基于深度残差网络的小样本杯沿缺陷检测
2021-11-28金宇霏陆慧娟郭鑫璐张俊朱文杰
金宇霏,陆慧娟,郭鑫璐,张俊,朱文杰
(1.中国计量大学 信息工程学院 浙江省电磁波信息技术与计量检测重点实验室,浙江 杭州 310018;2.浙江省农业科学院 食品科学研究所,浙江 杭州 310021)
食品软包装以其体积小、重量轻、方便食用,深受消费者的喜爱。目前,软包装食品市场逐年扩大,在其生产过程中,软包装内容物易粘在杯沿上,可能被压入封膜密封处,导致包装封口缺陷。这种产品如果在出厂前未被检测出来,在运输和储藏过程中易发生微生物污染的问题,造成较为严重的食品安全隐患。
目前的食品软包装加工厂大部分是采取人工检测剔除不合格包装,这一检测方式存在劳动强度大、标准不统一、误检和漏检率高等缺陷。李名等[1]设计了一种基于机器视觉的果冻质量检测技术与装置,提出使用区域生长算法对气泡进行检测,但机器视觉检测只可检测缺陷特征较简单的缺陷,并且不可更新。李苗[2]根据奶杯自身结构的特点,提出了一种奶杯表面质量检测系统设计与实现的方案,先采用区域分割的方法将奶杯内壁划分成不同的区域,再使用不同的污渍检测算法进行质量检测。何金彪等[3]提出了一种基于机器视觉的罐盖缺陷检测算法,可以检测罐盖是否合格,但是对于细微缺陷以及轻微划痕,该算法无法识别。
近年来,随着计算机视觉技术和深度学习的快速发展,在食品生产加工领域得到了广泛的应用。张博[4]针对小麦籽粒检测提出了一种基于深度学习的识别模型构建方法。俞芳芳等[5]采用深度学习的方法对食用油灌装进行质量检测,包括对瓶口、瓶盖的缺陷检测,相比传统方法,深度学习的检测精度更高、算法泛化能力更强。张芳慧等[6]提出了一种基于SSD的果冻杂质检测方法,该方法增强了算法鲁棒性,但准确率不高。相比传统机器视觉检测,深度学习模型具有不断更新缺陷类型、自动训练学习、不断提高预测准确率等优点。但基于神经网络模型的图像识别,依赖大量的数据样本,在数据样本不足的情况下,往往容易造成过拟合问题。
综上所述,为解决小样本带来的过拟合问题,本文采用数据增强的方法通过对数据进行擦除、旋转、镜像、剪裁等操作来扩充数据集,弥补数据样本不足。网络模型选择在大型图像数据集ImageNet上训练好的ResNet50模型,由于本实验是对软包装杯沿正负样本进行分类,所以需要微调网络结构,并且调整超参数,使模型更快收敛。
1 深度残差网络与迁移学习
1.1 深度残差网络
ResNet[7]是由华人学者何恺明在2015年提出的。近年来,深度神经网络层数成倍增加,当堆叠更深的网络结构时,性能却没有提升,反而容易造成梯度弥散和梯度爆炸现象。深度残差网络增加了一个短路连接,解决了上述问题,使得网络在堆叠过程中保留最优性能。

图1 残差网络的残差块Figure 1 Residual block of the residual network
残差网络是由残差块叠加而成,如图1所示[7],(a)、(b)表示两种不同结构的残差块,(a)主要用于18层、34层的残差网络,(b)主要用于50层、101层、152层的残差网络。对(b)进行参数量计算,64、256表示通道数,1×1、3×3表示卷积核大小,计算公式为输入通道×输出通道×卷积核大小,即产生参数256×64×1×1+64×64×3×3+64×256×1×1≈70 K。
残差学习定义为
y=F(x,{Wi})+x。
(1)
其中,x表示输入,y表示输出,F(x,{Wi})表示为待学习的残差映射,对于图1(b)的三层残差块结构,F的具体表达式可以为
F=W3σ(W2σ(W1x))。
(2)
σ表示为ReLU(Rectified Linear Units)[8]激活函数,W1、W2、W3表示权重。F+x操作是通过短路连接和输入参数相加得到的,要求维度相同,若维度存在差异,可修改公式(1)为
y=F(x,{Wi})+Wsx。
(3)
Ws表示一个矩阵,作用是维度转换。
根据上述公式可知,短路连接既不增加额外参数,也不增加计算复杂度,这让残差网络在普通网络中具有极大的优势。
1.2 迁移学习
迁移学习(Transfer Learning)[9]是把已经训练好的模型参数迁移到新的模型来帮助新模型训练。在本文中,将其他领域中的知识迁移到食品软包装检测应用场景中。文中使用ImageNet大型数据集学习到的网络特征运用于杯沿检测任务中,可降低所需的训练样本集和计算资源,并提高模型学习效率。例如黄健[10]等将迁移学习应用到表面缺陷检测中,获得了良好的识别效果。
实验所选择的网络模型为ResNet50,其网络结构如表1所示,conv1表示一个卷积层,conv2_x、conv3_x、conv4_x、conv5_x表示残差块,最后是一个全连接层。实验采用批处理操作,每一批包含64张图片,单张图片输入尺寸为224×224。
迁移学习有两种使用方法,一种是微调,另一种是Fixed Feature Extractor。微调是对别人已经训练好的网络进行修改应用到目标领域的任务中,通常使用预训练的网络权值作为自己网络的初始化权值。Fixed Feature Extractor即固定特征提取器,使用时将网络的前几层冻结,只训练网络最后的全连接层。实验选择微调的方式,对ResNet50模型进行修改,如图2所示,将ResNet50最后一层全连接层替换为一个1×1的卷积层和一个线性分类层,应用到本文的目标任务中。
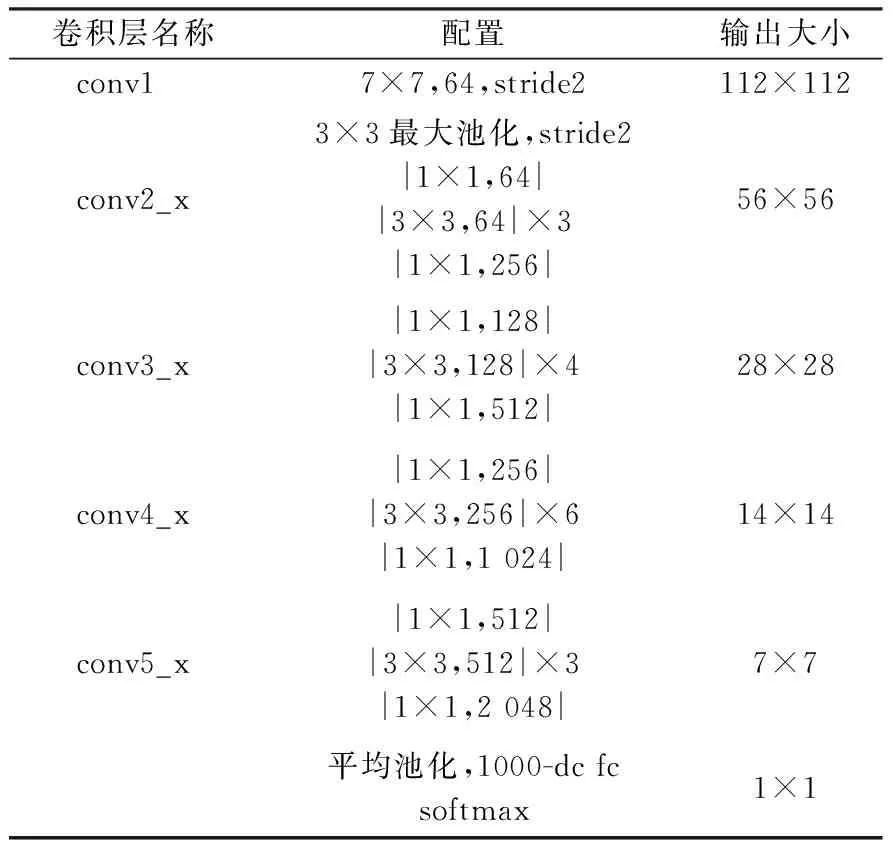
表1 ResNet50网络模型结构
卷积操作中采用1×1卷积核可以降低通道数,等价于全连接层,但参数更少。由于可降低通道数,卷积核参数与计算复杂度也相应降低。

图2 网络结构模型Figure 2 Network structure model
2 数据预处理
2.1 数据集
采用自制数据集,使用工业相机从食品软包装加工厂拍摄得到软包装杯沿图像,按杯沿有无缺陷分为两类,无缺陷杯沿图像300张,有缺陷杯沿图像205张,共计505张。将数据增强后的数据集60%划分为训练集、20%划分为验证集以及20%划分为测试集,各自为独立的集合。相比于神经网络训练所需的大量数据,本文所研究的是一个小样本数据集,因此采用数据增强技术来增强模型的泛化能力。
样本图像像素为1 280×1 024,每张带有缺陷的杯沿图像有一处或多处缺陷。本文的目的是对封口处有缺陷的食品软包装和合格的食品软包装进行精确分类。如图3,左图是合格的食品软包装,右图是带有缺陷的食品软包装,红框内是被压入封膜密封处的软包装内容物。

图3 无缺陷(左)、有缺陷(右)杯沿图像Figure 3 No defect(left), defect(right) cup edge image
2.2 数据增强
数据增强即扩充数据的总量,目的是增加训练数据的多样性,防止过拟合,当数据集较小时,过多的参数会拟合数据集的所有特点,而非数据之间的共性。

图4 原始图像(左)、预处理后图像(右)Figure 4 Original image(left), preprocessed image(right)
传统的数据增强方法有平移、旋转、镜像、裁剪、图像抖动和亮度变换等,图4所示分别为原始训练数据和经过传统数据增强之后的训练数据。
传统的数据增强方法在不改变原始数据特征信息的基础上,对数据集进行扩充。与上述方法不同的还有一些方法,是破坏原始数据图像得到带有缺损的训练数据,如随机擦除(Random Erasing,RE)[11]和Hide-and-Seek[12]等方法。随机擦除是在训练图像中随机选择一个或多个矩形区域,并用随机值代替图像原有的像素值,生成了不同层次遮挡的训练图像,降低了过拟合的风险,使模型学习到更细微的特征。Hide-and-Seek方法是一种弱监督学习方法,图像在训练过程中部分区域被掩盖,使得模型学习聚焦在较少分区的对象部分。由于杯沿封口处缺陷较小,若采用不当的擦除方法,会将缺陷掩盖,产生错误样本,导致分类精度降低。为此,本文设计了一种适合杯沿检测的随机擦除方法和非随机擦除方法。将训练图像分割成4×5小块,每块为256×256个像素点,只在图像的四个角和杯面中间黑色区域进行像素块擦除,不会影响需要检测的杯沿部分。非随机擦除方法将原始数据集扩充为原先的6倍,如图5。随机擦除方法只对负样本进行操作,弥补了数据样本分布不均匀的问题,随机选择0~3个随机块进行像素值替换,如图6。

图5 非随机擦除Figure 5 Non-random erasure

图6 随机擦除Figure 6 Random erasure
原始数据样本经过随机和非随机擦除方法以及旋转、平移等手段,扩充为4 127张图像,其中正样本2 100张,负样本2 027张。
为验证随机擦除方法和非随机擦除方法的有效性,对照样本仅使用旋转、平移等方法,数据集数量保持一致。
3 实验设计与结果分析
3.1 实验环境
实验是在Windows10专业版系统安装Anaconda 3,基于Facebook开源的PyTorch神经网络框架,使用Intel Core i7-10700 CPU以及GTX3060显卡加速,完成实验训练。
3.2 实验设置
对随机擦除和非随机擦除后的数据集进行划分,确保训练集、验证集和测试集相互独立。同时对训练集中的样本进行旋转、镜像、裁剪和亮度变换等数据增强操作,使样本数据多样化,避免训练过程中过拟合现象,对照样本采用相同的传统数据增强操作。原始图像尺寸为1 280×1 024像素,为适合模型训练,将图像调整为224×224像素大小。然后基于PyTorch框架给出ResNet50模型的实现。模型训练过程中,迭代步长设置过大,容易产生过拟合,设置过小,不利于模型学习,实验设置100个Epoch,实验参数设置如表2。

表2 实验参数设置
在实验一中,采用传统数据增强后的数据集和交叉熵损失函数对模型进行杯沿检测的训练,再采用提出的数据增强方法处理后的数据集以及交叉熵损失函数对模型进行杯沿检测的训练,以验证实验所使用的数据增强方法对小样本杯沿检测图像分类有效。
在实验二中,设计K最近邻算法作为深度学习算法的对比试验,以验证深度学习算法的优越性。
在实验三中,分别使用VGG16、DenseNet121、ResNet18、ResNet50、ResNet101模型进行实验对比。
3.3 实验结果分析
实验一,为了验证随机擦除和非随机擦除数据预处理方法对实验的有效性,分别对ResNet50模型进行训练。实验结果如表3所示。
由表3可知,在相同的网络结构下,使用所提到的数据预处理方法对实验分类效果有效。没有采取该方法的实验验证集最优准确率为0.98,准确率曲线图如图7,而测试集准确率为0.96,该样本处理方式较简单,容易导致模型学习训练数据中的噪声。采取本文方法的实验验证集最优准确率为0.96,准确率曲线图如图8,测试集准确率为0.97。测试集准确率相比传统预处理提高了1%。
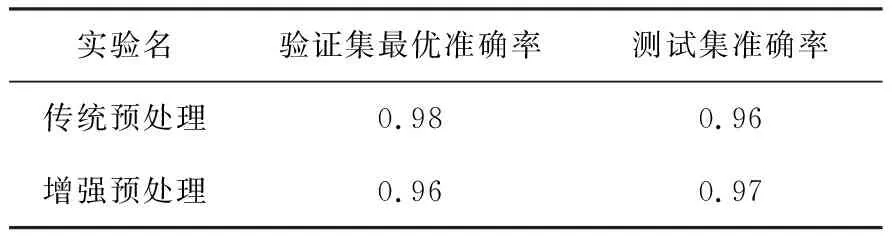
表3 实验结果
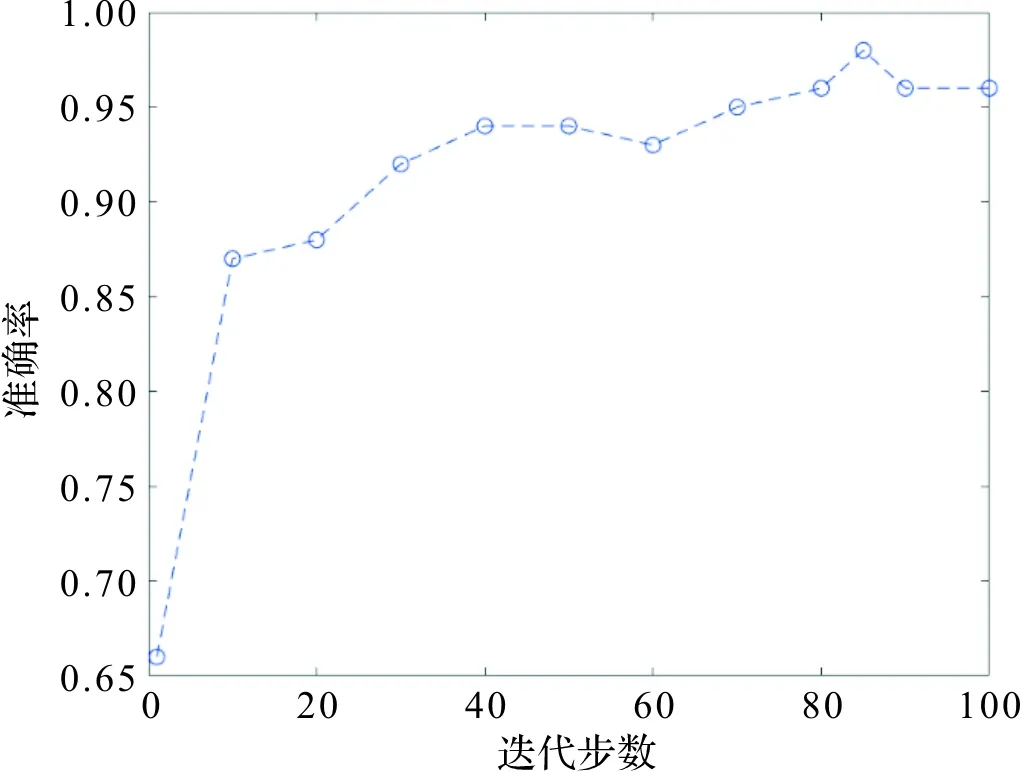
图7 传统预处理实验Figure 7 Traditional pretreatment experiment
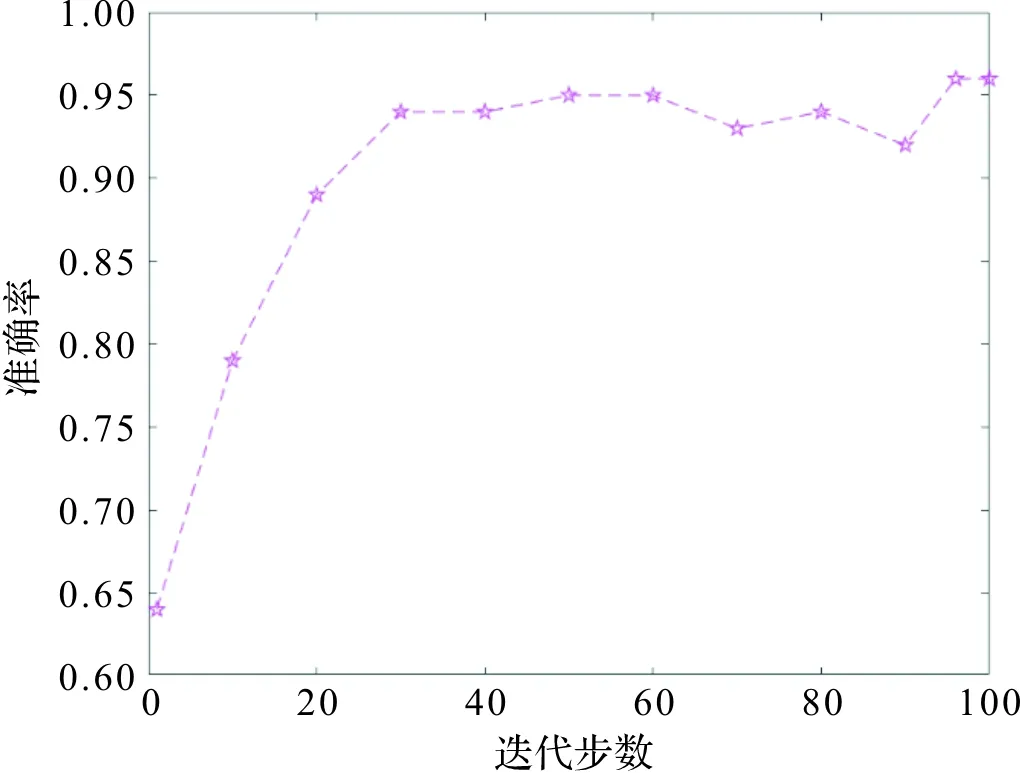
图8 增强预处理实验Figure 8 Enhanced pretreatment experiment
在实验二中,设计了机器学习算法对杯沿图像进行分类。使用K最近邻算法在同一个数据集上进行分类,60%的样本为训练集,20%为验证集,20%为测试集,输入图像大小同样为224×224。表4为实验结果。

表4 K最近邻算法
如表4,机器学习算法的分类精度远远低于本文采用的深度学习算法,分析其原因为,传统机器学习容易受到杯面残余水珠的干扰,极大地影响了识别的正确率。
传统机器视觉算法的表现如图9。(a)是待检测的图像,(b)是识别结果,红框表示杯面有缺陷的地方,杯面残留的小水珠容易影响视觉识别,如3号框错误的将水珠识别为缺陷。
在实验三中,分别对VGG16、DenseNet121、ResNet18、ResNet50、ResNet101模型进行训练,训练结果如表5所示。

表5 不同模型训练结果

图9 传统机器视觉检测Figure 9 Traditional machine vision inspection
由表5可知VGG16模型和DenseNet121模型的识别精度远远小于ResNet系列网络结构模型。ResNet18模型测试集准确率与ResNet50模型测试集准确率相同,但ResNet50模型层数更深,泛化能力更强;ResNet101模型准确率比ResNet50模型准确率低1%。通过上述实验可知,ResNet50模型在以上模型中为实验最佳模型。
4 结 论
针对传统机器视觉检测只可检测固定种类和缺陷特征较简单的缺陷,本文设计了一种基于深度学习的杯沿检测模型,自动训练学习,降低了人力消耗。预训练网络ResNet50在经过预处理图像训练后识别准确率可达到97.69%,证明在大数据集上训练好的预处理模型可以很好的迁移到小样本数据集上。今后,将进一步优化模型,收集更多数据样本,在提高识别准确率的基础上,对不同缺陷进行分类。
