基于深度学习的空管语音识别
2021-11-20吴向阳张建伟
吴向阳,王 兵,阮 敏,杨 波,张建伟,林 毅
(1.中国民用航空西南地区管理局,四川 成都 610200;2.四川大学计算机学院,四川 成都 610065)
空中交通管制(air traffic control,ATC)利用通信、导航和监视技术对飞机飞行活动进行干预以保证飞行安全和秩序[1]。管制员基于各种设备感知的空中态势对飞机进行飞行引导,飞行员在整个飞行过程中均需严格按照管制员的要求进行飞行,否则容易造成安全隐患。在整个扇区管制过程中,一个管制员通过无线电频率与多个飞行员进行通话,各方通过PTT(push to talk)信号来控制通话的唯一性,保证通信频率不被堵塞[2]。空中交通管制实时语音包含丰富的实时交通动态,对空管系统处理非常重要。但是,目前空中交通系统仅将记录管制通话语音作为事后处理的依据,并未引入其他相关处理。
语音识别(automatic speech recognition)的主要目的是将语音信号识别为计算机可读文本。语音信号受环境影响较大,如背景噪声、设备干扰、参数采集等,因此,传统语音识别方法是在一定限制的环境条件下获得满意的性能,或者只能应用于某些特定场合。作为提升产品智能化程度的一个标志,语音识别技术大量应用于生活,包括语音搜索、智能家居等。采用语音识别技术将管制通话语音转换为计算机文本对当前空管系统具有重要意义。引入空管语音识别技术可以在指令发布阶段从语音中获取管制动态、丰富系统信息来源。基于语音识别技术,空管系统可以检测管制指令规范性、飞行员复诵一致性,这能降低管制员工作负荷、提升空管运行安全。
初期的语音识别系统基于孤立词(音)进行识别,如1952 年贝尔实验室开发的特定人的数字及英文字母识别系统[3]。考虑到语音识别系统的实用性,后期研究主要集中在连续语音识别上,但是由于说话人习惯、背景噪声不同导致难以区分词边界,且分帧参数也需要验证确定;因此,连续语音识别面临极大的挑战。语音识别方法可分为以下几种。
1)HMM/GMM[4]。20 世纪80 年代,研究人员将隐马尔科夫模型(hidden markov model,HMM)应用到语音识别领域,用于音素建模。每个音素包含多个状态,每个状态用高斯混合模型(Gaussian mixture model,GMM)拟合对应的观测帧,观测帧依据时间顺序将数据组合成观测序列,在此基础上实现语音识别。
2)HMM/DNN[5]。随着神经网络应用的不断扩展,研究人员将神经网络引入到语音识别领域,将DNN(deep neural network)代替GMM 在拟合观测帧中的角色。因为神经网络在函数逼近上有强大能力,所以语音识别效果亦有较大提高。
上述的语音识别框架虽然取得了较好的识别效果,但基于音素的HMM 模型是人为设计模型,依赖于专家知识,且该模型设计较为复杂不易理解,不利于研究人员入门和改进。在此背景下,端到端(end-to-end)识别方法应运而生。
3)End-to-end[6]。End-to-end 语音识别方法是基于全神经网络进行语音识别,直接将输入的语音频谱图与字符标签进行映射,不再对语音数据进行基于上下文(context dependent)的状态转移和对齐(alignment)处理,其技术结构较传统方法更为清晰。该方法依赖于神经网络在特征自提取和表示方面的强大能力,实现对数据分布的描述。
目前,End-to-end 的语音识别算法已在较多公共领域的语音识别中得到应用。本文在分析我国空管语音识别的特殊性(如语速快、中英文混合以及高背景噪声等)基础上,运用深度学习技术研究适用于我国民航管制的端到端语音识别算法。首先将语音信号分帧并转换为频谱图,搭建卷积神经网络(convolutional neural network,CNN)提取频谱图在时间/频率维上的显著性特征,然后设计多层循环神经网络(recurrent neural network,RNN)进行语音数据时序相关性建模,最后通过全连接预测层(fully connected,FC)将抽象特征分类到输出词汇,其中包含汉字和空管专有名词。本文采用的网络结构如图1 所示,使用CTC(connectionist temporal classification)作为损失函数进行误差反向传递。
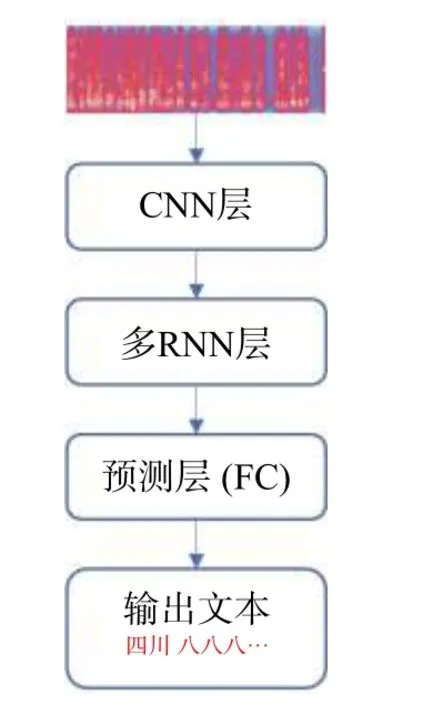
图1 语音识别模型图
1 空管语音特殊性分析
为保证通话双方正常理解和沟通,国际民航组织(International Civil Aviation Organization,ICAO)发布了相关文件以规范管制通话语音的流程与发音[7]。管制通话语音与生活中的语音相比,有以下不同的特征。
1)发音不同。空管通话中发音不同的词汇包含数字、字母以及空管术语等。这使得管制通话语音更像一类方言。表1 列举了一些管制通话特殊发音。针对发音的不同,本文研究并制定了一套与之对应的汉字映射表,所有的字母和地标点都有一个与之对应的词汇,其中的汉字选用生僻字以区分与常用字的发音。例如将地标点“PIKAS”映射为“噼胩咝”。目前这类词汇共有53 个。

表1 管制通话特殊发音
2)语速较快。由于空管过程对时间较为敏感,因此在管制通话过程中管制员和飞行员说话都较快。据目前样本统计,管制通话平均每秒能说5~7 个汉字。针对这一特点,本文在语音分帧的时候采用了比自然语音更小的帧长和帧间偏移量。
3)环境干扰较大。记录仪记录的管制通话语音除了管制室的背景噪声之外,还包括一系列设备造成的噪声,比如VHF 通话传输噪声、采集设备噪声、数字化噪声等。这类噪声对传统的基于HMM 的语音识别方法影响较大[8]。
因此,要想将管制通话语音引入到目前空中交通管制系统,必须要研究适合于我国空管管制通话的语音识别方法。由于基于HMM 语音识别算法在处理语速和噪声上性能不佳,研究基于End-toend 的空管语音识别方法就势在必行。
2 语音识别方法
2.1 频谱图
本文首先将一维语音信号转换为梅尔倒谱(Mel-frequency cepstral coefficients,MFCC),并将其作为模型输入,处理步骤如下。
1)分帧。将语音信号按20 ms 帧长和7 ms 帧间偏移量进行分帧处理。
2)预加重。补偿语音信号受到发音系统所压抑的高频部分,突出高频共振峰。
3)加窗。平滑信号,减弱傅里叶变换以后旁瓣大小以及频谱泄露。
4)梅尔滤波器处理。将语音信号从时域转换到频域并精简信号在频域的幅度值,然后进行取对数处理。
5)倒谱分析。先离散余弦变换(反傅里叶变换的一种),再通过低通滤波器获得低频信号。
6)差分处理。在特征维度增加前后帧信息的维度,常用的是一阶差分和二阶差分。
2.2 模型结构
本文采用的神经网络模块包含CNN、RNN 和FC 层。CNN 用于在时间维上对数据进行特征自提取和维度压缩。同时考虑到RNN 在模型训练时对时序数据记忆困难问题[9],本文采用改进的LSTM(long short-term memory)结构进行语音数据时序建模。FC 将提取的抽象语音特征与词汇表进行映射,并用softmax 作为激活函数以输出标签为某一字符的概率[6]。模型详细结构如图2 所示。

图2 模型详细结构图
CNN 是一种广泛用于计算机视觉领域[10]的神经网络结构,与DNN 相比进行了如下改进。
1)局部感受野(local receptive field):对应着语音频谱的时频相关性。
2)共享权值(shared weights):在局部感受野区域内,共享同样的神经网络权值,降低了参数量和训练难度。
3)卷积操作(convolution):卷积操作具有位移、缩放及其他形式扭曲不变性,降低了CNN 对语音速度和频域分布的依赖程度。
4)池化操作(pooling):针对局部区域提取其显著性特征,降低数据维度以提取有用深层数据特征。CNN 计算过程如式(1)所示。

RNN 是一种广泛用于时序数据建模的神经网络结构,其核心思想是对于每一个时刻s,其输入包含该时刻的输入x(s)以及上一时刻的隐状态h(s-1),输出y(s)依赖于h(s)。RNN 的基本规则如式(2)所示。实际应用中,在对长时记忆方面,RNN 性能表现得不够好,因此,本文采用LSTM 结构来提高模型性能。LSTM 是一种特殊的RNN 结构,设计了1 个保存信息的cell 和3 个控制信息传输的门限信号,即输入门(input gate)、输出门(output gate)和遗忘门(forget gate)。该模块以学习的方式对特定信息进行记忆或丢弃,以此来实现信息的长时传输,并最终提升语音识别的性能。LSTM 单元内部各部分的数学关系如式(3)所示。

式(2)中:w表示不同输入输出之间的权重值;b为权重偏置值。式(3)中:t代表计算时间步;I,F,C,O分别代表LSTM 单元的输入门、遗忘门、cell 和输出门的函数响应值;ht为最终的隐藏单元响应;Wix表示当前输入与输入门之间节点连接的权重;其他权重参数W意义类似;b代表内部各模块的偏置值;⊙代表向量内积操作。
3 实验结果
本文实验数据采集自国内某民航机场,人工将语音数据按管制员和飞行员语音分开,并提供相应的汉字标注。由于空管用语的专业性给数据标注带来了极大困难,截止目前本文研究采用的原始训练样本语音数据(原始数据集)共10 h。其中,训练集、验证集和测试集按90%、5%、5%进行随机分配。本次实验共涉及汉字词汇539 个。模型训练环境的操作系统为Ubuntu16.04,处理器为2×Intel(R) Core(TM) i7-6800K @ 3.4GHz,内 存 为4×16 GB,GPU 为2×NVIDIA GTX1080(2× 8GB 显存)。本文基于开源框架Keras 实现深度学习模型,程序开发语言为Python。实验设计包含以下部分。
1)通过实验验证不同数量的LSTM 层对识别效果的影响。
2)验证数据扩充对识别效果的影响。
3)与传统语音识别方法对比,分析识别性能。
本文分别从识别精度和效率2 方面衡量模型的性能。
1)用WER(word error rate)作为模型精度的评价因子,其定义为通过最少次数的插入(I)、删除(D)和替换(S)词语使识别出来的句子和真实值(truth)完全一样,其计算公式如(4)所示。len 是句子文本字符串的长度。WER 越小,说明模型的识别精度更高。
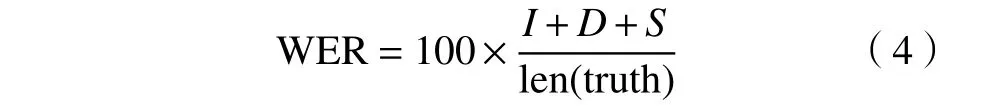
2)用RTF(real-time factor)衡量模型的识别效率,其计算公式如(5)所示。其中Tdur和Tasr分别为语音时长及其识别所需要的时间,单位为s。RTF越小,说明模型的识别速度更快。

由于训练样本的平均帧数为700 左右,通过CNN 维度压缩,本文所有的LSTM 层均设计为360 个隐藏节点。其仿真实验结果如表2 所示。
针对已有训练数据集,在仿真实验过程中,本文做了5 组对比实验,包含3~7 个LSTM 层。表2中对应的WER 为多次实验所得的最好识别结果。对比训练时间是为了衡量增加网络层数对整个模型造成的附加影响,其值并非严格的精确值。由表2 可知,增加LSTM 网络层数可在一定程度内提升语音识别效果,WER 由17.69 %降低到10.60 %。在LSTM 层数从3 增加至5 时,WER 降低5 %左右;从5 增加到7 时,WER 降低2 %左右,且消耗的显存和训练时间增加较多。此外,RTF 随着LSTM 层数的增加而逐渐增大。

表2 神经网络结构验证实验结果
本文对原始训练样本中的部分样本随机进行了加噪和调整语速的处理,以扩充数据集,最终获得了20 h 的训练数据,采用上文中7 个隐藏的LSTM层进行实验,最终得到的WER 为9.49%。
为了进一步证明本文方法的性能,本文基于原始数据集和扩充数据集进行了一组对比实验,对比本文算法与传统的HMM/GMM 和HMM/DNN 模型的识别效果,其结果如表3 所示。

表3 语音识别对比实验结果
从表3 可知,本文方法在识别效果上优于传统的HMM/GMM 和HMM/DNN 方法,但是在原始数据集和扩充数据集上的性能提升有所不同。数据集扩充给End-to-end 方法带来的提升明显比其他2 种方法更高,这印证了训练数据对深度学习模型的重要性。End-to-end 语音识别算法通过不断地自学习以提升模型对数据分布的拟合能力,因此未来在提高数据集的基础上,本文方法在空管语音识别上的性能将更加的优异。此外,由于深度学习模型结构的复杂性,其识别效率较传统方法更低,但是,在当前服务器配置下,其RTF 能够达到<1.0,可以部署到实时应用。
4 结论
本文在分析空管管制语音业务的基础上,借鉴端到端语音识别模型已有的成果,设计了适合我国空管管制通话的语音识别算法。通过与其他传统方法的识别结果比较,发现本文算法识别效果好。此外,本文的端到端方法极大地降低了语音识别技术对专家知识的依赖性,使得语音识别技术能够更加容易的应用到各个领域。在后续工作中,将进一步增加标注训练样本数据量,同时不断调整模型训练时的超参数以改进本文的模型识别结果。
