基于节点聚类的数据起源安全方法研究
2021-11-24孙连山马胜天陈秀婷
孙连山,马胜天,王 荔,陈秀婷
(陕西科技大学电子信息与人工智能学院,陕西西安 710021)
信息时代蓬勃发展,数据在互联网上传播和共享的过程中,携带了各种各样的信息,其中不乏用户的个人敏感信息。数据在公开共享之前,敏感信息的隐私保护成为多行业的重点关注问题[1]。数据起源(Data Provenance)领域的隐私保护问题也是学者们一直以来的研究重点和难点[2]。
数据起源描述了参与生产、影响或交付一条数据或一件事物的实体、活动、人或机构。通常呈现为有向无环图,简称起源图[3-4]。 特别来说,数据的来源对于决定信息是否可信,如何与其他的信息源集成以及在重用信息时是否能信任信息至关重要。
起源图中通常包含很多隐私数据,如职业、收入、银行卡号等,所以在公开发布数据起源之前需要对数据信息中的敏感数据进行遮蔽或改造。起源过滤是通过改造起源图,达到隐藏敏感信息的一种新型技术。Dey等[5]提出一种可以定制发布的PROPUB起源过滤框架,允许用户分别指定起源图中需要保留、隐藏、匿名或抽象的部分。王艺星等[6]提出“删除+过滤”的高效用的过滤机制,删除敏感节点或边,在保证溯源结果不增加的情况下,引入不确定依赖关系。Missier等[7]提出一种基于抽象的起源图过滤方法,将起源图中的敏感节点与其周围的一些节点组合在一起,用一个抽象的节点代替。
总的来说,现有针对敏感信息的过滤方法都会改变起源图的结构,但起源图的结构蕴含着数据之间的依赖关系,破坏起源图的结构会对起源图的溯源效用产生影响;另外,现有的过滤方法仅仅关注当前起源图的改造,没有考虑已经公开发布的起源图与当前起源图之间的关联,攻击者可能结合已公开起源图,对当前起源图的敏感信息进行推理,从而导致敏感信息泄露。
因此,本文结合研究现状和数据起源的特点,提出一种基于节点聚类的数据起源安全保护方法,在不改变起源图结构的基础上,构建起源图节点的层次聚类树,设计过滤视图的威胁和安全评估模型,依据用户对敏感节点的要求,对起源图节点进行泛化,泛化不同的节点数能够满足用户不同的起源发布偏好。实验结果表明,该方法能够在对敏感信息进行隐私保护的同时,保证过滤视图的溯源效用。
1 相关知识介绍
1.1 数据起源
本节结合实例介绍数据起源等相关概念,并介绍节点聚类策略和泛化的定义。
数据起源记录数据生产、转换过程的中间数据和相关人员、组织信息。根据W3C于2013年发布的数据起源模型(PROV⁃DM)及其相关模型的标准[8],数据起源通常呈现为如图1所示的有向无环图。起源图中的节点主要有实体节点,如节点e3,e4;活动节点,如 p2,p3;代理节点,如 L1。 起源图中的依赖关系有 7种,即生成(generation)、使用(usage)、派生(derivation)、通信(communication)、归属(attribution)、关联(association)和委托(delegation)[9-10]。 不同类型的边代表不同节点之间的依赖关系,例如使用边是由实体节点指向活动节点,记作used;产生边为活动节点指向实体节点,记作wgb;代理节点与活动节点之间相连的边为关联边,记作waw。
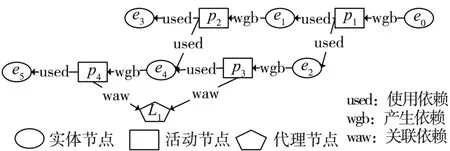
图1 某药品配方起源图
为便于论述,形式地定义起源图如下。
定义1(起源图 PG=(V,E,Ph))节点 V={v1,v2,…,vn}表示起源图 PG 中的 n个节点的集合;边 E = {ei|ei= <u,v>, u∈V,v∈V, i =1, 2,…,m}表示图PG有m条有向边。路径集Ph={Phi= (u, v), u∈V,v∈V, i= 1,2,…,r}表示图PG中有r条路径。
定义2(过滤视图PV=f(PG,SI)) PG表示原始起源图,SI为敏感信息集合,f表示所采用的过滤策略,过滤视图PV为原始起源图PG针对敏感信息SI采用过滤策略f进行过滤所得到的起源图。
定义3(直接前因节点集preN(PG,v))在起源图PG中存在由节点v指向节点u的边,且节点u和节点v之间的路径长度为1,称节点u是节点v的直接前因节点,preN(PG,v)表示节点v的直接前因节点集。如图1所示,节点e3和节点e4是节点p2的直接前因节点,则 preN(PG, p2)= {e3, e4}。 节点e3,e4与节点p2之间的连通边类型为使用边,则也可记作 preNused(PG, p2)= {e3, e4}。
定义4(直接后果节点集 subN(PG,v))在起源图PG中存在由节点u指向节点v的边,且节点u和节点v之间的路径长度为1,称节点u是节点v的直接后果节点,subN(PG,v)表示节点v的直接后果节点集合。如图1所示,节点p2和节点p3是节点e4的直接后果节点,则 subN(PG, e4)= {p2, p3}。 节点p2和节点p3与节点e4之间的连通边类型为使用边,则也可记作 subNused(PG, e4)= {p2, p3}。
定义5(节点向量Vec)起源图中的节点数据以文档形式存储,为便于计算节点之间的距离,需将节点用向量表示,本文采用word2vec算法将节点转化为向量,对于任意节点vi∈V,其向量化表示为Vec。
1.2 层次聚类
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算两类数据点间的相似性,对所有数据点中最为相似的两个数据点进行组合,并反复迭代这一过程[11-12]。
定义6(簇间距离)设有两个簇Ci和Cj,类簇之间的相似度用簇间距离评估,本文采用式(1)平均距离计算簇间距离。

其中, Xi,Xj为类簇中任取的样本,|Ci|为类簇 Ci中的样本数量,|Cj|为类簇Cj中的样本数量。
定义7(节点相似度)起源图PG中同类型的任意两个节点之间的相似程度。本文采用式(2)余弦距离计算样本节点间的距离。
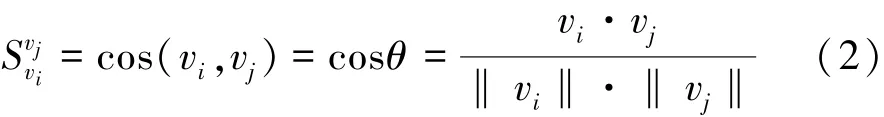
其中,vi和vj为起源图PG中任意两个节点。
定义8(层次聚类树)将所有样本层次聚类的结果以树状图的形式展示。图2是年龄的聚类层次树,原始样本点位于树的底层,也就是叶子结点;树的顶层是一个聚类的根节点,包含所有原始样本的信息。
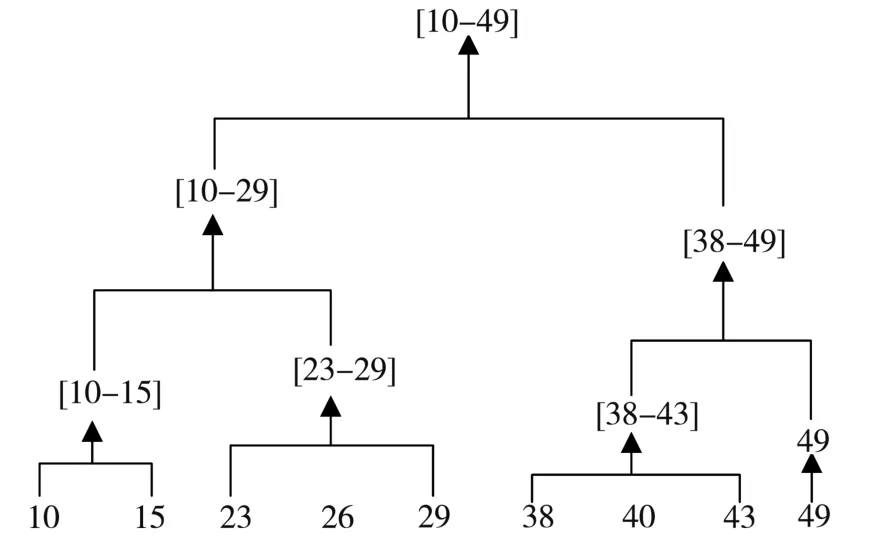
图2 年龄层次聚类树
1.3 节点泛化
在数据处理过程中,用模糊的、范围的取值取代精确取值的过程被称为数据泛化[13]。结合数据泛化的定义,节点泛化也就是将与敏感节点的取值相近的多个节点的值进行泛化概括,取代敏感节点的精确值,达到隐藏敏感信息的目的。
定义 9(泛化结果簇 RPG(vi))节点 vi根据层次聚类树,选择一个合适的类簇进行泛化,该簇就是节点vi的泛化簇集。如图3所示,若要对年龄“23”进行泛化,其泛化簇集可能为{“23”,“26”,“29”}、{“10”,“15”,“23”,“26”,“29”}或{“10”,“15”,“23”,“26”,“29”,“38”,“40”,“43”,“49”},对应泛化后的年龄取值为“23-29”,“10-29”或“10-49”。
2 数据起源安全威胁与评估
数据起源隐私保护的安全性与其所面临的威胁密切相关。本节阐述数据起源所面对的安全威胁和攻击者可以采用的推理方式,通过计算敏感节点的安全性对过滤视图进行安全评估。
2.1 安全威胁
定义10(已公开起源图集PubPG)将PubPG={PG1,PG2,…,PGl},其中 PG1,PG2,…,PGl是已经公开发布的起源图。起源图PGi(1≤i≤l)为采用不同的过滤技术进行敏感信息过滤的起源图。
不同阶段或不同偏好下发布的起源图存在密切的关联,已经公开的起源图数据可能对当前需要公开的起源图数据存在安全威胁。例如,图3是需要公开发布的原起源图的部分子图,其中,敏感信息是节点e1,泛化节点e1为节点e,得到其过滤视图PV如图4所示。而图5是已经公开发布过的一张起源图的子图,显然,节点e1是操作p2使用实体e3所产生的,攻击者可由此推理出在图4过滤视图中的节点e有二分之一的可能性是节点e1,进而导致敏感节点e1泄露。
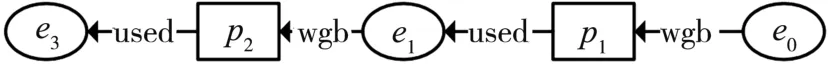
图3 原起源图子图PG
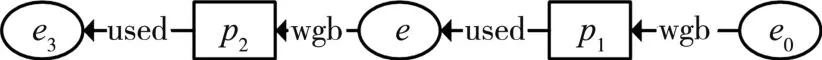
图4 起源图子图PG的过滤视图PV
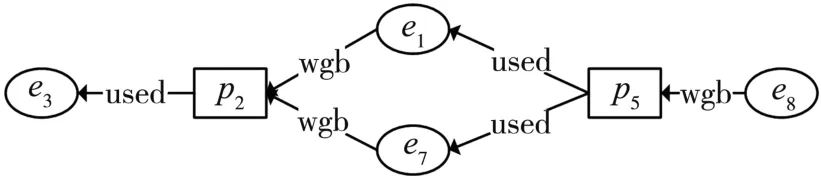
图5 已公开起源图子图PGi
2.2 推理方式
攻击者获得过滤视图后,首先需要确定待推理节点,也就是敏感节点。不同的过滤技术所得到的过滤视图具有不同的特点,如匿名[14]或者抽象[15]方法所得到的过滤视图中会出现空节点[16];本文所提出的泛化方法所得到的过滤视图中会出现某些节点数值模糊的情况。攻击者可以根据过滤视图中的节点特征确定待推理节点。另外,已公开起源图集PubPG与当前公开发布的过滤视图PV之间可能有多种多样的关联,攻击者可以通过这些关联对当前过滤视图中的敏感节点进行推理。
攻击者确定待推理节点后,对待推理节点的推理有多种方式,主要分为3类:单节点推理、多节点融合推理和节点级联推理。
定义11(待推理节点的推理结果集resN(PV,v))过滤视图PV中,节点v是待推理节点,攻击者将已有起源图作为攻击背景,对当前过滤视图的待推理节点进行推理,推理结果通常为已公开起源图中已有的节点的集合。resN(PV,v)表示攻击者采用任一推理方式获得待推理节点v在已公开起源图中可能的取值节点,记作 resN(PV,v) = {v1,v2,…,vm},其中 v1,v2,…,vm∈ PG1∪ PG2∪ … ∪ PGl。
(1)单节点推理。假设过滤视图PV中待推理节点v只存在一个直接前因节点prev(后果节点subv),且该前因(后果)节点未被泛化,将待推理节点与其前因(后果)节点之间的边类型记作epre(或esub)。若存在节点s为与前因节点prev(或后果节点subv)相似度最高的节点,其中节点s∈PGi且起源图PGi∈PubPG,在起源图PGi中与节点s相连的边类型为esub(或 epre) 的节点集为 esub(s)= {v1, v2,…, vn}(或epre(s)= {v1, v2,…, vn}),则将节点集 esub(s)或 epre(s)中的节点与待推理节点v的相似度按从大到小的顺序排列的结果,即为待推理节点v的推理结果集。
(2)多节点融合推理。假设过滤视图PV中待推理节点v的直接前因节点集preN(PG,v)和直接后果节点集subN(PG,v)中的节点有多个,如图4所示。 待推理节点为节点 e,其 perN(PV, e)= {p2},subN(PV, e)= {p1},其中节点 p1和节点 p2均未被泛化。此时,攻击者可以结合多个节点,即多个证据对待推理节点进行融合推理。攻击者可以将多个单节点推理方式下同一个节点与待推理节点的相似度取和,作为多节点融合推理的结果集。
(3)节点级联推理。假设过滤视图PV中有多个泛化节点,某待推理节点的直接前因节点或直接后果节点也是泛化节点,此时对待推理节点的推理需要通过级联推理的方式完成推理。如图4所示,若节点e0、p1为泛化节点,当要对节点e0进行推理时,其直接前因节点p1也为泛化节点,此时,对节点e0的推理需要采用级联推理的方式完成。
以上3种推理方式在攻击者的实际应用中通常不是单独使用的,对同一节点的推理可能需要同时用到3种推理方式。采用的推理方式越多,攻击者推测出敏感节点的可能就越大,攻击者可以对多种推理方式所得到的推理结果对比分析得出最终的推理结果。
2.3 敏感节点安全性
不同情况下,攻击者推理出敏感信息的难度不同,本文将攻击者最终确定的待推理节点的推理结果节点与原始敏感节点的相似性作为敏感节点安全性的评价指标,记作Q,形式化地表示为
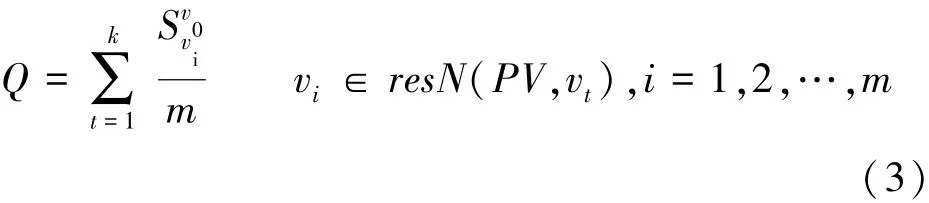
其中,过滤视图 PV中被泛化的节点数为 k。resN(PV,vt) ={v1,v2,…,vm} 为攻击者采用单节点推理方式获得的待推理节点vt的推理结果,m为节点集resN(PV,vt)中节点的个数。攻击者将节点vi(1≤i≤m)作为待推理节点vt的最终推理节点值,而v0表示待推理节点v真实的原始敏感节点中的取值。
显然,0≤Q≤1,Q的值越大,表示攻击者最终确定的待推理节点的最终推理节点与真实的敏感节点的相似度越高,则敏感信息的泄露概率就越大,过滤视图中敏感信息的安全性就越低。
3 基于节点聚类的数据起源安全保护方法
首先,提取原起源图和已公开起源图中所有实体节点、活动节点和代理节点的信息,应用word2vec算法思想将节点信息转换为嵌入向量[17];通过计算嵌入向量间的相似度,采用聚类算法分别构造实体节点、活动节点和代理节点的聚类层次树;根据用户指定的敏感节点更新泛化节点集,对泛化节点集中的节点,结合其所在的聚类层次树进行泛化,并且计算敏感节点的泄露概率,将该概率值与用户的期望值相比较,若小于用户期望值,则泛化完成,输出过滤视图;否则更新泛化节点集,即将敏感节点的关联节点更新到泛化节点集中,继续泛化,直至实际的敏感节点泄露概率值小于用户期望值。
3.1 层次聚类树的构造
起源图中节点数据通常以文本形式存储,要想对其进行聚类,须将其转换成可计算的结构化数据,即向量形式。本文应用word2vec算法实现文本到向量的转换[18-19],如图 6 所示。

图6 word2vec算法示例
从起源图原始数据表中获得节点属性值,组合为文本数据构成语料库,使用word2vec算法获得起源图所有节点的向量表示。
使用层次聚类算法,通过计算节点向量间的距离,分别形成实体节点、活动节点和代理节点的层次聚类树。层次聚类算法是基于簇间相似度进行的,每个簇类中包含了一个或者多个样本点,通常用距离评价簇间或者样本间的相似度,即距离越小相似度越高,距离越大相似度越低[20]。
3.2 基于层次聚类树的节点泛化策略
起源图中的敏感节点通常是由起源图所有者指定,当所有者指定敏感节点后,首先依据该节点所在的层次聚类树,对敏感节点进行泛化。
由于起源图的产生方式多种多样,其中具有多种依赖关系,攻击者可能会根据起源图的依赖关系对敏感节点进行推理,很大可能会造成敏感信息泄露,所以仅仅泛化敏感节点是不够的,而需要结合起源图的结构信息,也就是节点间的依赖关系,对敏感节点的关联节点进行泛化,以实现更高程度的隐私保护。如图7所示,节点A与节点B相关,而节点B又与节点C相关。若节点B为敏感节点,在泛化时不能仅仅泛化节点B,还需要对节点A和节点C进行泛化,从而保证节点 B的敏感信息不被关联推理。
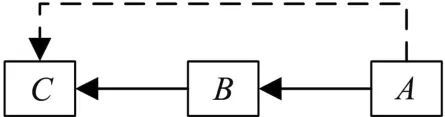
图7 简单起源图
因此,节点的泛化主要分为敏感节点的泛化和敏感节点关联节点的泛化。
定义 12(泛化节点集 HPG,v)PG 为起源图,v为敏感节点,则泛化节点集HPG,v表示在起源图PG中,当敏感节点是v时,需要进行泛化的节点集合。
3.3 泛化节点集的计算
节点泛化分为敏感节点和关联节点的泛化,但若是泛化敏感节点的所有关联节点,会造成泛化过度和过滤视图的效用低下,故本文引入敏感节点的泄露概率的概念,作为泛化节点集更新和泛化停止的标志。
敏感节点泄露概率分为实际值pcact和期望值pcexp。期望值由起源图所有者指定,代表对起源图敏感信息的安全程度的要求;实际值由本方法给出,每次泛化节点集中的节点泛化完成后,计算敏感节点的泄露概率,与用户的期望值相比较,当实际值小于等于用户的期望值时,结束泛化,此时起源图中被泛化节点的数量记为K。
在当前起源图中,已泛化节点为v,通过查看该节点所在的聚类层次树可知,节点v的泛化结果簇为 RPG(v)= {v1, v2,…, vt,…, vn},其中 v1, v2,…,vn∈PG1∪PG2∪…∪PGl,vt为原起源图 PG 中的敏感节点。节点 v的直接前因节点集preN(PG,v)={pre1v, pre2v, …, premv }, 直 接 后 果 节 点 集subN(PG,v)= {sub1v, sub2v,…, subkv }。 以下以pre1v为例,计算节点v与节点pre1v之间敏感节点的泄露概率。首先,在公开起源图集 PubPG={PG1,PG2,…,PGl}中查找与pre1v相似度最高的节点pre1v′,pre1v′所在的起源图记作 PGi(1≤i≤l),节点 pre1v与节点pre1v′之间的相似度采用式(2)计算得到,记作C。其次,由于节点v是节点pre1v的后果节点,则起源图PGi中获取节点pre1v′的直接后果节点集 subN(PGi, pre1v′) = {v1, v2,…, vs},其中 v1,v2,…, vs∈PGi。 最后,采用式(4)计算节点集 RPG(v)= {v1, v2,…, vn} 中节点与节点集 subN(PGi,pre1v′)= {v1, v2,…, vs}中节点的相似度,则
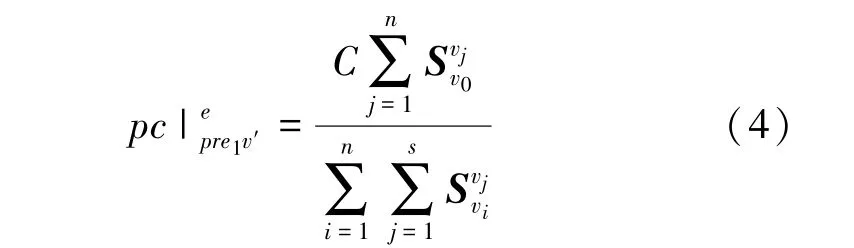
其中,v0为起源图 PG中的敏感节点。vi∈ RPG(v),i= 1,2,…,m。 vi∈ subN(PGi,pre1v′),j= 1,2,…,s。C为节点pre1v与节点pre1v′之间的相似度。
采用式(4)来计算泛化节点与其未泛化的前因节点或后继节点之间的敏感节点泄露概率。当有多条路径可以对敏感节点的泛化节点进行推理时,敏感节点的实际泄露概率取所有路径上敏感节点泄露概率的最大值;当被泛化节点的前因节点或者后果节点也被泛化时,采用级联推理的方式,从一个未泛化节点为推理起点,完成对敏感节点的泛化节点的推理。
一次泛化完成后,比较敏感节点泄露概率的实际值pcact和起源图所有者给定的敏感节点泄露概率期望值 pcexp,当pcact≤pcexp时,结束泛化;否则,查看泛化节点集中是否有未泛化节点,若有,则对其进行泛化,否则查找当前泛化节点集中第一个存在未被泛化的直接前因节点或后果节点的节点,并将其未被泛化的直接前因节点或后果节点的节点加入泛化节点集中继续泛化,直至敏感节点泄露概率的实际值pcact小于等于起源图所有者给定的敏感节点泄露概率期望值pcexp。
当完成泛化节点集HPG,v中所有节点的泛化,并且满足敏感节点泄露概率的实际值pcact小于等于起源图所有者给定的敏感节点泄露概率期望值pcexp后,提取泛化节点集HPG,v中每一个节点的泛化结果簇RPG(v)中节点的共有特征,作为预发布起源图PV中对应节点的属性信息。
4 敏感节点隐私保护算法
针对已经公开的起源图集对当前起源图具有安全威胁这一场景,以及现有隐私保护方法改变起源图结构的问题,本文提出一种基于节点聚类的数据起源安全保护方法。该方法通过节点聚类分析并建立已有起源图中节点与当前起源图节点之间的关联,以此作为节点泛化的依据,结合用户对过滤视图中敏感节点泄露概率的要求,对起源图进行不同程度的泛化,达到隐私保护的目的。
该算法的基本思想如下:
(1)应用word2vec算法思想,获取已公开起源图与当前起源图中的节点的向量化表示。
(2)计算同类型节点之间的相似度,应用层次聚类算法获取同类型节点,即实体节点、活动节点以及代理节点的层次聚类树。
(3)根据用户指定的敏感节点和期望的敏感节点泄露概率值对起源图进行泛化。为了保证过滤视图的溯源效用,选择敏感节点所在的最小簇作为其泛化结果。
(4)每一次泛化完成后,计算敏感节点的实际泄露概率值,若实际值小于用户的期望值,则完成泛化输出过滤视图,否则,更新泛化节点集,继续泛化。
基于节点聚类的敏感节点隐私保护算法(PrivacyProtectionAlgorithmforSensitiveNodes, PPA)的伪代码如下。
输入:当前起源图PG,已公开起源图集 PubPG={PG1,PG2,…,PGl},敏感节点v,敏感节点泄露概率期望值pcexp
输出:过滤视图PV,敏感节点泄露概率实际值pcact
PPA算法包括节点聚类和节点泛化两部分,因此,对算法的安全性分析从这两部分进行。
定理1已知树 Ten,Tact,Tag是根据已公开起源图PubPG和当前起源图PG,采用PPA算法分别得到的实体节点、活动节点和代理节点的层次聚类树,则攻击者无法重建树 Ten,Tact,Tag。
证明:层次聚类算法的选择不唯一,且同一个层次聚类算法中,参数设置不同,如簇类中最大样本数、簇类合并的临界距离等,都会对层次聚类树的形状产生巨大的影响。攻击者无法准确获得PPA算法中的参数设置,故无法重建PPA算法中生成的层次聚类树Ten、Tact、Tag,也就无法依据层次聚类树获得泛化节点的准确信息。
定理2已知图PV是起源图 PG={V,E,Ph}由PPA算法得到的过滤视图,则当攻击者以已公开起源图 PubPG={PG1,PG2,…,PGl}为背景知识时,从过滤视图PV中识别出敏感节点的概率为1/K。
证明:由3.3节泛化节点集的计算可知,当泛化至满足用户期望的敏感信息泄露概率时,被泛化节点数为K,即在过滤视图PV中包含K个被泛化的节点,因此攻击者从被泛化节点中识别出敏感节点的概率不大于1/K。
5 实验与结果分析
现有针对数据起源的隐私保护方法主要有3类:匿名[14]、抽象[15]以及删除+修复[6]。 其中匿名和抽象是主要针对敏感信息是节点的情况;而删除+修复针对的是敏感的间接依赖,即敏感信息是起源图中节点间的依赖关系,该方法首先删除一条敏感边,然后添加一条边来修复由于删除边误断的非敏感间接依赖。综上,本文提出的PPA算法与经典算法抽象和匿名相同,主要针对敏感信息是节点的情况,而删除+修复主要针对敏感信息是间接依赖的情况。因此,本节设计实验对比本文提出的PPA算法与经典的匿名和抽象算法在应用场景、性能和过滤视图的效用方面的差异,最后分析实验结果,说明本算法的优势。
为了验证本文提出的PPA隐私保护算法的各项性能,在实验部分选取了3个数据集进行测试,主要进行了两方面的实验:(1)对自身算法进行性能分析;(2)本文分别以3类数据集为实验数据,将本文算法与抽象和匿名经典算法进行对比分析。
本文所提算法和对比算法的实验环境为DELL Inspiron5598 笔记本电脑,Intel Core i5⁃10210U 2.11 GHz,8 GB内存,Window10的64位操作系统,所有代码用Python语言实现。
5.1 数据集
所选数据集是来自W3C起源数据模型的公开起源图数据集,分别为来自ProvStore的SmartHome、Article⁃prov和 Final。 数据集的详细情况如表 1所示。
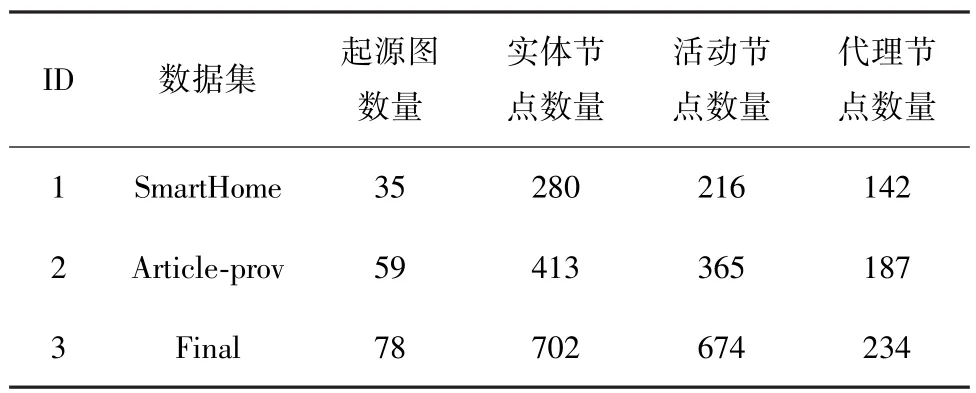
表1 数据集详细情况
5.2 评价标准
数据溯源是起源图的基本用途,它是根据已知起源图,对可能影响特定数据节点当前状态的历史信息进行追溯分析的过程[21]。溯源效用是用来定量衡量过滤视图满足用户溯源需求的程度,进而评价不同的隐私保护技术优劣的一个重要指标[22]。
定义13(溯源结果ΔPG(v0)) 起源图PG=(V,E, Ph)中,对于任意 v0∈V,若存在 vi∈V 使 Ph(v0,vi)∈Ph 或<v0, vi>∈E, i=1, 2, …, m,称节点vi为节点 v0的历史节点, ΔPG(v0)={vi|Ph(v0,vi) ∈Ph或 <v0,vi>∈E}称为节点u的溯源结果。
本文采用文献[23]中提出的效用评估模型,利用马尔科夫链建模历史节点通过溯源路径对溯源起点v0的影响,得到历史节点影响v0的因果信度分布,如式(5)所示。
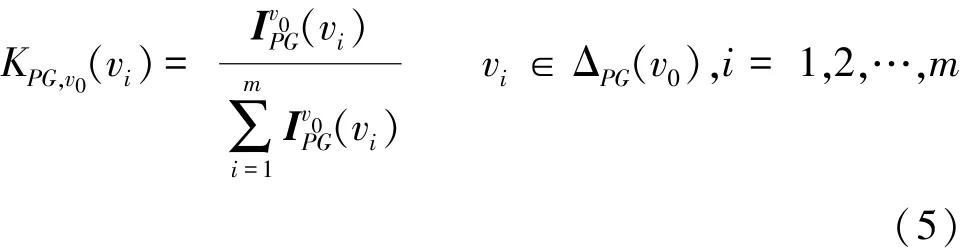
其中,ΔPG(v0)为溯源起点 v0的溯源结果, Iv0PG(vi) 表示起点v0的溯源结果集中节点vi的置信度向量。进而可利用相对熵计算原起源图PG与过滤视图PV的因果信度分布之间的相似度,如式(6)所示。
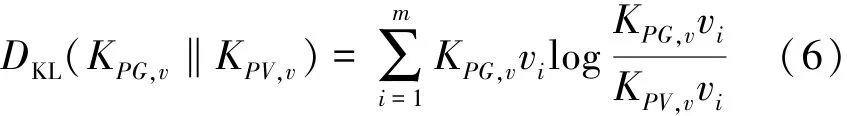
相对熵 DKL(KPG,v‖KPV,v) 的值越大,则过滤视图PV与原始视图PG之间的差异就越大。本文用U =e-DKL来表征效用,其取值范围为[0,1]。 溯源效用U与相对熵的值成反比,即原始起源图与过滤视图之间的差异越小,溯源效用越高。
5.3 实验方案与结果分析
本文的实验目的是对所提出的安全保护方法进行实证和分析。通过与现有的方法作对比,说明本文方法的优势。
5.3.1 应用场景对比
对比本文提出的PPA算法与抽象和匿名两种经典算法在应用场景上的差异,如表2所示。本文提出的PPA方法和已有的匿名和抽象经典算法相比,匿名和抽象两种方法无法满足用户定制发布的需求。当需要对一个或多个敏感节点进行隐私保护时,匿名方法会直接将节点信息置空,这种做法会使数据损失度较大;抽象方法会将敏感节点连同其周围的非敏感节点一并隐藏,无法满足用户保留非敏感节点的需求,无法定制发布。

表2 PPA与匿名、抽象的应用场景比较
5.3.2 算法性能对比实验
采用 SmartHome、Article⁃prov 和 Final三个数据集为实验数据,每一次随机指定1个敏感节点,使用3个算法各自重复执行1 000次,对比3个算法最终生成过滤视图的时间消耗,结果如图8所示。抽象算法的时间消耗要高于本文的PPA算法和匿名算法,这是因为抽象方法需要多次遍历起源图,获取敏感节点周围的结构信息,进而选取和敏感节点合并抽象的节点,然后再将所选节点抽象后与起源图中其他节点相连,时间消耗较大。同时实验结果显示,在不同的数据集上,PPA算法与匿名算法的时间消耗相差无几,但匿名算法的时间消耗略低于本文的PPA算法,这是因为匿名算法只是将敏感节点内的数据置空,而不需要遍历起源图。
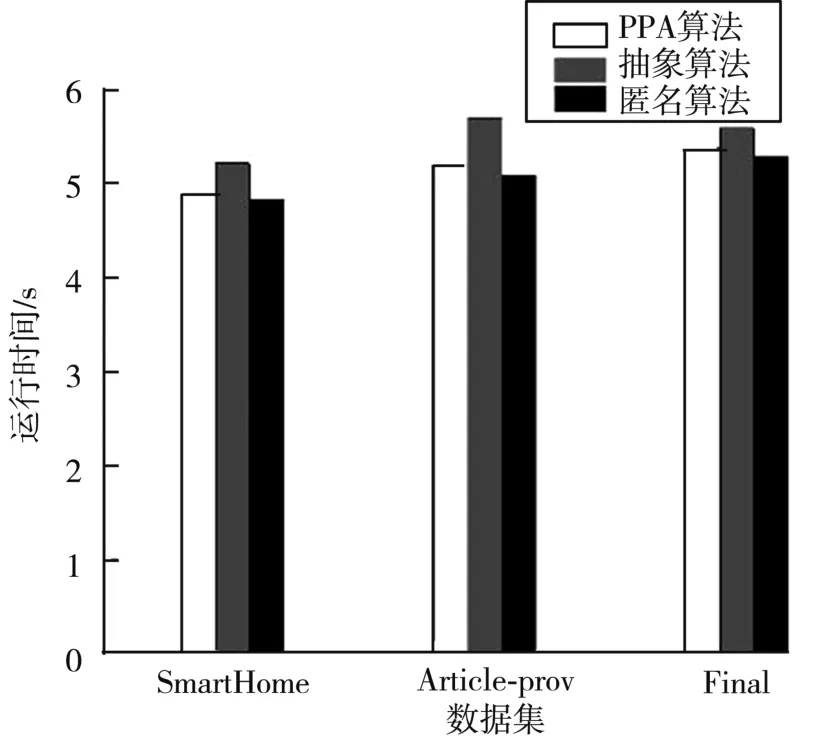
图8 不同数据集上运行时间对比
另外,当起源图中敏感节点的数量不同时,过滤视图的溯源效用也会产生较大的差异。由于起源图节点数目的限制以及领域专家的经验,起源图中敏感节点的数量一般不超过10个,因此本文选取Article⁃prov数据集为例,比较本文算法与匿名和抽象算法在性能上的差异,结果如图9所示。
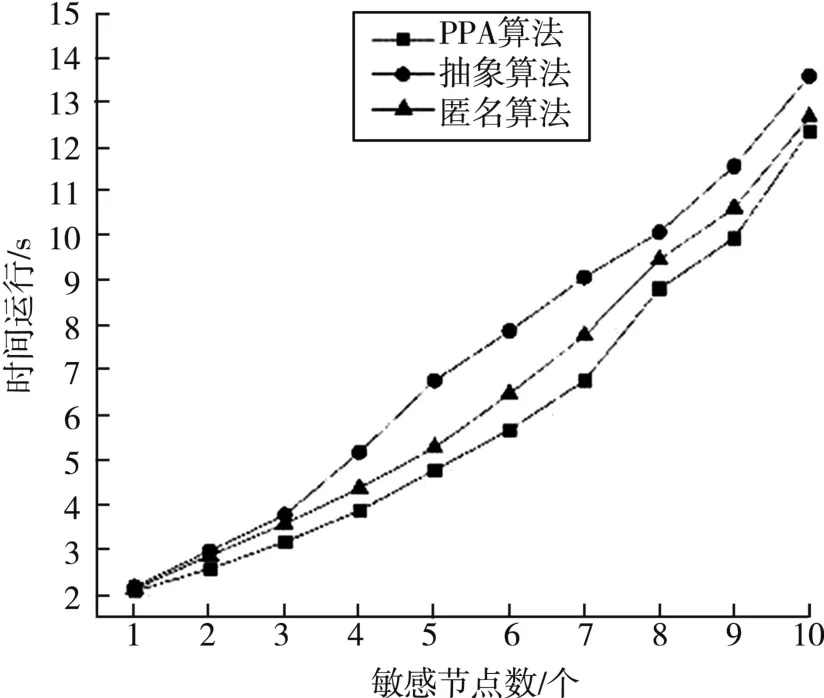
图9 性能对比结果
由图9可知,抽象算法由于需要多次选取抽象多个节点,消耗时间最多;匿名算法和本文所提算法总体来说差异较小,但本文算法所需的运行时间平均略低于匿名算法。
综合分析图8和图9可知,当敏感节点的数量较少时,PPA算法、抽象算法和匿名算法在性能上的差异很小,但当起源图中敏感节点的数量较多时,本文所提的PPA算法更具优势。5.3.3 过滤视图效用对比实验
由不同敏感节点下的算法性能实验可知,当敏感节点数为1、2、3时,3种算法的运行时间大致相同。在算法运行时间大致相同的情况下,本文设计实验 1、2、3,分别为选取数据集 SmartHome、Final和Article⁃prov为实验数据,采用本文提出的PPA方法、匿名和抽象3种隐私保护方法,当敏感节点的数量分别为1、2、3时的过滤视图的效用结果对比,如图10所示。由图10可知本文提出的PPA方法与匿名和抽象方法相比,能够有效地保证过滤视图的溯源效用。与抽象相比,本文方法能够在隐藏敏感信息的基础上不改变起源图的结构,抽象方法会将起源图中的敏感节点周围的非敏感节点与敏感节点一并隐藏,降低过滤视图的溯源效用;与匿名相比,匿名虽然也不改变起源图的结构,但匿名会把敏感节点的信息完全置空,这样会造成信息损失,当起源图中的敏感节点数量越多时,信息损失就越大,过滤视图的溯源效用就越低。总的来说,本文提出的隐私保护方法与抽象和匿名相比,能够更加有效地保持过滤视图的溯源效用。
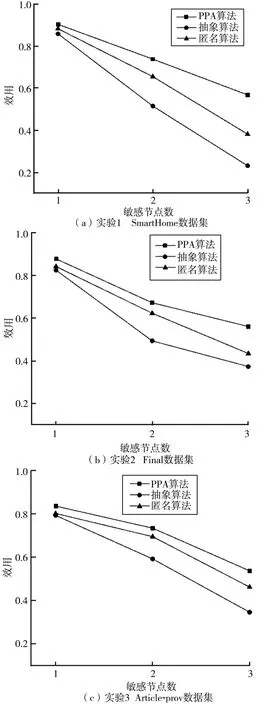
图10 过滤视图效用对比结果
6 结束语
本文针对现有数据起源隐私保护方法未考虑已公开起源图对当前起源图的关联推理的现状,提出了基于节点聚类的数据起源安全保护方法。实验结果表明,本文提出的方法能够满足数据起源发布者不同的发布需求,而且能够在保护敏感数据的同时更好地保持过滤视图的溯源效用。未来工作包括本隐私保护方法的优化,研究安全与效用能够达到平衡的综合过滤方法。
