基于改进卷积神经网络的山顶点识别研究
2021-12-01李凯明孔月萍张跃鹏朱旭东
李凯明,孔月萍,张跃鹏,朱旭东,高 凯
(1.西安建筑科技大学 信息与控制工程学院,西安 710055;2.地理信息工程国家重点实验室,西安 710054)
0 引言
山顶点是一个容易意会却难以量化的地理特征,是地表中最具控制性的特征点之一,其自动识别与准确标注对地学分析、军事测量、道路选址以及城市规划等工作具有重要的理论价值和指导意义[1]。现有DEM(digital terrain model)数据中的山顶点识别方法主要有几何形态分析法[2]、断面高程极值法[3]、水文流域分析法[4-5]和拓扑结构分析法[6]四大类,前两类方法通过计算分析窗口中邻域间的高程变化关系来确定山顶,能够快速提取山顶点,但该类方法多着眼于山顶的局部特征,容易产生误提或漏提的现象;水文流域分析法通过模拟地表水流,进行流域计算模型构造山顶点识别方法,能有效改善分析窗口的局限性,但受到地形复杂性、DEM数据精度等因素的影响,对地形微起伏较为敏感,易出现伪山顶点;而拓扑结构分析法以等间距高程剖分山体,结合地貌、高差提取山顶点,有效减少了伪山顶点的提取,但其需要准确、定量化的特征描述参数,否则提取效果不佳。
上述方法均依赖于人工构建的山顶特征提取模型,而人工选择特征难以对山顶的局部和宏观形态进行准确表达,容易造成山顶的误提与漏提。近年来,以卷积神经网络[7](CNN,convolutional neural network)为代表的深度学习技术在图像处理、目标检测方面显现出巨大优势。CNN通过多层卷积对输入图像进行多阶段的特征提取,对样本数据中隐形特征的表达更为高效准确,在一定程度上可以规避人工选择特征的局限性[8]。以CNN为基础,后有学者提出了应用于目标检测任务的R-CNN(Regions with CNN feature)算法[9],该方法在样本数据中进行选择搜索,生成若干个候选区域,然后对每个候选区进行特征提取,利用支持向量机进行目标分类,但由于没有共享CNN提取的各个候选区域特征,使得检测时间较慢;为了提升模型检测速度,Fast R-CNN[10]和Faster R-CNN[11]算法相继提出。Fast R-CNN模型在R-CNN的基础上融合了SPP-Net模块,采用全图卷积共享特征图的方式对目标检测进行加速,同时精度也有所提升;而Faster R-CNN采用区域建议网络(RPN,region proposal network)代替了Fast R-CNN中的选择搜索算法产生候选区域,在保证精度的同时极大缩减了检测时间,并在交通标志[12]、行人检测[13]、故障巡视[14]等复杂环境的目标检测应用中表现优异,具有良好的模型泛化能力和鲁棒性。
为了克服山顶点识别效果受人工选择特征的制约,将深度学习技术引入到DEM数据的山顶点要素提取领域,提出一种基于改进的Faster R-CNN山顶点识别方法。首先对DEM数据进行预处理,融合等高线图和灰度图两种图像下的山顶特征,并采用ResNet-101替代原始的VGG16作为山顶识别模型的特征提取网络,再利用K-Means聚类算法[15]得出适用于山顶区识别的锚框设定。通过改进后Faster R-CNN网络深度挖掘叠加图像下的山顶形态特征,自动生成高质量的山顶目标区,最后结合高程计算实现山顶点的精准提取。
1 山顶区域数据集构建
DEM数据作为地球表面地形地貌的一种离散化数学表达,与数字图像在数据结构上十分相似,但物理含义有着显著差异[16],其主要区别在于数字图像使用一个点表示整个像元的属性;而在DEM中每个格网只表示点的属性(即地理位置所代表的高程信息),点与点之间的属性则通过内插计算获得。因此直接将深度学习技术迁移到DEM数据中,检测性能还有待研究。通过分析数字图像与DEM栅格数据的异同,借助深度学习方法在数字图像领域的广泛研究与应用,以一种转换与融合的方法对DEM数据集进行处理与构建。
在地理信息领域,等高线地形图是将地面上海拔高度相同的点连成闭合曲线,并垂直投影到一个水平面上,以等高圈的形式描述地形地貌。如山顶、盆地在等高线图中均是以最小闭环的形式进行表达,但其主要反映山地要素的地貌形态,难以通过图像的形式对地形要素的空间高程变化进行准确描述。而数字图像中灰度值与DEM中高程值的组织形式相似,通过对DEM数据进行灰度渲染处理,以多层级的灰度差异反映山地的高程变化。因此,为了有效利用深度网络进行DEM数据中的地形特征提取,以等高线图像反映山地数据的地貌形态,以灰度渲染图表示山地数据中的高程变化趋势,对原始DEM数据作等高线生成和灰度渲染处理,以图像合成的形式融合两种模态下的山顶特征,形成深度网络可接收的学习样本数据。
DEM样本选取SRTM-DEM开源网站中比例尺为1:100万的地形数据,首先根据高程分布遴选出其中的山地部分,裁剪出1 000个大小为640*640的山地数据块,保证每个数据块中最少有一个或多个山顶,并按照图1的方法对DEM数据进行预处理。同时,采用人工的方式进行山顶目标区的框选与标注,利用最小外接矩形的方法对叠加图像中的山顶区域进行标注,保证每个标注矩形框中有且只有一个山顶,并且尽可能少地包含背景信息,以此形成如图2所示的山顶样本数据。其中,图2(a)为叠加后的山地等高线渲染图;图2(b)为样本的标签信息,依次为山顶区域坐标框的左下角坐标(x1,y1)及右上角坐标(x2,y2)和lable标签。如此,建立了包含山顶目标区的可学习样本集PEAK-100,共囊括了3500个山顶样本,并按照7:2:1的比例把山顶样本集分为训练集、验证集与测试集。

图1 DEM数据处理
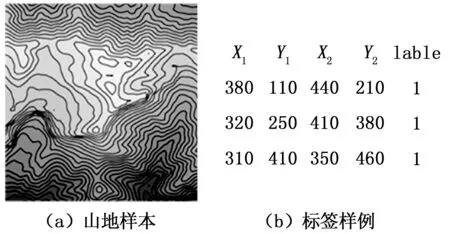
图2 山顶样本数据示意图
2 改进卷积神经网络的山顶点识别方法
为了深度挖掘山地样本中的山顶特征,准确提取出山顶点坐标位置,设计了如图3所示的基于Faster R-CNN山顶点识别框架。首先利用特征提取模块对山地样本中山顶区的形态特征进行深度挖掘,再结合RPN和分类回归网络自动生成高质量的山顶目标区,最后将样本图像中的山顶目标区映射回原始DEM数据中,通过计算目标区中的高程极大值位置作为最终的山顶点坐标。
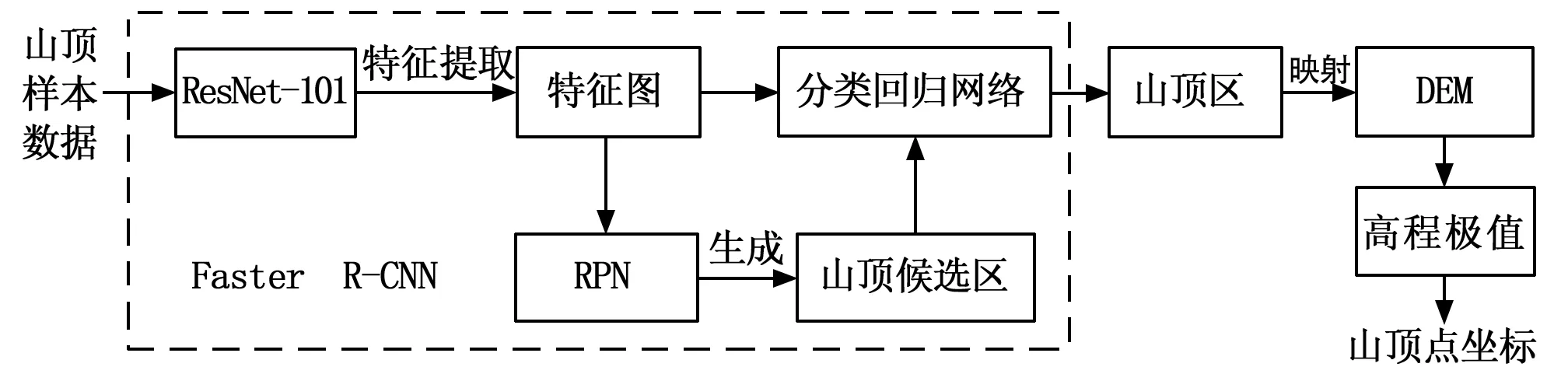
图3 山顶点提取方法处理流程
有效提取山顶形态特征是识别山顶点的关键,为提高山顶区域的识别效果,理论上增加网络层数可以提取更深层次的山顶特征,但实验证明网络层数的过度加深,会导致出现梯度消失等问题,使得深度网络训练精度下降,原始Faster R-CNN网络采用VGG-16作为基础特征提取网络,以13个卷积层进行堆叠,难以避免网络层数过深导致的梯度消失问题。而残差卷积神经网络ResNet(residual neural network )通过引用残差连接,能够在构建深层次卷积神经网络的同时,利用残差模块向下一个网络单元提供在卷积操作中实际丢失的关键信息,从而缓解随着网络深度增加带来的梯度消失问题[17]。残差模块结构如图4所示,其中中间两个卷积层表示进行两次卷积运算,x是残差块的输入值,F(x)是卷积块的输出值,F(x)+x是残差块的输出。因此,为了提取深层次的山顶区域形态特征,选择ResNet-101替代原始Faster R-CNN中的VGG-16网络作为山地样本数据的特征提取模块,用于承担山顶样本数据的特征提取任务。同时考虑到自建山顶样本数据量有限,而卷积神经网络的性能优劣易受到可学习样本量的影响,在此借鉴文献[18]中的技术思路,先利用ImageNet数据集[19]对ResNet-101网络模型进行预训练,冻结提取浅层通用特征的底层卷积块,然后使用自建的山顶样本集PEAK-100对顶层卷积块进行内部参数微调,以迁移学习的方式适应当前山顶区的特征提取任务。
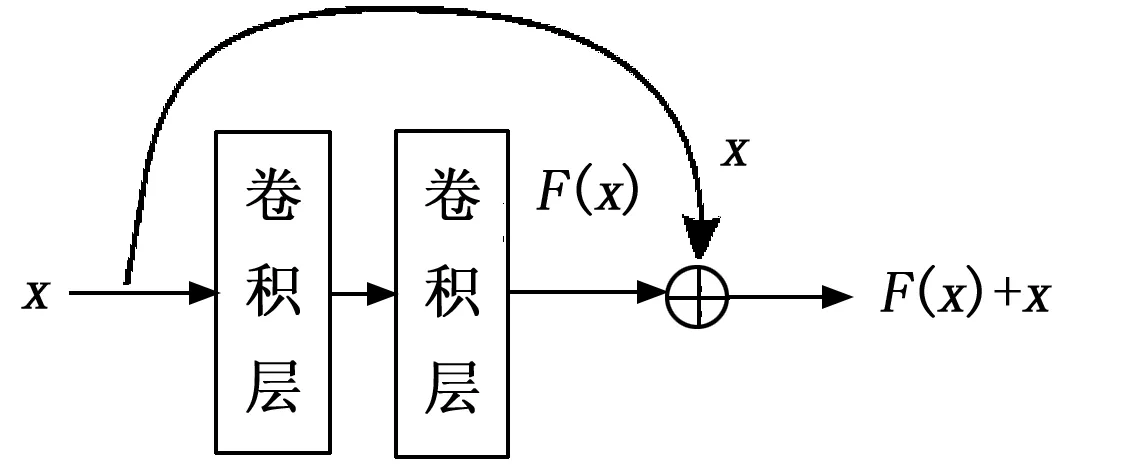
图4 残差模块结构
RPN网络模块是Faster R-CNN的算法核心,其目的在于搜索山地样本中可能存在的目标山顶区。RPN通过滑动窗口形式对ResNet-101提取的山顶特征图继续进行空间卷积,抽取山顶区更深层次的特征,并将所得空间卷积特征图上的每一个像素点映射回原始山地样本的位置,生成大小、比例各异的锚框。在原始RPN网络中是采用3种尺度([128,256,512])和3种横纵比([0.5,1,2])的参数设定在每一个滑动窗口的位置中心生成9个锚框。而山地样本数据中的山顶区域尺寸大小各异,直接使用默认的锚框参数难以实现山顶区的精准识别与定位,为了提高山顶要素的识别精度,预先采用K-means聚类算法根据山顶标注样本设定适用于山顶目标区的锚框参数,并对原始锚框尺寸进行替代优化。其中K-means算法的主要思想是将多个样本根据相似性划分于不同类别中,在此以自建山顶训练集中的标注框大小作为聚类算法的输入,通过对样本集中的标注框进行聚类分析,确定适用于山顶区识别的锚框参数设定。
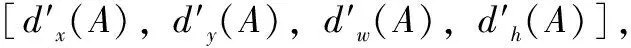
(1)
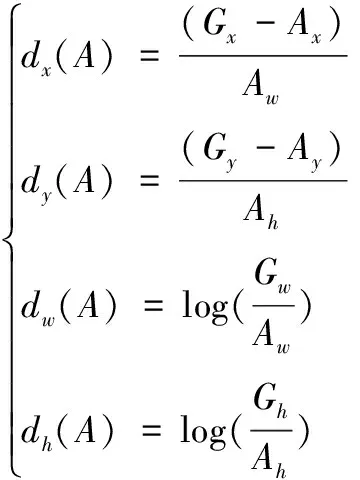
(2)
RPN网络模块获取山顶候选区后,借助分类回归网络对候选目标区进行识别与修正。感兴趣区域池化层将候选区域映射回原始特征图上的位置,得到各山顶候选区对应的特征图。由于得到的候选山顶区大小形态各异,为进一步进行山顶区的识别与筛选,需进行经最大池化后再同时输入最终的分类层和回归层进行计算,输出每个候选框符合山顶特征的概率值,并再次对候选框进行回归计算,利用边框偏移量对候选框进行坐标微调,使之更接近于理想的山顶区。为了在获得的山顶区域中准确标注出山顶点,将山地图像中标识出的山顶目标区映射回原始DEM数据中,通过计算该区域中的高程极大值点即可标定出准确的山顶点坐标,计算方法如式(3),其中bij为山顶点位置,αij为坐标(i,j)处的高程值。
(3)
3 实验结果与分析
山顶点识别模型实验环境基于Windows10操作系统,计算机配置处理器为AMD锐龙5 2600X,运行内存为16G,显卡型号为NVIDIA GeForce GTX 2060,以TensorFlow作为深度学习框架,并以自建的山顶样本集PEAK-100进行网络训练,模型的初始学习率为0.001,动量为0.9,迭代次数为10 000次。锚框初始尺寸参数则利用K-means聚类算法对山顶训练样本中的标记框进行设定,以山顶区标记框的左下角坐标和右上角坐标分别计算其宽度和高度,作为聚类算法的数据样本,其中设定的K-means聚类算法的准则函数为:
(4)
式中,k为聚类类别数,Sj为第j类的样本合集,mj为Sj的样本均值,设定J=0.01,以k=2,3,4,...,对训练样本中的标记框大小进行聚类分析,得到如图5所示的结果,可知相对于其它聚类结果,当k=4时,能够将数据集中的锚框几乎均匀的分为4种不同尺寸种类,因此,根据聚类分析结果,将聚类中心对应的坐标参数作为Faster R-CNN网络的锚框初始尺寸设定,即以(41.48,50.49)、(63.40,82.33)、(93.13,121.91)与(131.94,194.44)的4种长宽比例替代原始的锚框参数作为每一个山顶区目标的初始锚框设定值。
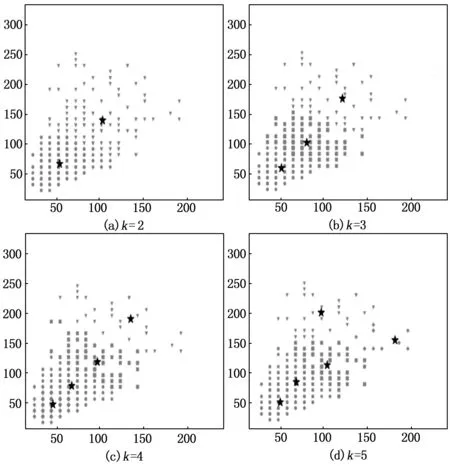
图5 K-Means算法聚类结果图
为评价山顶点提取结果,以山顶点识别的准确率、误提率和漏提率作为模型评价指标。其中准确率Rd是指识别出的正确山顶点占识别结果的比率;误提率Rw表示识别出的山顶点中误提数所占的比率;漏提率Ru表示山顶漏提数占真实山顶数的比率。计算公式为:
(5)
(6)
(7)
式中,TP为识别结果中正确的山顶点个数;FP为识别结果中误提的山顶点个数;Fl为识别结果中漏提的山顶点个数。
为了测试改进Faster R-CNN中ResNet-101网络模块对山地样本特征提取的有效性,选取如图6的浅层山顶特征图进行可视化表达。可以看出,ResNet-101网络对标注的山顶区进行多阶段的特征提取,对山顶区的位置、形态有着良好的信息表达能力,说明该网络模型能够自动挖掘山地样本中的山顶特征。

图6 特征图可视化
在数据处理阶段,通过将DEM数据以等高线图与灰度渲染图的形式进行叠加,融合两种模态下的山顶特征。为了验证该数据处理方式的有效性,对不同模态下的山顶区识别效果进行对比实验,实验结果如图7所示,图(a)为灰度渲染图的识别结果,图(b)为等高线图中的识别结果,图(c)为叠加处理后的识别结果,其中,A和B框为误提、漏提的山顶区,同时分别在自建的山顶样本集中进行测试实验,统计结果如表1所示。可以看出,由于等高线图或灰度图在单模态下难以完整表述山顶的形态特征,容易造成山顶区的误提与漏提现象。其中在灰度图下的山顶识别精度较低,这是由于灰度图中的山顶形态不易确定,仅能表述山顶的高程变化趋势,候选框难以准确标定出山顶目标区;等高线图则主要反映山顶要素的轮廓形态,难以通过图像的形式对山顶要素的高程变化趋势进行准确描述,易出现山顶区的误提现象。而通过结合灰度图与等高线图两种模态下的山顶形态特征能够有效提高山顶区的识别效果。

图7 不同模态下的山顶区识别结果
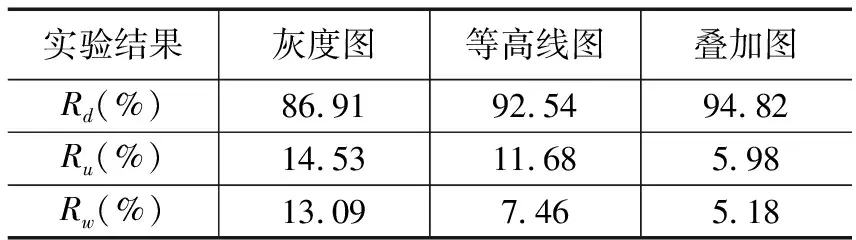
表1 不同模态下的识别结果对比
为了验证新方法在不同地貌的山顶点提取性能,另外选取我国具有代表性的三大地貌阶梯中的中起伏低山(数据I)、大起伏中山(数据II)、和大起伏极高山(数据III)对新方法进行测试。图8为不同地貌下的山顶点识别结果,其中方框为新方法识别出的山顶区域,圆点为提取的山顶点,A类点为误提的山顶点。从实验结果中标定的山顶点位置可知,识别出的山顶点均位于山地高程极值处,符合山顶点要素的定性描述特征,其中误提的山顶点其周围形态也较符合山顶的区域特征,说明深度网络模型是以山顶区所呈现的空间形态作为主要特征进行学习的。

图8 基于Faster R-CNN网络的山顶点识别结果
此外,还设计实现了拓扑分析法[6]、等高线剖分[20]、原始Faster R-CNN与新方法进行对比实验,各种方法分别在自建PEAK-100山顶测试集上的实验统计结果如表2所示。结果表明,新方法利用改进的Faster R-CNN深度网络模型实现山顶的自动标识,虽仍存在山顶的误提与漏提现象,但相比于传统方法山顶的识别更为准确,漏提和误提的山顶点更少,表明改进的Faster R-CNN网络模型能有效学习山顶区所呈现的形态特征,避免了人工选择特征的局限性。

表2 新方法与其他方法对比实验结果
4 结束语
针对传统山顶点识别方法中人工选择特征困难等问题,以DEM中的山顶要素为研究对象,结合深度学习技术,设计了一种基于改进卷积神经网络的山顶点识别方法。通过将DEM数据变换为等高线图和灰度图叠加的形式,选择ResNet-101自动提取山顶的深度特征,同时利用K-Means算法对Faster R-CNN网络模型中的锚框尺寸进行优化设定,实现了山顶的自动化标识。实验结果表明,该方法有效避免了山顶要素提取易受人工选择特征的影响,提高了山顶点的识别精度,为DEM中的山顶要素识别提供了新的技术途径。但因自建的山顶样本集数据量有限,提取结果中仍会出现一定的误提、漏提的现象,今后可通过数据增广等方法来充实DEM地形样本数量,提高深度学习模型的数据支撑。
