基于YOLOv5s的人脸是否佩戴口罩检测
2021-11-12张路遥
张路遥,韩 华
(上海工程技术大学 电子电气工程学院, 上海 201620)
0 引 言
截止2020年12月,全球累计确诊新冠肺炎病例已经超过8 000万例,累计死亡病例已经超过180万,病例每天以更快的速度上涨[1]。受疫情的影响,绝大多数主要经济体受到了影响,为了抵制病毒的传播,同时加快复产复工的速度,国家制定了相关的政策,要求人们在公共场所必须佩戴口罩,这一措施有效的降低了病毒的传播概率,成为一个切实可行的举措[2]。然而在公共场所中,会遇到有些人有可能忘记佩戴口罩的问题,在这种情况下一般是由安检人员进行提醒,这不仅增加了人力成本,也增加了人与人之间传播的概率。
在高铁、地铁等一般都会配备有人脸检测识别装置,这些装置具有很高的人脸检测识别率,然而其仅限于人脸的检测识别,无法检测人脸是否佩戴口罩,无法满足当前疫情下的现实需求。
在这种背景下,为了能实时精确检测人脸是否佩戴口罩,本文选择目前比较流行的YOLOv5s目标检测算法作为本文的基础算法。本文从面部遮挡数据集MAFA(A Dataset of MAsked FAces)和人脸检测数据集WIDER FACE中随机抽取了9 800张人脸数据,并使用LabelImg重新进行了标注和校对。训练出的模型不仅具有更高的精确度和召回率,而且可以较为容易地部署到移动端设备中。
1 目标检测相关方法介绍
近年来,计算机视觉在目标检测方面取得了很大的进展。其中,YOLO系列算法作为目标检测领域的一个经典算法,其思想是将检测任务转换成一个回归的问题,利用整张图作为算法的输入,直接在图像的多个位置上回归这个位置的目标框及目标的类别。凭借着出色的检测精度和速度,YOLO系列算法在包括行人检测、缺陷检测、医学图像检测等多个领域得到了广泛的应用。
YOLO系列目标检测算法是一个不断迭代的算法。随着技术的发展,YOLO已经发展到了YOLOv5。其中,比较出名的为YOLOv3,YOLOv5。就大体的结构而言,YOLO系列算法的网络结构都是由输入端、Backbone、Neck和Prediction 4个部分组成。YOLOv5的网络结构如图1所示。
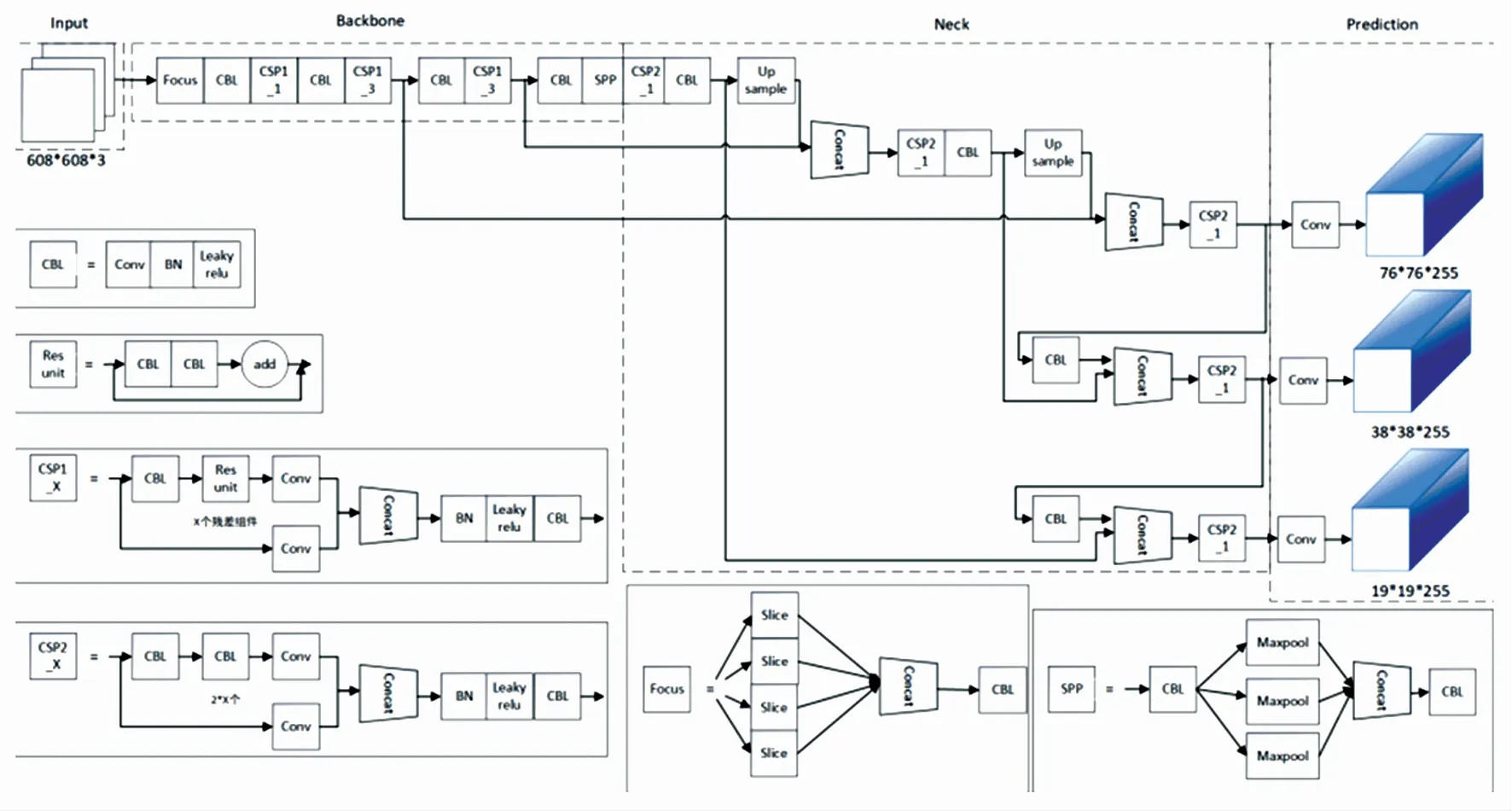
图1 YOLOv5网络结构图
相比较于YOLOv3,YOLOv5在网络结构的4个部分进行了创新:
(1)输入端部分:使用Mosaic数据增强的方式,使用自适应锚框,自适应的图片缩放;
(2)Backbone部分:使用Focus结构和CSP结构;
(3)Neck部分:使用FPN+PAN结构;
(4)Prediction部分:采用GIOU_Loss。
YOLOv5系列一共可以分为YOLOv5s、YOLOv5m、YOLOv5l和YOLOv5x共4种网络。其中,YOLOv5s的网络最小,精度相比较其它3个略差,但是其检测速度最高。其它3种网络是在YOLOv5s的基础上,不断的加深和加宽网络结构,精度依次上升,但检测速度略慢。由于本文要求的基础算法要有较高的检测速度,且有部署到移动或者嵌入式端的需求,故选用YOLOv5s目标检测模型。
2 人脸是否佩戴口罩检测
本文利用安装在检测设备上的摄像头采集的视频图像作为输入,并将其输入到本文训练好的YOLOv5s算法中进行人脸是否佩戴的检测。算法会在采集的视频图像上绘制出人脸或人脸口罩的边界框,并在边界框的上方输出是否佩戴口罩的检测结果。当显示佩戴口罩时会启动装置发出通过的命令,反之则发出不能通过的命令。以装有人脸佩戴检测算法的闸机为例,当YOLOv5s人脸口罩检测算法在镜头前检测出佩戴有口罩的行人后,会打开闸机使行人通过。当在镜头前检测出行人没有佩戴口罩后,不会打开闸机,重新进行检测直至该行人带好口罩为止。人脸佩戴口罩检测算法的闸机检测流程图如图2所示。
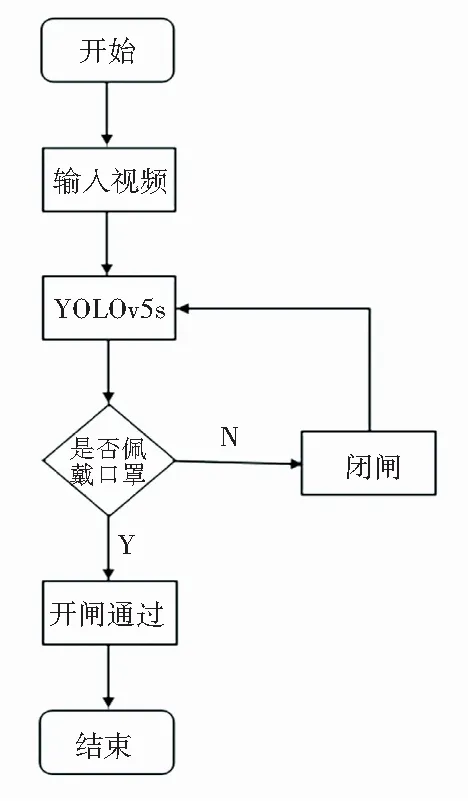
图2 闸机检测流程图
2.1 数据集
本文从面部遮挡数据集MAFA和人脸检测数据集WIDER Face中抽取了9 800张图像作为模型的数据集。由于图片缺少适合YOLO算法的标注文件,故本文使用LabelImg软件重新进行了标注,90%的图片用于模型训练,剩下10%用于模型测试。使用LabelImg软件进行脸部标注示例如图3所示。
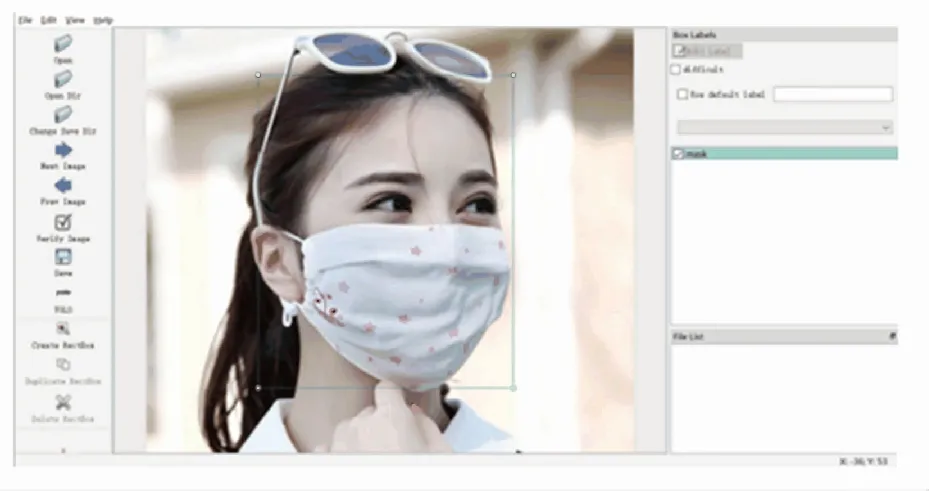
图3 数据集标注示例图片
2.2 模型
考虑算法需要比较快的检测速度,本文选用YOLOv5系列中的YOLOv5s作为人脸佩戴口罩检测的基础算法。另外,在训练阶段,对模型进行适当的微调来加快训练及收敛速度。
2.3 算法实验平台
本文的算法实验平台可分为硬件和软件两个部分。具体的硬件和软件配置见表1。

表1 硬件及软件配置
2.4 实验参数设置
训练阶段参数设置:
本算法使用9 800张图片中的90%作为训练集,采用数据并行的方式进行训练,设置世代(epoch)数为300,优化方法为随机梯度下降法(SGD),batch的大小为36,图片的大小为1 024。
测试阶段参数设置:
本算法使用9 800张图片中的10%作为测试集。在测试阶段,加载训练好的权重文件,设置图片的大小为1 024。
3 结果分析
为了验证训练出的YOLOv5s模型对人脸是否佩戴口罩检测的性能,本文在测试集上进行了总体的评估。
3.1 评价指标
依照目标检测领域常用的评价指标,使用精确率(P),召回率(R)和平均精度均值(mAP)作为人脸是否佩戴口罩检测任务的评价指标。
精确率又被称为查准率,表示分类器分为正样本的样本中实际为正样本的比例,即分对样本的概率。精确率的计算公式(1)如下:
(1)
其中,tp表示实际为正样本,且被分类器划分为正样本的数量,fp表示实际为负样本,但被分类器划分为负样本的数量。
召回率又被称为查全率,表示分类器分为正样本中实际为正样本的数量占全样本中正样本的比例。召回率的计算公式(2)如下:
(2)
其中:fn表示实际为正样本,但被分类器分为负样本的数量。
平均精度均值是将每个类别的平均精度(AP)做算术平均值。该指标是对要检测目标的一个综合度量,常见的mAP有mAP@.5和mAP@.5:.95,表示当阈值设为0.5和0.5~0.95时的平均精度均值。mAP的计算公式(3)如下:
(3)
其中:N为类别数,AveP(i)为第i类的平均精确率。
3.2 算法性能分析
为了量化本文使用的YOLOv5算法的性能表现,本文将YOLOv5、YOLOv3和YOLOv4检测算法在人脸是否佩戴口罩检测任务上的性能进行比较。3个算法在同一个数据集中的检测性能比较结果见表2。
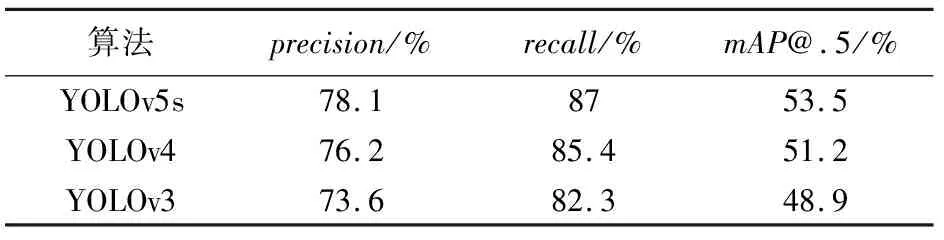
表2 3个算法在数据集上的测试结果
由表2可以看出,在同一个数据集进行训练和测试,本文使用的YOLOv5sprecision为78.1%,recall为87%,mAP@.5为53.5%,3个指标均高于YOLOv3和YOLOv4检测算法。
3.3 结果展示
本文针对人脸是否佩戴口罩检测任务训练的YOLOv5s模型的推理结果如图4所示。在单人佩戴口罩、单人未佩戴口罩、多人佩戴口罩、多人未佩戴口罩这几种情况下都具有良好的检测效果。

图4 多情况下口罩佩戴检测效果图
4 结束语
本文使用YOLOv5s检测算法作为人脸口罩佩戴检测的基础算法来完成检测人脸是否佩戴口罩的任务,应用在闸机设备上。当YOLOv5s检测出佩戴有口罩的人脸,则允许通行。反之则不允许通行直至带好口罩为止。使用YOLOv5s训练好的模型的precision为78.1%,receall为87%,mAP为53.5%,均超过YOLOv3和YOLOv4目标检测算法,达到了任务的目标。
