基于多元分解的大气污染深度学习预测方法
2021-11-17卫晓旭王晓凯
卫晓旭,王晓凯,朱 涛,龚 真
(山西大学物理电子工程学院,山西 太原030006)
1 引言
近年来,大气污染日益严重,全国环境空气质量相对较差的20个城市中,其中山西省占三个。为更好的解决多变量非线性时间序列的不确定性、不稳定性和复杂性问题,利用深度学习,可以提前预测污染物浓度,提供准确的防治对策并及时控制大气污染,修补工业生产中问题环节,创造出弹性、可塑性、可再生功能的绿色的人工自然系统。
20世纪40年代以来,人们在平稳随机过程中广泛使用预测方法是自回归模型(Auto Regressive, AR)、滑动平均模型(Moving Average, MA)和混合模型。对非线性数据,运用支持向量机(Support Vector Machine,SVM)可以看作是单隐含层网络,比BP具有较强的逼近能力和泛化能力,但是SVM算法对大规模训练样本难以实施,分类问题存在困难。深度学习可以对大规模数据进行整合。常用的深度网络有卷积神经网络(Convolutional Neural Networks,CNN)和循环神经网络 (Recurrent Neural Network, RNN)。目前,在RNN优化中被广泛接受的变体为长短期记忆网络(Long Short-Term Memory, LSTM),自此基础上,双向长短期记忆网络(Bi-directional Long Short-Term Memory,BILSTM)考虑上下数据信息,更好的捕捉双向的数据特征依赖。但是,CNN和RNN二者分别针对完全不同的问题做了优化,其任一功能存在单一性,存在数据特征提取不完全,参数权值不匹配等问题。
学者们通过对分解后的子序列进行分析可以提取出时序的特征,例如,STL在卫生医疗应用有STL-ADABOOST-ESN组合模型[1]对HIV月病发数进行预测。文献[2]针对单一模型无法实现准确的电力能耗预测的问题,通过引入STL时间序列分解并采用支持向量回归算法实现了电力能耗数据的准确预测。EMD是一种新的处理非平机稳信号的方法。文献[3]提出了EMD+SVM组合模型对风力进行了短期预测。文献[4]提出了一种基于经验模态分解(EMD)算法和深度学习相结合的集成方法。
近年来,国内外学者运用多种先进的多变量预测方法,例如,文献[5]基于多元回归分析方法,依据可能影响涌水量的主要影响因子,得到非线性预测公式对涌水量进行预测研究。文献[6]为了提高隧道火灾感温探测器温度预测的精度,建立隧道火灾温度分布多元回归预测模型。文献[7]利用时间序列和线性回归2种统计方法进行自适应预测。文献[8]将主成分分析法与定性分析和定量分析结合,建立基于多元分析优化的模糊神经网络预测模型预测短期太阳能辐射量。
为克服目前单一的非平稳预测算法难以充分捕捉时序的复杂关联特性,本文提出基于多元分解分析的大气污染深度学习预测方法。首先,确定主要预测变量,并对主变量进行STL分解得到3个分变量;其次,通过皮尔逊相关系数得出与主变量较为相关的几个相关变量;最后,对3个分变量和其余相关变量进行CNN+BiLSTM混合网络预测并融合得到主变量预测值。此模型充分提取复杂分平稳时序数据的特征,且可考虑多重影响因素,加之深度学习网络,可实现自动化的可靠预测。
2 多元分析和分解的深层预测方法
在本节中,首先建立一个模型框架来解释预测过程。然后介绍了该算法的核心关键部分,包括相关分析、时间序列数据分解和循环神经网络与卷积神经网络相结合的预测模型结构。在现存的比较成功的时序预测网络模型的基础上进行改进,以提高对非平稳多元时序数据的预测精度。
2.1 框架
模型框架如图1所示。可以看出,整个模型主要由4部分组成:输入变量、分解主变量、选择相关变量、模型预测。输入变量包括1个主变量及n个其它变量,分解主变量主要是对主变量进行STL分解得到3个主分量,STL可以将原始时间序列数据分解为三个子序列,它们具有不同的规律性,即趋势性、季节性和残差性。选择相关变量是通过皮尔逊系数挑选出n个相关度较高的变量,相关系数是反映变量之间相关关系的一种统计指标,这部分可以去除和主变量相关度不高的变量,减少模型的计算量,提高预测精度;最后,3个主分量和其余N个相关向量经过CNN+BiLSTM混合网络进行预测得到主变量预测值。

图1 模型框架
2.2 相关变量的确定
由于SO2浓度受多种因素的共同作用,其在大气中具有复杂性、随机性、可变性和不确定性,为了减少计算量,提取相关度较高的相关变量,提高预测精确度,本文选取相关变量时利用皮尔逊相关系数,得到影响其含量最为相关的变量。
皮尔逊相关系数广泛用于度量两个变量之间的相关程度。其实就是两个变量的协方差除以两个变量的标准差,其值介于-1与1之间。最常用的公式如下

(1)
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
1) 当相关系数为0时,X和Y两变量无关系。
2) 当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
3)当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
通过对大气中CO、PM2.5、NO、湿度、温度等进行相关系数对比得出,皮尔逊相关系数正相关的两大因素,即对其浓度影响最大的外部因素CO、PM2.5。同时,对附近监测站点的SO2的也进行了相关系数对比,选择三个最相关站点的SO2作为相关变量。
2.3 基于分解的深度预测模型
STL是以鲁棒局部加权回归作为平滑方法的时间序列分解方法。STL由两个循环机制组成,分为内循环与外循环,把时间序列分解为三个部分:趋势分量, 周期分量和残余分量,如式(2),其中,为趋势分量,St为季节分量,Rt为残余分量。
Yt=Tt+St+Rtt=1,2,…,N
(2)
本文中应用了CNN与BiLSTM结合的混合网网络,结构如图2所示。

图2 CNN+BiLST模型结构图


(3)

(4)


(5)
虽然Bi-LSTM需要训练更多的代来收敛到稳定性,但是输出是同时考虑了前后的因素得到的,因此更具有鲁棒性。同时也有更高的精度,因为它得到了更多的输入信息, 为神经网络提供的上下文全局特征,更快而且更充分地学习训练。因此,选择Bi-LSTM作为预测模型。
CNN-BiLSTM的方法可以通过CNN自动提取空间特征,考虑不同变量之间的水平信息提高准确性,又可以通过BiLSTM提取时序特征,学习CNN获得的特征的更多输入时序特征,并以此为基础进行预测融合,使得在多维时间序列变量的水平和垂直维度上都可以提取特征。
3 实验及结果
3.1 实验设置和数据集
实验数据来源于空气检测中心提供的大气检测数据,包括PM10、PM2.5、SO2、NO2、CO、臭氧、温度、湿度等物理量。利用所提出的多元预测模型来预测二氧化硫。这些气象数据包含9个监测站,每个监测站每小时测量一次,将每5个月的数据分为一段,一共设置三段数据,每段数据有3650个数据点。
本文设置三个实验,验证了该模型的预测性能。
实验1:选定预测站点的SO2数据为主变量,通过皮尔逊系数选出几条和主变量相关性特别高的几个气象要素和几个其它站点的SO2数据,将主变量进行STL分解,连同通过皮尔逊系数选出来的相关变量一同输入到CNN-BiLSTM中,来预测主变量。接着用LSTM、GRU、BP、ARIMA来预测主变量,观察多元预测方法和传统预测方法的优劣,通过3段数据进行实验。
实验2:在实验1多元预测的基础上,把STL分解去掉,直接输入主变量和相关变量,其余部分不变,和实验1多元预测进行对比。
实验3:在实验1多元预测的基础上,把其它站点的SO2数据去掉,输入其余变量,和实验1多元预测进行对比。
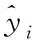

(6)
3.2 实验结果
3.2.1 实验1
预测站点的SO2预测结果如图3、4、5所示,棕色曲线代表真实数据,蓝色曲线代表多元预测结果,橘黄色、绿色、红色、紫色分别代表LSTM、GRU、BP、ARIMA模型的预测结果。

图3 数据1多元预测结果和传统预测方法对比

图4 数据2多元预测结果和传统预测方法对比
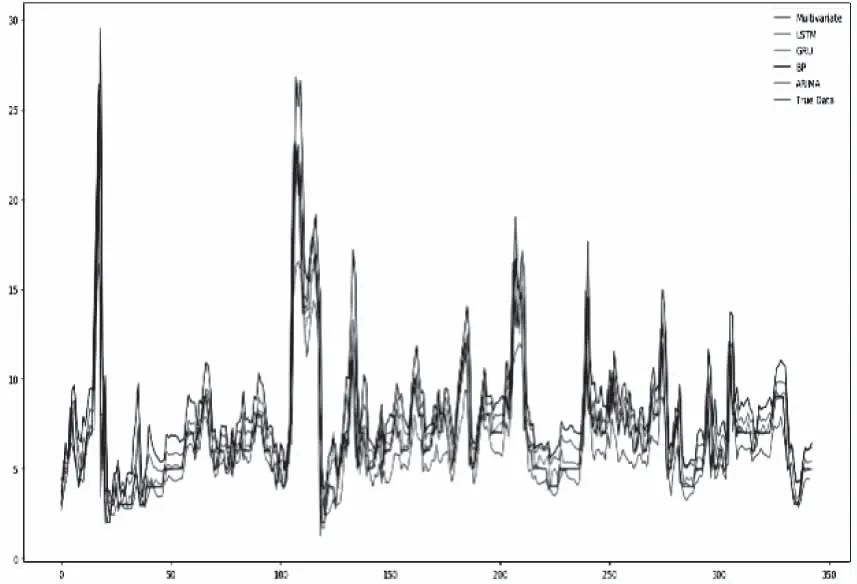
图5 数据3多元预测结果和传统预测方法对比
从图中可以看出多元预测结果的曲线与真实数据的曲线更加吻合,从图4可以看出,虽然数据的复杂度较高,但是多元预测模型相比其它传统模型预测效果要好,特别是在数据复杂度小的时间段,多元预测方法的预测性能尤为显著。但是在峰值较高的区间内,多元预测方法的预测结果要稍微逊色一些。表1表示多元预测方法和传统预测方法的RMSE对比,从表中可以看出,在总体预测性能上,多元预测方法要比其余传统模型预测方法的误差要小。GRU模型在传统预测模型中已经算是性能很好的模型,在预测数据1时,RMSE达到了4.71,但是在使用多元预测模型预测数据1时竟达到了6.38,在预测数据1和数据2时,更是比其它传统模型的预测结果的RMSE要低。

表1 多元预测和传统预测方法的RMSE对比
3.2.2 实验2
将多元预测方法中的STL分解去掉后,再来预测数据1和数据2。两个模型的预测结果如图6、7所示,蓝色曲线表示真实数据,黄色曲线表示去掉STL分解后模型的预测结果,绿色表示未经调整的多元预测方法预测结果。

图6 数据1多元预测方法与去掉STL分解的多元预测方法的预测结果比较

图7 数据2多元预测方法与去掉STL分解的多元预测方法的预测结果比较
从图中可以明显看出,去掉STL分解后模型的预测结果与真实数据吻合度比较差,特别在峰值特别高和复杂度比较高的区间内,对比度特别明显。说明在加入STL分解方法后,数据的噪声得到了降低,多元预测模型的性能得到了改善。多元预测方法与去掉STL分解的多元预测方法的RMSE情况如表2所示,从表中可以看出,在预测数据1时,多元预测模型的RMSE为3.59,去掉STL的多元预测模型的RMSE为6.05,文中的模型相对于去掉STL的模型预测性能提高了37.8%。在预测数据2时,多元预测模型的RMSE为7.38,去掉STL的多元预测模型的RMSE为10.79,文中的模型相对于去掉STL的模型预测性能提高了31.6%。通过分析发现,去掉STL分解后的模型预测性能明显比未经调整的模型差。
表2 多元预测方法与去掉STL分解的多元预测方法的RMSE比较

数据多元多元(去掉STL)数据13.596.05数据27.3810.79
3.2.3 实验3
将输入的变量中,去掉相关站点的SO2变量,再预测数据1和数据2,预测结果与元模型进行对比,如图8、9所示,图中蓝色曲线代表真实数据,黄色曲线代表原模型未经调整的预测结果,绿色曲线代表输入变量去掉相关站点的SO2数据时模型的预测结果。

图8 数据1多元预测方法与输入变量去掉相关变量的多元预测方法的预测结果比较

图9 数据2多元预测方法与输入变量去掉相关变量的多元预测方法的预测结果比较
从图中可以明显的看出,输入变量去掉相关站点的SO2数据时,预测结果效果不佳,说明其余站点的SO2变量与预测站点的SO2数据是有一定的联系的,去掉后,模型预测性能大打折扣。多元预测方法与输入变量去掉相关变量的多元预测方法的RMSE如表3所示,从表中可以明显看出,在预测数据1时,多元预测模型的RMSE为3.34,减少相关变量的多元预测模型的RMSE为4.72,文中的模型相对于减少相关变量的模型预测性能提高了29.2%。在预测数据2时,多元预测模型的RMSE为7.00,减少相关变量的多元预测模型的RMSE为8.55,文中的模型相对于减少相关变量的模型预测性能提高了18.1%。通过分析预测结果发现,输入变量去掉相关变量的多元预测方法的RMSE明显升高。

表3 多元预测方法与去掉相关变量的多元预测方法的RMSE比较
4 结论
实际从检测站点收集到的数据是多维的、复杂性高的、非线性的、嘈杂噪声的。所以,在进行数据预测时,通过皮尔逊系数分析多维数据之间的相关性对主变量的预测显得尤为重要,通过皮尔逊系数抛弃掉相关性不强的变量,大大缩短了网络学习的时间。通过STL分解将数据分解为周期分量、趋势分量和残差分量,有利于深度学习网络更有效的学习显著的特征。
观察实验1和实验3的结果可以看出,本文提出的多元预测方法的预测结果比传统网络预测和去掉相关变量的多元预测的效果要好很多,通过皮尔逊系数筛选出来的相关变量,减少了数据的纬度,减少了计算所带来的负担。
观察实验2的结果可以看出,对主变量进行STL分解后,再连同其余相关变量输入到CNN-BiLSTM比不进行STL分解输入到CNN-BiLSTM的效果要好很多,对于深度网络,网络训练受输入数据的影响很大。在提取特征时,适当的数据分解通常提供更简单的特征,有助于网络的训练。
通过实验,多元预测也存在一定的缺陷和不足,在输入数据维度过大时,误差反而降不下来,但是在大多数情况下,多元预测方法的性能比较突出,未来可以实现关联变量的动态分析,从而改善多元预测的性能。
