基于Ripley K函数的景观聚集程度仿真
2021-11-17罗小娇彭黎君
罗小娇,彭黎君
(1. 西南科技大学城市学院,四川 绵阳 621000;2. 西南科技大学,四川 绵阳 621010)
1 引言
景观是由不同土地单元聚合而成的,是具有明显视觉效果、经济效果和美学效果的混合型制造物。景观的聚集程度由景观布局和景观个体大小排列交汇而成,是景观动态变化的具体表达方式,由于景观聚集程度需要符合当前市场、社会以及城市的多方面需求,因此将其作为自然和社会要素间产生的相互作用结果。随着人们对城市景观需求的不断增强,景观对人们生活的影响范围也不断扩大[1]。提高城市景观建设的合理性,是对城市人们休闲生活状态的负责。景观聚集程度是当前城市景观合理性的核心部分,为提高城市景观聚集程度的合理性,必须仿真研究景观聚集程度,通过分析城市景观布局和人类活动的相关关系,获取人为干预下城市景观的演变规律,进而研究当前城市景观建设的重要意义。
文献[2]结合景观生态学研究了土地利用景观格局变化特征,引入CA-Markov模型对土地利用变化过程进行模拟,预测和评估景观的聚集程度。但是该方法存在引入模型局限性大的问题,导致方法无法普遍应用。文献[3]基于混合蛙跳算法,耦合逻辑回归与马尔可夫模型构建了SFLA-M-L模型。利用景观适宜性指数和景观聚集度指数构造目标函数,以景观转移概率矩阵为景观聚集的控制条件。该方法效果较理想,但是其过程过于复杂,应用要求太高。文献[4]利用粒度反推法和主成分分析从增强整体连通性的角度实现了生态源地的客观选取,并结合最小累积阻力模型构建了生态景观聚集程度评估网络。该方法虽然实现过程较为简单,但是其景观聚集程度分析结果与实际相差较大,方法不够精准。
为有效提高城市景观聚集程度数据精度,设计从Ripley K函数角度出发,对当前景观的各据点进行分析,再对噪声进行评估,根据当前景观图像的布局,完成景观聚集程度的仿真[3]。
2 景观聚集程度模拟方法
在对城市景观聚集程度总计布局来说,需要利用认知美感和认知情感结合的方式,实现景观汇聚。在此过程中,分析当前景观聚集程度的美感认知程度,可以获取当前景观聚集网络走向。

图1 景观聚集程度网络走向
所以在对景观聚集程度进行模拟仿真的过程中,需要结合当前城市人群情感特征,包括美感认知层次,计算当前城市人群对于景观节点的覆盖概率[5]。因为景观的美感层次包括汇聚等多重结构,均需要一个由浅入深的过程,所以需要对其进行量化处理[6]。设计以RipleyK函数为核心,通过引入多重空间数据,制定局部据点的分析层次,对当前景观均值图像进行噪声评估,通过多重景观视角,实现景观汇聚程度仿真。
2.1 基于RipleyK函数的景观各据点分析
想要获取最佳的景观聚集程度仿真数据,需要保证当前景观的核心层次美感,满足当前区域空间环境以及人们的需要。RipleyK函数是一种可以实现多种数据空间限制尺度下的空间点格局分析方法,景观类型包括空间尺度特征和强度特征,均可以通过RipleyK函数进行体现,如果借助RS技术,就可以完成对景观板块的初步分析。在应用RipleyK函数前,需要引入当前环境下人们对景观的认知数据,确定其层次结构,如图2所示[7]。

图2 认知数据结构
图2中的各边均可看做是景观认知途径,包括多种拓扑结构。RipleyK函数以认知层次数据为中心,构建N个不同景观的认知网络G(V,L),其中根据景观汇聚数据构建的美感认知节点集合为
V={V1,V2,V3,…Vn}
(1)
在景观美感认知网络G中,将任意的节点Vi带入到相邻节点的分析矩阵中,可以获取当前景观节点的前导性集合
F(Vi)={Vj|(Vi,Vj)∈L}
(2)
RipleyK函数作为点格局分析工具,可以进行多尺度研究,利用前导性集合对数据的显著性进行验证[8]。最大化减少后续景观汇聚程度仿真的过程,会影响分类的工作量,而且可以最大化保证计算精度。其计算公式如下

(3)
在上述式(3)中,A、n、d分别指当代景观研究区的区域面积、随机研究点个数以及绝对空间点尺度[9]。获取函数数据后,利用仿真工具ArcGIS10.0的软件工具箱中的SpatialStatistics工具,随机生成5000个函数公式指代点,并将指代点的图层按照不同结构需要进行矢量叠加和分析,获取随机点的专属类型,然后利用RipleyK函数进行三级显著点划分。RipleyK函数中的L(d)函数值计算时,半径每增加1000米,需要计算至少20次。函数边界的矫正需要采用编制模拟法,如图3所示。

图3 编制模拟示意图
利用编制模拟,根据采样区域边界,划分函数边界,在利用蒙特卡洛模拟法进行检验,包括偏离随机性和显著性,其置度数超过99%。
把RipleyK函数获取的格式结果导入到排序文件中,生成上包线、下包线则该景观空间分布整体呈聚集性趋势。当L(d)值关系数大于预期值是,函数观测值曲线会远离预测值曲线,则整体数据观测点的分布处于集聚趋势中。将观测线数据进行汇总,建立数据集,该数据集即为当前RipleyK函数下,景点数据的数据点分析数据[10]。
2.2 景观据点图像噪声评估
利用RipleyK函数建立景观汇聚趋势下的分析数据集后,即可建立当前景观的均值图像数据。但上述数据集存在有用数据和无用数据,利用获取到的有效图像滤波信息,同时引入立体图像组织数据建立立体图像,结合特征信息构建向量集,完成数据的分解,以实现对其噪声的确定。
设当前图像信号噪声为n(t),此时存在以下关系
s(t)=x(t)-n(t)
(4)
其中x(t)表示当前景观原始数据点分析数据;设
fx(x,μ,σ2,γ)=ωmey
(5)
其中,μ与σ表示现阶段图像信息分布子代系数的平均数与均方差,γ表示分类带状数值;ey表示公式的分类数。利用小波变换当前图像信息的分布情况,实行多角度检测。通过不同特征值组成图像的向量集,具体表达式如下

(6)
在公式中,d代表方向,s代表图像尺度;
通过以上方法可以获取图像的特征信息,包括n个噪声信息向量,{x1,…,xn}⊂X,σi表示当前个图像布局中的样本下相应的噪声水平参数,指定当前图像布局的特征向量Y,利用下述公式表达当前景观图像的实际布局噪声

(7)
式中,w(y,xi)是当前图像噪点决策权重函数,该函数主要依赖于当前图像布局下的空间矢量数据,y为图像中的矢量数据距离,利用下述公式表示当前数据权值
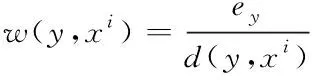
(8)

2.3 景观图像布局
以1.2节获取的景观聚集趋势下去噪后的图像数据为依据,利用景观仿真形态学,将景观图像的布局划分为景观聚集纹理区和景观聚集光滑区两个部分。采用椭圆形聚合窗数据评估景观图像,并确定当前图像小波域图像区域个点位的信号方差。然后利用双重维纳滤波对去噪图像进行重复构建,其构建过程如下:
y(i,j)=s(i,j)+ε(i,j)
(9)
式中,s(i,j)和ε(i,j)分别代表图像布局点和小波域实际系数。
对当前景观聚集图像布局X来说,需要保证其边缘检查效果,获取最佳图像布局边缘。设计采用拉普拉斯算法,定理对应算子L(·),对三维空间景观图像布局进行滤波析出,提取对应算子,再次基础上根据滤波处理后的景观聚集图像阈值,获取图像边缘:
E={(m,n):L(m,n)>mean(L(X))+std(L(X))}
(10)
其中,mean(·)与std(·)表示现阶段图像汇聚的分布方阵元素,分别为汇聚仿效的平均数与平均差计算值,与此同时对现阶段汇聚分布图像进行数值图像处理,区分汇集边缘和领域,通过式(11)完成计算
M={(E·B)∘B}
(11)
式中,·和∘分别代表当前景观边界区域运算的开合运算和闭合运算。定义当前参数M(i,j),用于指代输出的三维空间景观图像布局数学形态最终的处理结果,即

(12)
此时需要进行图像划分的景观聚集区小波系数,存在的噪点较低,由此利用上述最终的景观聚集评估数据结果,建立当前景观聚集图像小波域不同层级的子带信号方差,计算公式为
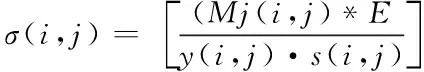
(13)
式中Mj(i,j)代表当前M(i,j)的数据采样结果。评估当前图像景观聚集程度的布局信号,再根据执行滤波,获取最终景观图像的布局优化结果。

(14)
式中,y2(i,j)代表了图像布局下的小波分解域系数。根据以上方法,即可完成维纳滤波景观下的图像布局。
2.4 景观聚集程度模拟的实现
为使景观聚集程度仿真的结果符合当前城市区域和使用用户的应用喜好,设计采用多指数法对当前景观格局聚集程度特征进行数据描述。根据景观斑块的外部形状,以及斑块紧密程度求取当前景观的近园观测指数,包括测度尺上的表征和斑块边缘复杂程度的维度值。应用上述数据,结合当前景观斑块在图像上的离散程度,可以分组建立多指数集合,根据该指数集合即可最终确定景观聚集程度,完成仿真。
近园指数SICi:景观斑块的形状越紧密,景观聚集的整体效果越趋近于圆形,近园指数也就越趋近于1。该指数越小,则表示斑块形成也就越复杂。其公式表达式为

(15)
方形指数SISl:该指标的取值一般大于1或者等于1,该值越大,表示当前景观聚集斑块越复杂,景观偏离度也就越远。其公式表达式为

(16)
分维数D:该值反应了当前观测尺度下的景观斑块边缘复杂程度,该值越小,越表明当前景观斑块的相似性越强。其公式表达式为
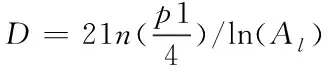
(17)
分离度Fl:该指数可以表述为当前景观聚集程度下空间分布的离散程度,该值越大,则表示景观斑块分散程度越高,其公式表达式为

(18)
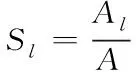
(19)
在上述公式表达式中,Pi代表了当前景观斑块的周期长度;AI代表了当前景观实际斑块面积,nI代表了当前景观斑块个数;综合上述公式,可以建立多个当前景观聚集程度的指数数据集合K。
K={SICl,SISl,D,F}
(20)
在实际仿真中,可以根据当前仿真软件的实际需求,将当前景观聚集程度指数指标录入到PC端中,所获取的最终数据结果,即为当前景观聚集程度仿真结果。
3 仿真研究
实验硬件平台中央处理器主频调试为3.5GHz,内存为8GB,仿真软件平台设置为Matlab2018a。为了验证当前设计的基于RipleyK函数的景观聚集程度仿真技术是否可以达到理想的效果,以传统决策树分析数据仿真和Markov数据链分析仿真为对比组,进行标准化的景观聚集程度仿真。实验指标为当前景观布局的合理性和真实度。其实验流程如图4所示。

图4 实验流程图
3.1 景观布局合理性对比
景观布局合理性是对景观聚集程度仿真效果的重要评测指标,其合理性越高,证明景观聚集程度仿真效果越好。实验组和对比组仿真结果如图5所示。

图5 合理性对比
图5代表了随机10组实验组的合理度系数评测情况。分析图5数据可知,传统决策树和数据链分析方法进行的景观聚集程度仿真结果其合理性系数均在0.5到0.7左右,而基于ipleyK函数的景观聚集程度仿真技术其仿真结果的合理度系数则均在0.7以上,二者相差比例超过20%,证明了当前设计的仿真技术其获取的模拟结果更加合理。
3.2 景观聚集真实度对比
传统景观聚集程度仿真技术虽然可以获取更有效的仿真结果,但是因为环境变更和适应误差等因素,无法完全满足实施要求。对此实验引入真实对评测指标,用于评测当前的景观模拟结果是否具有真实的应用价值。表1为三种仿真技术获取数据的真实度对比情况:

表1 不同方法下数据真实度对比
在上述实验表格中,H1代表此次设计的基于ipleyK函数的景观聚集程度仿真技术,H2和H3分别代表了传统决策树和数据链分析方法。根据表1数据可以看出,此次设计的仿真技术,其仿真结果真实度均在90%以上,而决策树和数据链分析方法的平均真实度在75%和71%左右,明显低于设计方法。经过上述两次分别针对合理性和真实度的对比实验,可以确定此次设计的基于ipleyK函数的景观聚集程度仿真技术获取的数据结果与常规方法相比,具有更高的数据准确度,其整体精确度更高,应用效果更好。
4 结束语
城市景观聚集程度是城市景观规划的重点,对其进行有效数据仿真,可以提高当前景观规划效果。为有效解决仿真精确度问题,此次设计通过RipleyK函数构建数据集,通过去噪布局等步骤,完成仿真,获取仿真数据,其真实度更强,且整体仿真效果优于传统方法。
