基于深度学习的长尾数据集分类精度提高的研究
2021-11-29王中洲魏胜楠
王中洲,陈 亮,魏胜楠
(沈阳理工大学 自动化与电气工程学院,沈阳 110159)
在机器学习及其视觉识别的应用中,处理的数据集通常都有一个基本假设,即该数据集各类别对应的样本数量近似服从均匀分布,亦即类别平衡,但实际数据往往呈现极端不平衡状态[1]。在一个训练样本集中一些类别的样本数量较多,这种类别的样本称为头类样本;一些样本的数量较少,是头类样本的十分之一甚至更少,这种类别的样本称为尾类样本。头类样本与尾类样本的比值称为不平衡率,不平衡率大于10的数据集称为长尾数据集[2]。汽车轮胎缺陷的分类和定位研究中实验用轮胎数据集即为长尾数据集。
数据集类别不平衡导致模型学习非常容易被头类样本主导而产生过拟合;同时模型对于尾类样本的建模能力极其有限,从而在模型测试阶段表现出对尾类样本预测精度不高的问题。
经典统计机器学习处理长尾问题采用处理传统类别不平衡问题的方法。现有技术有两类做法:第一类为重采样法,即通过采样方式缓解长尾分布带来的样本极度不平衡[3];第二类为重权重法,通过改变权重来调整不同类别的训练比重[4]。
深度学习使用的方法如下。
(1)开放长尾识别算法(Open Long-tail Recognition,OLTR)基于一种度量标准将图像映射到一个特征空间[5]。其优点是在尊重封闭世界的同时承认开放世界的新颖性,但是训练过程复杂,操作繁琐。
(2)解耦算法认为对任何不平衡分类数据的重平衡本质上都是对分类器重平衡[6]。按照此理论提出了一种可以将特征学习和分类器学习解耦的训练策略,但该算法使用类平衡策略会出现学习头类样本特征不充分的问题。
(3)标签分布感知边缘算法(Label-Distribution-Aware Margin,LDAM)提出基于边缘泛化界限的损失函数[7],取代了训练网络中的损失函数,但是训练过程相比其他算法并没有优势。
两阶段法训练过程分为两个阶段:第一个阶段深度神经网络的训练数据服从原始长尾分布;第二阶段是缓解长尾分布带来的不平衡。2020年CVPR会议上Zhou B等基于两阶段法提出双边分支神经网络(Bilateral-Branch Network,BBN),用于解决在自然界中存在的长尾数据集中尾类样本数量少、分类精确度低的问题[8];该训练方法简单、操作步骤较少,可以兼顾特征学习和分类器学习。
本文使用BBN网络解决轮胎长尾数据集中缺陷样本分类精度低的问题。
1 BBN网络结构分析
BBN双分支循环神经网络结构如图1所示。
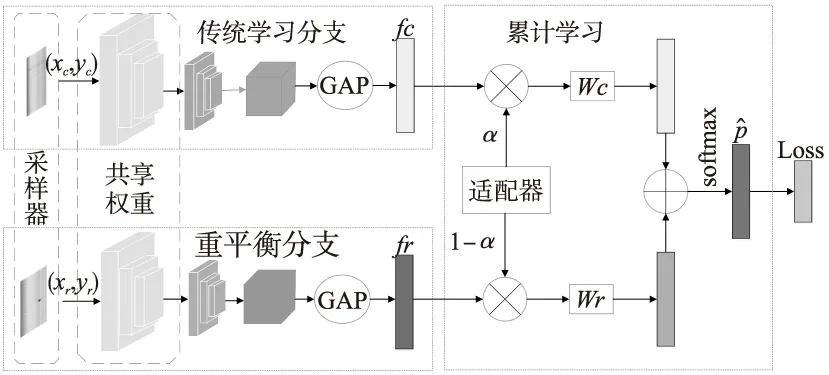
图1 BBN双分支循环神经网络结构图
BBN中包含的两个分支用于表示特征学习和分类器学习。两个分支使用相同的残差网络结构,共享除最后一个残差块以外的所有权值。其工作过程如下。
(1)设x表示训练样本集,y∈{1,2,…,H}是x内各元素对应的标签,其中H是类别数量。经采样得到的样本(xc,yc)和(xr,yr)作为两个分支网络输入数据,其中(xc,yc)为传统学习分支的输入数据,(xr,yr)为重平衡分支的输入数据。
(2)先将两个分支的输入数据经过残差网络特征提取,然后经过全局平均池化(Global Average Pooling,GAP)降低维度,减少训练参数,得到特征向量fc和fr。
(3)将(2)中得到的特征向量fc和fr经过特定的累积学习策略,改变网络对两个分支特征向量的注意力。通过累计学习策略中的自适应权衡参数α控制fc和fr的权值,将加权特征向量αfc和(1-α)fr分别传输到Wc和Wr分类器中,输出结果为
(1)
式中z为预测输出向量。
(4)将两分支输出的结果经过归一化指数函数Softmax处理,计算每一个类别的概率。Softmax函数计算公式为
(2)
式中:zi为第i个节点的输出;j为输出的网络节点类别。
(3)
1.1 特征提取网络
在数据集的特征提取网络中,卷积神经网络特征提取效果相比于其它网络更好。
采用ResNet-32与ResNet-50网络在不同不平衡率的CIFAR-10和CIFAR-100数据集上的对比实验错误率结果如表1所示。
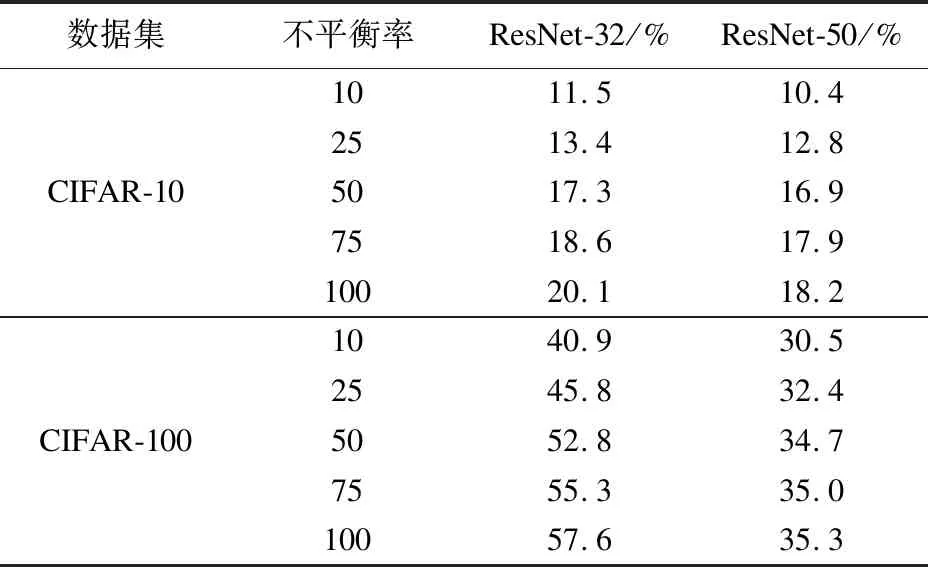
表1 不同骨干网络错误率对比
从表1可见,使用网络ResNet-50比使用ResNet-32的错误率更低,表明ResNet-50相比于ResNet-32提取效果更好,没有出现网络退化问题。
ResNet-50的网络结构如表2所示。
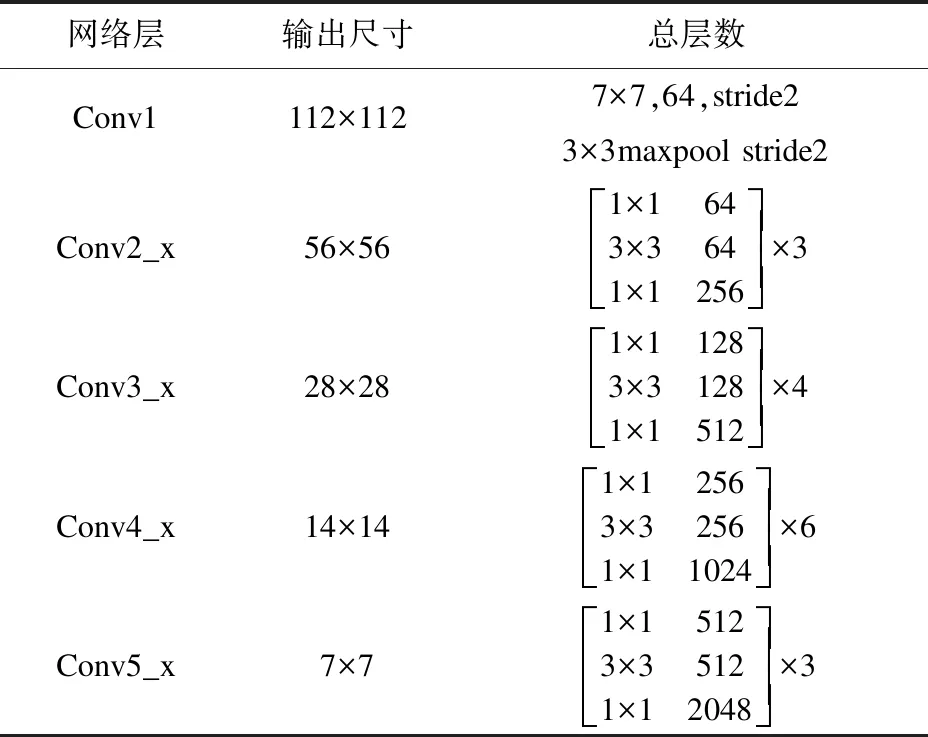
表2 ResNet-50网络结构
1.2 数据采样
传统学习分支的输入数据来自均匀采样器,其中训练数据集中的每个样本在一个训练时期中以相等概率只采样一次[9]。均匀采样器保留了原始分布的特征,有利于表征学习。而重平衡分支的目的是为了缓解数据不平衡。表3为实验得出的不同采样器模型的错误率。从表中可以看出,反向采样器取得了比均匀采样器和平衡采样器更低的错误率,表明重平衡分支可以通过使用反向采样器更多地关注尾类缺陷数据[12]。
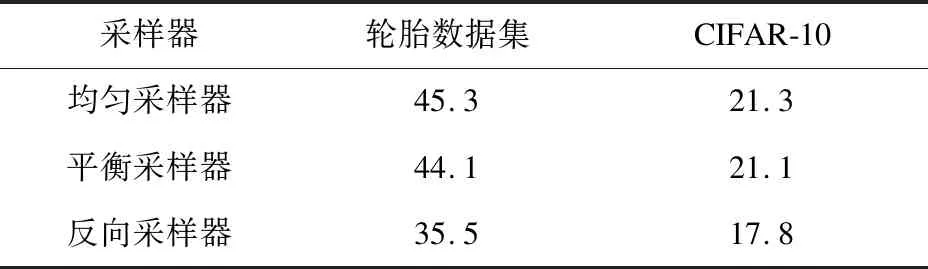
表3 不同采样器的错误率 %
1.3 累积学习策略
累积学习策略使用一个权衡参数α,可以将训练的注意力从一个分支转变到另一个分支。不同的α取值方式对于实验的影响如表4所示。
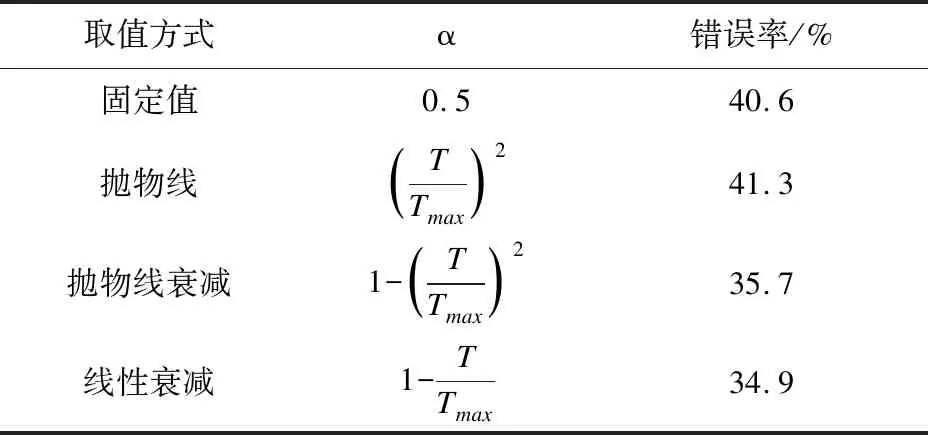
表4 不同α在轮胎数据集的对比实验
从表4的实验结果可以看出:以线性衰减和抛物线衰减为取值方式的α的错误率相比其它取值方式更低。说明首先训练传统学习分支,再训练重平衡分支的训练方法,可以避免破坏学习到的原始分布特征,又提升了分类准确率。
2 实验结果与分析
轮胎数据集样本量分布如图2所示。
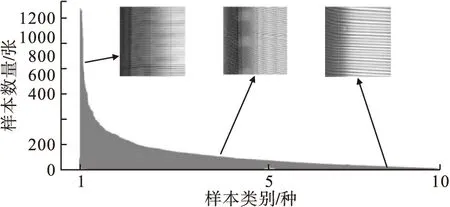
图2 轮胎长尾数据集样本量分布图
轮胎数据集中共10类缺陷,其中稀线缺陷样本为头类样本,气泡缺陷样本为尾类样本。
实验中除使用长尾版本的CIFAR数据集CIFAR-10和CIFAR-100外,还使用了实验室标注分类的轮胎数据集。此数据集包含60000张图片,50000张图片用于训练,10000张图片用于验证,缺陷类别数量为10,不平衡因子设置为10。
实验中制作数据集时,采用的数据增强策略是从原始图像中随机裁剪一个32×32的图片横向翻转,每边填充4个像素[10],目的是提升训练样本的数据量,改善网络模型的鲁棒性。
2.1 长尾数据集实验分析
本实验使用不同不平衡率的长尾CIFAR-10和长尾CIFAR-100训练数据,错误率为评价指标。不同损失函数的实验结果如表5所示。
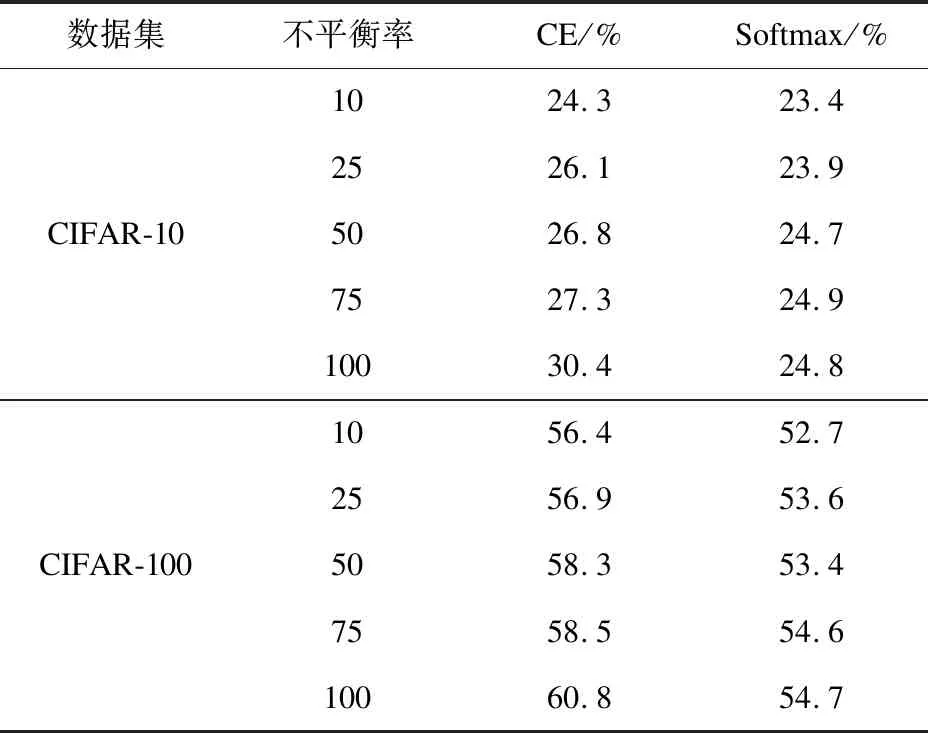
表5 不同损失函数在CIFAR-10和CIFAR-100上的错误率对比
从表5可以看出,使用Softmax函数比CE损失函数的错误率更低,而且随着不平衡率的上升,相较于CE损失函数,使用Softmax函数错误率变化更稳定,说明该方法可有效解决样本不平衡对分类精度的影响问题。
2.2 自制数据集实验分析
本实验使用轮胎数据集作为训练数据,损失值、平均精度均值(mAP)、错误率作为评价指标。实验过程中损失值的变化曲线如图3所示。
从图3可以看出,使用ResNet-50比使用ResNet-32收敛速度更快,收敛维度更低。证明对于轮胎缺陷图片ResNet-50比ResNet-32特征提取效果更好,没有出现网络退化问题。
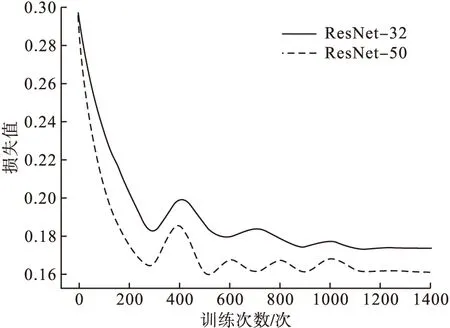
图3 不同骨干网络的对比图
为验证损失函数对实验结果的影响,使用Softmax函数和CE损失函数进行对比试验,实验结果如图4所示。
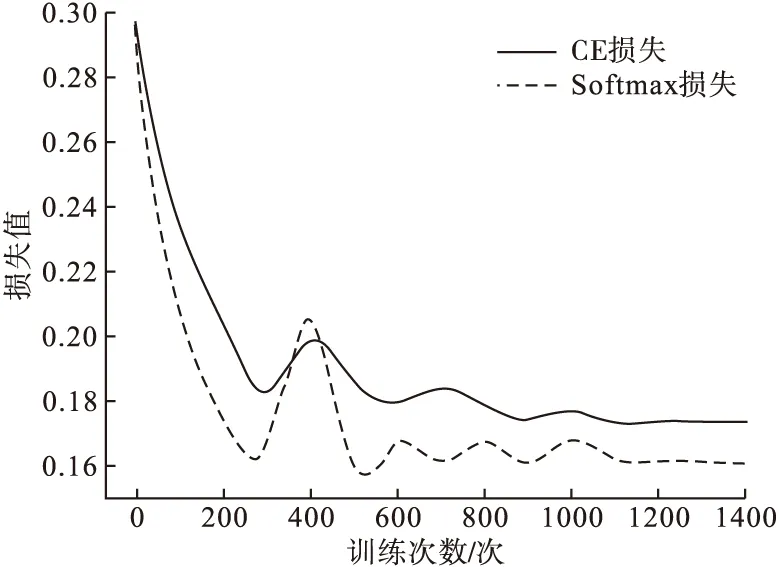
图4 不同损失函数的对比图
从图4可以看出,使用Softmax函数与CE损失函数相比,收敛维度降低,收敛速度更快。证明在BBN网络中使用 Softmax函数可以降低训练难度,提高分类准确性。
在轮胎数据集上训练改进后的网络模型(OURS)与网络模型OLTR、Decoupling、LDAM、BBN进行对比实验。实验结果如表6所示。
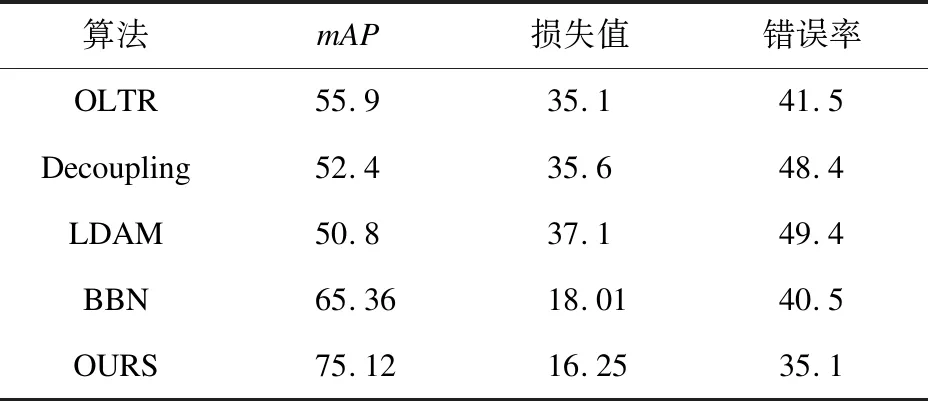
表6 不同网络模型实验结果 %
从表6可见,改进后的网络模型各评价指标均优于其他网络。说明改进后的网络在特征提取效果和分类器性能两方面均有提升。
在轮胎数据集上训练BBN网络模型和改进后网络得到的部分轮胎缺陷分类结果如图5所示。

图5 实验结果图
由图5可见,改进后的网络相比于原网络,杂质和气泡两类缺陷的分类准确率有很大提高。
3 结论
本文使用BBN双边分支神经网络训练轮胎数据集。通过对BBN神经网络中的骨干网络采用更适合提取轮胎缺陷图片的ResNet-50神经网络,损失函数采用适合轮胎数据集的Softmax 函数,权衡参数调整为线性衰减,令改进后的BBN神经网络更适合训练本实验室制作的轮胎数据集,使轮胎数据集中的尾类缺陷的分类效果更好,平均准确率更高。
