基于多语义复合表示模型的去离群点文本聚类
2021-11-28顾永春金世举顾兴全尹雪婷刘雅萱
顾永春,武 娇,金世举,顾兴全,尹雪婷,刘雅萱
(1.中国计量大学 理学院,浙江 杭州 310018;2.中国计量大学 标准化学院,浙江 杭州 310018)
随着互联网的发展,以文本为代表的非结构化数据增长迅速,但文本数据无法直接被计算机识别。因此,文本数据挖掘的首要问题是对文本进行结构化表示[1]。
文本(句子或文档)表示[2]是指以词向量为基础,对词向量进行组合得到可以表示文本的向量。向量空间模型[3](Vector space model,VSM)是常用的文本表示方法,可以看作是对One-Hot词语表示的加权平均,权重可以是词语的词频[4](Term frequency,TF)和词频逆文本频(Term frequency-inverse document frequency,TF-IDF)[5]等。VSM具有可解释性强、操作简单、耗时少等优点。但VSM表示的维度由文本语料控制,若文本语料较大,则文本向量稀疏且高维;此外,VSM表示无法完整融合词语的上下文位置信息,导致文本向量的语义信息缺失。
以Word2vec为代表的词嵌入(Word embedding)[6]可以将词语表示为紧凑低维的实值向量,并且能够捕捉词语的语义和句法属性。但对于文本聚类等文本级别的任务,需要将词嵌入扩展到整个文本。Le[7]等人提出的Doc2vec模型就是Word2vec从词语到文本层级的扩展。也有学者利用递归神经网络[8]、卷积神经网络[9-10]等神经网络模型训练文本向量。这些直接训练得到文本向量的方法[11]可以有效解决文本向量语义缺失的问题[12]。但也存在可解释性差,训练时间冗长等不足[13]。
词嵌入组合[14]是另一种常用的文本表示方法,这种表示方法通过对词嵌入加权平均形成文本向量。常见的加权方式有均值加权、平滑逆词频(Smooth inverse frequency,SIF)[15]加权和互信息(Mutual information,MI)[16]加权等。对词嵌入进行组合得到低维紧凑的文本向量不仅可以融合文本语义,还具有可解释性强、耗时少等优点。然而,相同词语在不同文本中可能会有不同语义。例如,“苹果”一词可以表示一种水果也可以表示苹果公司。但由词嵌入组合得到的文本向量无法体现这种语义上的差异。
Nikolentzos[17]等采用多元高斯分布对词嵌入和文本向量进行建模,并应用于文本分类。但是,单个高斯分布并不能解决一词多义的问题。为此,Mekala[18]等人提出了稀疏复合文本向量SCDV(Sparse composite document vectors)表示模型。SCDV首先利用软聚类方法将词语划分为多个词簇,形成语义空间,并得到词语属于不同语义空间的概率,作为词语不同语义的权重;然后将多个语义权重作用在词嵌入上得到多个语义向量,并将之连接成词语的多语义向量;接着将文本中所有多语义词向量的均值作为文本向量;最后,通过将较小的元素置零,对文本向量进行“稀疏化”。SCDV模型的优点是,文本中具有不同语义的同一个词语可以同时被划分到多个不同的语义空间,使得不同语义被包含于文本向量的不同部分,从而加强了文本向量的语义结构。然而,传统的SCDV模型仍存在着一些不足。例如,对任意的语义空间,软聚类方法为每个词语都会相应地赋予非零语义权重。但是,若词语对应于某个语义空间的语义权重较小,在构造文本语义向量时将会引入冗余信息和“噪声”。SCDV使用“稀疏化”方法通过设置阈值过滤冗余信息,但不恰当的阈值会将文本向量的所有元素都置为零,从而导致“过稀疏”并产生无意义的文本表示。针对上述问题,本文设计一种截断概率来优化词语的语义权重,并将其作为词嵌入的权重用于文本多语义向量构建,提出多语义复合文本向量(Multi-semantic composite document vectors,MSCDV)模型。
文本聚类是文本挖掘的常见任务,目标是将结构化表示后的文本数据集划分为若干个簇类,使得同一簇内的文本尽可能相似,不同簇类间的文本尽可能相异。K-means算法是应用最广泛的聚类算法之一,其具有原理简单、易于实现等优点[19]。但是,传统的K-means算法对离群点敏感,离群点的存在会导致聚类中心偏移,从而导致聚类性能下降。为此,本文利用MSCDV的结构特征识别离群点,在此基础上提出一种去除离群点的K-means(K-means based on removing outliers,KMRO)算法。本文提出的MSCDV模型与KMRO聚类算法具有以下优点。
1)利用截断概率优化词语的语义权重,过滤冗余语义空间,使得MSCDV的语义结构特征更加明显。
2)使用概率阈值仅过滤掉词语的小概率语义空间,大概率语义空间仍被保留,因此,MSCDV模型能有效避免文本向量的元素“过稀疏”的问题。
3)KMRO算法借助文本向量的结构特征,通过统计语义空间包含的文本数量来确定离群点,并采用去除离群点的优化方法能够显著地提高K-means算法的聚类性能。
1 多语义复合文本向量
本节主要介绍多语义复合文本向量的构建流程。假设语料库Ω中共有N个文本。首先对语料库中所有的文本进行分词和训练词嵌入等预处理,每个文本d∈Ω都可以被切分为多个不同的词语,每个词语w都有与之唯一对应的词嵌入vw,其维度为M。
1.1 语义空间构建
高斯混合模型(Gaussian mixture model,GMM)可以看作是多个高斯分布函数的线性组合,通常用于描述同一集合中包含多个不同数据分布的情况。
本文使用GMM来刻画语料库中词语的语义空间分布及其语义概率,每个高斯分布代表一个语义空间。假设语料库Ω包含K个的语义空间c1,c2,…,cK,将词语w∈Ω的概率分布定义为如下形式:
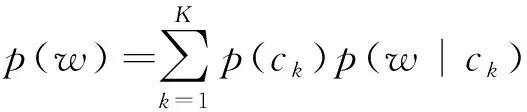
(1)
其中,p(w|ck)=N(μk,Σk)表示w的词嵌入vw在第k个语义空间中服从均值为μk,协方差矩阵为Σk的Gaussian分布;参数p(ck)=πk被称为GMM的混合系数,可看作是选择第k个语义空间的先验概率,满足
(2)
使用期望最大化(Expectation-maximum,EM)算法求解GMM,可得到词语w属于第k个语义空间的后验概率
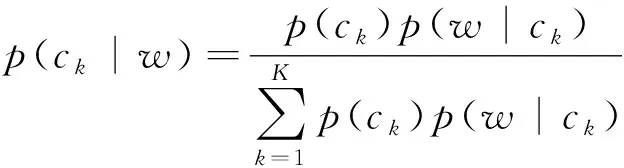
(3)
本文将p(ck|w)称为词语w对ck的语义概率,k=1,2,…,K。
由于p(ck|w),k∈{1,2,…,K}不全为零,表明词语w以不同的概率归属于不同的语义空间,从而对任意的ci和cj,i≠j,有ci∪cj≠∅。
如前所述,当词语w属于某个语义空间的语义概率较小时,会将冗余信息和“噪声”引入文本表示。为此,定义如下的截断语义概率
(4)
其中,ε为阈值参数。通过将过小的语义概率置零,可过滤词语在小概率语义空间中的分布,从而达到优化语义空间的目的。
1.2 文本的MSCDV表示
对语料Ω中的某个文本d,首先,以各语义空间中词语的截断语义概率为权重,通过对d中所有词语的词嵌入加权平均得到相应语义空间的语义向量。

(5)
其中,wi是d中的词语;|d|是文本d中词语的数量;vwi是d中第i个词语wi的词嵌入,P(ck|wi)是wi对ck更新后的截断语义概率。
然后,将K个语义向量x1,x2,…,xK连接形成文本d的MSCDV表示
(6)
其中,x是一个K×M维向量。
2 去离群点K-means算法
在得到多语义复合文本向量表示后。首先,借助文本向量的语义结构将文档划分到不同的文本空间sk,k=1,2,…,K,文本空间与语义空间的在数量上相等;然后,统计文本空间中的文档数目确定冗余文本空间和离群点;最后,提出去离群点聚类算法提高聚类性能。
2.1 离群点判定
首先,将所有文本向量按如下规则划分到K个文本空间中。对任意的文本向量x,如果其第k个语义向量xk满足
(7)
则称x属于文本空间sk,记作x∈sk。其中,xk,m表示xk的第m个元素。
由于文本向量由多个语义向量复合形成,同一文本可以同时被划分到不同文本空间,从而对任意的si和sj,i≠j,有si∪sj≠∅。
然后,判别sk是否为冗余文本空间。对第k个文本空间sk,若其中包含的文本向量数量sk≤δ·N,则称sk为冗余文本空间,sk中的文本向量即为离群点。将所有离群点构成的集合记为O,有
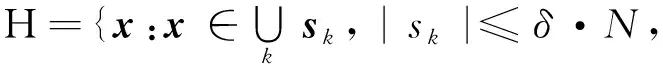
(8)
那么,由正常的文本向量构成的集合即为Hc,Hc=Ω-H。
2.2 去离群点聚类算法
将语料库Ω中N个文档对应的文本向量用矩阵X=(xd1,xd2,…,xdN)T表示,其中xdn是n个文本向量。设L为文本的聚类簇数,Z=(z1,z2,…,zL)T是由L个聚类中心组成的矩阵,zl∈Z是第l簇的聚类中心。对每个文本向量xdn,使用二值变量un,l∈{0,1}(l=1,…,L)表示其所属的类别,若xdn属于第l个簇类,有un,l=1,且∀k≠l,un,k=0。将这些二值变量用矩阵U=(un,l)N×L表示。那么,K-means聚类的目标函数具有如下形式:
(9)
考虑到文本向量中包含的离群点,本文分别使用二值变量un,l∈{0,1}和vm,l∈{0,1}(l=1,…,L)来标记正常点和离群点所属的类别,将(9)式改写为如下形式:
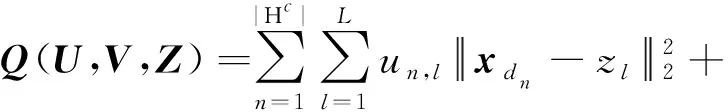
(10)
其中,U=(un,l)|Hc|×L,V=(vm,l)|H|×L。可以看到,目标函数被分为两个部分:第一部分(“+”前)反映正常文本向量的簇类划分对聚类性能的影响;第二部分(“+”后)反映离群点的簇类划分对聚类性能的影响。与K-means算法的思想一样,本文将通过对正常点和离群点的簇类划分与聚类中心的交替优化来最小化Q(U,V,Z)。但不同之处在于,更新聚类中心时,本文剔除了离群点,仅使用正常的文本向量,从而达到弱化离群点的影响、提高聚类性能的目的。
本文提出的KMRO算法使用迭代方法最小化(11)式,每次迭代对U,V,Z交替更新:
1)固定Z,更新U和V
第s次迭代中,估计U和V的子问题为
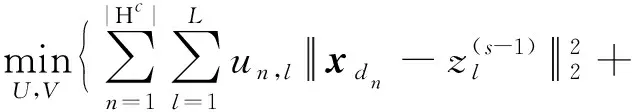
(11)
最优解可以通过将数据点划分到与其最近的聚类中所属的类别得到。对任意的xdn∈Hc,un,l的更新公式为

(12)
对任意xdn∈H,vm,l的更新公式为

(13)
2)固定U和V,更新Z
第s次迭代中,估计Z的子问题为
(14)
目标函数是zl的二次函数,令其关于zl的导数为零,可以容易得到zl的更新公式
(15)
从初始的聚类中心开始,KMRO算法按上述公式对正常点与离群点的簇类划分和聚类中心交替更新,直到簇类划分不再改变,或者迭代次数达到某个最值。KMRO算法流程如算法1所示。

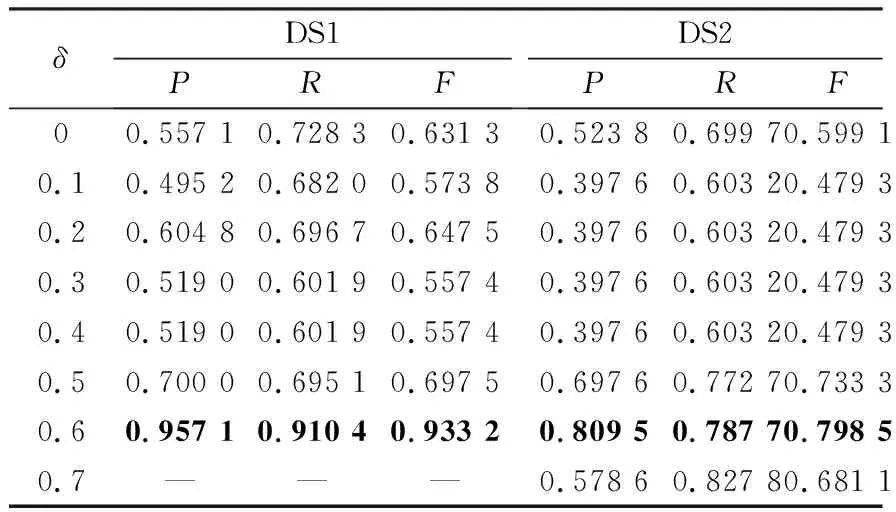
算法1.KMRO算法输入:X,smax,ε1,L输出:U,V1.利用(8)式将X划分为H和Hc2.从Hc随机选择L个点构成Z(0)3.根据Z(0)计算U(0)和V(0)4.令s=0,Δ=1005.Whiles (16) 在本节中,通过2个文本数据集的实验来验证基于MSCDV的KMRO聚类算法(PSCDV-KMRO)在文本聚类任务上的有效性和优越性。实验讨论了不同截断语义概率、语义空间数目和冗余文本空间数目参数对PSCDV-KMRO算法性能的影响,并与基于平均词嵌入表示(Meanvec-KM)模型、TF加权平均词嵌入表示(TFvec-KM)模型、TF-IDF加权平均词嵌入表示(TFIDFvec-KM)模型和SCDV文本表示(SCDV-KM)模型的K-means算法性能进行对比。实验中所有程序代码使用Spyder(Python3.7)编译,并在CPU为i5-4210M,内存8GB的计算机上运行。 实验数据集从20Newsgroups[21]中选取。其中,数据集DS1:从10个类别中选取200个文本;数据集DS2:从20个类别选取400个文本。 在MSCDV中使用的词嵌入由20Newsgroups所有语料生成,对语料的文本作词根提取等预处理后,利用Python3.7的gensim工具包训练基于Word2vec模型的词嵌入,除了词嵌入的维度M=150,其他参数均为默认值。设K-means和KMRO算法的聚类簇目等于文本类别数目;最大迭代次数smax=1 000;最小迭代误差ε1=10-5。MSCDV-KMRO的最优参数组合利用控制变量法依次确定,具体数值在3.1中详细叙述。SCDV模型的参数均为默认值。 实验以精确率(Precision,P)、召回率(Recall,R)和F值(F-measure,F)作为聚类性能的评价指标。 数据集进行聚类实验,利用控制变量法分别研究MSCDV-KMRO中截断语义概率阈值参数ε、语义空间数目K和冗余空间参数δ对聚类性能的影响。 实验1)和2)都设置δ=0,即所有数据点都为正常点的情况下做的聚类,也就是MSCDV-KMRO算法即为MSCDV-K-means。 1)ε对MSCDV-KMRO聚类性能的影响 设置K=2,ε为变量。图1分别展示了ε的变化对两个数据集聚类效果的影响。其中,图1(a)说明在给定的上述条件下,当ε=1-10-8时,对数据集DS1的聚类效果最好;图1(b)说明,相同条件下,当ε=1-10-2时,对数据集DS2的聚类效果最好。 2)K对MSCDV-KMRO聚类性能的影响 在DS1和DS2中分别令ε=1-10-8和ε=1-10-2,K为变量。表1分别显示了当K的取值为15到20之间的整数时,在两个数据集上聚类性能的变化情况。实验结果表明,在给定上述ε值和δ值的条件下,当K=17时,在本文提出的MSCDV模型下,K-means算法的性能最佳。 3)δ对MSCDV-KMRO聚类性能的影响 将ε和K设置为常量,在两个数据集上分别讨论参数δ对聚类性能的影响。在DS1上设置ε=1-10-8,K=17;在DS2上设置ε=1-10-2,K=17。δ从0到0.7变化,实验结果如表2所示。可以看到,当δ=0.6时,MSCDV-KMRO在两个数据集上都获得了最优的聚类性能。如前所述,δ=0对应于未考虑离群点的MSCDV-KM算法,这表明通过去除离群点确立能够有效地提高算法的聚类性能。 通过上述参数实验,得到MSCDV-KMRO算法对数据集DS1和DS2的最优参数设置,见表3。 图1 参数ε对聚类性能的影响Figure 1 Cluster performance comparison with different values of ε 表1 参数K对聚类性能的影响 表2 参数δ对聚类性能的影响 表3 MSCDV-KMRO算法参数设置 表4 聚类性能比较 表4给出MSCDV-KMRO与Meanvec-KM、TFvec-KM、TFIDFvec-KM、SCDV-KM和MSCDV-KM等5种算法聚类性能的比较。对于数据集DS1,MSCDV-KMRO和SCDV-KM算法的聚类性显著优于其他算法,说明多语义复合表示更适合文本聚类任务;相比于SCDV-KM,MSCDV-KMRO的三个聚类性能指标都有14%以上的提高,说明在多语义复合表示下,去除离群点的策略对聚类性能的进一步提升起到了重要作用。对于数据集DS2,由于SCDV模型的文本向量过于稀疏,从而无法有效地进行文本聚类,但MSCDV模型能够避免“过稀疏”问题。总的来说,与其他4种算法相比,MSCDV-KMRO算法在聚类性能上的提高能达到3.57%~44.88%。 本文针对文本聚类任务,通过复合词语的多种语义信息提出MSCDV文本向量表示模型,并基于文本向量的结构特征构建KMRO聚类算法。参数和对比实验的结果表明:1)文本的多语义复合表示更适合文本聚类任务;2)过滤冗余语义空间和去除离群点能够有效提升算法的聚类性能;3)在适当的参数设置下,KMRO算法显著优于传统K-means算法。 基于MSCDV模型的KMRO算法对文本聚类性能的提升表明,在文本表示中以适当的方法融入不同的语义信息能够使文本表示更加完善。因此,在文本表示模型构建中探究如何选择和提取有效语义信息,构造语义和结构特征并存的表示模型,并将其应用于其他文本任务需要做进一步的研究。2.3 算法收敛性分析

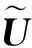
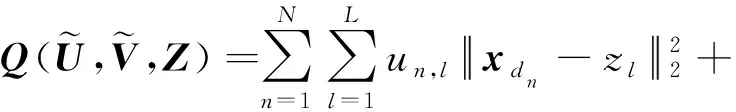
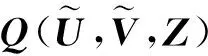
3 实 验
3.1 参数实验




3.2 对比实验
4 结 论
