基于递归神经网络的英译汉机器翻译模型设计与实现
2021-12-01樊同科
杨 璐,樊同科
(1.西安外事学院 国际合作学院,西安 710077;2.西安外事学院 工学院,西安 710077)
0 引言
翻译是将一种语言转换成另一种语言,翻译可以是逐字翻译,也可以是逐句翻译。在逐句翻译中,获得的信息比逐字翻译要多[1]。汉语是世界上使用人数是最多的语言,其使用人口约为14亿。机器翻译长于文本或者语音翻译,因此机器翻译系统在快节奏的语言交流领域扮演者重要作用[2]。与此同时,机器翻译是开放系统,具有泛化学习能力,随着新数据添加到模型,能够进行独立的更新替换。机器可以处理多维数据以及多种数据,机器翻译有助于节省时间,所以人们不必花时间在寻找字典来翻译一个句子,提高了生产率。
利用机器学习算法将英语翻译成汉语,采用自然语言处理使机器翻译智能化。语言处理方式日益丰富,许多研究定义了自然语言处理的体系结构,有些研究涉及英译汉翻译的改进,也有一些研究是简单句子结构和不同机器翻译系统的比较。然而,目前对复杂句子结构和句子重复意义的研究还比较少[3-7]。本研究的目的是设计一个基于递归神经网络(RNN,recursive neural networks)的英汉机器翻译体系结构,综合词汇的句法分析因素和注意权重,用RNN设计机器翻译系统的体系结构,并测试了机器翻译系统的性能。
1 方法论
采用自然语言处理可以使机器翻译智能化,研究人员提出了许多机器翻译的解决方案,对于英语到印地语的翻译,使用了两种编码器-解码器神经机器翻译结构,它们是卷积序列到序列模型(ConvS2S)和递归序列到序列模型(RNNS2S)[3]。在训练数据中,使用了1 492 827个句子,其中英语20 666 365个单词,印地语22 164 816个单词。递归序列到序列模型使用Nematus框架进行训练,卷积序列到序列模型使用Fairseq-5进行训练,Fairseq-5是Facebook开发的一个开源库,用于使用卷积神经网络(CNN)或递归神经网络进行神经机器翻译。研究结果表明,卷积序列到序列模型在英印翻译方面表现更好,这将有助于解决本文提出的英汉翻译问题。在基于语料库的方法中,使用一个主语文件和一个动词文件,解决了文献[4]的翻译问题。对于每个主语,都有一个对应于其动词的标记,并选择最合适和最有意义的句子进行最终翻译。结果显示,与谷歌翻译程序相比,该译码器具有更好的性能。
对于另一个英语到印地语的翻译,使用了前馈反向传播人工神经网络[5]。在实现方面,采用Java作为主要编程语言,实现了除神经网络模型外的所有规则和模块,并在Matlab中实现。这里,训练数据由编码器编码成数字形式,编码器也是用Java实现的。使用BLEU来计算系统的得分,BLEU分数也被用于测试训练模型。另一种维吾尔族语到汉语的神经机器翻译方法采用RNN编码器-解码器框架方法实现[6],其中一些训练过程和数据集被用来实现这两种模型。以上研究的结果表明,递归神经网络比传统的RNN编码提供了更好的结果。
1.1 数据收集
为了使用机器学习算法进行训练,本文收集了数据集,文中研究的主要数据集是英语和汉语平行句。对于每一个英语句子,都需要一些对应的汉语句子来训练和测试智能系统。数据集是从一些文章中收集的,这些文章是由手工编写的英语和汉语,英语和汉语句子的最大长度均为7。数据集由4 000个英语和汉语平行句组成,数据集被分成4:1的比例分别进行训练和测试。
1.2 预处理
为了规范化数据集,需要执行文本预处理步骤。句子的所有字母都被转换成小写,所有的标点符号都被删除,不属于英语和汉语的字符也会被删除。对于模型设计原型,利用Tensorflow-Keras Python软件包建立了神经网络的设计模型[7]。
2 模型构建
2.1 标记化
数据集必须在初始状态下实现标记化,对于每一个英语和汉语句子,所有的单词都根据频率进行标记。Tensorflow有一个标记器库,用于将单词映射为相应的整数。
然后,将所有单词替换为一个记号数字,并存储在英语和汉语句子的列表中。表1的英文句子转换如下:

表1 标记化映射词

511331
相应的汉语标记化句子转换如下:

721141
每个句子的长度不是固定的,为了使所有标记化的句子具有相同的长度,将应用填充。英语和汉语句子的最大长度均为7,因此,未填入的空格用0(零)填充。
英语标记化序列为:

511331000
汉语标记化序列为:

721141000
输入的数据是矢量化的,因此数据集可以输入到神经网络模型中。
2.2 词汇上下文向量
根据存储的上下文向量,可以预测英语标记化句子。为了生成上下文向量,将英语和汉语的标记化句子作为输入,英语和汉语映射的标记为注意权重,注意权重代表汉语标记化序列对英语标记化序列的注意。
score=Sigmoid(denseLayer+hiddenLayer)
attentionWeights=Softmax(score)
contextVector=(attentionWeights?encoderOutput)
(1)
利用式(1)生成上下文向量,图1所示为用于生成上下文向量的网络,训练序列的输入为英语-汉语平行句。RNN的嵌入层对标记序列进行归一化处理,并将输出作为GRU或LSTM层的输入。为了测量性能,本研究实现并测试了GRU和LSTM。使用Sigmoid和Softmax激活函数激活密集层和隐藏层的输出,同时测量注意权重的得分,以便进行性能评估,通过将编码器输出和注意权重相乘来生成上下文向量。
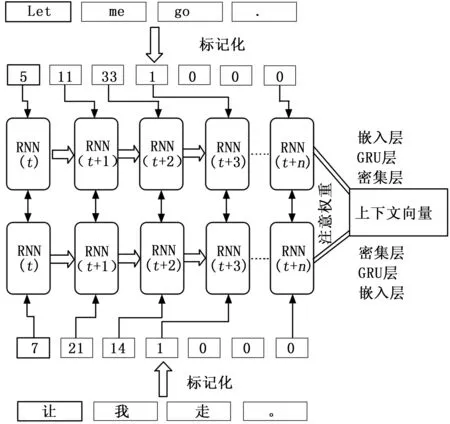
图1 生成上下文向量的训练模型
2.3 递归神经网络
递归神经网络(RNN)模型采用顺序输入的方式[8],即一个节点的输出作为另一个节点的输入或偏置。由于一个句子中的单词具有关联意义,因此采用RNN模型进行研究。
1)编码器:
编码器由输入嵌入层、GRU层和隐藏输入层组成。输入嵌入层用于对数据集进行规范化。GRU层使用门控循环单元(GRU,gated recurrent unit)[9],为了测试性能,也可使用长短时记忆网络(LSTM,long short term memory network)来代替GRU。使用不同的激活函数来衡量模型的性能。编码器输出的批量大小为64,序列长度为7,共1 024个单元。
2)解码器:
解码器的第一层由嵌入层构成,然后使用GRU作为类似编码器,激活函数在GRU层工作。在GRU之后,用总词汇大小作为密集层。与Bahdanau注意力机制类似,用于制作上下文向量。
3)注意方法:
本设计采用了注意机制,英语单词重点集中于由注意权重测量的汉语词汇[10]。使用Sigmoid激活函数对两个密集层的输入进行归一化,并计算得分权重,权重也用Softmax或Sigmoid激活函数进行归一化。
4)激活函数:
为了进行性能比较,使用了一些激活函数,激活函数的主要作用是将输入序列标准化。
双曲正切激活函数式(2):
(2)
其中:x为序列的值。
线性激活函数式(3):
F(xi)=wixi+b
(3)
其中:wi和b分别表示线性激活函数的斜率和截距。
Softmax激活函数式(4):
(4)
Sigmoid激活函数式(5):
(5)
在激活函数中,i=1,…,k;x=(x1,x2…,xk)∈Rk,表示标记序列。
Softmax和Sigmoid的激活函数如图2所示。
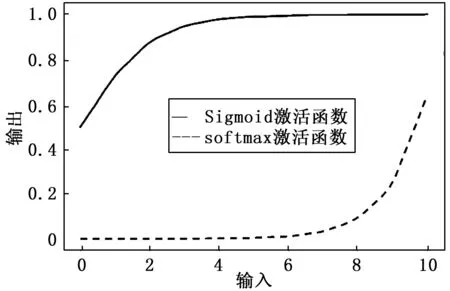
图2 Sigmoid和Softmax激活函数
所有这些激活函数都用于编码器GRU层、解码器GRU层和注意层,从而寻找注意权重。
5)损失函数:
为了训练RNN模型,对误差进行了计算,并利用反向传播损失函数对模型进行了改进。Tensorflow有一个稀疏的分类交叉熵函数库,用于计算误差。
分类交叉熵函数如下:
(6)
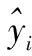
6)优化和学习率:
优化部分包括数据预处理和归一化,优化的另一个因素是学习率。
LearningRate(学习率)=1e-3=0.001
学习数据集使用了Adam优化算法[11],Adam是RMSprop和随机梯度下降的组合。在本研究中使用Adam的主要优点是在训练数据集期间可以进行时间优化。
对于英文输入句“Let me go”整体模型如图3所示。上下文向量模块表示在该部分定义的映射英语和汉语标记化句子的训练模型数据集[12]。一旦对输入句子进行标记和填充,序列就可以进行RNN输入。在RNN编码器中,第一层是嵌入层,第二层是GRU层。

图3 英译汉的机器翻译模型
解码器与编码器相似,不同的是解码器有一个密集层,该层根据注意分数返回相应的标记序列,在移除填充之后,标记器将序列解码成汉语句子。
3 结果与讨论
本文模型设置了检查点,模型的对象保存在本地驱动器中,并从上一个检查点恢复。对于每一次的训练数据都有助于提高性能。模型的性能用损失函数,即式(6)来衡量,本研究进行了30个阶段的性能评估,模型的精度取决于误差。为了使系统误差最小化,采用了不同的方法,比较了编码器、解码器和注意层的激活函数。本文还以最佳激活函数测量了GRU和LSTM的性能。
3.1 输入输出层
对于输入层,双曲正切激活函数和线性激活函数在实验中表现最好。编码器的第一层是嵌入层,在嵌入层中对标记化序列进行归一化。将所有序列转换成嵌入格式后,在GRU层测试双曲正切激活函数和线性激活函数,以测量系统的性能。
模型损失如图4所示,从图4可以看出,编码器的线性激活函数和解码器GRU层的双曲正切激活函数具有稳定的性能[13]。为了交叉检查双曲正切激活函数和线性激活函数的误差和性能,对4种组合进行了评估。

图4 模型损失
由表2可知,编码器GRU和解码器GRU的线性激活函数均增加了0.805的误差,编码器线性和解码器双曲正切激活函数的平均误差为0.740,另一个编码器的双曲正切激活函数和解码器线性激活函数的损耗为0.783。
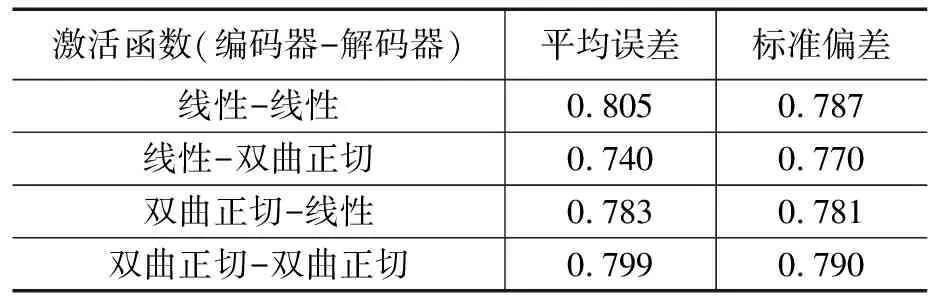
表2 价值损失平均值
3.2 注意层
注意层由两个激活函数组成,一个用于输入,另一个用于将输出归一化为注意权重。这里使用了Sigmoid激活函数和Softmax激活函数。使用了Sigmoid激活函数和Softmax激活函数的所有组合来评估系统的性能。
如图5所示,Sigmoid函数给出了注意层的最佳性能。注意层输入的Sigmoid函数和输出注意层的Softmax函数都是有效的。
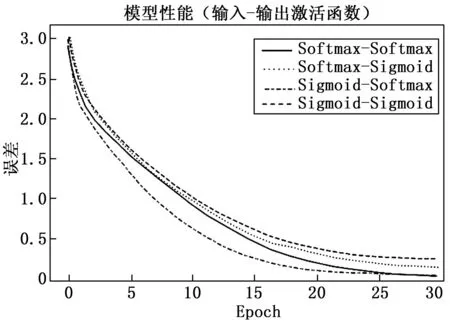
图5 基于注意层激活函数的模型损失
3.3 LSTM和GRU
在嵌入层之后实现了GRU层,也可以使用LSTM层来代替GRU[14-17]。在图2中,运行了50个epoch,并且使用了输入输出层和注意层中性能最佳的激活函数。但随着epoch的增加,门控循环单元(GRU)的误差和损失也会减少。为了获得最佳的性能,使用一些参数如中央处理器(CPU)、随机存取存储器(RAM)和图形处理单元(GPU)以及明显的数据集数目作为样本训练的重要因素。
在图6中,GRU的性能比LSTM更好,这就是模型使用了GRU层的原因,GRU的平均误差为0.508,比LSTM的0.602更有效。

图6 模型(LSTM-GRU)的性能
3.4 误差最小化
使用100个epoch用于评估每个epoch的最小误差,这些epoch被分为两个部分,如图7所示,对于后50个epoch,误差在满意度水平上有所下降。
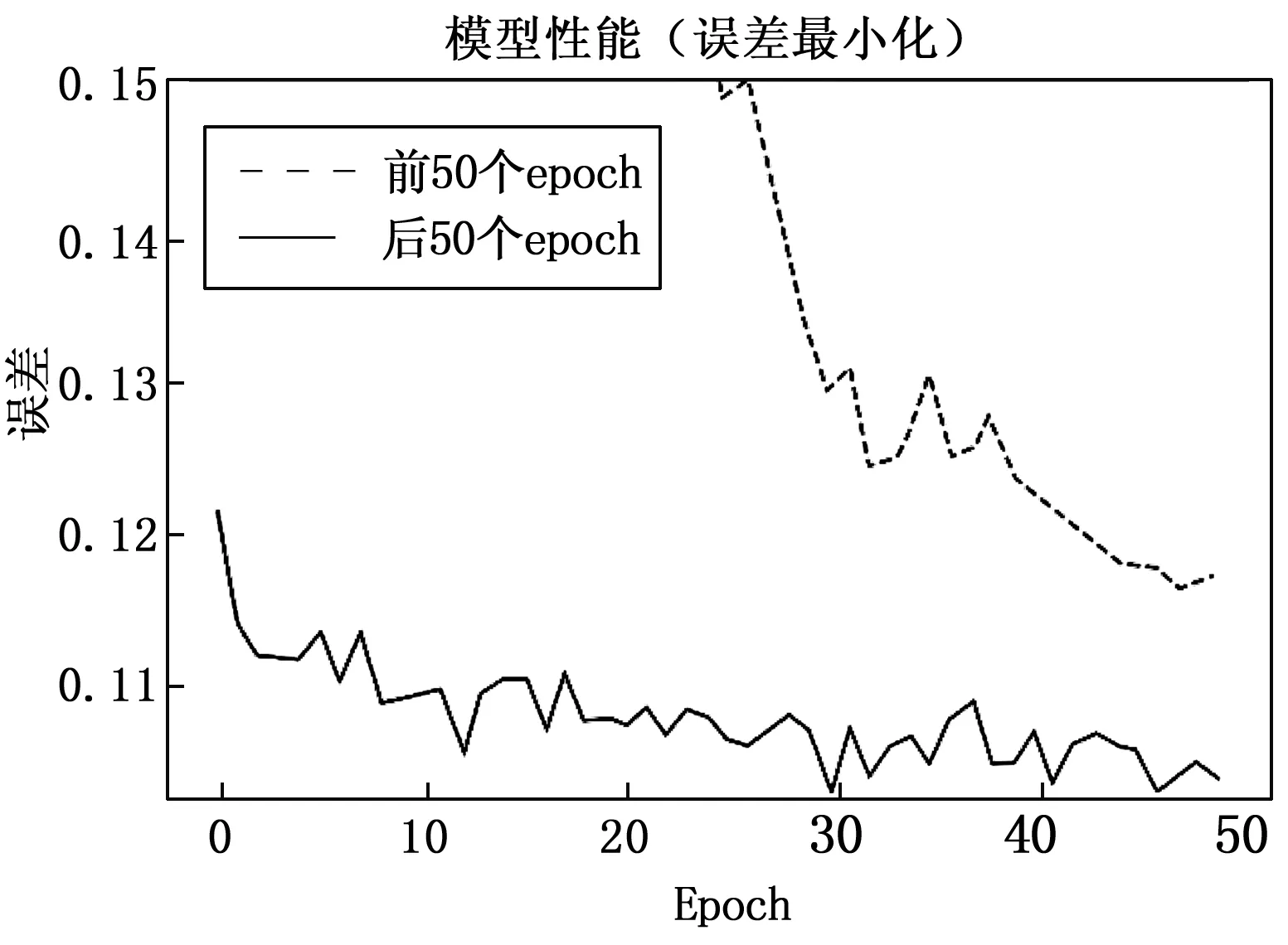
图7 性能提升
从表3可以看出,前50个epoch的标准偏差为0.680,平均误差为0.506。对于后50个epoch,平均误差降低到0.107,标准差为0.003,性能良好。

表3 性能评估
该系统模型可以在输入英语句子的基础上对一个平行的汉语句子进行评估,这个模型是使用深度学习方法以数据驱动的方式生成的,它通过多层神经网络学习预测每个给定单词的翻译单词,将单词转化为向量表示[18]。在标记化之后,RNN模型具有嵌入层,嵌入层是编码器和解码器的初始层。为了评估自动语音识别,对于GRU和LSTM层的性能进行了比较,结果表明,GRU的性能优于LSTM,所以下一层是GRU层。使用双曲正切激活函数和Softmax激活函数来评估注意机制,注意层的激活函数采用Sigmoid函数,以达到最佳的汉语翻译效果[19]。编码器和解码器的两个GRU层使用线性激活函数和双曲正切激活函数,由于它们的平均损耗最小。
在编码器和解码器中分别使用线性激活函数和双曲正切激活函数,在注意层使用Sigmoid函数,可以获得最佳的精度[20]。用这些配置进行了100个epoch,平均误差最小为0.107。与文献[14]相比,本文的基于递归神经网络的英译汉机器翻译方法误差较低。实验结果表明,该算法比传统的翻译算法具有更好的性能。此外,考虑到交际翻译,这种翻译方法提供了准确地获取给定句子的上下文意义的优势。
如前所述,在翻译后获取句子的实际意义是一项复杂的任务,它依赖于训练数据集、词汇和CPU处理能力,丰富的词汇可以带来更好的表现。除了这个限制之外,提出的模型可以应用于各种应用。许多现有的解决方案侧重于逐字翻译或直译,而没有考虑句子或短语中单词的用法,这种模型为从英译汉的翻译提供了一种新的可能性。此外,由于该模型克服了翻译的均衡性,因此可以用来建立系统,从而能够通过相应地考虑单词的实际意义来更准确地翻译语言。例如,模型可以作为一个对话系统,在不真正了解汉语的情况下,用这种语言表达情感和想法,这对很多人来说是一个有益的指导。此外,通过学习正确的翻译,会话系统将能够获得正确的句子含义。
4 结束语
机器翻译有很多好处,它节省时间,可翻译多种语言等。本文提出了一种英译汉机器翻译的设计方案并对其加以实现。与各种研究中的其他实现方法相比,本文提出的英译汉的递归神经网络方法提供了更好的结果,它将为机器学习算法中的自然语言处理做出更大的贡献,当处理大量词汇可以提高性能,增加epoch的数量可以提高准确率,但是处理这类问题需要更多的处理能力和内存,这些不足将在以后的工作中得到解决。
