关系数大于0.5的变量,如表4所示。

表4 变量相关系数
2.3.2 多重共线性检验 当模型中两个或两个以上变量相关时,说明模型具有多重共线性。因为本文研究的变量维度较高,所以对于多重共线性的检验比自相关性的检验更加实用。判断一个自变量和其他所有自变量的多元线性相关性可以用方差膨胀因子(VIF)来衡量。当0<VIF<5时,表明变量之间不存在多重共线性;当5≤VIF<10时,表明变量之间存在弱多重共线性;当10≤VIF<100时,表明变量之间存在多重共线性;当VIF≥100时,表明变量之间有严重的多重共线性。本文筛选出VIF>5的变量,10个需要删除的具体变量如表5所示。
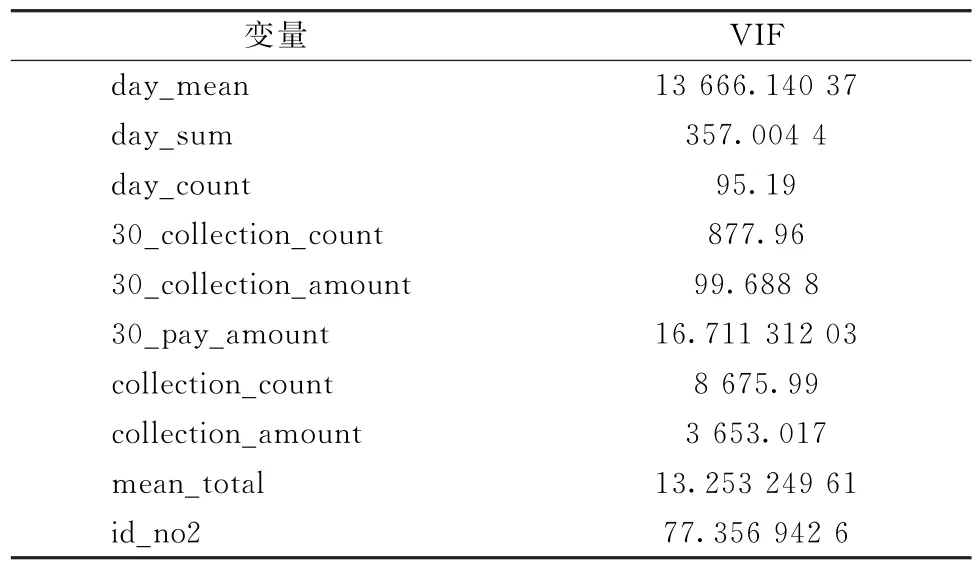
表5 多重共线性检验
根据自相关检验和多重共线性检验,以多重共线性的变量为基础,删除和自相关检验共有的23个变量。
2.4 训练和交叉验证
以2018 年前6 个月的数据的70%作为训练集,30%作为验证集进行模型训练,其中,负样本数据量为84 197条,正样本数据量为2 350条。训练样本中正负样本数极其不均衡,会导致模型追求准确率而牺牲一些正样本。针对正负样本不均衡问题,在训练模型时采用过采样中的SMOTE 算法,将正负样本比例调整为接近1∶1,然后通过随机森林算法来训练模型。
2.4.1 混淆矩阵与ROC 曲线 图4 所示为模型的ROC曲线,接近对角线,说明模型的泛化能力很强,且有很高的准确率。ROC曲线包围的面积占比达0.994 5。
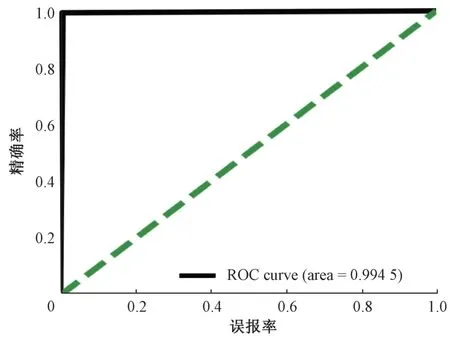
图4 训练模型ROC曲线
表6 所示为随机森林训练结果得出的混淆矩阵,分别显示出模型预测结果和实际结果的比例关系和数量关系。表6表明,实际为可疑交易并且预测为可疑交易的数量为24 256,实际为不可疑交易并且预测为不可疑交易的数量为23 740,实际为可疑交易但是预测为不可疑交易的数量为34,实际为不可疑交易但是预测为可疑交易的数量为99。模型结果表明,随机森林预测的可疑交易和人工筛查上报的可疑交易基本相同,在很大程度上节省了人力,并且模型数据处理量大,处理效率极高。

表6 训练模型混淆矩阵
由表7随机森林模型的评价指标可以看出,模型正负样本的精确率、召回率以及F1-Score值的平均值均为0.997 2,说明分类正确的样本占所有样本的比例为0.997 2,模型能够很好地预测可疑交易。
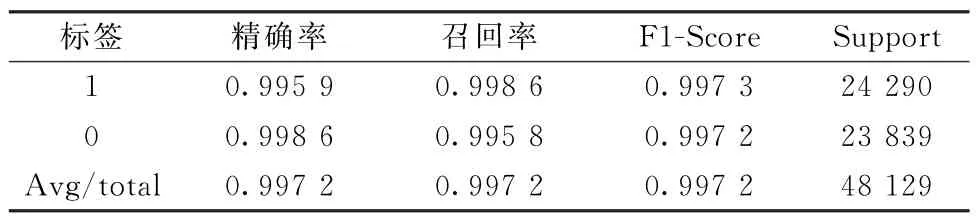
表7 随机森林模型的评价指标
2.4.2 随机森林模型优化 随机森林模型的优化,主要是对模型调整参数。随机森林模型的重要参数如下:n_estimators为弱学习器的最大迭代次数,max_features是最大特征数,max_depth为决策树最大深度,min_samples_split为内部节点再划分所需最小样本数,min_samples_leaf为叶子节点最少样本数。
运用python软件进行网格搜索,得出模型的最优参数分别为:n_estimators=60,max_features=5,max_depth=11,min_samples_split=50,min_samples_leaf=20。将参数代入随机森林模型,重新进行随机森林建模,得到新的混淆矩阵如表8所示。由混淆矩阵可以看出,调参后的模型正负样本预测情况均有提高。

表8 优化后训练模型混淆矩阵
图5所示为优化后模型的ROC 曲线,其包围的面积占比达0.999 3。与图4模型的ROC曲线对比,更接近对角线,说明模型的泛化能力增强,且准确率也增加了。由表8所得混淆矩阵对比表6所得混淆矩阵可以看出,可疑交易预测结果的正确率明显增加。
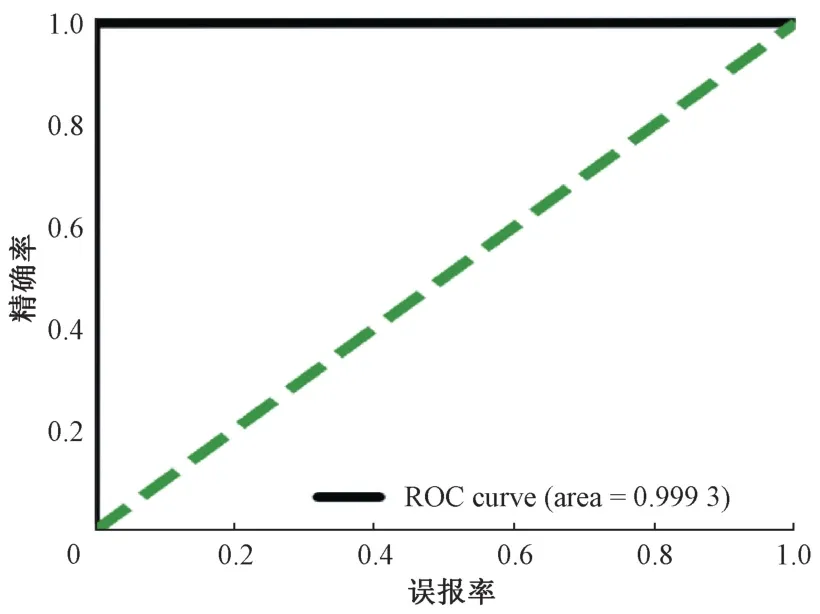
图5 优化后训练模型ROC曲线
由表9 中优化后模型的评价指标结果可以看出,模型正负样本的精确率、召回率和F1-Score值相比于表7都有明显提高。
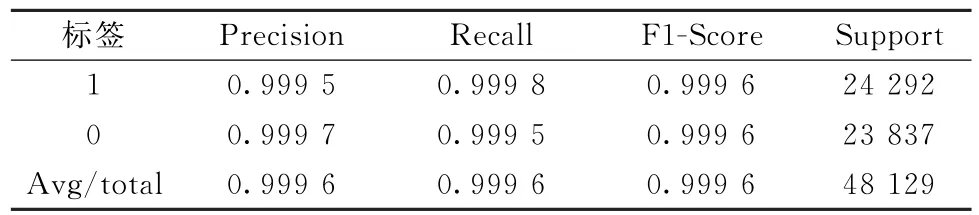
表9 优化后模型的评价指标
2.4.3 特征重要性排序 计算随机森林模型特征重要性排序过程如下:
(1)对于随机森林中每一棵决策树,根据袋外数据,对决策树性能评估,计算袋外数据误差,记为erro1。袋外数据指在训练模型时,由于重复抽样,建立决策树时没有用到的数据。
(2)随机对袋外数据样本加入噪声干扰,并计算袋外数据误差,记为erro2。
(3)假设随机森林N棵树,特征X重要性=∑(err2-err1)/N。
(4)特征重要性排序原理为:对袋外数据加入噪声干扰时,若袋外数据误差变化很大,则说明该特征对模型预测有很大影响。
随机森林模型特征重要性排序结果如表10所示。由表10可以看出,std_total(月交易额的标准差)、建立业务关系日期(open_time)、sum_total(月总交易额)对可疑交易监测模型影响较大,商户名称(acc_name)、单位个人标识(acc_type)、province_exist(省份)对可疑交易监测模型影响较小,一部分原因是这些变量本身区别能力较小,商户名称和单位个人标识基本没有缺失值。
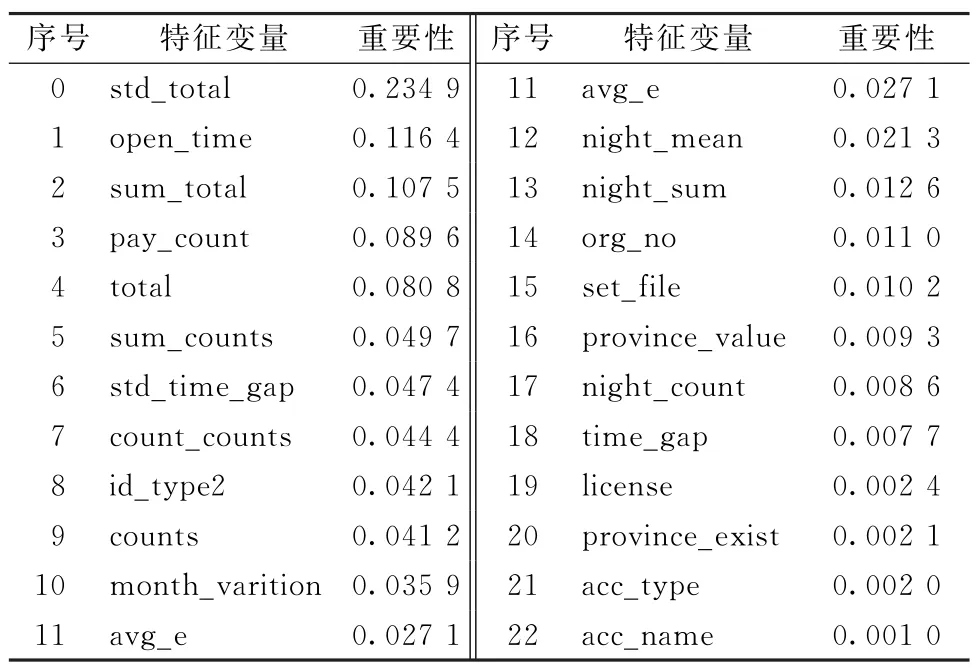
表10 特征重要性排序
3 模型的验证与评价
3.1 模型的样本外验证
以2018年7~9月的数据作为模型的验证集,对模型进行样本外验证。验证集数据基本情况为:数据总量为49 973条,其中,正样本数据量为3 033条,负样本数据量为46 940条。为检验真实数据的预测情况,不对验证样本进行SMOTE 采样,直接对测试集样本数据代入调参后的模型进行验证,查看模型的预测能力。
表11中显示了随机森林模型验证结果得出的混淆矩阵,给出了模型预测结果和实际结果的比例关系和数量关系。表11表明,实际为可疑交易并且预测为可疑交易的数量为3 012,实际为不可疑交易并且预测为不可疑交易的数量为46 918,实际为可疑交易但是预测为不可疑交易的数量为21,实际为不可疑交易但是预测为可疑交易的数量为22。

表11 样本外验证的混淆矩阵
由表12中随机森林模型的验证结果可以看出,随机森林模型的平均精确率、召回率和F1-Score均值为0.999 1,表明模型有很好的准确性。
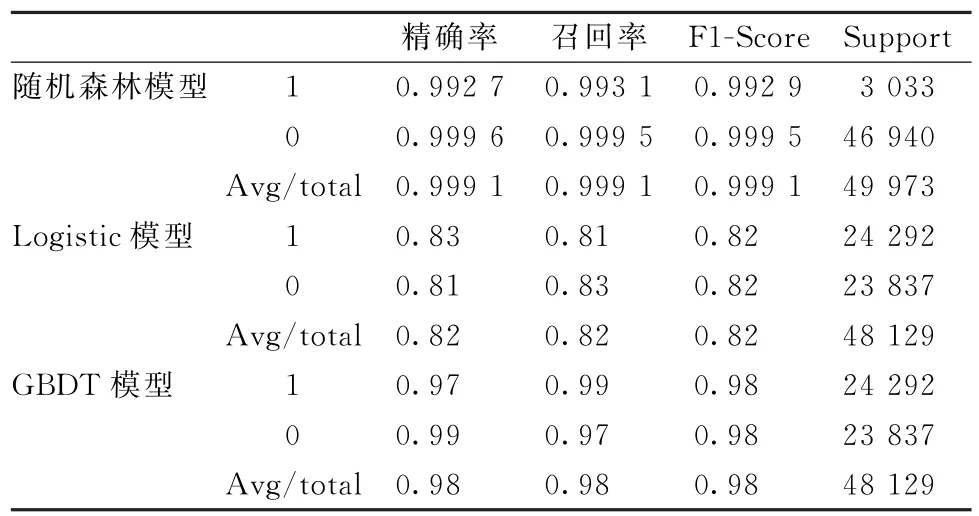
表12 样本外验证的评价指标
3.2 模型的评价
通过分析客户交易信息及客户基本信息的实证结果,运用随机森林模型对于可疑交易分类问题具有很高的准确率。基于该模型能够得出可疑交易与建立业务关系日期、月交易额的标准差(日)、月收款金额、夜晚交易次数、是否填写法定代表人证件号码、是否填写法定代表人或负责人姓名、月平均交易额、月总交易额、白天交易额以及日总交易额等11个变量,具有相关关系,并且能够很好地预测是否是可疑交易。
上述研究表明,由人工反馈的经验形成的衍生变量是随机森林模型的重要特征变量,人机耦合使得基于随机森林算法的反洗钱可疑交易监测模型预测的结果与人工筛查后预测的可疑交易基本符合,在很大程度上节省了公司人力,而且模型效率高、预警快,带来了实际的效益。
3.3 与Logistic回归模型的比较
Logistic回归模型为基本的机器学习分类模型,具有很好的可解释性,在实际中有很好的可实施性。在实际应用中,基于Logistic分类的模型,预测结果能够得到概率值。模型预测准确率结果见表11。Logistic回归模型的混淆矩阵表明,实际为可疑交易并且预测为可疑交易的数量为19 685,实际为不可疑交易并且预测为不可疑交易的数量为10 807,实际为可疑交易但是预测为不可疑交易的数量为4 607,实际为不可疑交易但是预测为可疑交易的数量为4 030。由表12的验证结果可以看出,Logistic回归模型虽然能够表现出变量之间对于可疑交易判断的影响,但是模型的准确性较差。
3.4 与GBDT模型的比较
GBDT 模型是集成机器学习分类算法,和随机森林模型有很多相似之处,也是以决策树为基础,具有很好的准确性。GBDT 是按照每次决策树分类的结果,对于分类错误的结果给予较高的惩罚权重,分类正确的结果给予较低的惩罚权重,从而使模型能够减少错误的分类误差。
表11表明,实际为可疑交易并且预测为可疑交易的数量为24 068,实际为不可疑交易并且预测为不可疑交易的数量为23 084,实际为可疑交易但是预测为不可疑交易的数量为224,实际为不可疑交易但是预测为可疑交易的数量为753。由表12的验证结果可以看出,基于GBDT 分类的模型相对于Logistic回归具有较好的准确性,但是其准确率仍不及随机森林模型。
4 结论
本文首先构建了基于人机耦合的支付机构反洗钱监测模型。该模型较人机分离的反洗钱系统具有优越性。面对金融交易的复杂性和不确定性,人和计算机在识别洗钱交易方面各有优势和局限性。计算机虽然可以代替人类从事大量的计算筛查工作,但人类在与外界展开各种非结构化数据的交互方面具有独特优势,可以主动探测新型洗钱线索,用于判断交易的整体可疑度。因此,在人机共同组成的反洗钱监测系统中,人是与外界沟通、学习新趋势,并对交易的整体可疑度进行最终判断的主体。虽然这个监测系统的适应能力主要源于人,但不能止于人。因为交易的数据量之庞大已超出了人工处理的范围,所以将经过人工判断之后的可疑交易的数据加入机器学习的训练集,甚至根据反洗钱的新线索修改机器学习的特征变量提取等步骤,可以让机器筛查这一环节的学习能力和适应能力更强,实现更快速的迭代。
在构建人机耦合反洗钱监测系统之后,针对机器学习算法的选择,本文比较了随机森林算法、Logistic算法和GBDT 算法,发现基于随机森林算法的模型具有更高的精确率,且模型有很好的适应性。模型中变量的预处理也应用了人工筛查的经验。根据人工筛查的最新经验,需要深层次挖掘交易信息才能提高机器学习模型的准确度,所以本文将交易时间、资金收付标志、交易金额等交易属性进行多方面衍生,多角度地寻找交易方面的共性,包括但不限于日交易收付、月交易收付,白天夜晚收付、日交易标注差、月交易标准差等角度。在根据人工经验将交易信息进行了上述衍生之后,模型达到了99%以上的精确度,这正是人机耦合的效果。未来随着洗钱新手段、新趋势的出现,人工可以再次修改数据和数据的预处理方式,因此,本文的数据预处理方式仅是一个算例,在本文构建的人机耦合系统框架下,未来是可以不断迭代进化的。
