时空大数据的缺失数据流关联修复仿真
2021-11-18关玉欣李雷孝
关玉欣,李雷孝
(内蒙古工业大学数据科学与应用学院,内蒙古 呼和浩特 010080)
1 引言
大数据中的数据缺失和来源复杂,导致数据易出现错误,给数据处理带来很大的困难。为避免以上问题,提升自身的使用价值,发挥最大作用,需要对缺失数据进行修复[1]。传统修复缺失数据的方法一般可分为两大类:单独修复法和多目标修复法[2]。单独修复法包含人工修复法、均值修复法、回归修复法、冷热平台修复法等等。多目标修复法包括随机回归修复法、趋势得分修复法等。从修复的手段来看,均是采用语义规则和统计学理论实现的。这些方法在隐蔽规则探索方面研究不够透彻,因此还需更加深入分析和研究。对数据的处理在该领域具有很重要的意义,很多相关学者针对数据已经研究出了很多成果。文献[3]提出基于去除噪声自编码网络的缺失大数据修复方法。该方法通过堆叠去除噪声干扰的方法,创建自编码网络以提取监测数据之间的关联关系,以这种关联关系对数据进行训练,建立支持向量模型对缺失大数据进行检测,进而对缺失数据进行修复。文献[4]提出一种基于时空大数据的收缩近邻缺失数据流修复方法。该方法可分为三部分,第一部分是基于提取的数据样本和数据特征变量的缺失比值,将该比值应用于对缺失数据的采样作为入样概率,并通过该概率实现对数据不等概的收缩;第二部分是基于提取数据样本之间的距离,挑选出与缺失数据样本相似的样本组合成样本训练集,最后一部分是创建随机森林模型,并对缺失数据样本进行迭代填补修复。文献[5]提出一种基于全景调整控制统一化数据模型的缺数数据修复方法,该方法针对创建全景数据中存在的低质量数据,运用改进的遗传优化方法对低质量和不完整数据的均值和协方差进行估计,得出最佳参数;再采用Markov Chain Monte Carlo方法根据估计得出的最佳参数进行缺数数据修复。文献[6]提出基于分块填补的缺失数据修复方法。该方法的主要目的是对缺失数据进行分块处理,单运用和待修复数据具有相似性的数据进行填补修复,进而减少无关数据对缺失数据修复造成的影响。
上述相关学者研究出的修复方法,存在修复过程复杂,且经过这些方法修复的数据仍然存在数据漏洞,修复准确度较低。现提出一种基于时空大数据的缺失数据流关联修复方法。经过仿真证明,本文提出的方法能够更准确地计算缺失数据,并在最短的时间内对其进行高效、准确地修复,令修复结果更接近原始的时空大数据的数据流,具有较高的可行性和可信度。
2 时空大数据的缺失数据流修复方法
2.1 数据流之间的关联规则
首先对数据之间的关联规则和条件函数进行设定[7],然后对有效的规则与条件函数依赖相等、规则可信度由置信度决定两方面进行证明。
数据之间的关联规则就是数据处理的核心思想,对其进行设定具体如下:
关联规则可通过以下方式进行表述:设I={I1,I2,…,In}是一个任务集合,T={T1,T2,…,Tm}表示一个事件数据集合,事件数据集合中的任意事件Ti均是单独的任务集合,即Ti⊆I。关联规则的蕴含关系如下:X→Y,其中X⊆I,Y⊆I,且X∩Y=φ。X(或Y)是一个任务的集合,叫做事务集,将X为前件任务,Y为后件任务。当关联规则X→Y存在时,X成立,则Y也会成立。
针对关联规则的条件函数依赖可用于数据处理,在数据库修复上应用广泛[8]。假设数据之间存在一定关系R,a(R)代表设定在这层关系上的属性集,并对每个属性A,满足A⊆a(R),A的取值范围表示为d(A),设定在R上的条件函数依赖φ表示为φ:(R:X→Y,Tp)。
其中:X和Y是设定在a(R)的属性集;{R:X→Y}表示一个标准的函数依赖;Tp是和X与Y相似的模式元素组,设定了相似属性在取值范围方面的约束条件。
证明关联规则和条件函数依赖相等的具体步骤如下:
关联规则R:X→Y可以视为关系模式R的条件函数依赖。
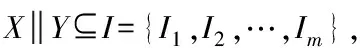
综上所述,进一步对关联规则R:X→Y进行表达
R:X→Y≡[Ai=Ii,Ai+1=Ii+1,…,Ai+n=Ii+n]
→[Aj=Ij,A+1=Ij+1,…,Aj+n=Ij+m]
(1)
关联规则X→Y和条件函数依赖相同的表达式为
φ:[Ai=Ii,Ai+1=Ii+1,…,Ai+n=Ii+n]
→[Aj=Ij,Aj+1=Ij+1,…,Aj+m=Ij+m]
(2)
由此关联规则得以证明:条件依赖取决于关联规则R:X→Y,该规则的挑选原则:R:X→Y具有超高的置信度,同时不会要求过高的支持度。
对上述设定进行证明的具体过程如下
令支持度减小,可发现较多的关联规则,若支持度较高,则发现的关联规则较少;当关联规则R:X→Y转换成条件函数依赖,如式(2),那么本文研究的以数据X修复Y为目的,就需要X和Y同时被发现的概率较高。
X→Y支持度的计算公式如下
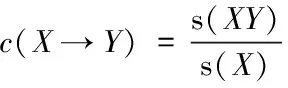
(3)
式中:s(X)为X的支持度,s(XY)为X,Y的支持度,当c(X→Y)过高时,则X和Y同时被发现概率也较高,由此可见上述设定可被验证。
挑选较小的支持度、较高的置信度来提升可信关联规则的数目,由此可搜寻到较多的条件函数依赖。就是依据数据的实际修补需要,运用合理地降低支持度的方法来发现更多的与缺失数据属性相似的关联规则,以此来实现对缺失数据的填补和修复,提升数据的使用性。
2.2 缺失数据填补修复
根据2.1节提到可通过数据之间的属性关联,实现对缺失数据的修复。针对不同时空大数据之间的时间、空间和属性方面的关联性,对时空大数据Si和目标数据对象Sk之间的时空相似度进行计算,计算公式如下
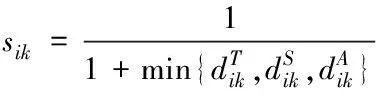
(4)


(5)
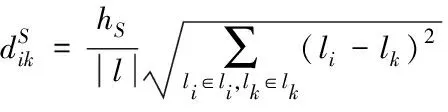
(6)
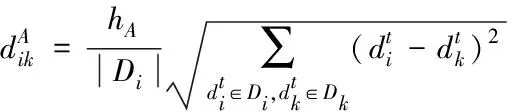
(7)
式中:s代表时空大数据的时间维数,l代表时空大数据的数据流相应位置,|l|代表时空大数据的位置维度,|Di|代表时空大数据属性的邻域维度,hT、hS、hA均代表相应维度的划一因子。时空大数据之间的维度相似程度越大,数据越相似。时空大数据在时间、空间和属性之间的相似度就是数据之间的最佳相似度[9]。
可通过时空大数据之间的相似度,实现对数据在时间、空间和属性的互相弥补,以保留较多的数据临界点,从而缓解时空大数据集中数据流出现连续缺失的情况[10],临界点数据发生缺失而不能被修复的情况。
针对缺失目标对象sr,挑选出一个特定的数据对象sz,将二者之间的相似度结合在一起,对数据sr的加权值进行计算,数据的加权值可实现对缺失数据sr和相应的数据临界点的相似度的结合。数据的加权值计算公式如下
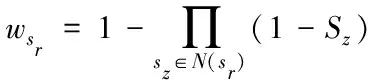
(8)
式中:N(sr)代表目标缺失对象对应的数据临近点集,Sz代表缺失数据sr和特定数据sz之间的相似性。数据加权值wsr的数值过大,说明缺失数据和相应的数据临界点的结合效果越好,可用于修复缺失数据的完整数据越多。
针对一个包括t个缺失对象可能的修复顺序x,列出所有不同的排序,并利用Bayes联合概率对排序的置信度进行计算,Bayes联合概率公式如下

(9)
式中:sN(r)表示用来修复缺失对象sr的数据临界点集。在对修复顺序进行确定之后,后续修读的数据临界点不是固定的,缺失对象的加权值也随之发生变化。p(sr|sN(r))表示用来修复缺数sr的临界值中添加sN(r)后得出的加权值。
当集合sN(r)为空集时,可对p(sr|sN(r))进行简化,变成p(sr),可得出:缺失数据sr的加权值为p(sr)=wsr;当集合sN(r)为非空集合时,结合式(8)可得到
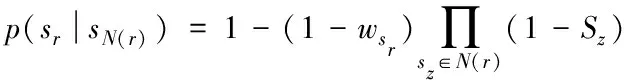
(10)
待修复顺序确定后,对缺失部分进行修复。采用时空大数据相似度结合关联规则修复算法对缺失数据进行修复值msr进行计算,计算公式如下
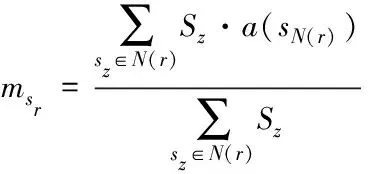
(11)
式中:a(sN(r))代表用于修复缺失目标对象sr的数据临界点集的平均值。
由实验可知,在最短的时间内对缺失数据填补进行高效、准确地修复,修复结果更接近原始的时空大数据的数据流,准确性更高。
3 仿真证明
在计算机上建立实验平台,采用Matlab和C语言作为实验的开发工具,并编写算法程序。实验对象选用STD数据库(Spatial-Temporal Database, 时空数据库)中的数据,并将数据随机分为四组,该数据库专门用来测试数据挖掘技术的公共数据库,数据库中有明确的分类,因此可用来验证本文缺失数据修复的效果。
为了验证本文研究的修复方法的可行性和可信度,将基于时空大数据的收缩近邻缺失数据流修复方法、基于分块填补的缺失数据修复方法和本文所提修复方法进行对比实验,通过根均方值误差C和准确度百分比P(单位:%)作为指标评价三种方法。
根均方值误差(C)的计算公式如下
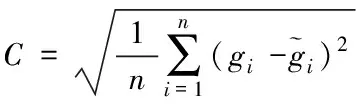
(12)
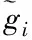
准确度百分比(P)的计算公式如下:
(13)
式中:m表示所有缺失数据中达到准确修复的数据数量,h表示修复数据集中缺失数据的数量。该值越大,修复效果越好。
3.1 实验结果
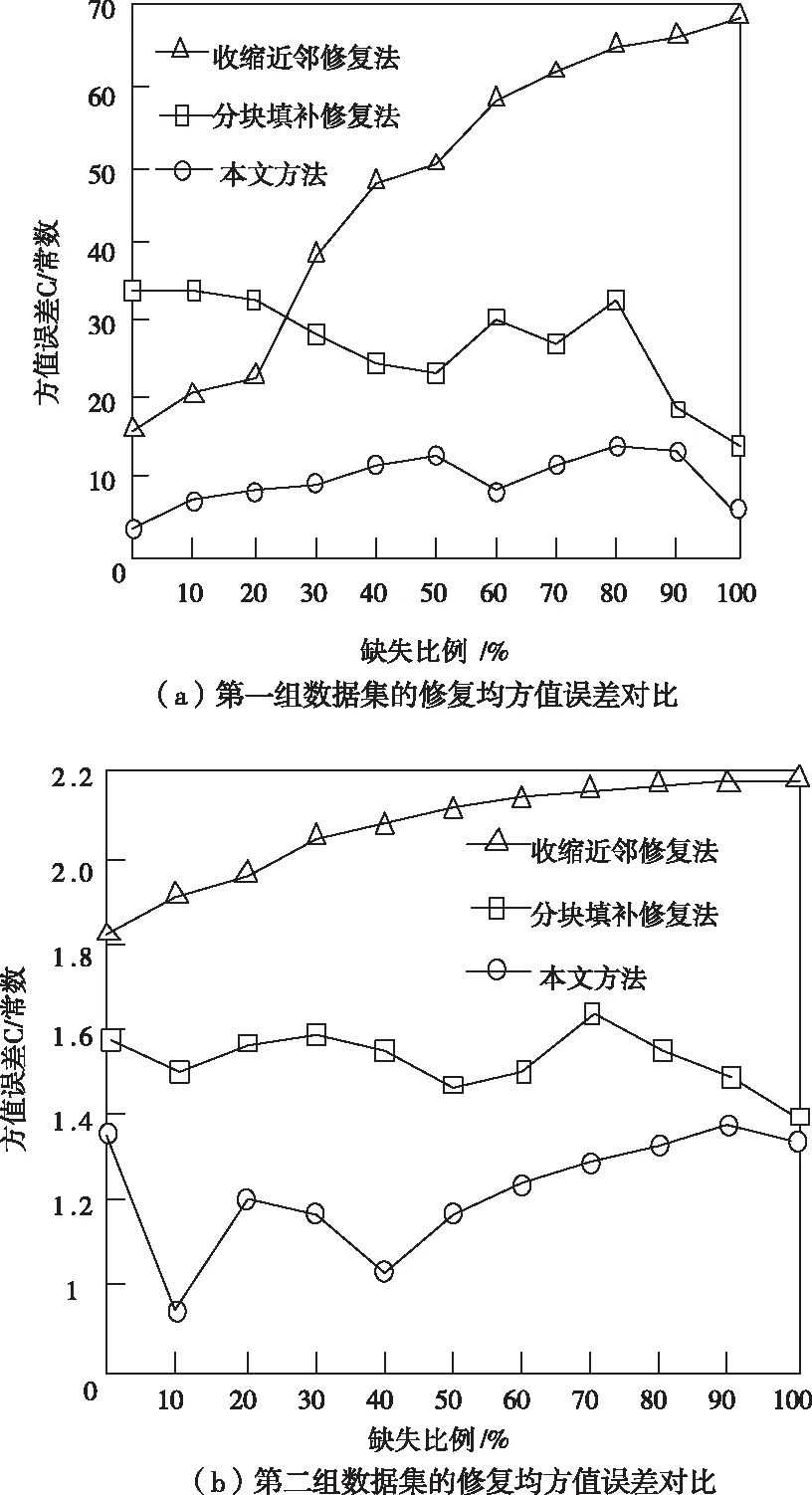

图1 不同方法对数据集修复的均方值误差对比
图1为不同方法对四组数据集修复的均方值误差对比,表1为不同方法对随机抽取一组数据修复的准确度百分比对比。
根据分析上述四组数据修复效果图可知:由图1(a~d)可以看出,基于时空大数据的收缩近邻缺失数据流修复方法在整体上明显高于其它两种方法,由此可说明该方法的修复效果不如其它两种方法的修复效果;对于基于分块填补的缺失数据修复方法,直观来看该方法整体别的变化趋势忽高忽低,状态不平稳。说明该方法的准确性不能保证;而对于本文研究的修复方法,能够准确高效地检测出缺失数据,并加以修复。由图1可以看出,C值均低于其它两种方法,说明本文研究的修复方法具有较高的修复准确性,且具有明显优势。
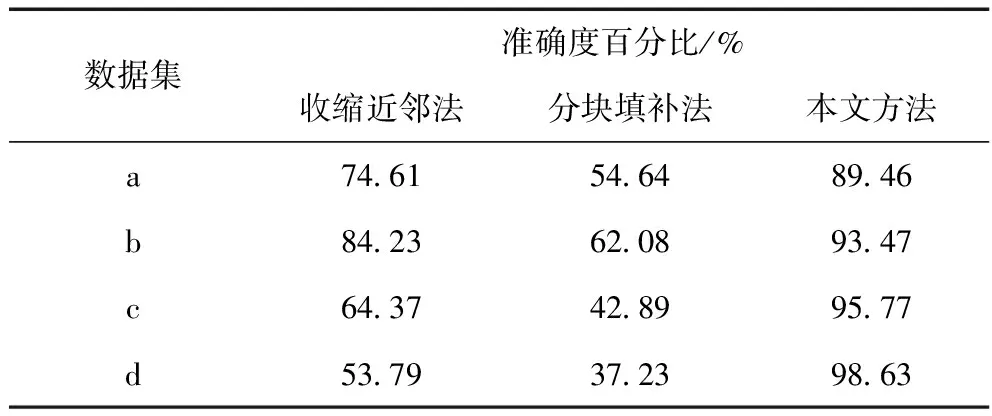
表1 不同方法对数据集修复的准确度百分比对比
分析表1可知:准确度百分比用于衡量方法的准确性,由表1可以看出,分块填补方法的准确度最低,准确度百分比最高值仅为62.08%;收缩近邻法的准确度百分比最低值为53.79%,最高值为84.23%,这两种方法的准确度百分比最高值均低于本文研究方法的准确度百分比最低值,由此说明,本文研究的修复方法具有较高的可信度,且修复效果较好。
4 结束语
为了更好地使数据发挥其最大的作用,提升自身的使用价值,需要对大数据中缺失部分进行修复。针对现有方法存在的不足之处,提出一种针对时空大数据的缺失数据流关联修复方法。利用数据之间的关联特性,结合数据缺失填补方法,对缺数数据流进行缺失修复。并通过仿真证明,本文研究的修复方法能够更准确地计算缺失数据,并在最短的时间内对其进行高效、准确地修复,令修复结果更接近原始的时空大数据的数据流。
