基于贝叶斯网的高维数据隐藏模式挖掘
2021-11-18陈传毅戴卫军
陈传毅,戴卫军
(澳门城市大学,澳门 999078)
1 引言
高维数据就是指多维数据,是一维数据或者能够写成表达式的二维数据,而高维数据同样可以类推,不过在维数较高时,很难直观地表示,因此目前高维数据挖掘是重点研究对象。高维数据挖掘是指在大量的数据内,找出事先未知、隐含的,同时有用知识的一项任务[1]。是计算技术研究中一个非常具有价值的新领域,主要融合了统计学、机器学习、人工智能以及数据库等多个领域的技术以及理论,成为数据库领域以及国际信息的最新研究方向之一,受到工业界以及学术界的广泛关注[2]。
文献[3]采用无线传输技术,对异常数据进行降噪处理,结合FFD技术完成数据互通,根据FIFO挖掘思想,挖掘数据并设计挖掘流程,实现大规模高维数据挖掘算法。该方法的数据挖掘可靠性强。文献[4]运用分段向量量化编码技术,分析云数据空间存储结构,根据闭频繁项集检测方法,信息融合处理云数据并提关联规则特征,结合尺度分解方法,降维处理云数据,采用模糊聚类方法,对云数据进行分类挖掘。该方法数据挖掘的聚类性能较好。当前高维数据隐藏模式挖掘能够利用降维把数据从高维降低至低维,通过增量方法以及并行方法来提升计算性能。而当前高维数据隐藏模式挖掘精度较低,挖掘执行时间较长,且挖掘过程工作量较大,挖掘过程较为复杂,很难满足实际需求。
针对上述问题,本文提出一种基于贝叶斯网的高维数据隐藏模式挖掘方法,通过有向无环图像以及概率表所构成贝叶斯网络,利用信号处理的方法来对数据信息进行特征提取,对子空间降维处理,采用自适应级联滤波完成数据的降噪,将多通道声的传感信息数据完成自适应进行波束构成,聚焦数据,从而完成高维数据的隐藏挖掘。
2 贝叶斯网络理论
贝叶斯网络构成,具体步骤有以下两个部分:
第一步:有向无环图像(DAG),其中所有节点都表示一个数据变量Xi,Pai表示Xi父节点集合。
第二步:另外一个条件的概率表(CPT),在表内所有元素代表数据变量Xi条件的概率密度p(Xi,Pai)。

贝叶斯网络主要是针对概率推理与图理论所建立的模型,此模型具体表示为有向无环图,是利用节点与弧进行构成的,在其中节点表示变量的关系,具体表示为证据或者事件,在两个节点之间,弧表示时间之间的关联性,是作为单项式的,而进行反馈环路并不存在[6]。根据此特性,就能够对父子节点间的关系或者是相连节点之间的互相关联概率进行确认。
贝叶斯网络在应用于条件概率时,假如某些已经发生的证据事件E是针对假设性H的,那么H与E二者则同时具有的概率P(H,E)能够被定义成P(H,E)=P(H)P(E|H)。
具体网络结构的表达节点之间具有条件独立的联系,且存在3种局部构造[7],具体如下所示:
顺连图像:
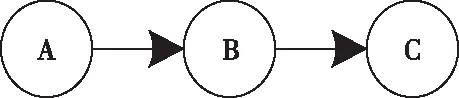
图1 贝叶斯网络顺连结构示意图
具体公式为:
P(A,B,C)=P(C|B)P(B|A)P(A)
(1)
分连图像:

图2 贝叶斯网络分连结构示意图
具体公式为:
P(A,B,C)=P(C|B)P(A|B)P(B)
(2)
汇连图像:

图3 贝叶斯网络汇连结构示意图
具体公式为:
P(A,B,C)=P(B|C,A)P(C)P(A)
(3)
根据乘法定律的交换性质,假如H与E二者相关,则说明E就一定会与H有关系,基于此联合概率代表公式为
P(H,E)=P(H)P(E|H)=P(E)P(H|E)
(4)
所以

(5)
式(5)为叶贝斯公式,依据统计学角度,P(H)表示因假设H所引起的E产生条件概率,被称为H对于E似然估计[8]。证明了H是在真实情况中E所产生的信度。P(H|E)是后验的概率,如:E产生条件中H所出现概率。
贝叶斯网推断的基本步骤是:首先选取一个概率密度的函数π(θ),代表在获取数据前某一个参数θ信念,将其称为先验的分布,对一个模型π(x|θ)进行选取,能够反映出给定参数θ状态中对于x信念,在获取数据X1,X2,…,Xn之后,对信念进行更新,同时计算后验的分布π(θ|X1,X2,…,Xn),在后验分布内获取点的估计与区间的估计。
贝叶斯网络可以提供一种便利的表示因果知识路径,在其网络中,节点是能够作为“输出节点”来对类符号的属性进行表示,且能够同时存在多个输出节点,而对于分类过程所返回类标号的属性分布概率,就可以对所有类概率完成预测[9]。具体主要来源不确定:
1)该方面的领域专家对于自己掌握的知识的不确定性。
2)在建模的领域自身中存在的不确定因素。
3)知识工程师的表示知识、试图翻译而造成的不确定因素。
4)对于知识本身准确性以及所获取的知识方面,所具有不确定的因素。
通过概率方法完成不准确性步骤的推理,具体过程如下:
第一步:将待处理的问题域,进行抽象成一组随机的变量集X=X1,X2,…,Xn。
第二步:将相关此问题的知识,代表成一个联合概率的分布P(X)。
3 高维数据隐藏模式挖掘
3.1 数据挖掘框架分析
基于数据挖掘质量分析的系统框架结构图像,具体如图4所示。
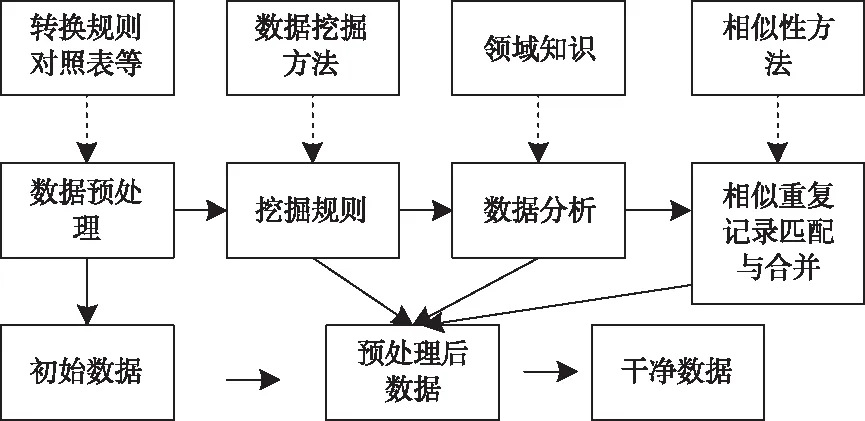
图4 数据挖掘与质量的框架分析
数据挖掘的质量分析一般分成4步:
数据预处理:当转换规则与对照表的指导下,来对初始数据进行元素化以及标准化的处理,构成预处理之后的数据信息,而元素化就是解析地址等自由的格式化的文本数据信息[10]。
挖掘规则:该步骤是在预处理之后的数据上,选取数据的挖掘方法,隐藏挖掘规则等。
数据分析:利用挖掘出的规则对异常数据进行发现,同时进行对应的标记或者结合领域内知识完成修正。
类似重复的记录匹配与合并:对相似对象识别,清除重复记录与冗余字段,完成记录合并。
3.2 降维处理与降噪处理
利用信号处理方法对数据信息进行特征提取,完成数据高维数据隐藏信息的挖掘。首先对高维数据进行子空间降维,利用贝叶斯网络对高维数据缩小开销计算,而相对于高维数据的时间序列x1,x2,…,xn,…,能够将其设置成采样数据时间的序列长度是N,而序列{Xi}时间的延迟是jτ,具体数据构造之间的自相关函数公式是

(6)
以此可以固定j,获取高维数据特征的矢量子空间,具体的子空间函数公式是
Xq=UDXTRxx(jτ)
(7)
式(7)中:U表示正交函数,把上述奇异值(SVD)分解,D表示高维数据的子空间类间的平均距离大小排序,XT表示非零的特征值。经过以上的子空间降维,完成数据的维度降低。然后以此作为基础,利用自适应级联滤波完成数据的降噪[11]。
如果数据的挖掘背景噪声内,具有Nx个正弦的信号,那么就说明所有的结构单元Hi(z)都是可变参数θ1i(k),最后选取可以使系统输出噪声更小的,具体滤波器传递函数公式为

(8)
与简化梯度的算法进行结合,利用级联的Nv个陷波器将滤波函数改成

(9)
式(9)中:陷波器频率的参数a与带宽的参数r,φi(k)主要是作为第i级梯度的信号,在经过上述处理,就能够完成对数据降噪,提升数据的挖掘精度。
3.3 数据隐藏模式挖掘
经过上述的降维处理与降噪滤波之后,能够将多通道的传感信息数据完成自适应的波束构成,然后利用提取特征的方式来对数据完成聚焦[12],具体输入高维数据的噪声p(ek|uk),方差与均值服从的分布公式为

(10)
相对于多个已知的干扰线谱内的高维特征矢量,建立自适应的波束形成器公式为
xmin,j=min{H(z)(xmax,j-xmin,j)}
(11)
xmax,j=max{H(z)(xmax,j-xmin,j)}
(12)
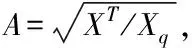
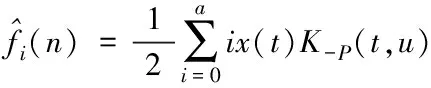
(13)
经过自适应的波束构成,其高维数据的矢量x(t)以及波束的聚焦核K-P(t,u)是作为基函数所展开的,具体构成新的映射公式为
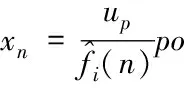
(14)
将up轴定义成po阶段的Fourier域,则噪声与干扰的情况,就能够利用自适应的波束所形成,以此完成高维数据的隐藏挖掘。
4 实验结果分析
为了验证所提方法的有效性,在仿真为MATLABR2014的环境下,选择浪潮XEON服务器,CPU主频选择2.4GHz,内存选择4GB,软件选择Windows 2003,程序选择Delphi7编写进行实验。在实验中的6组数据集是T40.I30.D8000K,其项目数分别为5000、10000、15000、20000、25000,事务量分别为2000、4000、6000、8000、10000,通过IBM数据发生器构成,存在高维大数据集特征。分别采用文献[3]方法、文献[4]方法和所提方法对高维数据隐藏模式挖掘的执行时间进行对比,具体对比结果如图5所示。
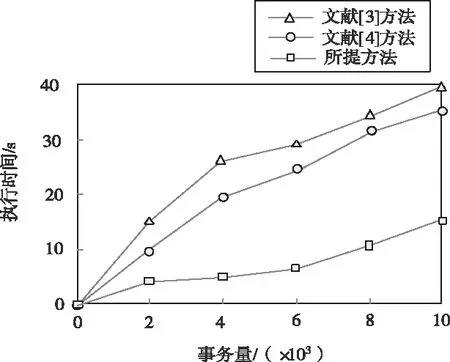
图5 不同方法高维数据隐藏模式挖掘执行时间
分析图5可知,随着事务量的增加,不同方法的高维数据隐藏模式挖掘执行时间均增加。其中,文献[3]方法的高维数据隐藏模式挖掘平均执行时间为28.8s,文献[4]方法的高维数据隐藏模式挖掘平均执行时间为24.4s,而所提方法的高维数据隐藏模式挖掘平均执行时间为9s。由此可知,所提方法的高维数据隐藏模式挖掘执行时间较短,本文主要采用贝叶斯网络确认父子节点间的关系或相连节点之间的互相关联概率,从而有效缩短高维数据隐藏模式挖掘执行时间。
在此基础上分别采用文献[3]方法、文献[4]方法与所提方法对高维数据隐藏模式挖掘工作量进行对比。minlen是评价高维数据隐藏模式挖掘过程工作量大小的指标。minlen越大,说明高维数据隐藏模式挖掘工作量越少,反之,minlen越小,说明高维数据隐藏模式挖掘工作量越多,如果minlen太小了,则交集的事务量增加明显,导致高维数据隐藏模式挖掘执行时间较长,从而影响了整体的性能。具体对比结果如图6所示。

图6 不同方法高维数据隐藏模式挖掘工作量
分析图6可知,当项目数为25×103时,文献[3]方法的minlen值最大为4,文献[4]方法的minlen值最大为10,而所提方法的minlen值最大为17。由此可知,所提方法的高维数据隐藏模式挖掘工作量越少,挖掘过程较为简单。
为了进一步验证所提方法的精度,在同一条件下,选取6组数据集,将所提方法与文献[3]方法、文献[4]方法进行对比,具体对比结果如图7所示。

图7 不同方法高维数据隐藏模式挖掘精度
通过图7能够看出,文献[3]方法和文献[4]方法的高维数据隐藏模式挖掘精度仅在70%左右,在实际应用时,经常会出现部分数据挖掘遗漏的情况。而所提方法的高维数据隐藏模式挖掘精度在90%左右,虽然同样存在部分遗漏,但相对于文献[3]方法和文献[4]方法遗漏的数量较少,在实际应用效果较好。由此可以看出,所提方法的高维数据隐藏模式挖掘精度较高,本文主要利用自适应级联滤波对高维数据降噪处理,有效提升数据的挖掘精度。
5 结束语
目前计算机技术各种类型数据收集工作量越来越大,致使数据库的规模逐渐变大,数据维度也越来越高。而这些高维的数据中,仅有部分的数据是有用的,所以需要在其中进行挖掘,寻找出有用的数据进行利用。而当前数据挖掘方法,由于挖掘精度低,执行时间较长,且挖掘过程工作量较大,过程较为复杂,很难达到实际应用需求。本文提出一种基于贝叶斯网的高维数据隐藏模式挖掘方法,先阐述贝叶斯网络的构成,通过贝叶斯网来计算高维数据,减少计算开销,利用信号的方式来对数据特征信息提取,完成高维数据子空间信息的降维操作,采用自适应级联滤波对高维数据进行降噪,最终把多通道声传感信息的数据完成自适应进行波束构成,聚焦数据,完成数据挖掘。实验结果表明,所提方法能够有效缩短高维数据隐藏模式挖掘执行时间,且数据挖掘精度,其挖掘过程工作量较小,挖掘过程较为简单。
