融合情感特征的卷积神经网络情感分类模型
2021-12-07徐新燕张顺香
徐新燕,张顺香
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
1 引言
随着神经网络的不断研究,基于深度学习的方法被广泛应用到文本情感分析[1]任务中。卷积神经网络(convolution neural network,CNN)是目前比较热门的深度学习模型之一[2,3],但是传统的神经网络应用在情感分类中存在几个缺点:1)词向量特征输入太过单一,忽略词语自身的词性和情感特征。2)通常使用最大池化法来提取特征,忽略了粗糙的位置信息而导致的情感分析欠佳。
为了解决上述问题,本文提出的融合情感特征的情感分析模型,将词语、词性、词语情感特征向量化后拼接作为模型的输入层,利用多特征融合解决同词不同义问题和表达多情感特征信息;采用分段池化[4]的方法,综合句法结构位置特征,提高整个情感分类的准确性。

图1 融合情感特征的文本情感分析
2 相关工作
目前,情感分析主要有基于情感词典[5,6]和基于机器学习[7]两种方法,而随着神经网络的不断研究,基于深度学习[8,9]的方法被广泛应用到文本情感分析任务中。
首先,基于情感词典方法需要构建一个情感词典,然后对情感词的情感极性和强度进行手工标注,最后通过文本情感阈值来判断情感倾向。Zhang 等人通过程度副词词典的提取和构造,网络词词典、否定词词典等相关词典来扩展情感词典[10,11]。栗雨晴等人通过双语情感词典的构建对微博语料进行多类情感分析,以更精确的发现舆论倾向[12]。因为情感词典的构建需要大量的手工标注,所以分类的效率一般。基于机器学习的方法,首先数据集需要人工标注,然后根据设计,提取情感特征,最后构建分类器对文本进行情感分析[13]。Maria 等人通过对词典特征和词嵌入特征的联合,利用SVM 模型在多个公开数据集上提升了情感分析的准确率[14]。
目前,许多学者将神经网络运用至自然语言处理中,相较于传统的机器学习方法,深度学习更容易捕获文本中的复杂关系,对于高维数据的处理速度更快[15]。Zhang 等人使用卷积神经网络(CNN)和其他经典的机器学习方法进行结合,获得比传统的机器学习方法更好的性能[16]。王盛玉等人在卷积神经网络输入层之后利用注意力机制层有选择地进行局部重要特征提取[17]。梁斌等人通过结合多种注意力机制有效获取更深层次的情感特征信息,有效识别不同目标的情感极性[18]。Hai 等人利用深度学习模型能够捕获文本的句法和语义特征,而无需高级特征工程的特性,为基于方面的情感分析提供深度学习方法[19]。程艳等人提出了C-HAN 优化模型,利用卷积层学习词向量间的联系与组合并将结果输入到基本单元为双向循环神经网络的层次化注意力网络中判定情感倾向[20]。Meb 等人提出了一种基于注意力的双向CNN-RNN 深度模型,通过考虑双向的时间信息流来提取过去和将来的上下文[21]。
在上述工作的基础之上,本文主要针对词向量特征输入太过单一问题,将词语自身的情感特征向量与词向量相结合,提出一种融合情感特征的情感分类模型,并通过现有的公开数据集验证其效果。
3 情感分析模型
本文通过对输入层词向量进行改进,旨在词语的语义向量上引入词语的情感极性和词性,形成融合情感特征的词向量,使模型能够提取出更为多样的隐含信息,进而提高情感分析性能。主要有输入层、分段卷积层、池化层、输出层。
3.1 输入层
输入层是融合情感特征的卷积神经网络模型的输入层,是由词向量、词性特征向量和情感词特征向量构成。对文本数据集进行分类,需要将数据向量化转换成模型可识别的数学矩阵,但是现有的词向量方法存在一定局限性,容易忽略词语自身携带的情感信息以及无法解决同一词语不同词性而导致的不同词义问题。
1)词向量
本文以句子为单位,将每个词映射为连续值向量。假设句子最大长度为n,对于给定的句子序列,X={w1,w2,…,wn},通过在词向量矩阵中查找每个词wi所对应的词向量xi,通过将句子序列的词向量拼接起来,即可得到整个句子序列的词向量,如下式(1)所示。
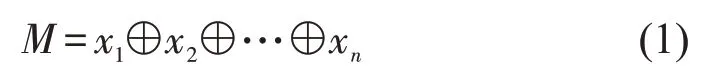
其中,M 是拼接后整个句子序列词向量矩阵,⊕为拼接操作。
2)词性特征向量
本文在对句子进行中文分词时,利用结巴分词工具对分词后的每一个词的词性进行标注,如表1 所示。
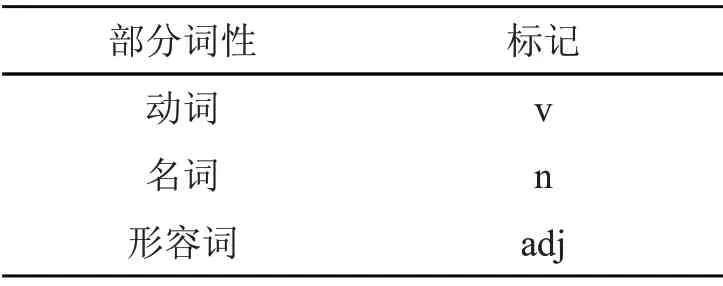
表1 词性标注说明
将标注好的词性,经过与词向量一样的向量化操作,转换成连续的多维向量pi∈Rk,pi表示词wi对应的词性向量,k表示词性向量的维度,如式(2)所示。
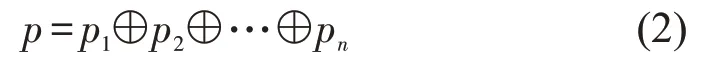
3)情感特征向量
本文利用Hownet 情感集合对句子序列中重点词语进行特征标注,如表2 所示,通过对句子的重点情感词性进行标注,有助于保留对情感分类有重要作用的词语信息。
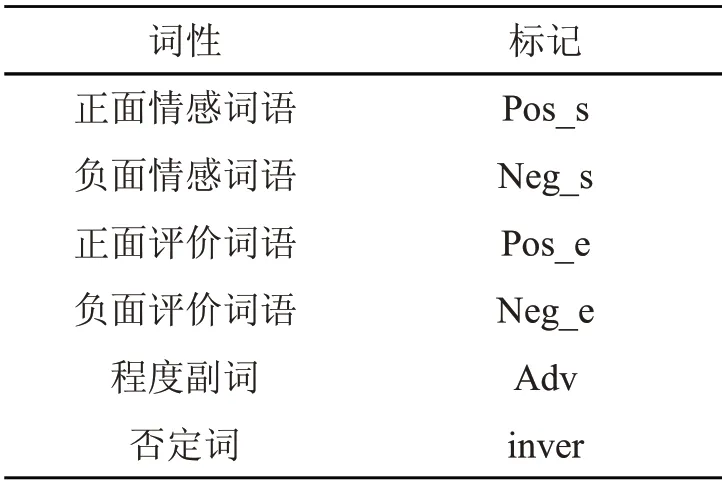
表2 情感词性标注说明
将标注好的情感词性,经过与词向量一样的向量化操作,转换成连续的多维向量ei∈Rm,ei表示词wi对应的情感特征向量,m表示情感特征向量的维度,如式(3)所示。
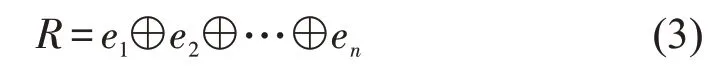
将上述得到的词语语义向量、词性特征向量和情感特征向量进行融合,本文采取前后依次连接将三者融合,得到扩展后的融合特征的词向量Q,拼接公式如式(4)所示。
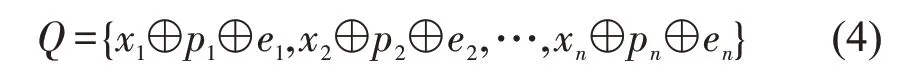
3.2 卷积层
在卷积操作中,不同尺寸的卷积核大小,可以提取更丰富的上下文特征信息,提取的特征如式(5)所示。

其中ci表示经过卷积运算得到的第i个特征值,xi:j+h-1∈Rh×d代表h个词构成的局部滤波器窗口,h×d代表卷积核窗口高度是h,维度是d,b∈R为偏置项,f(g)为卷积核函数。经过卷积操作后得到的特征序列如式(6)所示。

3.3 分段池化层
池化层是减少经过卷积操作得到特征图的大小,从而减轻后续的计算量。多数卷积神经网络池化采用最大池化方法,对于情感分类,但是该方法在通情感分类中往往会丢失位置特征而导致情感分析结果欠佳。为了获取多个关键特征,本文采用分段池化的方法,将所有计算出来的最大特征图组成一个一维向量。
3.4 输出层
本文输出层是将池化层后得到的特征图以全连接的形式进行连接,然后输入到Softmax 分类器中,将文本分别划分为积极情感和消极情感两种类别。
4 实验及结果分析
为了验证本文模型的效果,将基于word2vec的SVM 方法、基于传统的CNN 方法与本文方法进行对比。本文数据集选取的是谭老师整理的ChnSentiCorp-Htl-ba-8000 酒店评论语料库,正负各有4000 条。
4.1 实验性能评价指标
本次实验的评估指标采用的是准确率(Precision)、召回率(Recall)和综合度量指标F 值(F)。公式见(7)、(8)、(9)。
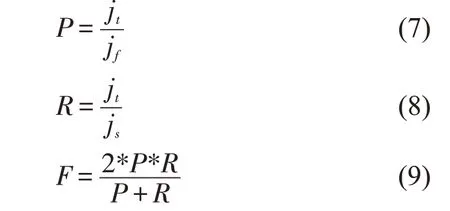
其中,jt表示为判断正确的该类别评论数,jf为判断为该类别的评论数,js为应该判断为该类别的评论数,类别包括正向和负向。
4.2 实验参数设置
实验时为了达到较好的实验结果,需要不断对参数的设定值进行调整与优化,最终为模型选取了实现效果最佳的参数结果,如表3 所示。

表3 模型参数
4.3 实验结果及分析
运用基于传统的CNN 方法、基于word2vec的SVM 和本文方法进行实验,在训练时利用dropout 防止拟合,对酒店评论8000 条数据运用十折交叉法进行验证,取平均值作为最终衡量的标准。具体实验结果如下表4、图2 和图3 所示。
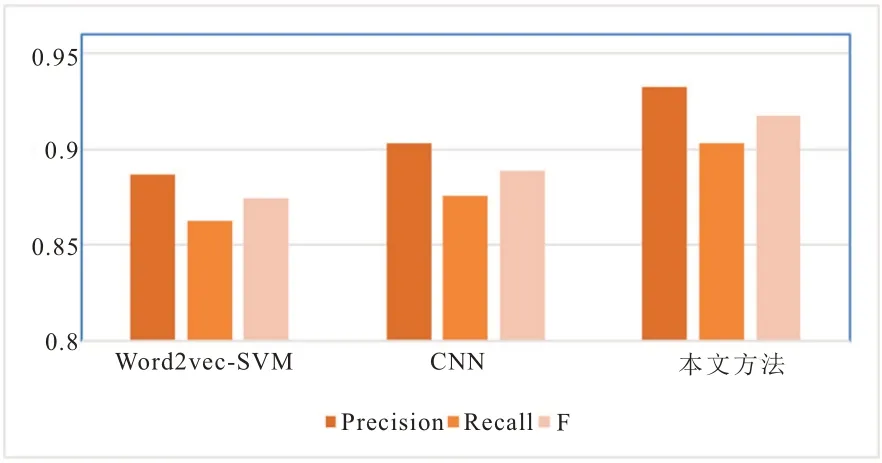
图2 正面评论的情感分类结果
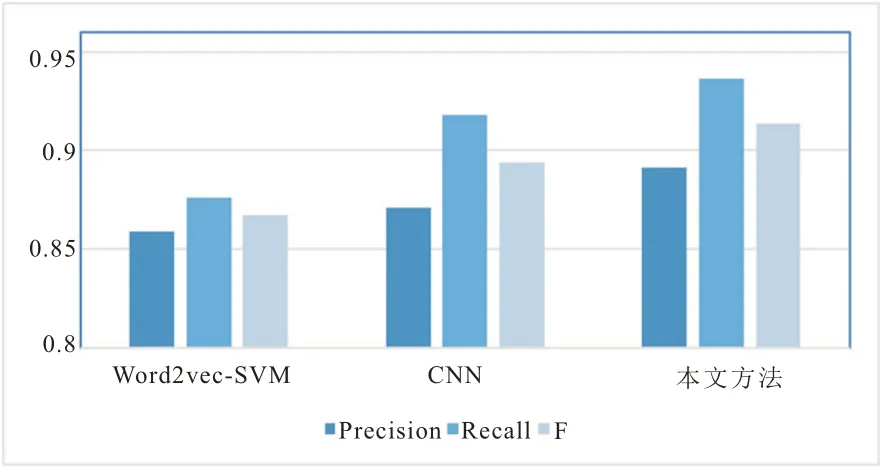
图3 负面评论的情感分类结果
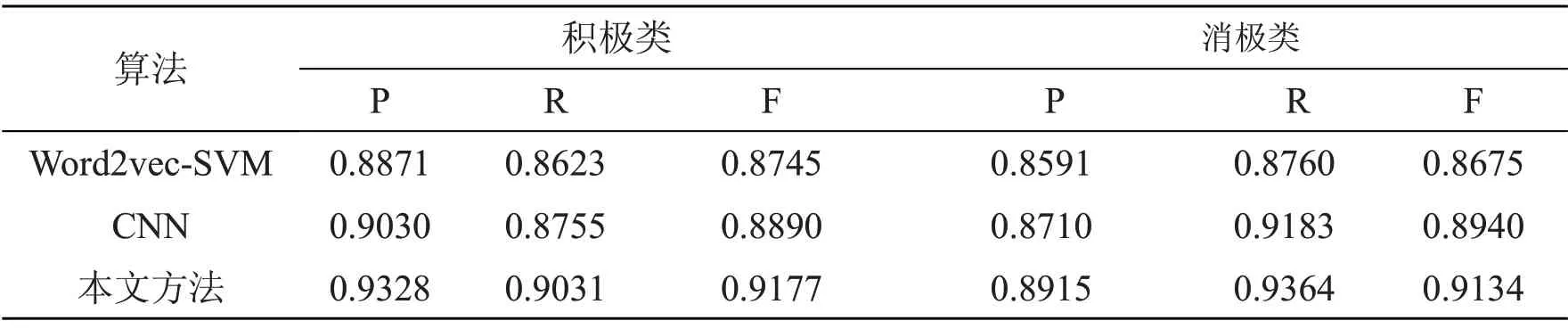
表4 实验对比性能结果表
为了将每个实验结果之间的对比情况更清楚的展示,将表4 中的数据以图2 和图3 的形式进行数据图形化。其中,图2 表示的是正面评论的分类结果,图3 表示的是负面评论的分类结果。
综合图2、3 和表4 的对比结果,可以进行如下分析:本文提出的融合情感特征向量可以提高文本情感分类的正确率,与此同时召回率和Fmeasure 也有所提高,取得了比传统的word2vec-SVM 和CNN 更好的分类效果。相较于传统的CNN 模型,本文方法在积极类的F 值和消极类的F 值分别高于CNN 模型的2.87%和1.94%,主要原因是由于中文词汇的多义性和情感特征的复杂性,传统的神经网络模型并没有将这些作为情感分类的影响因素,而融合情感特征的卷积神经网络情感分类模型将词语自身的词性和情感考虑在内,并利用分段池化方法,综合句法结构位置特征,有效提高文本情感分类的正确率。
5 结论
针对目前词向量特征输入太过单一以及忽略了粗糙的位置信息而导致的情感分析欠佳问题,本文对CNN 方法进行改进,提出融合情感特征的卷积神经网络情感分类方法。实验结果表明,本文提出的方法对于情感分类有较好的效果。
