考虑产品组合的零售门店选址模型
2021-12-07陈亚静
苏 凯,陈亚静
(1.南京大学 历史学院,南京 210023;2.上海交通大学 安泰经济与管理学院,上海 200030)
近年来,随着中国居民生活水平的不断提高,社会零售消费也更加活跃。尽管网络购物的兴起在一定程度上减少了实体零售渠道的销售量,但是实体渠道依然在现有的零售渠道中占据主导地位。
众所周知,中国零售行业在取得巨大成绩的同时,也有许多零售业由于经营不善而倒闭,其中一个非常重要的原因就是经营选址不当。实体店与电商相比,最大的不同之处是有实体,那么,优势与劣势都取决于实体店的位置,假如实体店能坐落在目标人群地段,则优势不言而喻。选址决定了门店的客流来源、租金成本结构、运输配送成本以及营业员的薪酬水平范围,是一家门店财务模型中最关键的外部因素。因此,零售店的选址是零售企业战略规划的重要组成部分,受到零售业管理者和学者的高度重视。
与此同时,实体店铺内所摆放的商品种类的个数,也是影响顾客选择行为的一个重要原因。例如,顾客会选择虽然距离自己比较远,但是店铺内商品种类较多或者有特殊限定商品专售的店铺进行购物。就零售实践而言,本文观测到的更细化的影响因素主要是,在不同的商圈,客流结构的比例会有一定程度的差异(商务客流/学生客流/社区家庭客流/通勤客流等都会呈现明显的到店时段差异),门店需要结合不同消费客群的差异,针对性调整出样数量。在当今时代,店铺内产品种类对于实体店的长期运营发展也发挥着至关重要的作用,如果说选址背后对应的是流量和流量结构,那么,产品种类个数背后对应的就是销量和需求匹配的有效性。因此,在考虑门店选址问题的同时,也要考虑门店的选品种类问题,将两者结合进行有效决策。
回顾已有的关于零售门店选址问题的研究可以发现,目前在针对实体门店进行选址研究时,仍然是所有的连锁门店经营的商品种类个数是一样的,并没有对不同的门店进行个性化的确定选品个数。但是由于不同地址位置的门店,对应的消费人群是不同的,因而对每个门店的选品个数进行个性化决策是非常重要的。为此,本文给出了一个综合考虑选品个数的门店选址方法。
1 文献综述
关于选址问题的研究已有很多。早期关于选址问题的研究主要集中在构建理论模型以及模型的求解方面[1-3]。目前关于选址问题的研究,主要针对具体的实际问题展开。Shan等[4]提出了一个双层模型来处理连锁店的竞争选址问题,模型同时考虑了新进入企业与现有竞争对手之间的定价博弈,在纳什均衡的原则下,通过利益最大化来优化选址。Zhu等[5]提出了一种新型的插电式电动汽车充电站选址模型,为使总成本最小化,所提出的模型同时处理了将充电站放置在何处以及在每个充电站应建立多少个充电器的问题。此问题虽然与本文考虑的门店选址和出样数量问题非常类似,但文中并没有考虑充电站的个数多少对顾客选择该充电站行为的影响,因此,该方法不能直接应用于本文所提出的问题中。
双层规划是在研究非平衡经济市场竞争时首先提出的,1973 年,在Bracken等[6]的文章中出现了双层规划数学模型。20世纪80年代,双层规划引起了国内外学者的广泛关注。Soares等[7]以电力零售市场为研究对象,建立了一种新型的零售商与消费者相互依赖的双层规划模型,并提出了一种计算上层目标函数边界质量估计值的方法以使决策者在短时间内做出更好的决策。郑斌等[8]针对震后两级救灾动态网络系统多运输方式以及物资需求急迫性程度不同等特点,建立一个上层以物资运送时间满意度最大为目标,下层以物资分配公平性最大为目标的双层规划动态模型。求解双层规划问题最常用的算法是遗传算法。它是由Holland[9]提出的一类借鉴生物界自然选择和自然遗传机制的随机搜索算法。该算法具有较强的鲁棒性,是求解复杂优化问题时广泛应用的方法之一。Zhang等[10]提出了一种对象编码遗传算法(OCGA)来解决工艺计划和车间调度问题;Ren等[11]提出了一种基于遗传算法的元启发式方法来处理再制造活动中的拆卸序列规划问题;Hiassat等[12]开发了一种遗传算法来有效地解决易腐产品的位置-库存-路径联合优化模型。
近年来,越来越多的学者采用双层规划方法对综合考虑选址和其他因素的问题进行研究。Calvete等[13]研究了带有顾客偏好的设施选择问题,建立了以最小化总成本为上层目标和以最小化总的顾客偏好序值为下层目标的双层规划模型,并设计了进化算法对模型进行求解。Dan等[14]通过建立双层规划模型刻画了公司在决定其选址的位置和服务水平时要考虑到用户光顾设施,以使其个人效用最大化的问题。Gang等[15]研究了地方政府和石材企业同时参与的石材工业园区选址问题,建立了以政府总运营成本最小为上层目标以及以石材企业使用成本最小化为下层目标的双层规划模型。然而,在目前的考虑选址和其他因素相结合的问题中,并没有对选品和选址进行联合优化的研究。但是,Hoch等[16]指出,若零售商提供的产品子集较小,则无法充分满足消费者的个性化需求,将失去对部分消费者的吸引力;反之,Gourville等[17]指出,若零售商提供的产品子集较大,虽然能够刺激消费者购买且有助于培养品牌忠诚度,但也会加剧产品之间的“蚕食”效应,会对零售商带来巨大的库存管理和资金占用压力,甚至可能导致消费者因选择过多而放弃购买的结果。由此可见,产品摆放过多以及过少都会对商店收入带来影响。因此,如何将选品和选址进行联合优化研究是一个亟待解决的问题。
2 考虑产品组合的选址模型
2.1 模型假设
本文研究考虑产品组合的零售门店选址问题以及产品个数的选址问题。为了模型的可解性,本文将进行简化,仅考虑解决出样产品种类的问题。为便于基本思想的表述,又不具有损失概括性,做出如下基本假设:
(1)本文没有涉及在店铺内具体为顾客推出哪些商品,只考虑店铺内需要摆放的商品种类。因此,只考虑顾客选择店铺的行为,不考虑顾客具体购买几件商品,顾客只要选择了该店铺,就会消费一单。并且进店消费一单的平均金额是相等的。该消费额与店铺的商品个数有关。
(2)仅考虑距离和店铺内所摆放的产品个数作为衡量顾客对店铺偏好度的因素。已有文献指出距离和店铺内产品个数均是影响顾客选择该店铺的因素,为了简化模型,这里只用这两个要素来衡量顾客的购买行为。
(3)假设同一家门店内每种商品的运营成本和运营收益是相同的。因为同一家店内,是同一群人和店长在运营商品来维护补货、接待顾客、促销等,本文假设同一家的运营成本是相同的。为了简化模型,假设运营收益也相等,这里的运营收益只与摆放的产品个数有关。
2.2 问题描述
本文所要解决的是考虑产品组合的选址问题,即如何从多个可供选择建设门店的地点中,确定所要建设门店的地点和每个门店所需摆放的商品个数来最大化公司利润。
模型涉及的具体符号:
N={1,2,…,n}——可供选择建立商店的地点集合
M={1,2,…,m}——顾客的集合
dij——地点i到顾客j的距离
fi——建设商店i所需要的固定成本(租金)
ci——门店i内陈列1个商品所需的运营成本
πi(w)——表示商店i中陈列w个产品所带来的平均每单的收益,文献[18]中指出πi(w)是关于w的一个单峰函数
决策变量
xi——0-1变量,店铺在i处选址为1,否则为0
zi——表示商店i中所摆放的商品个数
yij——0-1变量,顾客j去地点i购物时为1,否则为0
2.3 双层规划选址模型
传统的选址问题,公司是把运输成本作为目标函数的一个部分,公司自己可以确定如何运输。众所周知,传统的解决选址问题的方法是以公司的总利润最大为目标函数,建立单层规划模型进行求解。而本文考虑的是零售环境,即顾客是去门店自行选择,且用户自己的运输成本也不在公司的考虑范围之内。因此,与传统的解决选址问题的方法不同的是,本文将顾客和公司分别看作单独的决策个体,将公司的总利润最大和顾客的选择满意度最高作为目标函数来建立双层规模模型进行选址决策。
在本文中,上层规划可以描述为决策部门在可供选择的商店集合中确定最佳的选址决策和选品决策以使总的利润最大。下层规划则描述了在多个门店中,顾客选择其满意度最高的门店购物。值得指出的是,由于不同门店所在的周边环境可能不同,例如,门店周围竞争对手的数量以及商品的价格,都会影响到顾客到店消费的金额。因此,即使在所有门店的选品个数相同的情况下,顾客到不同门店消费的金额也可能是不同的。
首先给出所有门店选品个数相同时的双层规划选址模型,即不考虑门店产品组合的选址模型,记为模型1。具体如下:
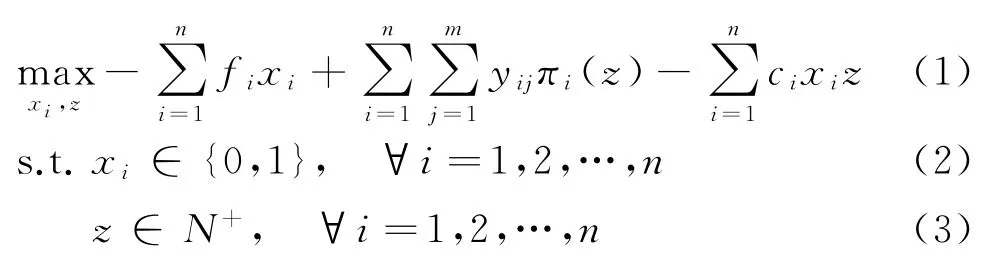
其中,y由求解如下规划问题得到:
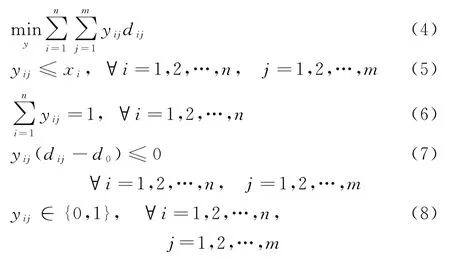
其中:目标函数式(1)为上层问题目标函数,表示所建店铺总利润最大;式(4)为下层目标函数,表示顾客选择购物的门店与顾客距离最小;约束条件式(5)表示顾客只能去开设店铺的地址购物;式(6)表示顾客必须去一个门店购物;式(7)表示顾客所选择购物的门店与顾客之间的距离不超过d0;式(2)、(3)和式(8)为决策变量的取值约束。
接下来建立门店可以根据自身需求个性化选品的双层选址规划模型,即考虑门店产品组合的选址模型,记为模型2。具体如下:
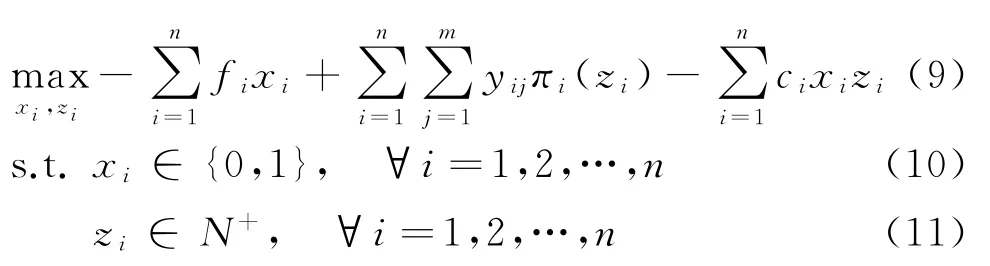
其中,y由求解如下规划问题得到:
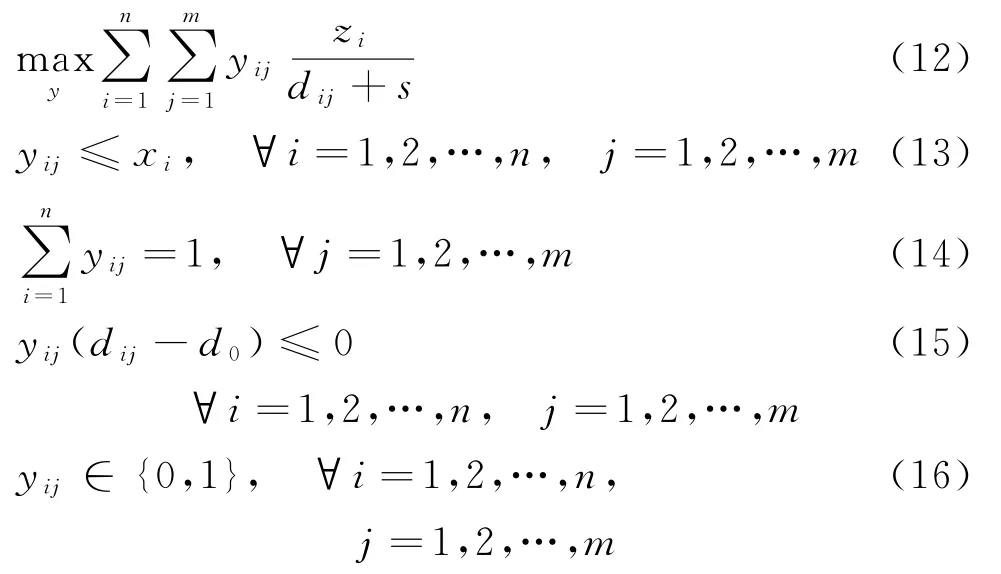
其中:目标函数式(9)为上层问题目标函数,表示所建店铺总利润最大;式(12)为下层目标函数,表示顾客选择去偏好度最高的店铺购物,这里顾客的偏好度与店铺内所摆放商品的个数以及店铺到顾客的距离有关,具体而言,顾客j对店铺i的偏好度随着dij的增加而减小,随着店铺内所摆放商品个数zi的增大而增大,因此,用式子zi/(dij+s)表示顾客j对店铺i的偏好度,此处s是为了防止dij等于0而设置的大于0的参数;约束条件式(13)表示顾客只能去开设店铺的地址购物;式(14)表示顾客必须去一个门店购物;式(15)表示顾客所选择购物的门店与顾客之间的距离不超过d0;式(10)、(11)和式(16)为决策变量的取值约束。
3 模型求解
对于上述两个模型的上层问题采用遗传算法求解,下层问题采用精确整数规划算法求解。算法的基本思想是:首先选取一些上层决策变量构成初始种群,上层将相应的决策变量传递给下层,下层在上层决策变量的基础上做出相应的最优反应,将反应结果反馈给上层,上层根据下层的反应对应的决策做出评价,并通过反复进行遗传操作,寻求上层的最优决策。本文针对所给出模型的特点,分别对所给出的两个双层规划模型设计了相应的遗传算法。算法主要过程如下。
模型1和模型2的遗传算法步骤:
(1)个体编码。对于模型1,上层种群染色体长度为备选地点个数加1,即n+1。其中:染色体中前n个基因代表上层决策变量xi,X(t)(X={xi|i∈N}),取值为0或1,为1时表示备选地点被选择建立门店,否则为0;染色体第n+1位为上层决策变量z,z采用实数编码。对于模型2,根据模型1所求得x≠0的个数来确定染得体的长度。不妨设x≠0的个数为n个。采用二进制编码,上层种群染色体长度为a0n,这里a0为常数。
(2)种群初始化。遗传算法是对群体进行进化操作,需要随机生成初始群体数据。令群体规模为popSize,对于模型1,要求基因型的前n位的每一位数值取值等于0 或1,剩余的取值为正整数;对于模型2,要求基因型的每一位数值取值等于0或1。照此方法,随机产生popSize个个体,构成初始种群。
(3)求解下层规划。将上层个体的值代入下层问题,求出下层的决策变量yij,由于下层规划是整数规划问题,故可调用gurobi进行直接求解。将yij和xi代入上层目标函数,由于上层目标函数是关于z的单峰函数,故可求出上层目标函数最大时所对应的z*,并将z*作为下一轮迭代时z的值。
(4)计算适应度。在遗传算法中,往往通过适应度来衡量每个个体的优劣程度。本文将上层目标函数作为适应度函数。把求解出的下层决策变量yij连同对应上层决策变量xi和z*代入上层目标函数,计算适应度。
(5)选择。选择操作采用轮盘赌——精英策略相结合的方法以使每次迭代的最佳个体被保留,算法不会出现退化。
(6)交叉。对给定的种群,在给定概率下进行交叉,产生新的个体。其中,染色体中前n位基因采用均匀交叉法,将每个点作为潜在的交叉点,随机产生交叉。
(7)变异。对给定的种群,在给定概率下进行变异,产生新的个体。染色体中前n位随机选择变异位,然后取反。原基因位值为1,则1变异为0;反之,原基因位值为0,变异为1。
根据上述阐述,给出求解该双层模型遗传算法的主要步骤,算法流程如图1所示。

图1 算法流程图
4 算例分析
为了验证所提出的模型和算法的可行性,本节将利用模型求解实际案例,研究实际案例背景下的最优选址和最优选品方案及总收益。通过与不考虑选品组合的选址方案所对应的总收益进行对比分析来说明本文所提出模型的有效性。
4.1 数据描述
通过与国内一家大型家居连锁公司合作,获得了该家居公司在广州市5家门店自开业以来截止到2018年9月30日的1 048 576条订单信息数据集。其中,订单信息数据集包含了每个订单ID、订单交易所在的门店ID、订单交易时间、每个订单中所包含的商品的ID 和商品名称、商品吊牌价格以及订单金额。店铺的基本信息如表1所示。

表1 店铺基本信息
4.2 模型的输入
该公司在广州市可供选择开设门店的地点有100个,即n=100,每个地点的位置用该地点所对应的经纬度表示,用(lati,lngi)表示门店i的经纬度;顾客人数为4 000个,即m=4 000,每个顾客的位置用该顾客所在地点对应的经纬度表示,用(latj,lngj)表示顾客j的经纬度。由于数据中没有给出可供选择的店铺地址以及周围顾客的地址,故在广州市所在的经纬度区间内,抽取100组均匀分布的值作为可供选择的门店地址。同理,抽取6 000组均匀分布的值作为样本中顾客的地址。顾客j到门店i的距离运用以下公式计算:

通过所给数据,拟合出每个店铺每单收益与店铺内所摆放不同商品个数的函数πi(zi)。假设πi(zi)是关于zi的二次函数,即πi(zi)。以5家店铺的订单信息为例进行回归分析。首先计算出5个店铺每天所摆放的不同商品的个数,以每个商品的首次售卖日期和最后一次售卖日期作为商品的起止售卖日期,并假设在此期间该商品一直在店内摆放,然后计算出店铺每天的总收益,最后对平均每单的收益和每天所摆放的商品个数进行回归分析,回归结果如表2所示。

表2 π1(z1)的回归结果
由表2可以看出,回归结果显著,其中平均每单收益和产品个数的关系的拟合结果如图2所示。通过回归分析可得
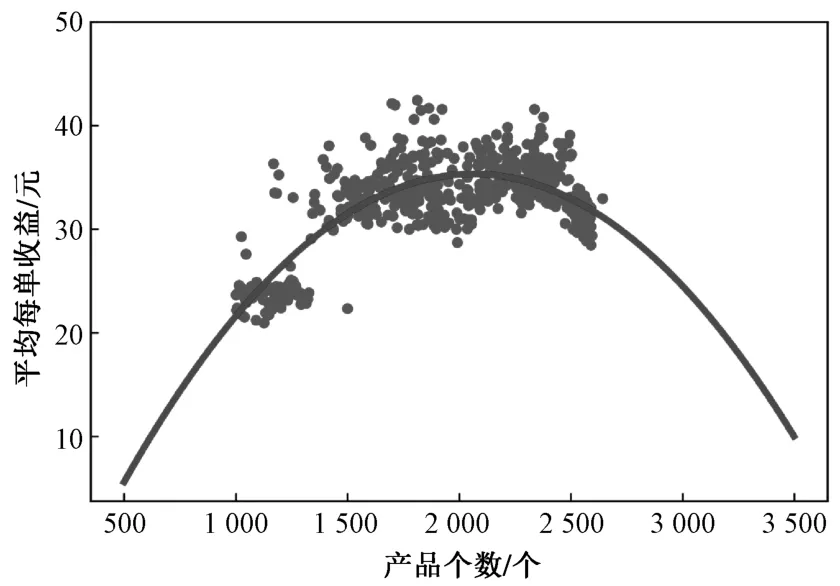
图2 拟合结果
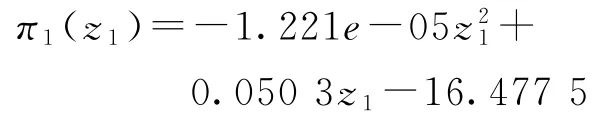
然后以回归结果中的均值和方差为参数,随机生成100个正态分布随机数,作为这100家门店的每单收益函数πi(zi)中一、二次项系数和常数项值。
其他相关参数设为:每次的交叉概率pc=0.8,每次的变异概率pm=0.1,最大迭代次数gn,max=80,遗传算法的种群规模popSize=2 000。
4.3 计算结果
基于上述数据和参数求解模型。由于遗传算法计算出的结果随机性较大,为了降低随机性,对于考虑产品组合的选址模型独立运行该算法10次,记录每次运行结果中的x值和z值。首先生成1~6 000区间内的4 000个均匀分布的随机整数,以这些整数作为索引选出对应的顾客作为样本顾客,重复上次过程10次,得到10个随机样本。然后将模型1(不考虑产品组合的选址模型)每个样本所对应的模型运行10次,记录每次运行结果中的x值和z值,以及遗传算法每次迭代所对应的最优上层目标函数值,并计算这些值的平均值,如表3 中第2、3 列所示。接着,根据模型1所计算出的x值,作为模型2中x的输入值,将模型2每个样本所对应的模型运行10次,记录每次运行结果所对应的最优上层目标函数值,并计算这些值的平均值,如表3 第4 列所示。其中,考虑产品组合的选址模型相对于不考虑产品组合的选址模型所提高的收益百分比等于模型2的最优目标函数值与模型1每次最优目标函数值之差除以模型1每次最优目标函数值,如表3中第5列所示。由表3可以看出,两个模型的计算结果都较为稳定。

表3 实例的运行结果
图3所示为选品个数箱线图,其中,红色“.”表示模型1所对应的选品个数,绿色框表示模型2所对应的选品个数。由图3 可以看出,考虑产品组合时的选品个数中位数与不考虑选品组合时的选品数量差值的绝对值在10%以内。由此可见,即使在各店铺产品个数个性化的情况下,商品个数的变化并不是太大,然而利润却有显著提升,这也进一步说明通过个性化选品来改善企业利润是一个有效的途径。
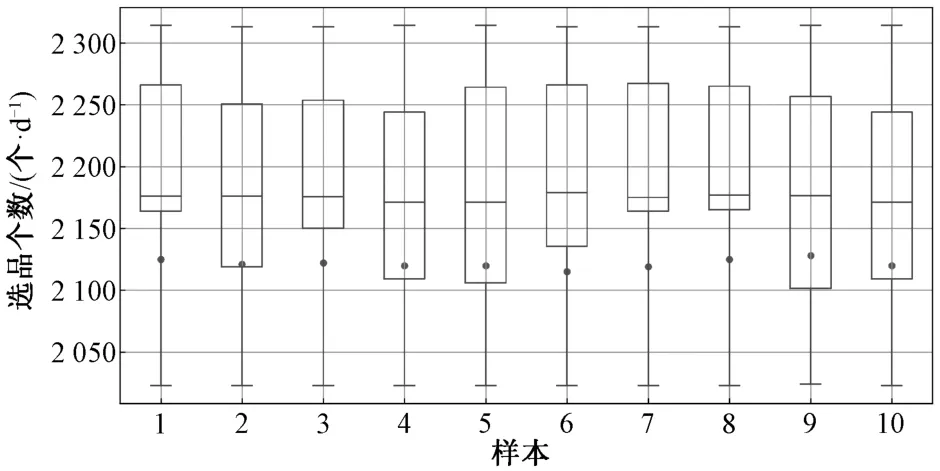
图3 选品个数箱线图
图4所示为每个样本10次运行结果的收益变化曲线。由图4可以发现,每个样本运行10次的结果均较为稳定,且本文所提出的考虑产品组合的选址模型对应的方案的总收益均高于不考虑产品组合时的收益。每个样本的10次运行结果总收益差值的平均值(单位:元)分别为5 527.7、5 402.23、5 442.61、5 513.66、5 165.76、5 525.71、5 495.69、5 525.78、5 404.75和5 512.03。

图4 每个样本10次运行结果图
在每个样本中不考虑产品组合的选址模型的10次运行结果中挑选出目标函数最大的结果,其对应的目标函数值的变化情况如图5中红线所示。由图5可见,求解时算法收敛较快,计算23次时上层目标函数值趋于平稳。同时,从每个样本中考虑产品组合的选址模型的10次运行结果中挑选出目标函数最大的结果,其对应的目标函数值的变化情况如图5中绿线所示。由图5还可见,求解时算法收敛较快,计算18次时上层目标函数值趋于平稳。

图5 遗传算法的收敛曲线
通过上述结果对比分析可以发现,考虑产品组合进行门店选址时,公司获得的利润高于不考虑产品组合时的利润,进而也说明本文所提出的考虑产品组合选址模型的有效性。
5 结论
对于现代零售企业而言,线上零售已经实现了针对客户行为的“千人千面”商品展示效果,以提高线上流量转化率。因此,面对线上的分流和竞争,对于当今企业线下零售的连锁布局,既要充分考虑线下门店选址的合理性,也要考虑线下进店客流量的有效利用和转化效率,这就需要在门店的商品匹配度上建立多一层策略思考。
而线下门店选址的合理性既包含该企业对单店财务模型预测的风险控制问题(租售比/客流量/装修摊销/周边竞争因素等),也包含了该企业如何有效控制和降低由于同一业务同城多店之间的内部竞争分流所带来的负面影响问题。企业出于线下客流量转化效率优化的考虑,也需要进一步针对每个特定商圈自己门店的商品组合结构的差异性,以及这个商品组合和对应商圈客户需求的匹配,及时做出因地制宜的调整,以提高产品出样效率,进而提高开店成功率,同时提高客户的满意度。
本文针对实体门店的选址优化问题,提出了考虑产品组合的双层规划选址模型。其中,上层模型是以公司利润最大化为目标,下层模型是以顾客的购物满意度最大为目标。为了测试模型和算法的实用性,以国内某家居行业的选址问题为例,对提出的方法进行实际应用。与已有的研究成果相比,本文提出的方法考虑了影响实体门店运营的另一重要因素,即门店的选品决策,弥补了以往研究成果中将选品和选址进行单独决策的不足。数值算例分析表明,本文提出的考虑产品组合的选址方法可以进一步提升公司的总利润。
