基于人工智能的脱机手写数字识别研究综述
2021-11-24张华美张皎洁
张华美,张皎洁
(南京邮电大学电子与光学工程学院、微电子学院,江苏南京 210023)
在光学字符识别领域中,手写数字识别是一个必不可少的组成部分[1],它是在光学字符识别基础上,采用计算机等处理器对手写阿拉伯数字进行识别的一种技术。该技术在财务报表、邮政分拣、成绩统计、银行票据等场合应用广泛。依据字体分类,数字识别可分为印刷体识别和手写体识别两类,而手写体识别遵从识别时间分类,又可分为联机手写体识别与脱机手写体识别两种模式。目前印刷体和联机手写体数字识别系统的使用非常成熟[2],而脱机手写体数字识别因其写法不同难以做到兼顾各种写法的实用性数字识别系统。近年来,众多学者在机器学习领域、深度学习领域、机器学习与深度学习相结合的领域对脱机手写数字识别进行研究,取得了不错的成果。但目前仍无法满足社会的迫切需求,因此研究高性能的脱机手写数字识别技术非常有必要。
1 机器学习在手写数字中应用
机器学习不仅能从海量数据中挖掘并找到其中隐含的规律,还能应用于某些未知数据的预测,因此可以将机器学习的方法运用到手写数字识别中。图1是运用机器学习的方法进行手写数字识别的流程图,主要包括数据集、预处理、特征提取、分类器等。
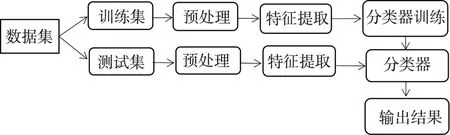
图1 手写数字识别流程图
1.1 划分数据集
机器学习中手写数字常用的数据集有3个:(1)美国标准技术研究所手写数字数据集(MNIST),其中训练集样本为6万张,测试集样本为1万张,每张手写数字图像的灰度值统一被归一化,图像像素为28∗28。(2)美国邮政手写体数字数据集(USPS),数据集所有图像均为16像素∗16像素的灰度图像,其中训练集数据样本为7 291张,测试集数据样本为2 007张。(3)美国加州大学欧文分校提出的手写数据集(UCI),数据集包含了3 832个训练数据和1 797个测试数据,全部为16像素∗16像素的灰度图像。
1.2 预处理
图像的获取容易受到外界环境的干扰和影响,得到的图像需要进行预处理操作。常用的预处理措施有二值化、细化、归一化、去噪等,在尽可能保存原始图像信息的前提下,去除图像受到的干扰,使图像可以适用不同模型的需求。
1.3 特征提取
手写数字识别中采用特征提取的方法主要分为三大类:第一类图像像素降维法包括主成分分析独立成分分析法[3]等;第二类结构特征法包括轮廓特征[4]、首个黑点位置特征[4]、矩特征[5]等;第三类统计特征法包括粗网格特征、笔划密度特征[6]、投影特征[6]、傅里叶系数特征[7]、13 点网格特征提取法[8]等。
1.4 分类器
在手写数字识别研究过程中,支持向量机(SVM)、K⁃近邻(KNN)、随机森林(RF)、决策树(DT)、贝叶斯网络(BN)等传统分类器对手写数字识别产生了一定的影响力。由Cortes等[9]于1995年提出的基于统计学理论的SVM,成功通过核函数的思想把低维空间非线性分类问题转变为高维空间线性分类问题,常用的有线性核函数、多项式核函数、径向基核函数、Sigmoid核函数[10]等。SVM是著名的二分类器,在二分类方面表现突出,而通过对多个SVM组合构造算法,可以用来实现多分类问题。目前SVM解决多分类问题的主要方法有一对一算法(OVO)[11]、一对多算法(OVA)[12]、有向无环图算法(DAG)[13]。 李雅琴等[14]分别使用 OVO,OVA,DAG算法对USPS手写数字数据集进行统一测试,实验选用径向基核函数(RBF),c参数设为32,测试结果如表1所示。
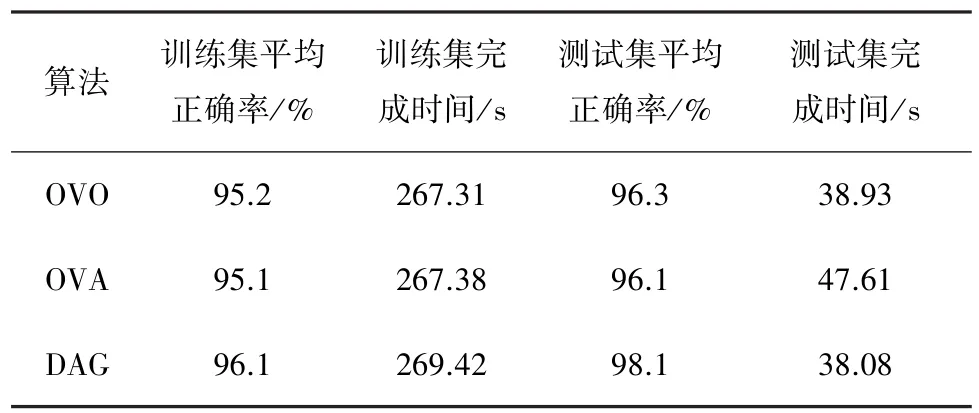
表1 三种算法实验结果
在SVM解决多分类问题时,还可以对核函数中c、g参数进行优化,常用的优化算法有网格寻优算法(GS)[15]、遗传寻优算法(GA)[16]、粒子群寻优算法(PSO)[16]。 石会芳[17]随机选取 MNIST 数据集1 050个训练样本和1 520个测试样本,分别采用GS算法、GA算法、PSO算法对核函数中c、g参数进行寻优,根据实验结果可知,该三类算法的分类准确率分别为92.181%、93.381%和94.4211%。 Tuba等[18]分别使用x轴、y轴,y=x和 y=-x投影直方图对MNIST数据集进行特征提取,选择SVM进行分类。实验结果表明y轴投影直方图的识别效果最佳,识别率为 94.68%。 Abbas等[19]使用前景特征(FF)、背景特征(BF)、几何特征(GF)、均匀网格特征(UGF)以及组合特征(BF、FF)、(BF、FF、GF)和(UGF、BF、FF、GF)对 MNIST 数据集进行特征提取,通过并行组合两个SVM分类器的输出来提高手写数字识别性能。对于不同的特征方法使用SVM分类的平均错误率如表2所示。总体来说,SVM适合处理小规模样本,分类准确率较高,当SVM处理大量样本时,核函数映射维度高,计算繁重,运转效率低,导致分类效果较差[20]。
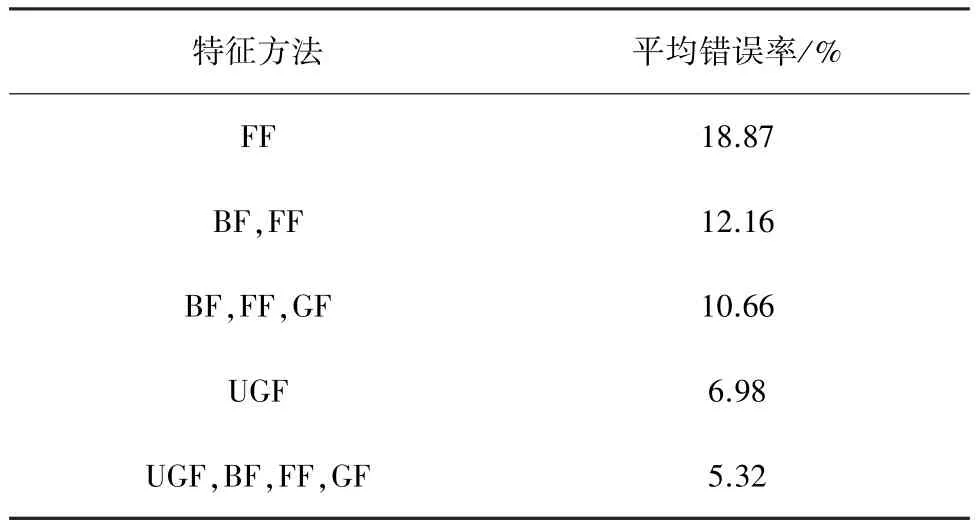
表2 SVM分类的平均错误率
贝叶斯网络(BN)是1988年由Pearl提出的基于统计信息论,不确定性推理和数据分析的理论,结合Campos[21]提出的需要确定随机变量间拓扑关系和构造条件概率表的一种网络。该网络常用的算法有评分算法即K2算法[22]和爬山算法。张艳芳[23]利用关联规则可以挖掘数据的优势,提出了一种基于关联规则和爬山算法的贝叶斯网络,取得了91.1% 的识别率。Liu[24]对BN模型连接权重和学习参数进行改进,提出了一种新的BN分类器建立手写数字识别模型,结果显示新的BN分类器在手写数字识别中可以达到92.7%的识别率。总之,BN分类器原理简单,可以高效处理多分类问题,然而对于残缺数据却不太灵敏[25]。 卜凡军[26]改进了 Cover等人在1968年提出的一种创新算法,通过测量不同特征值之间的最短距离,计算K值进行分类,最终得到92.3%的识别率。Tiwari等[27]首先对 MNIST数据集进行平滑降噪处理,然后提取结构和统计特征,最后使用KNN进行分类达到了96.3%的识别率。张翠军等[28]提出了一种基于多目标粒子群优化(BPSO)的特征选择算法,使用KNN对UCI手写数字数据集进行分类,识别性能和特征子集个数作为评价特征子集优劣的标准,结果表明该算法挑选的特征子集具备良好的识别指标,分类错误率可以降低至7.4%。总之,KNN计算简单,识别精度高,但对内存要求较高,对不相关的功能和数据规模敏感[29]。 决策树(DT)是一种带有判决准则的树[30],根据树中的判决准则对未知样本的类别和值进行预测。决策树训练常用的算法有贪心算法(ID3)、贪心算法的改进版算法(C4.5)和分类回归树算法(CART)[31]。 陈军胜[32]提取手写数字结构特征,利用ID3算法构造DT分类器对手写数字进行分类,可以达到86.7%的识别率。姜文理等[33]使用CART算法构造DT分类器对在线用户手写数字进行识别,实验结果显示,参加测试的所有用户手写数字的平均识别率高于93%,具有很好的用户适用性。当决策树作为分类器时,计算速度快,对缺失的中间值不敏感,处理不相关的特征数据可能会产生过拟合现象[34]。
2 神经网络和深度学习在手写数字中应用
2.1 神经网络
从20世纪40年代起,人们相继提出了许多种类的神经网络模型,按照模型结构可以划分为前馈型网络和反馈型网络[35]。BP神经网络是前馈神经网络的代表之一,它是由Rumelhart等[36]于1986年提出的一种误差反向传播训练的多层前馈神经网络。BP神经网络从结构上讲由输入层、隐含层和输出层组成,可从本质上讲,它是以网络误差的平方为目标函数,利用梯度下降法达到计算目标函数最小值。不少国内外学者把BP神经网络应用到了手写数字识别。钟乐海等[37]运用13点网格特征的方法对MNIST数据集进行特征提取,BP神经网络作为分类器,得到79.5%的分类准确率。Cun等[38]改进BP神经网络结构和权重约束,对USPS手写数字数据集进行测试,识别率可以达到81.6%。Wellner等[39]在Matlab中实现了基于反向传播训练的多层BP神经网络,该网络识别率为91.6%。董慧[40]运用傅里叶系数特征、笔划密度特征、轮廓特征等方法对USPS手写数字数据集进行特征提取,BP神经网络作为分类器,得到测试集正确率为94.15%。由于BP神经网络通常需要逆向调整权重和阈值,耗时长,运算大[41],且网络结构与参数大多数靠经验和实验验证得出。Huang等[42]基于对逆向传播算法的改进,提出了一种前馈神经网络快速学习算法——极限学习机(ELM)。该算法对输入层与隐含层之间的权重是可以随机设置的,关于隐含层神经元的偏置,在训练过程中也无需调整,唯一要学习的参数是隐含层和输出层之间的权重[43],对于标准的ELM算法可以通过优化算法来提高其泛化能力,常用的有正则算法优化的极限学习机(R⁃ELM)和粒子群算法优化的极限学习机(PSO⁃ELM)。郄小美[44]利用R⁃ELM对手写体数字进行仿真实验,实验结果表明,当隐含层节点个数设置为200时,测试集识别率为84.20%,测试时间只需0.007 9 s。毕浩洋[45]利用标准 ELM 和 PSO⁃ELM 分别对 MNIST手写数据集进行实验,结果表明:当ELM隐含层节点数目为140时,训练集准确率为98.10%,测试集准确率为 91.33%,训练时间为0.843 8s;当 PSO⁃ELM迭代次数为5,隐含层节点数目为50时,训练集准确率为98.89%,测试集准确率为98.40%,训练时间为40.352 8 s。总之相对其他神经网络而言,ELM具有识别速度快、分类精度高、泛化性能好等优点,然而ELM只适应于单隐层神经网络,且不使用反向传播,处理过于复杂的问题时效果不佳[46]。
2.2 深度学习
目前,卷积神经网络(CNN)是一个具有可学习权重和偏置的神经元组成的前馈神经网络。它在深度学习算法中占据了重要的地位,伴随深度学习理论的深入和计算设备的改进,CNN得到了迅速发展,在计算机视觉、人脸识别、自然语言处理等领域得到了广泛运用[47]。CNN的网络架构由输入层、卷积层、池化层、全连接层、输出层5个基本部分构成[48]。其中卷积层由两个组件搭配而成,第一个组件是滤波器,第二个组件是卷积核。卷积层的目标是为了提取输入样本中不同的特征,而多次利用卷积层提取更复杂和更全面的特征[48]。池化层是CNN模型中控制过度填充的一个好方法,池化实质上是一种向下采样的方式,有3种类型:最大池化、最小池化、平均池化,目的是实现特征的不变性,同时起到了一定的降维作用[49]。卷积层和池化层提取的所有特征都将传递给全连接层,与普通神经网络连接方式相同,全连接层一般都在网络的最后几层执行分类的任务。图2为计算机科学家Yann等[50]在1998年提出的LeNet网络模型,它作为卷积神经网络的“开篇之作”,由两层卷积、两层池化、三层全连接组成。在CNN快速发展的历程中,除了经典的LeNet模型,还提出了一些优秀的深度卷积神经网络(DCNN)模型。按照时间顺序以及网络层数的依次递加,相继推出了AlexNet模型、VGGNet模型、GoogLeNet模型等,极大地促进了手写数字识别领域的发展。图3为Alex等在2012年ImageNet图像分类竞赛中所采用的AlexNet网络模型,将1 000类图像的Top⁃5分类错误率从最初的26.172%降低到 15.315%,该模型获得了竞赛的冠军。Krizhevskya等[51]提到过当年的 GPU运算能力不高,Alex等构造两个GPU一起训练AlexNet网络,该网络由5层卷积、3层池化、3层全连接组成。
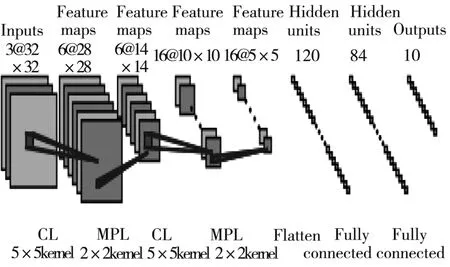
图2 LeNet网络模型结构
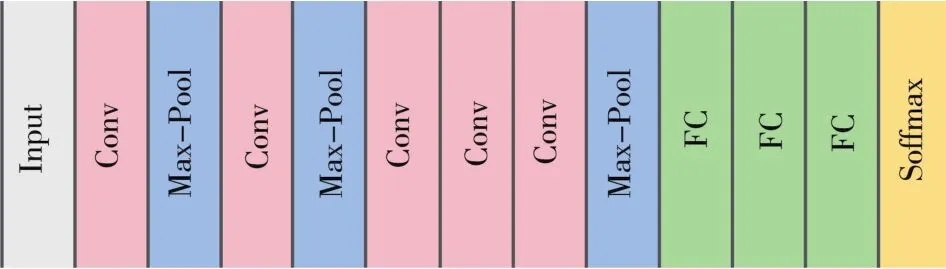
图3 AlexNet网络体系结构
图4是由牛津大学Visual Geometry Group实验组研究员们提出的一个VGGNet模型,该模型共有16层网络结构,获得了2014年的ImageNet图像分类竞赛亚军。该模型是在AlexNet模型的基础上使用多个3∗3的卷积核来增加网络深度,从而提高图像的分类精度[52]。 图 5是由 Christian Szegedy在2014年提出的一种全新的深度学习GoogLeNet模型的基本单元,采取了多尺寸卷积再聚合的方式拓宽网络结构,通过1∗1的卷积运算来减小参数量。GoogLeNet模型有22层网络结构,与AlexNet模型和VGGNet模型通过卷积层纵向堆叠的方式相比,Xie等[53]提供了深度卷积神经网络构建的另一种思路。由于卷积神经网络设计的目的是为了减少网络的权值参数并适应不同尺度,因此很多学者在这些经典模型的基础上改进网络结构来提高手写数字的识别率。刘辰雨[54]提出用Dropout技术构造网络结构,挑选Relu函数作为激活函数,搭建出一个性能更优的LeNet+网络模型,把识别率提高到98.8%。黄献通[55]通过预设随机小参数对LeNet模型网络参数进行更新,应用在试卷分数复核统计上,实验结果表明,在试卷分数复核应用中数字识别的平均正确率达到94%以上。由于AlexNet模型用到的数据库是ImageNet大型计算机视觉数据集,图像中含有更多的无关噪声,分类任务多,识别难度高,因此,AlexNet模型在分类任务不多的手写数字识别中可以发挥出更好的性能。Beohar等[56]调整网络层数,改进AlexNet模型,将卷积层和池化层都设置为4层,全连接层设置为5层,将改进后的模型采用MNIST数据集进行验证,使用人工网络的平均误差为1.31%,而使用该模型的平均误差仅为0.91%。Wen等[57]设计了一种直线网络的深度卷积神经网络模型,该模型主体框架基于AlexNet模型,其中特征提取部分设置了卷积层和池化层,全部采用2∗2的卷积核,分类部分则由舍弃层、线性层和激活层组成。这一模型在MNIST数据集中进行测试,通过10次迭代,测试集准确率高达99%。Ghosh等[58]借鉴了共享卷积核的思想,改变AlexNet模型网络参数,分别从精度、性能、测试时间3个方面对改进的AlexNet模型以及BP神经网络进行了对比,实验结果表明,改进的AlexNet模型在精度、性能、测试时间方面都明显优于BP神经网络。近年来标准化形式的手写数字集已普遍应用于CNN中,取得了不错的成绩。越来越多的学者开始将其他形式的手写数字集也应用到CNN中,例如孟加拉文手写数字集NumtaDB[59](由 2 700 多名贡献者手写的超过85 000个样本)、包含了17 768个高分辨率的西藏手写数字图像集TibetanMNIST[60]、计算机视觉手写数字集CVL[61](由10个类别组成,每个类有3 578张不同风格的数字图像)等。Zunair等[62]调整VGGNet模型中网络层数和网络参数,使用改进版VGGNet模型对NumtaDB数据集进行分类,获得了97.09%的准确率。Saha等[63]提出了一种数据增强的GoogLeNet模型对NumtaDB数据集进行测试,结果显示原GoogLeNet模型在测试集中分类准确率为93%,而经过数据增强后GoogLeNet模型在测试集中分类准确率为98.51%。Bendib等[64]对CNN模型进行改进,设置了3层卷积层、3层池化层、2层全连接层的网络结构,并对CVL数字集进行测试研究,研究结果表明该模型达到了96.63%的分类精度。Zhang[65]提出了一个新的CNN模型,在训练过程中增加了数据增强和学习率衰减这两部分。利用数据增强技术增加输入的多样性,通过监测训练中的学习率衰减,使参数更新变小。这一模型在TibetanMNIST数据集中得到了应用,结果显示训练集准确率为99.98%,测试集准确率为99.21%。虽然基于深度学习的手写数字识别精度高,学习能力强,但是深度学习训练时间长,计算量大,硬件需求高,参数选取缺乏强有力的理论支撑是个无法回避的问题[66]。
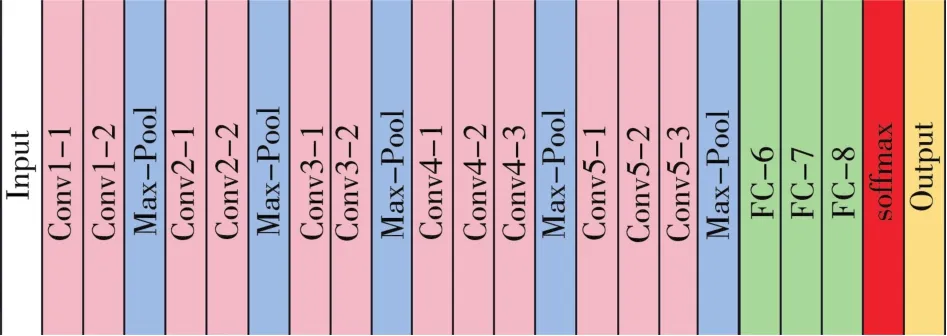
图4 VGGNet网络体系结构
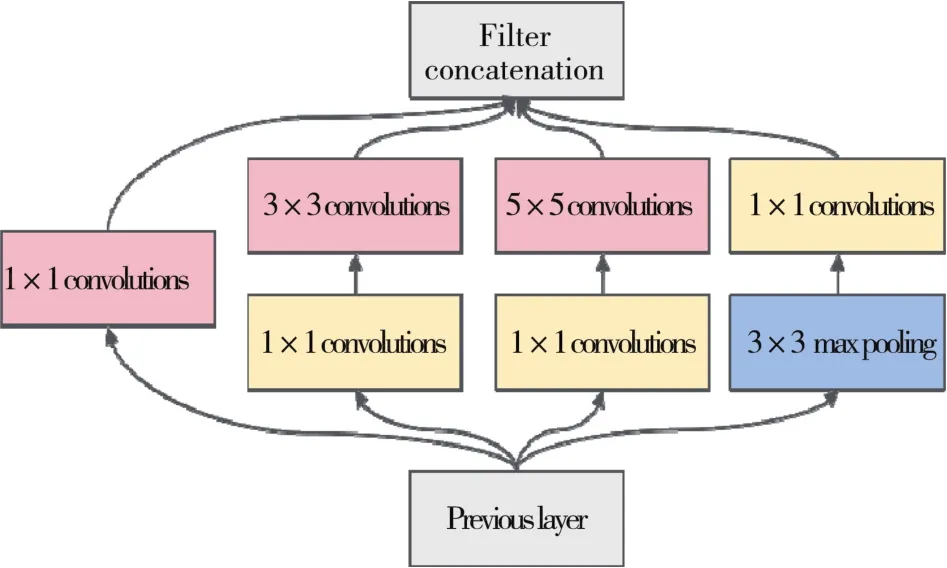
图5 GoogLeNet网络基本单元
3 机器学习与深度学习相结合
针对深度学习中卷积神经网络Softmax函数容易产生计算溢出以及较高的计算机硬件需求,且机器学习中分类算法常常依托人工手动提取特征等问题[67],出现了机器学习与深度学习相结合的思想。近年来国内外学者将这种思想运用于手写数字分类,不仅解决了人工手动提取特征的繁琐步骤和过度依靠先验知识的惯性思维,还可以借助传统分类器除去大多数冗余和无关数据,提升手写数字的分类准确率和预测时间。Peres等[68]使用 MNIST数据集中60 000张训练图像和由11名不同学生手写的3 415幅数字图像组成的专有数据集作为本次实验的数据集,分别采用CNN+SVM、方向梯度直方图(HOG)+SVM、CNN等3种模型对数据集进行仿真测试,实验结果如表3所示。

表3 3种模型识别率对比
Aly等[69]通过余弦平移和弹性畸变等模式畸变对MNIST数据集中所有样本进行数据增强,在特征提取环节中采用CNN的AlexNet模型,分类器使用SVM,原CNN+SVM模型测试错误率为1.03%,然而通过数据增强的CNN+SVM模型却可以实现0.93%的错误率,由此可知,经过数据增强的CNN+SVM模型分类精度有一定的提升。Shima等[70]提出了一种基于主成分分析的卷积神经网络和SVM相结合的算法,其中主成分分析的卷积神经网络提取训练图像中低层次和高层次的特征,SVM替代Softmax函数作为分类器,识别率能够达到96.12%。杨刚等[71]基于CNN和粒子群优化SVM 的手写数字算法对UCI手写数字数据集进行实验评估,发现CNN+SVM(PSO)模型识别率达到 99.11%,而 CNN+SVM模型识别率为95.97%,表明CNN+SVM(PSO)模型达到了很好的识别效果。余圣新等[72]使用深度可分离的卷积层去改进 GoogLe⁃Net结构,通过MNIST数据集进行实验验证得到99.45%的识别率。为了进一步提高网络识别率,在分类层上使用SVM代替CNN中的Softmax层,经交叉验证得到99.78%的识别率。 Rajalakshmi等[73]使用 CNN+SVM(RBF)混合模型对MNIST数据集进行实验,该模型错误率为5.6%。为了进一步降低错误率,对数据集中的所有图像进行旋转、尺度缩放等增强处理,增加样本总数量,使得该模型达到良好的识别效果,错误率降低至 0.19%。林仁耀等[74]随机选取MNIST数据集4 000个训练样本和1 000个测试样本,分别采用 CNN+RF、CNN+KNN、CNN+SVM(linear)模型对数据集进行仿真测试,测试结果如表4所示。由表4可知,CNN+SVM(linear)模型识别率最高且收敛速度较快。总之,机器学习与深度学习相结合的思想在手写数字的识别中发挥了重大作用,深度学习中基于CNN模型的改进能够获得更大的网络宽度,达到更好提取特征的目的,同时机器学习中分类器的分类能力也很强,两者结合获得更高的识别率,有深入研究的价值。
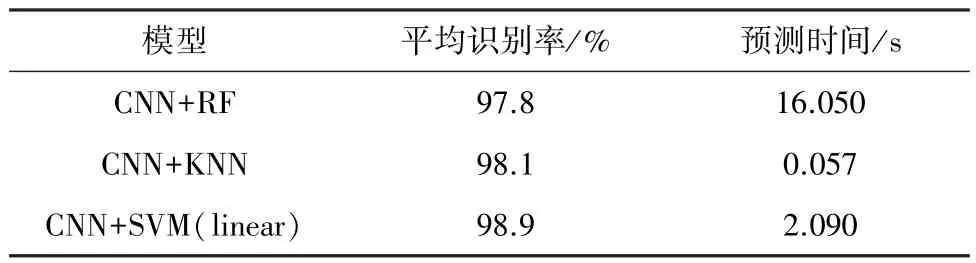
表4 3种模型测试结果
4 结束语
本文对基于人工智能的脱机手写数字识别的研究进行了梳理和总结。现有的技术已能对脱机手写数字有较好的识别效果,但在实际应用中还没达到抗干扰、系统稳定、适应性强等高效系统水平。因此,针对手写数字识别的研究现状提出未来的发展方向:(1)优化识别算法。机器学习与深度学习结合的思想在手写数字的识别中具有突出优势,因此可以根据算法本身特点,融合不同的算法进一步节省训练时间,提升训练效率。(2)扩充数据库。在图像采集这一部分,可以尝试在不同场景下建立自己的手写数据库,加大实际应用。(3)推广应用。将手写数字的智能化识别方法推广到其他识别问题中,如对英文字母、拼音、汉字的识别,从而实现对所有字符的智能化识别。
