一种用于垃圾评论分类的融合主题信息的生成对抗网络模型
2021-11-22徐闽樟陈羽中
徐闽樟,陈羽中
1(福州大学 数学与计算机科学学院,福州 350116)
2(福建省网络计算与智能信息处理重点实验室,福州 350116)
1 引 言
在快速发展的信息时代,网络中充斥着海量的信息,但它们并不一定都是出于正确的目的或者能够提供有效的服务,特别在电商领域,网络平台上的评论在很大程度上影响了消费者的消费观.在利益的驱动下,许多投机者在网络中发布大量的垃圾评论,文中的垃圾评论是指网络平台中传播的没有参考价值的无效评论.针对这种广泛的不良现象,如何准确高效的识别垃圾评论成为一个亟待解决的问题.
商品垃圾评论首先由Jindal等人[1]提出,并将垃圾评论分为3类:1)欺骗性评论,指故意提升或诋毁商品声誉和口碑的不真实评论;2)不相关评论,指评论的对象并非针对商品本身,而是与商品无关的品牌、商铺等;3)非评论信息,即广告、聊天等.在这3类中欺骗性评论难以人工识别,因为一个垃圾评论发布者若是刻意伪装掩饰自己的真实意图,使其发布的评论与正常用户发布的评论并无太大差别,那么即使是人工识别也很难奏效.当前针对垃圾评论的识别方法主要分为两种[2]:基于评论文本分析的垃圾评论识别与基于用户行为特征的垃圾评论识别.
基于用户行为特征的垃圾评论识别的研究对象扩大到用户,通过对用户的评论发布行为进行特征提取和建模进行垃圾评论识别.这里用户可以是个体用户也可以是用户群体,基于个体用户行为的垃圾评论识别方法主要有反常行为侦测,或构建用户、商品和评论之间的关系图来建模迭代运算来进行识别等,基于用户群体的垃圾评论识别方法主要有通过对垃圾评论发布者之间的关系进行群组特征提取或者是聚类等来进行群体垃圾评论发布者识别.这些方法一方面或多或少都需要进行特征工程处理,特征选择费时费力,也使得模型的迁移较为困难,要求较高,另一方面用户与评论的关系并不绝对,容易产生噪声,使得模型训练不稳定.
基于评论文本分析的垃圾评论识别的观点是虽然垃圾评论发布者会尽可能的伪装、掩饰自己的真实意图,但一定程度上在语言的细节上仍然会暴露破绽,它侧重于对文本特征的挖掘和组合.在传统机器学习方法中,基于评论文本分析的垃圾评论识别方法的主要思路是通过特征工程,对评论文本进行特征选择,对这些评论特征建立模型,进而训练分类,主要用到的模型有贝叶斯分类、支持向量机、决策树等传统模型.基于评论文本分析的传统垃圾评论识别方法相对于基于用户行为特征的传统垃圾评论识别方法,它的特征工程难度更高,特征选择更为困难,且难以获取评论深层语义信息,分类效果差强人意,泛化能力较弱.近年来,随着深度学习的发展,通过卷积神经网络或循环神经网络对评论文本深层次编码,对评论文本自动进行特征提取,将评论信息映射到高维空间,从而建立垃圾评论分类模型,较好解决了传统机器学习方法所面临的主要问题.但是,深度学习方法依赖大规模数据集,而垃圾评论的人工识别成本高昂,标记样本数量有限,在深度学习训练中容易发生过拟合,且正负样本非常不均匀,模型训练不稳定;另外评论文本本身并不存在垃圾与否的属性,而是这个评论出现在当前的主题是否合适,能不能有效的为消费者提供帮助是定义评论是否为垃圾评论的重要参考,其中的主题可以是商品或服务,因此在不考虑评论出现的主题信息,仅关注评论文本的情况下,容易使模型出现过拟合,泛化能力较弱,影响分类效果.
综上所述,针对现有方法存在的问题,本文提出融合主题信息的生成对抗网络模型Topic-SpamGAN模型,使用对抗神经网络能够有效解决标记数据集匮乏的问题,避免在大规模的深度学习训练中由于缺乏标记数据和正负样本不平衡导致的过拟合等问题,利用强化学习解决文本生成中生成对抗神经网络的梯度不连续问题;此外引入主题信息,一方面主题信息能够强调评论所处环境,帮助生成器拟合真实样本,提高生成器生成的评论样本的质量,另一方面引入主题特征显式强化了分类器的评论主题学习,主题特征作为分类的重要参考,引导分类器在主题情景下进行学习分类,提高分类器的识别效率和准确度,解决;另外,本文通过优化鉴别器和分类器的结构,提高模型对于文本的信息挖掘能力,进一步加强文本特征提取能力,从而提高模型的性能.
2 相关工作
本文基于评论文本分析的垃圾评论方法根据模型划分为传统学习方法和深度学习方法,根据训练样本组成划分为监督学习和半监督学习.
在传统监督学习方法方面,Jindal等人首先通过2-grams来判断两个评论的相似度,再使用逻辑斯特回归对垃圾评论进行分类;Ahmed等人[3]使用N-gram建立统计模型,使用贝叶斯分类器和支持向量机进行分类,何珑等人[4]提出使用随机森林模型,针对数据集中的样本不平衡问题,对样本中的大、小类有放回的重复抽取同样数量样本或者给大、小类总体样本赋予同样的权重以建立随机森林模型来垃圾评论识别;Xu等人[5]提出一个集成了依存句法树等高级语言特征的模型,分类器采用支持向量机,在多语言垃圾评论识别场景中取得不错的效果;金相宏等人[6]提出LDA主题-情感分析模型,首先利用LDA主题模型过滤出内容型垃圾评论,然后结合情感分析识别出欺骗型垃圾评论.这些方法作为经典算法,都能够取得不错的识别率,此外引入主题模型,直接对评论进行内容筛选,虽然能够在一定程度上提高分类效率,但对主题信息的利用过于低效,没有充分挖掘主题和评论的联系.另外这些方法均需要进行特征工程,而不同领域的评论特征空间也有差异,因此这些方法往往在特定领域才能够取得效果,泛化能力有限.
在深度学习监督学习方法方面,卷积神经网络与循环神经网络被广泛运用在垃圾评论识别中.Li L等人[7]使用卷积神经网络在文档级别上做语义表示进行垃圾评论分类,通过在CNN中加入注意力机制,使用KL散度作为权重计算,先计算句中每一个词的重要性,再进一步得到评论句的重要性权重,与评论句向量加权后组合为文档向量用于分类;Siwei Lai[8]等人引入递归卷积神经网络来进行垃圾评论识别,在网络学习单词表示时,通过应用递归结构来尽可能地捕获上下文信息,另外还采用一个最大缓冲层,该层可以自动判断哪些单词在文本分类中起关键作用,以捕获文本中的关键成分;Y.Ren[9]等人使用卷积神经网络并结合循环神经网络建立模型识别垃圾评论,其中使用卷积神经网络来学习评论句表示,然后使用带有注意机制的门控递归神经网络对其进行组合,以对话语信息进行建模并生成文档向量.最后,文档表示形式将直接用于垃圾评论识别;原福永等人[10]则提出融入注意力机制的卷积神经网络构建特征提取模型,在使用评论本身的特征外,还引入用户和商品的特征,首先,使用融入全局-局部注意力机制的卷积神经网络构建评论特征提取模型;其次,分别使用神经网络及卷积神经网络构建评论者及商品特征提取模型;最后,将3个特征模型融合,构成垃圾评论检测模型;Yuan C等人[11]则提出利用张量分解与注意力机制的结合,通过设计多层次单元和融合注意力单元来获取用户和产品层次的语义表示,将评论和产品关系联合起来检测虚假信息.在深度学习框架下,模型能够适应更多的领域和商品,从而取得不错的效果,但是注意到神经网络对于标记数据的需求更为关键,且数量要求较高,受限于人工标记的高成本,人们开始更多的考虑半监督学习策略.
针对深度学习的样本要求,许多研究工作开始采用半监督学习策略.对于垃圾评论分类领域,不同于情感分析等其他文本分类场景中的文本生成,由于评论文本的词项与垃圾属性不存在直接联系,不能直接帮助垃圾评论的分类,这就要求在垃圾评论识别的文本生成中不能仅仅局限于生成词项与垃圾类别标记的关联,也意味着直接使用数据样本并不能很好的指导垃圾识别中的文本生成,此外,由于标记数据集的限制,文本生成训练中拟合的样本分布也相应的受到限制,影响泛化能力.于是图像处理领域成熟的生成对抗神经网络逐渐进入视野,生成对抗神经网络的生成器参数更新不是直接来自数据样本,而是来自鉴别器的反向传播,基于鉴别器提供的自适应损失能够指导生成器的生成目标由词项关联类别标记转移到使文本整体更为符合类别标记上,提高生成器的健壮性,生成效果更好,此外生成器可以分布空间中任意取样,并不仅仅局限于标记数据集,由鉴别器提供损失更新参数来拟合样本空间,提高泛化能力.Lantao Yu等人[12]提出的SeqGAN使用Seq2Seq框架实现评论样本的自动生成,并在之后由Yi-Lin Tuan等人[13]提出的StepGAN,William Fedus等人[14]提出的MaskGAN以及Nie W等人[15]提出的RelGAN进一步提高了评论样本生成的准确性,随后Stanton G等人[16]提出SpamGAN将GAN引入垃圾评论识别,将小部分的标记数据用于GAN的样本生成,利用GAN生成的大量标记数据来满足分类神经网络的庞大样本需求,取得相当不错的成果.
综上所述,传统监督学习方法在垃圾评论识别领域逐渐出现性能不足,泛化能力弱的情况下,深度学习的蓬勃发展给垃圾评论识别带来瞩目的成果,但是标记数据获取成本高昂,标记数据稀少成为深度学习方法垃圾评论识别中更为紧迫的问题,本文通过引入GAN,利用深度学习方法解决标记数据稀少的问题,具有更多的优化空间,分类性能也随着标记数据的增加得到明显提高;另外为了避免仅针对评论文本进行分类学习,本文引入主题,并充分利用深度神经网络的特点,深入挖掘评论与主题的联系,引导分类器基于主题信息对评论进行分类,提高分类效果.
3 Topic-SpamGAN
本节主要介绍Topic-SpamGAN模型框架,包括生成器、鉴别器和分类器3个主要模块.
3.1 问题描述
本文垃圾评论分类主要聚焦于常见的电商平台评论.在评论数据集中随机抽取评论文本和相应主题文本,通过分类模型的分类识别,输出一个二类标签,标识该评论是否为垃圾评论.以下给出相关的符号标记.
本文使用SL来表示已标记数据集,SU表示未标记数据集,用来提高对抗网络中的生成器的性能.模型最终使用S=SL∪SU进行训练.对于数据集S中的每一个训练评论句r1:N={r1,r2,…,rn,…,rN,}都是包含N个词项的序列,其中rn∈R表示在此训练句中的第n个词项,而R则表示词项集合.另外模型使用主题信息来进一步获取评论样本信息以及提升分类性能,每一个评论样本的主题t1:M={t1,t2,…,tm,…,tM,}同样都是包含M个词项的序列,其中tm∈T表示在此主题中的第m个词项,而T则表示是所有使用的主题词的集合.对于数据集中所有的已标记评论样本rL,同样会有类别标签标记每一个评论样本,本文将类别分为两类:c∈:{spam,no-spam}.
3.2 模型框架
为了能够在训练中更加有效的运用数据集中的标记评论样本和未标记评论样本,Topic-SpamGAN将分为3部分:生成器 G,鉴别器 D,分类器C,如图1 所示.对于给定的主题句和类别,生成器 G能够学习生成一个新的样本,称之为生成句,且该评论句应该相似于训练数据集中的对应类别的已标记评论句.鉴别器则通过比较真实评论样本与生成评论样本的差别学习判断一个评论样本是否为真实评论句或为生成评论句,同时利用鉴别器的判断来指导生成器生成更加真实的评论样本.通过生成器与鉴别器之间的博弈以提高生成器所生成的评论样本的质量.
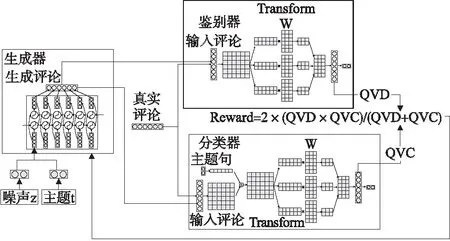
图1 Topic-SpamGAN框架
生成句是由生成器根据给定的主题句与类别标签所生成,因此其对应的主题句与类别标签是已知的,基于SL中的标记评论样本,由生成器根据给定主题句与类别标签,生成标记评论样本对分类器进行训练,从而提高分类器的泛化能力.此外,分类器同样可以指导生成器生成更加符合要求的评论样本,从而使得生成器能够生成更加符合给定的主题句和类别标签的生成句,进一步提高分类的准确性.在生成器与鉴别器相互对抗,生成和鉴别生成句时,生成器与分类器同样在互相促进学习.在对Topic-SpamGAN的3个主要模块进行预训练后,再进行联合训练,此时生成器能够生成与训练集非常相似的评论样本,分类器通过对大量的标记评论样本进行特征学习,从而能够正确识别垃圾评论与正常评论.
3.3 生成器
首先假设PR(y1:N,t,c)是从真实训练集中采样得到的评论样本r1:N、主题t∈T和类别标签c∈C的真实联合分布,那么生成器的目标就是寻找一个参数化的条件分布(r1:N|t,c,z,θg),且该条件分布应尽可能接近真实联合分布.生成句由生成器网络中的参数θg、随机噪声z、类别标签c和主题信息t共同控制生成,其中随机噪声z从随机分布Pz中采样获得,类别标签c从随机分布Pc中采样获得,主题信息t由主题句t1:M经过主题编码器获得.其中对于类别标签c采样得0(c为0表示样本为垃圾评论,反之c为1则表示样本为非垃圾评论)的随机样本噪声z取为-z,类别标签c采样为1则仍为z,以此保证生成器能更加有效获知类别差异.最后由z与t拼接构成输入向量.这个输入向量将会在生成评论样本时,作为每个时间步的输入,保证在每个时间步的生成都能准确获知类别标签信息和主题信息,本文将网络对评论样本的每一个词项生成或每一个词项向量处理的过程为一个时间步.
(rn|rt-1,t,c,z,θg)
(1)
在预训练阶段,首先从数据集S中批采样真实评论样本,并通过最小化在每个时间步上的条件交叉熵进行训练.具体来说,对于从SU中随机采样的样本,为这些样本从类别标签随机分布中随机采样标记类别标签,这些样本与从SL中随机采样的样本一同作为训练样本,最小化如下的损失函数:
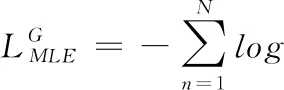
(2)
其中t为主题句,c为类别标签,z为随机噪声,θg为生成器参数.
在对抗训练阶段,Topic-SpamGAN模型将生成器的评论句序列生成过程视为序列的决策问题,将生成器作为强化学习中的智能体,生成器在评论样本生成的每一个时间步上都在做决策,通过策略梯度算法,训练生成器去最大化期望奖励,这些奖励由鉴别器与分类器在已生成的评论样本上进行评估而共同提供(详见3.4).生成器的主要结构是由带有门控循环单元的双向多层循环神经网络单元作为基础神经元,以提供双向解码和选择记忆能力.
3.4 鉴别器
鉴别器D用于检测一个评论样本是真实的(采样于S)还是生成的(由生成器G生成),它具有参数θd,通过计算一个评论样本的真实度得分(r1:N|θd),进而判断这个评论样本是否为真实的评论样本.鉴别器会在评论样本的每个时间步上都进行计算真实度得分QD(r1:n-1,rn),随后平均所有时间步的真实度得分得到评论样本总体真实度得分.
(3)
QD(r1:n-1,rn)是仅在时间步n处的真实度得分,它仅仅依赖于评论文本的前n-1个词项部分r1:n-1.之所以这样设置,是因为鉴别器D是Topic-SpamGAN中的重要部分,Topic-SpamGAN将评论部分词项r1:n-1视为生成器 G 也即强化学习中的智能体现在所处的评论样本生成状态s,将词项rn视为智能体所做出的评论样本生成动作a,而QD(r1:n-1,rn)则为估计值.这样就能够不用蒙特卡洛搜索获得估计值,节省计算开销.
在训练阶段,首先会从数据集S以及生成器G分别批量采样相同数量的评论样本,显然,可以得知采样评论样本的真实与生成类别标签,随后分别计算每个评论样本真实度得分(r1:N|θd),此时和训练其他GAN一样,通过最大化在真实评论样本上的真实度得分,最小化在生成评论样本上的真实度得分.最后即可最小化损失LD.
LD=LDR+LDG
(4)
其中:
LDR=r1:N~PR-[log(r1:N|θd)]
(5)
LDG=r1:N~-[log(1-(r1:N|θd))]
(6)
此外,由于Topic-SpamGAN采用强化学习算法,因此在鉴别器中包含一个评价器Dcritic,用于强化学习的训练.评价器同样在每一个时间步上进行真实度得分的估计,对于基于评论部分词项r1:n-1的下一个词项rn,评价器Dcritic将会根据鉴别器计算出一个基准得分VD(r1:n-1),使得QD(r1:n-1,rn)能够尽可能逼近该基准得分.基准得分VD(r1:n-1)将会用于鉴别器的对抗训练,使得策略梯度的更新更加稳定.
VD(r1:n-1)=rn[QD(r1:n-1,rn)]
(7)
评价器Dcritic的损失函数为QD(r1:n-1,rn)和VD(r1:n-1)间的均方差,如下所示:
(8)
对于鉴别器,Topic-SpamGAN采用Transformer作为主要网络结构,相比于循环神经网络,Transformer结构能够更加有效的捕捉文本中的信息;另外为了更好地表示文本位置信息,对输入加入位置信息编码;通过掩码计算评论样本在每个时间步上的真实相似度得分QD(r1:n-1,rn)等,之后使用二元分类Dense层判断该评论样本是否为真实评论样本.对于评价器Dcritic,Topic-SpamGAN采用在Transformer结构后额外增加一个Dense层用于评估计算VD(r1:n-1).
3.5 分类器
给定一个评论样本r1:N和其主题句t1:M,分类器C将会判定该句是否为垃圾评论,并对比其真实类别标签,调整分类器C的参数集θc进行训练学习.首先,对给定的评论样本r1:N和其主题句t1:M进行处理,评论样本r1:N通过词编码器得到训练句词向量序列,主题句通过主题编码器获得主题句词向量序列,Topic-SpamGAN使用注意力机制获得训练句词向量序列和主题句的注意力序列,拼接到句向量序列后,作为输入向量序列.与鉴别器类似,分类器C同样会在序列的每一个时间步上根据评论部分词项r1:n来得出一个预测分值QC(r1:n-1,rn,t,c),该分值将用于判定该训练句是否属于类别c.将这些时间步上的平均分值作为总体分值.
(9)
分类器C的损失LC分为两个部分:LCR与LCG.LCR是分类器在真实的已标记样本上进行预测分类分值的交叉熵;LCG是分类器在由生成器生成的生成句上进行预测分类分值的损失.生成句在这里被视为具有潜在噪声的训练样本,因此它的损失不仅包含交叉熵损失,还包含香农信息熵H((c|r1:N,θc)).
LC=LCR+LCG
(10)
LCR=(r1:N,c,t)~PR-[log(c|r1:N,θc,t)]
(11)
LCG=c~Pc,r1:N~-[log(c|r1:N,θc,t)+αHC]
(12)
其中
HC=H((c|r1:N,θc,t))
(13)
在LCG中α是一个平衡参数,用于平衡香农熵的影响.加入香农熵能够增加分类器在分类时的确信度,这对于提高生成器在生成给定类别的评论样本时的性能很重要.
类似于鉴别器,分类器中同样包含一个评价器Ccritic用于计算估计在每个时间步rn上基于评论部分词项r1:n-1的基准得分VC(r1:n-1,c),使得QC(r1:n-1,rn,c)能够尽可能逼近这个基准得分,公式如下所示:
VC(r1:n-1,t,c)=rn[QC(r1:n-1,rn,t,c)]
(14)
同样,评价器Ccritic的训练损失LCcritic设置为QC(r1:n-1,rn,t,c)和VC(r1:n-1,t,c)之间的均方差,公式如下所示:
(15)
分类器的实现采用Transformer结构,输入的评论句与主题句的注意力序列通过一个Transformer结构获得,与评论句拼接后作为分类预测输入向量,分类预测的主体结构同样是一个Transformer结构,输出是一个二元分类Dense层用来预测类别标签的概率分布.分类器的评价器与鉴别器的评价器类似,在分类器的Transformer结构之后额外加一层Dense层用于在每一个时间步上计算估计VC(r1:n-1,t,c).
3.6 强化学习
Topic-SpamGAN采用强化学习策略对生成器进行训练,将生成器的生成句的生成视为序列决策过程,生成器则作为强化学习中的智能体或者行为者,将已生成的词项序列r1:n-1视为智能体当前所处的状态,所要生成的下一个词项rn即为智能体所采取的行为,而智能体采取的这个行为是基于策略函数(rn|r1:n-1,t,c,z,θg)进行选择,策略函数通过计算各行为的期望奖励,给出各行为的概率,智能体依据概率选择相应的行为,一方面保证总体获得的奖励较高,另一方面能够提高生成器的样本多元性,避免生成器出现过拟合.在给定类别标签c和主题句t后,生成器生成的评论样本r1:N所获得的奖励将由鉴别器和分类器共同确定提供.具体来说,Topic-SpamGAN将式(3)中的(r1:N|θd)和式(9)中的(r1:N,c|θc)进行组合,整个评论样本的奖励如下:
(16)
生成器智能体将会学习去最大化期望奖励,即:
LG=r1:N~[R(r1:N)]
(17)
为了最大化LG,生成器通过梯度策略算法一步步学习调整自己的参数θg.具体来说,生成器智能体在每一个时间步都需要考虑最大化期望奖励,Topic-SpamGAN设置优势函数为Q(r1:n,t,c)-V(r1:n-1,t,c),这样可以有效减少方差,公式如下:
(18)
(19)
另外增加一个参数β=N-n使得在更新生成器的参数θg时提高初始生成的词项的重要性,β是一个线性递减的参数,它能够帮助生成器在初始生成阶段更加大胆的生成词项.在对抗训练时,生成器的参数梯度更新为:
∇θOlogG(rn|rn-1,t,c,z,θg)
(20)
3.7 训练策略

第2个训练阶段是对抗训练阶段,是主要的算法部分.在对抗训练中,首先训练生成器,保持鉴别器和分类器的参数不变,给定从Pc中采样的类别标签c,生成器G根据类别标签c和主题句t批量产生生成句样本,随后利用鉴别器和分类器在每个时间步上计算Q(r1:n,t,c)公式(18)和V(r1:n-1,t,c)公式(19),进行生成器的策略梯度的参数更新公式(20).为使生成器在强化学习训练中依然保持所生成评论样本的稳定性,本文在对抗训练中会继续使用真实样本S对生成器进行最大似然估计训练公式(2).接着保持生成器不变,从SL和SU中采样真实评论样本,在生成器中采样生成句用于训练鉴别器公式(4),同时对鉴别器的评价器进行训练公式(8).同理对分类器公式(10)和分类器的评价器公式(15)进行训练.
4 实 验
4.1 评价指标
实验使用分类准确率和F1分值作为度量标准,分类准确率公式如下:
(21)
其中,ncorrect表示模型预测正确的文本总数,npredict表示模型预测的文本总数.
F1分值公式如下:
(22)
其中Precision为分类准确率,Recall为分类召回率.
4.2 数据集
本文使用的标记数据集是旅馆评价数据集[17],该数据集共1600条标记评论,包含在芝加哥旅馆的800条非垃圾评论,以及在亚马逊上的800条垃圾评论.另外使用从TripAdvisor数据集中随机抽取的13400条芝加哥旅馆无标记评论.所有的评论文本将全部转换为小写,并分词到单词层次,设置词典大小为10000,均为语料中单词,出现频次前10000的单词.评论的最大长度N设置为120个单词,接近整个数据集的评论样本长度的中位数.数据集主题均为旅馆评论,故设置评论主题句为旅馆.
在词典D中还包含特殊字符用于训练,
4.3 参数设置及基准算法
在Topic-SpamGAN中,生成器、鉴别器和分类器分别拥有独立的词编码器,保证在不同的应用场景下,词向量空间能够灵活适应,所有的词编码器维度均为128.
生成器由2个GRU层组成,每层GRU具有1024个神经单元,最后一层Dense层输出10000个单词的概率,用于生成句的生成.
鉴别器的Transformer结构由2个多头注意力块结构组成,每个多头注意力块包含8个注意力头、512个单元,之后一层二元分类Dense层输出类别标签概率,以及评价器的一层Dense层进行估计计算.
分类器中用于融合评论句与主题句的Transformer结构由2个多头注意力块结构组成,每个多头注意力块包含8个注意力头、128个单元,分类预测的主体Transformer结构由8个多头注意力块结构组成,每个多头注意力块包含8个注意力头、512个单元,之后一层二元分类Dense层输出类别标签概率,以及评价器的一层Dense层进行估计计算.
生成器、鉴别器和分类器全部使用ADAM优化器训练,对于生成器,在进行最大似然估计训练时优化器设置学习率为0.001,权重衰减为5e-3;在进行强化学习训练时优化器设置学习率为0.001,权重衰减为1e-7.梯度截取均设置为最大全局范数5.对于鉴别器及分类器,优化器设置学习率均为0.0001,权重衰减均为1e-4,与各自评价器优化器设置相同.设置香农熵平衡参数α为1.0.Topic-SpamGAN在单块Tesla V100 GPU上训练用时约3小时.
本文将标记数据集按照70%训练集,10%验证集,20%测试集划分.本文选取的对比算法包括:传统贝叶斯分类方法[18],两种使用循环神经网络的监督学习方法,即RCNN[19]和DRI-RCNN[20],2种半监督学习方法,包括使用贝叶斯分类器的Co-Training[21]和使用贝叶斯分类器的PU Learning[22].
4.4 实验结果分析
在实验中,本文除验证不同模型之间的性能差距外,对于Topic-SpamGAN的性能提升,本文做了3个方面的比较:1)从Topic-Spam中去除主题部分,以验证引入主题对分类性能的影响.2)验证在给予分类器对生成句进行分类得到的分类损失不同的权值情况下的性能表现,一方面可以从侧面验证生成器的性能提升表现,另一方面则验证生成器对于分类器的性能影响.3)最后验证鉴别器和生成器在采用Transformer结构后,相比于采用GRU的性能提升.
4.4.1 不同模型的性能比较
表1展示了不同的模型在测试集上的性能表现.从表1可以看出,本文提出的Topic-SpamGAN在精确率和F1分值都表现较为突出,在所对比的各模型中取得最高的精确度88.4%和F1分值0.882.从表1的从实验结果还可以发现,深度学习方法普遍要优于传统学习方法,如DRI-RCNN的准确率达到84.6%,SpamGAN的准确率达到85.6%,Topic-SpamGAN则达到了88.4%,相对于Base Classifier的准确率82.7%提升明显,说明在垃圾评论识别领域,深度学习方法能够有效提高识别准确度,无论是卷积神经网络,还是循环神经网络,都能够很好的提取评论文本特征,获取评论的深层隐含信息,有效进行垃圾评论识别.原因在于深度学习网络通过对文本信息进行大规模的编码,将文本隐含的信息映射到庞大的向量空间,再在向量空间中对文本进行建模,寻找文本和类别标记之间的联系,在经过不断地学习调整后,使得模型能够更准确的识别垃圾评论.
此外,在对比的深度学习模型中,RCN的性能表现较差,准确率只有82.5%,F1分值只有0.833.RCNN使用两个循环神经网络对文本中的每个单词上下文进行双向编码,得到两个上下文向量,包含当前单词的上下文信息,再将这两个上下文向量分别拼接到单词向量的两头组成完整的卷积向量,通过卷积和池化后,使用激活函数获得概率进行分类.由于RCNN仅通过双向循环神经网络获取文本上下文信息,并没有考虑评论的主题信息,同时由于训练集规模的限制容易发生过拟合.而DRI-RCNN对RCNN进行了优化,其卷积向量由6部分组成,第1部分和第2部分是当前单词分别对在垃圾评论和非垃圾评论训练而得的向量,第3部分和第4部分是左边单词分别在垃圾评论和非垃圾评论上训练而得的上下文向量,第5部分和第6部分则是右边单词分别在垃圾评论和非垃圾评论上训练而得的上下文向量,可以发现在DRI-RCNN的卷积向量中包含更多的额外信息,包括左右单词在不同类别的评论样本中的向量,而不单单是当前单词的上下文信息,因此DRI-RCNN获得了优于RCNN的性能表现.
在半监督学习方法中,GAN在垃圾评论识别领域也取得了更加具有竞争力的表现.为使对比更具客观性,采用SpamGAN利用50%的未标记数据集样本下的实验结果,以保证未标记数据集大小与本文采用的未标记数据集大小相符.从表1可以发现,SpamGAN的准确率达到85.6%,相比于Co-Train的准确率77.4%以及PU Learning的准确率84.3%,都有了大幅提高,说明GAN通过大量的未标记数据来学习评论句生成,利用强化学习来拟合标记数据,能够取得较好的效果.

表1 不同模型的精度和F1分值结果对比表
4.4.2 主题引入的影响
为验证在模型中引入主题信息的有效性,本节去除Topic-SpamGAN模型的主题部分,在生成器与分类器中不使用主题编码器,比较其与完整的Topic-SpamGAN模型的性能差异,结果如表2所示.从表2可以发现,通过引入主题信息确实能够提升模型性能,准确度提升0.4%,F1分值提升0.008.一方面,在生成器中引入主题信息能够帮助生成器发现评论的主题特征,并主动学习,而非垃圾评论与垃圾评论往往在主题信息上有较大差异,通过大量的训练,生成器在逐渐发现非垃圾评论和垃圾评论在主题信息上的差异的基础上,开始学习拟合真实评论,从而得到质量更高的生成标记样本,为分类学习提供更具真实性的学习样本.另一方面,在分类器中引入主题信息,可为分类器提供更多的分类特征,而且这些分类特征在不同的分类样本中差异明显,具有较高的区分度,通过在分类器中引入主题信息,可帮助分类器学习更加有效的分类特征.

表2 主题对Topic-SpamGAN的性能影响
4.4.3 生成器样本的影响
本节通过实验分析生成器生成的样本质量以及生成样本对于分类器的性能的影响,了解基于GAN的半监督学习方法对识别垃圾评论的作用.具体来说,在分类器中为对生成样本进行分类的交叉熵损失添加权值G_class,该权值决定生成样本在分类器进行学习调整时对分类器的影响程度.实验中设置G_class为[0,0.5,0.7,1.0],从小到大依次表示生成样本对分类器学习的影响程度.表3给出了不同的G_class下分类器的性能表现.随着权值G_class的逐渐增大,模型的性能也在逐渐提升,准确率提升幅度达到2.2%,F1分值提升幅度达到0.013,性能提升较为明显.以上实验结果表明,通过GAN产生生成样本,将生成样本与真实样本一同训练分类器的半监督学习方法是可行且有效的.此外,从准确度来看,G_class从0-0.5的性能提升是最大的,准确度提高1.6%,占总体准确率提升幅度的72.7%.在G_class为0时,由于对生成样本分类的交叉熵损失被完全丢弃,分类器仅能够获得真实样本的交叉熵损失,所以可以认为生成器完全没有参与分类器的学习,当G_class为0.5时,虽然对生成样本分类的交叉熵损失仅剩余一半,但对分类器的准确率提升幅度的贡献度达到72.7%,说明在分类器得到生成样本的交叉熵损失后,通过对生成样本的学习,有效提升了自身的分类能力.原因一方面在于拥有大量的额外训练样本后,分类器通过对更加广泛的文本进行训练,在一定程度上能够有效避免模型的过拟合,提高模型的泛化能力;另一方面是由于生成样本的质量足够优秀,生成器对于真实样本的拟合程度足够高,提供给分类器的生成样本也就更加接近真实样本的分布,分类器在足够真实的生成样本上进行训练学习,性能由此得到提升.

表3 分类器中生成器损失权值对模型性能影响
4.4.4 结构不同的影响
本文通过实验验证了鉴别器和分类器在采用不同的结构的情况下,对于模型的性能的影响,主要比较在文本分类问题中最常用的GRU结构和Topic-SpamGAN采用的Transformer结构对性能的影响.对比实验仅比较鉴别器和分类器的主体采用不同结构对性能的影响,附加的主题编码器和评价器的结构则保持不变.表4给出了鉴别器和分类器在采用这两种不同结构下的实验结果.从表4的实验结果可以发现,鉴别器和分类器采用GRU或Transformer,对于模型的性能也有较大影响.相比于采用GRU结构的模型,在采用Transformer时的精确度提升1.6%,F1分值提升0.11,性能提升较明显.GRU虽然能够很好地保存评论句的长短时记忆,但是GRU对文本特征信息的挖掘能力弱于Transformer.由于Transformer的主要单元为多头注意力模块,通过对评论句进行整体切割,分头进行注意力训练,一方面能够较为完整的保存评论句整体信息,避免出现长时记忆,另一方面通过多头的多层编码学习,再最终整合,使得模型对于评论句的信息把握更为深入,其中隐含的关联信息也能够很好的保存,另外,Transformer可对位置信息进行编码训练,避免模型无法学习位置相关的语义信息,因此Transformer在要对文本进行语义表征学习时的性能往往优于GRU.

表4 鉴别器和分类器结构对Topic-SpamGAN的性能影响
5 总 结
本文提出了一种引入主题特征的对抗神经网络垃圾评论分类方法.该方法采用生成对抗神经网络解决了现有的深度学习方法普遍存在的标记样本获取困难,模型易过拟合的问题,充分利用有限的标记数据集,在大量的未标记数据中学习标记样本生成,通过生成器,鉴别器和分类器的对抗学习,不断获得高质量的标记数据,从而使分类器得到高效的训练;其次采用强化学习方法将生成器,鉴别器和分类器进行巧妙的结合,使得分类器参与生成样本的生成,由此提高了生成样本的质量,以满足分类器的训练要求;最后在模型中引入主题,既可以帮助生成器提高生成样本的质量,又能够为分类器提供更具有区分度的分类特征,从而提升分类效果.实验表明,相比于基准方法,本文利用生成对抗神经网络,采用强化学习方法并引入主题特征,有效提高了垃圾评论识别的分类性能.目前对抗神经网络在文本处理领域的逐渐成熟,未来的工作将考虑进一步提升生成器的生成质量,保证对抗学习中的稳定性,以及优化主题引入方式,以提高模型在多主题情景的表现,进一步改善模型.
