基于BO-CatBoost的变压器故障诊断
2021-11-26周海阳赵振刚李英娜张家洪张大骋
周海阳 赵振刚 于 虹 李英娜 张家洪 张大骋
(1.昆明理工大学信息工程与自动化学院;2.云南电网有限责任公司电力科学研究院)
我国电力水平在日益提高,泛在电力物联网也在不断发展、完善,因此实现对电力变压器的准确可靠监控显得尤为重要[1]。 油色谱在线监测装置被广泛用于油浸式变压器,使用行业中认可的油中溶解气体分析 (Dissolved Gas Analysis,DGA)方法作为主要的监测手段,该方法已成为带电检测项目中应用最广泛、 最有效的一种方法。 基于DGA 数据诊断的核心思想是根据油中气体组分含量确定故障类型。
变压器在运行中由于受到电应力、热应力和机械应力的影响发生异常, 导致变压器油分解,产 生H2、CH4、C2H4、C2H6和C2H2这 些 典 型 气 体。传统的变压器诊断方法主要利用图表查询方式,常见的有IEC 三比值、Rogers 比值及Duval 三角等[2~5]。 由于存在编码方式有缺失,划分结果依赖阈值等情况,传统的诊断方法误诊率较高,已经逐步沦为辅助手段。 电力变压器结构复杂,故障类型较多。 支持向量机是针对二分类问题提出的,在多分类方面存在不足之处[6]。神经网络模型对小样本问题的分类效果并不是很理想,需要较多样本数据才能取得较好的效果,而变压器故障样本数量一般较少,此外神经网络存在收敛速度慢、容易陷入局部最优值等问题[7]。利用集成学习的方法主要有随机森林(Random Forest,RF)和梯度提升树(Gradient Boosting Decision Tree,GBDT)两大分支。 RF 是用决策树作为其基学习器,通过减小方差来提高预测精度,但处理噪声较大的分类问题时容易过拟合,文献[8]利用集成学习的思想建立RF 模型, 克服了单分类器的局限性, 并提高了分类器的分类预测能力。 而GBDT则通过降低偏差来减小总误差,但由于每一个体学习器之间依赖关系较强,无法并行训练,因此训练速度较慢。 文献[9]提出采用极限梯度提升(XGBoost)算法来拟合模型,在变压器故障诊断上取得了较好的效果。 CatBoost 算法类似于常规的梯度提升算法,但是利用一种全新的梯度提升机制来构建模型以减少过拟合,这使模型具有通用性和更强的鲁棒性,采用默认参数就可以获得较好的结果,减少了对众多超参数调优的需求和调参时间。CatBoost 被用于许多疾病的判别预测,具有很高的可靠性[10~12]。
基于以上研究, 笔者提出了一种基于CatBoost 的油浸式变压器故障诊断方法, 该方法对故障中产生的不同特征气体之间的关系进行挖掘,利用不同故障情况下各特征气体之间存在的典型比值、 占比关系构建了一系列新特征;利用Z-score 标准化方法处理所有特征数据; 将处理后的数据分为训练集和测试集,将训练集数据输入CatBoost 模型,并采用贝叶斯优化(Bayesian Optimization,BO)对模型超参数进行优化,最终建立基于CatBoost 的变压器故障诊断模型,实现对变压器的故障诊断。
1 BO-CatBoost 算法
1.1 BO 原理
BO 是一种被广泛用于超参数寻优(Hyper-Parameter Optimization,HPO)问题的迭代算法[13]。 与传统的随机搜索和网格搜索(Grid Search,GS)不同,BO 是依据历史获得的结果来不断更新概率模型,从而有利于找到最优的超参数。 为了确定下一个超参数配置,BO 使用了代理模型和采集函数两个关键部分[14]。 代理模型的目标是将所有当前观测的点都拟合到目标函数中。 在得到概率代理模型的预测分布后,利用采集函数平衡探索与开发的关系。 探索就是在还未取样的区域获取采样点,而开发就是根据后验分布在有希望出现全局最优解的区域进行采样。 BO 模型平衡了探索和开发过程, 以寻找当前最可能的最优区域,避免在未探索地区错过更好的配置[15],陷入局部最优。 图1 为贝叶斯优化流程。

图1 贝叶斯优化流程
TPE(Tree-structured Parzen Estimator)算法是BO 的一种常用代理模型。 TPE 算法先随机采样一些超参数,然后将采样得到的超参数用于目标函数的评估,从而得到学习样本(x,y),其中x表示设置的超参数,y表示将所设参数代入目标函数所得到的最优值。 在随机采样得到的样本满足一定数量时,TPE 算法利用已有样本得到非参数概率密度函数。 根据非参数概率密度函数,再在超参数空间内采集新的样本。 重复整个过程直到发现能产生较优目标函数值的超参数设置。
1.2 集成策略
与传统学习方法不同,集成学习方法通过训练多个学习器来解决问题。 通常集成后的模型比基学习器有更强的泛化能力,效果更好。 在集成学习中, 集成方式主要有Bagging 和Boosting。Bagging 是一种并行集成方法, 利用基学习器之间的独立性,结合相互独立的基分类器来显著减小误差。其实现过程为:给定一个样本数为m的训练集合, 通过有放回采样得到有m个训练样本的采样集。 原始样本有的被选中多次,有的未被选中。 重复过程T次,得到T个样本数为m的样本集。对每个采样出来的训练集,使用基学习算法可以得到一个基学习器。 Boosting 是一种串行集成方法,实现过程为:每个训练样本算法会分配一个权值,在每一轮的训练中,新分类器标注出每一个样本,分类正确的则降低其权值,在下一次抽样中减小它被抽中的概率;分类错误的则提高其权值,增加下一次抽样被抽中的概率。 样本权值越高,在下一次训练中所占的比重就越大,也就是说越难区分的样本在训练过程中会变得越来越重要。 整个迭代过程直到错误率足够小或达到一定次数才停止。Boosting 算法流程如图2 所示。

图2 Boosting 算法流程
1.3 CatBoost 原理
CatBoost 是一种以对称决策树为基学习器,参数较少、 支持类别型变量和高准确性的GBDT框架,能够高效合理地处理类别型特征,解决以往GBDT 框架的机器学习算法中常出现的梯度偏差和预测偏移问题, 从而减少了过拟合的发生,提高了算法的泛化能力。
CatBoost 与其他梯度提升算法类似, 它每构建一棵新树, 都会近似当前模型的梯度。 但在GBDT 的每一步迭代中, 损失函数使用相同的数据集求得当前模型的梯度,然后训练得到基学习器,但这会导致梯度估计偏差,进而导致模型产生过拟合问题。 CatBoost 通过采用排序提升(Ordered Boosting)的方式替代传统算法中的梯度估计方法,进而减小梯度估计的偏差,提高模型的泛化能力。
2 基于BO-CatBoost 的变压器诊断模型
2.1 特征构建和数据预处理
利用从DGA 数据中获得的信息可以识别变压器的故障类型。 由于变压器内部发生故障的情况不同,会产生对应的H2、CH4、C2H4、C2H6和C2H2这5 种故障气体,不同的诊断方法就是利用这些气体之间的比例和占比关系来判定变压器故障类型的。
因此笔者参考传统的三比值法和无编码比值法[16],在原有的5 种故障气体特征的基础上又构建了11 种故障特征,现将变压器的所有16 种故障特征列于表1。

表1 变压器故障诊断所用特征

图3 各特征量Pearson 相关系数图
由于不同特征之间存在量级差异,为了避免计算误差,将各特征进行标准化处理:

其中,x*为标准化后得到的特征量,x为原始数据,x为原始数据的均值,σ为原始数据的标准差。
根据IEC 60599 中对故障类型划分的标准,加上正常运行情况,将变压器运行状态分为以下7 种:
0 低能放电(D1)
1 高能放电(D2)
2 局部放电(PD)
3 低温过热(T1)
4 中温过热(T2)
5 高温过热(T3)
6 正常状态(ZC)
从电力数据分析中心后台和文献中取得已确认状态的DGA 数据1 034 条,随机抽取样本的30%作为测试集,故障样本分布见表2。

表2 故障样本分布 条
2.2 贝叶斯优化CatBoost 过程
贝叶斯优化CatBoost 的具体步骤如下:
a. 对收集到的样本数据进行标准化处理;
b. 选取数据的5 个原始特征和新构建的特征作为模型的特征输入, 将样本数据按7∶3 比例随机分为训练集和测试集;
c. 设置CatBoost 模型的初始参数并进行预训练,利用BO 不断对模型参数进行调整;
d. 判断是否达到迭代次数,若是则停止,存储当前得到的训练参数值作为最优参数,否则返回步骤c;
e. 将存储的最优参数装载进CatBoost 模型,利用测试集对模型的诊断效果进行测试,输出故障分类结果。
2.3 CatBoost 模型参数选取
虽然CatBoost 在默认参数下表现已很好,但它还包含一些可以调优的参数。 参数iterations表示弱学习器最多需要迭代的次数,弱学习器迭代次数太少,就很有可能出现欠拟合的现象;相反,如果弱学习器迭代次数过多, 会出现过拟合的现象。 参数learning_rate代表学习率,学习率的数值越小,所需迭代的次数就越多。 参数max_depth代表树的深度。参数l2_leaf_reg代表L2正则化数。参数loss_function是损失函数,多分类时运用MultiClass。 表3 描述了主要参数、寻优范围和最优参数。
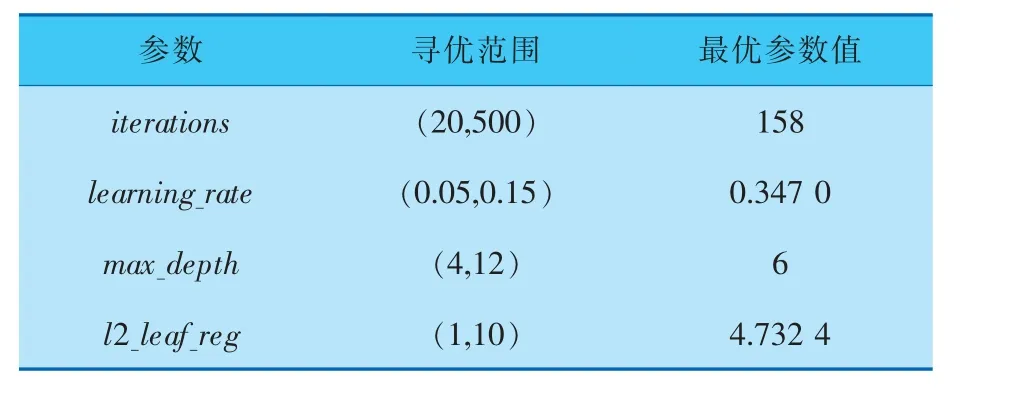
表3 CatBoost 主要参数
3 仿真结果
3.1 CatBoost 诊断结果
根据划分的训练数据和测试数据,建立基于贝叶斯优化CatBoost 的变压器故障诊断模型。 每个测试集样本的诊断结果如图4 所示,各类别诊断准确率见表4。
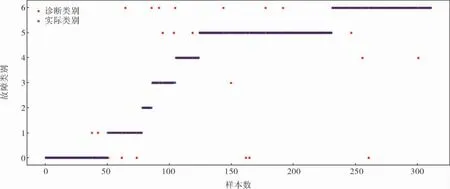
图4 BO-CatBoost 故障诊断分类结果

表4 BO-CatBoost 的诊断结果
从结果可以看出,诊断准确率最高的故障类型为D1、T2、T3 和ZC,D2、PD 和T1 类样本的准确率相对来说偏低,主要是因为这3 类故障的样本数过少。 BO-CatBoost 将2 条D1 类故障误诊为D2 类故障;将4 条D2 类故障诊断为D1 类和ZC类;PD 类中有1 条诊断为ZC 类;在T1、T2、T3 类故障中,分别有4 条、1 条、6 条故障被识别错误;正常样本中有4 条被识别为故障样本。
3.2 不同模型诊断结果对比
利用相同的数据集, 分别建立RF 和支持向量机(SVM)诊断模型,然后对两个对比模型进行贝叶斯寻优,寻优得到的最优参数见表5。图5 所示为几种模型混淆矩阵对比,从中可以看出,BOSVM 模型将10 条ZC 故障诊断为T1 和T2 故障,而将6 条T3 故障诊断为T1 故障,在所有模型中对过热类故障的诊断效果最差。 而BO-CatBoost诊断正确数是所有模型中最多的,在T1、T2 和正常类故障中诊断效果比其他模型好。

表5 SVM 和RF 主要参数
从表6 中可以看出, 经过寻优后,SVM 准确率从寻优前的82.64%提高到86.17%,RF 准确率从90.42%提高到92.60%, 且模型的精确率(Precision)、召回率(Recall)、F1 分数(F1-score)与寻优前相比均有提升。 对于CatBoost 模型来说,寻优前的准确率为90.68%,利用网格搜索得到的准确率为91.64%, 与之相比经过贝叶斯寻优后,准确率提升到92.93%。由对比可以看出,BO 对各种算法模型均有优化作用,虽然CatBoost 算法在默认参数设置下性能较好, 但在经过BO 调参后性能仍有提升, 说明BO 在集成算法上具有优秀的寻优能力。
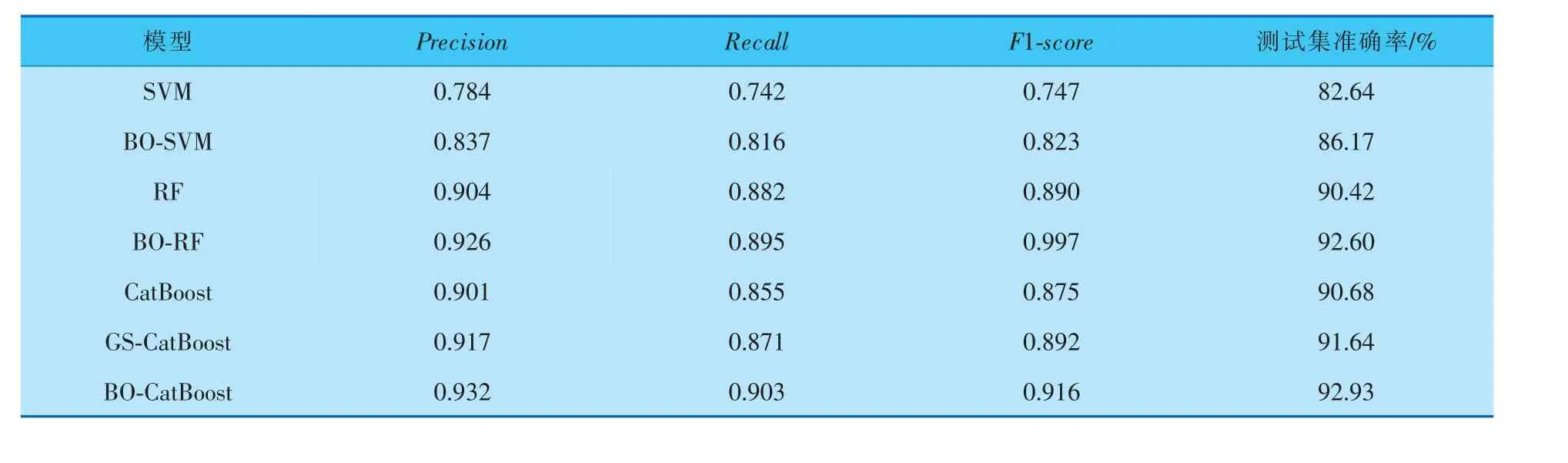
表6 不同模型诊断结果对比
4 结论
4.1 DGA 数据的比值和占比关系蕴含不同故障情况下气体之间的联系。
4.2 在采用同样特征输入时,CatBoost 比SVM、RF 具有更高的精度和稳定性。
4.3 将BO 引入CatBoost 诊断模型, 对模型的4个超参数进行优化,经优化的CatBoost 模型诊断准确度为92.93%, 优于未经优化的CatBoost 和GS-CatBoost,同时也优于优化后的SVM 和RF,有效地提升了模型诊断准确度。
