面向司法大数据的文本主题OLAP系统
2021-11-12刘晓清何震瀛奚军庆
王 玲,刘晓清,何震瀛,奚军庆,项 焱
(1 复旦大学 软件学院,上海 200438;2 复旦大学 计算机科学技术学院,上海 200438;3 司法部信息中心,北京 100020;4 武汉大学 法学院,武汉 430000)
0 引 言
随着新兴技术的发展,数据流量增长速率不断加快,大数据成为各行各业的研究热点。司法大数据的运用正成为提高司法业务效率、推进审判体系和审判能力的现代化重要手段。绝大部分的司法数据,如:法律文书、法律新闻等法律类文章都是非结构化数据,其中蕴含着案件类别、案件发生时间、案件发生地点等重要信息。如何处理这些非结构化数据,挖掘其中的重要信息亟待解决。
法律文书或法律类新闻中,往往包含地理位置信息,提取文本中的地理信息并精准定位,对案件地域分布研究具有重要意义。因此,需要设计一个能自动判别法律文章的行政区划方法,以满足用户希望根据法律文章的地点维度做数据分析的需求。
对于文本数据关键信息的获取,常见的是通过主题建模方式抽取文章的潜在主题。文本主题即文本的主旨思想,表现为一系列相关的词语。如:一篇法律文章中涉及到“离婚”这个主题,那么出现“婚姻”、“子女抚养权”、“财产纠纷”等词语的可能性会比较高。从数学角度来看,主题就是语料库中词语的条件概率分布。一个词语和主题关系越紧密,其在文章中出现的条件概率越大。主题模型是对文字中隐含主题的一种建模方法。LDA(Latent Dirichlet Allocation)[1]是一种经典的文档主题生成模型,通过对文本进行统计分析,学习出主题的分布,可实现关键词提取及文章聚类。LDA假设在一个文本集合中存在多个主题,每个主题下又都包含一系列的词汇。那么对集合中任意一篇文章,可看作是按照一定概率选择主题及词汇构造而成。集合中的单词构成的概率分布,组成了一个主题。不同的主题再构成一个概率分布,最终组成文章。LDA首先按照一定概率选择某个主题,接着在此主题下以一定的概率选出某个词,作为该文章的第一个词。通过不断迭代上述步骤模拟文章生成的过程,最终得到一篇完整的文章。目前针对文章主题,各方学者展开了许多研究工作。比较常见的有主题检测与跟踪[2]、主题生命周期以及突发性[3]等。但是,这些研究都将重点放在了给定范围内文档主题的变化状态,并未考虑该主题在全局范围的地位。因此,文献[4]中提出了独特主题这一概念,用来寻找只在小范围内频繁出现而不在全部文档中出现的主题。
常见的大数据处理技术有HBase[5]、Spark[6]等。HBase是一个开源的非关系型分布式数据库,其参考了谷歌的BigTable[7]建模,可以容错地存储海量稀疏的数据。Spark是一种快速、通用、可扩展的大数据分析引擎,为分布式数据集的处理提供了一个有效的框架,并以高效的方式处理分布式数据集。Spark实现了一种分布式的内存抽象,称为弹性分布式数据集[8]。其能够广泛适用于数据并行类应用。其中包括:批处理、结构化查询、实时流处理、机器学习与图计算等。
数据仓库技术常应用于大规模数据分析工作。OLAP(Online Analytical Processing)[9]是数据仓库[10]提供的一种对储存在数据库中的多维数据进行搜索和分析的技术,其能在不同维度上对数据进行搜索和分析。常规的OLAP实现方式,是用数据库中的多维数据,构建数据立方体[11],多维数据的每一维都对应到数据立方体的每一条轴上。通过对数据立方体各个维度的组合,实现OLAP分析。此外,OLAP还提供了诸如上卷、下钻、切片等操作,使用户可以更深入的分析数据。然而OLAP的这些操作大都只支持关系型数据。
针对上述提到的种种现象和问题,本文设计了一个面向司法大数据的文本主题OLAP系统。通过对文本进行预处理及分析,来实现法律文章数据行政区划归类、主题建模、独特主题查找以及基于此的OLAP,具有重要的实际意义。本文从3方面对此进行了研究:
(1)针对司法数据量庞大且多以非关系型数据为主的特点,设计了一个数据模型以及基于此基础的操作符,通过各种操作符的组合达到数据处理的目的。底层使用了Spark分布式处理系统来实现,以此达到高效地处理大规模非关系型数据的目的。
(2)针对法律文章数据中的主题、时间、地理位置等多维度信息挖掘,设计并实现了一系列数据处理方法,使数据可以最终变为主题立方体形式,供OLAP查询使用。
(3)设计了基于OLAP的线上查询模块以获取司法数据关键信息。
1 基于Span数据模型的文本主题OLAP系统
本文设计了基于Span数据模型的文本主题OLAP系统。系统由线上查询和离线处理两部分组成,整体流程如图1所示。
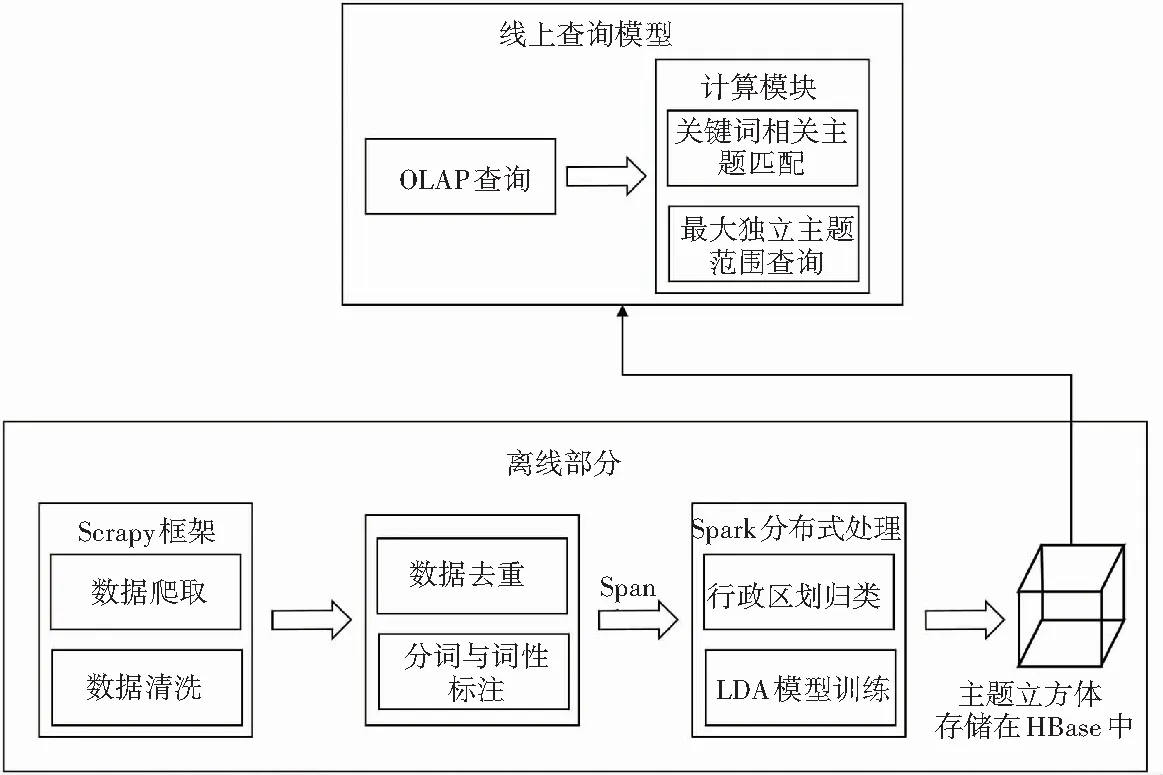
图1 系统整体流程
系统使用Scrapy分布式爬虫框架,爬取网络上的法律文章[12],利用Spark对文本进行清洗、去重以及分词处理[13]。本文设计了Span数据模型,将处理后的文本以Span形式存入HBase中。随后,使用Span的操作符进行关键词提取、行政区划归类以及主LDA模型训练,最终得到具有时间维度和地理维度的主题模型立方体。当用户发起OLAP查询时,系统根据用户的查询操作,结合之前保存在HBase中的数据以及主题立方体,进行关键词相关主题匹配和最大独立主题范围查询。用户可以对返回的结果执行上卷、下钻等OLAP操作来获取感兴趣的信息。
1.1 Span数据模型
在传统的数据模型基础上,本文提出了Span关系模型,来描述原本非关系型的文本数据,并在此基础上设计了适用于此关系模型的操作符和任务。
系统将每篇法律文章表示为关系模型的一行,其中包含的属性见表1。如:id为文章的编号、title为文章的标题、text为文章的正文、text_spans为文章正文经过切词和词性标注后的结果。
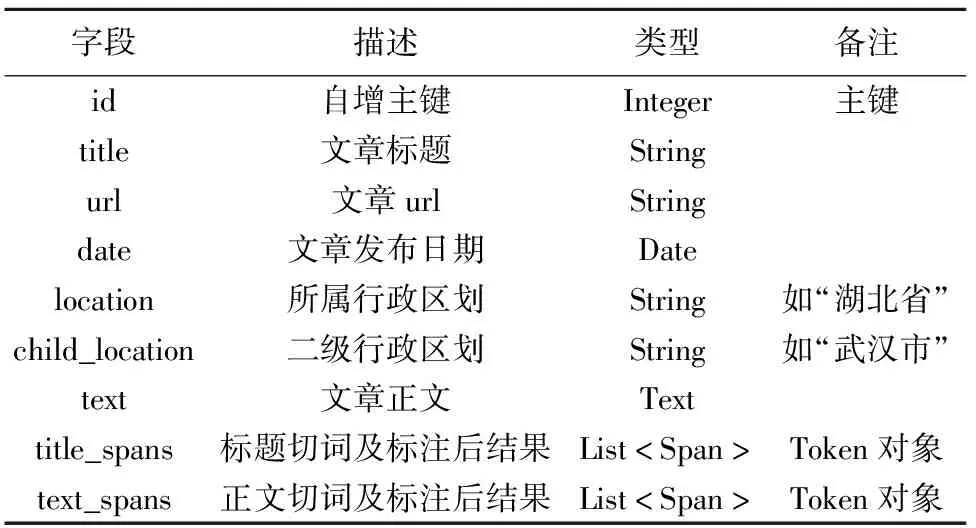
表1 数据模型
其中,“text_spans”和“title_spans”两列的类型为List。Span的定义见表2。
每一个Span都是文章在分词之后的一块内容,每个Span包含表2所示的4个属性。
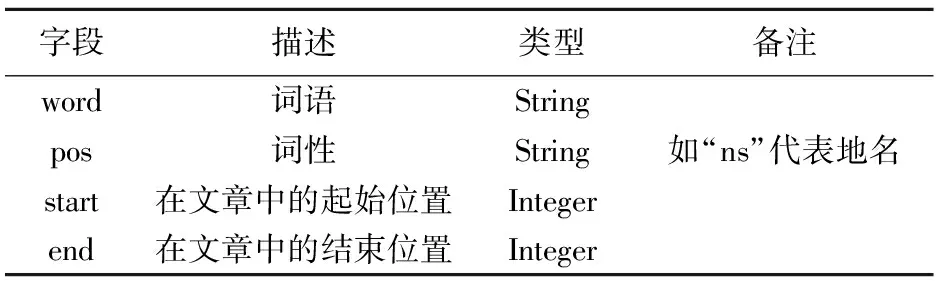
表2 Span定义
其中,word是Span的词语;pos是Span的词性;start是Span在文章中的起始位置;end是Span在文章中的结束位置。
本文将每篇文章的text_spans字段看作一张表,表中的每一行都为一个span。这样的表示方式对于理解之后定义的诸多基于span之上的操作是有帮助的。具体表示方式如图2所示。
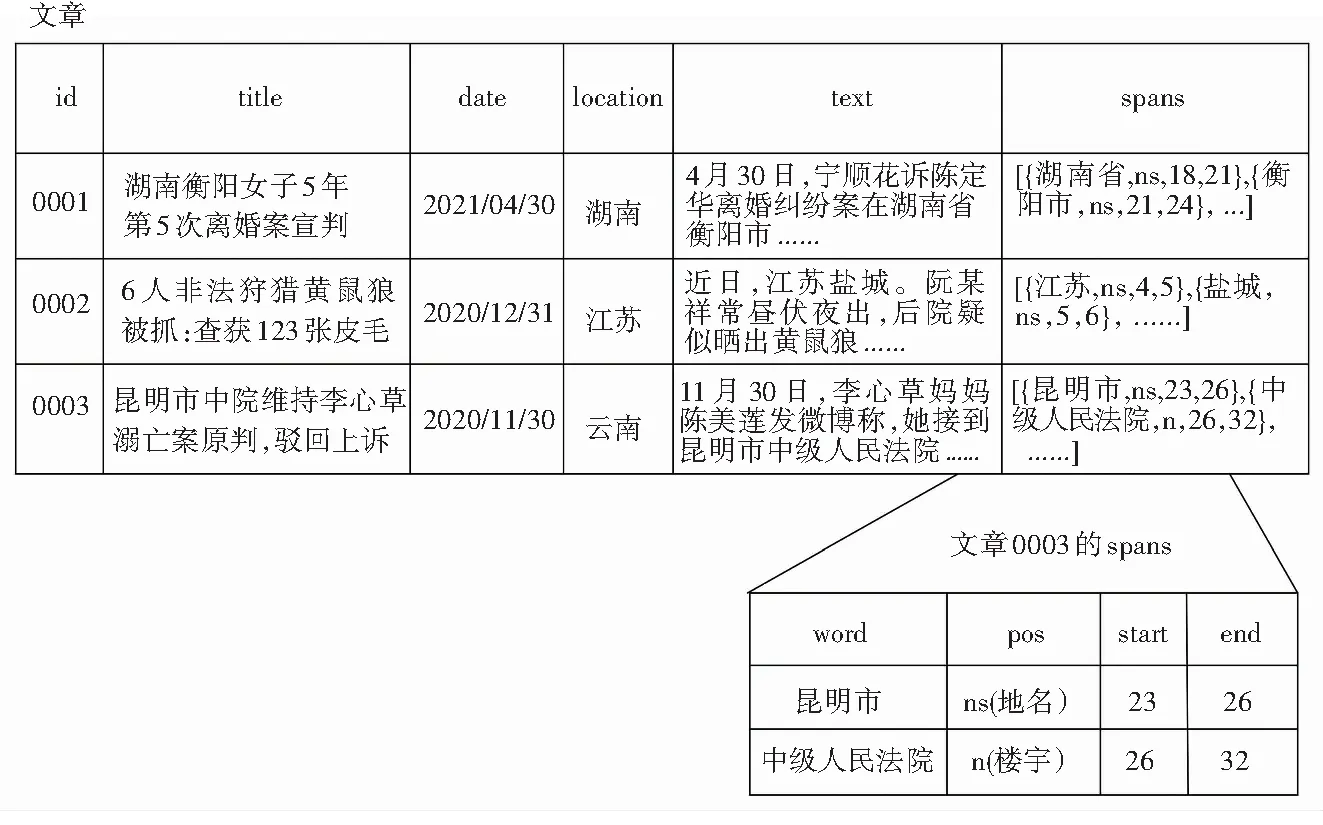
图2 Spans示例
在将每篇法律文章转换为Span的集合之后,本文在这些Span上执行统一的操作来实现信息抽取。在定义完操作符后,用户可以将一系列操作符进行组合,形成一个任务,每一个任务都是对文章信息的一次抽取,可以通过一系列操作符,组合出LDA模型的构建过程。表3中列出了本文设计的主要文章级别的操作符及其作用。
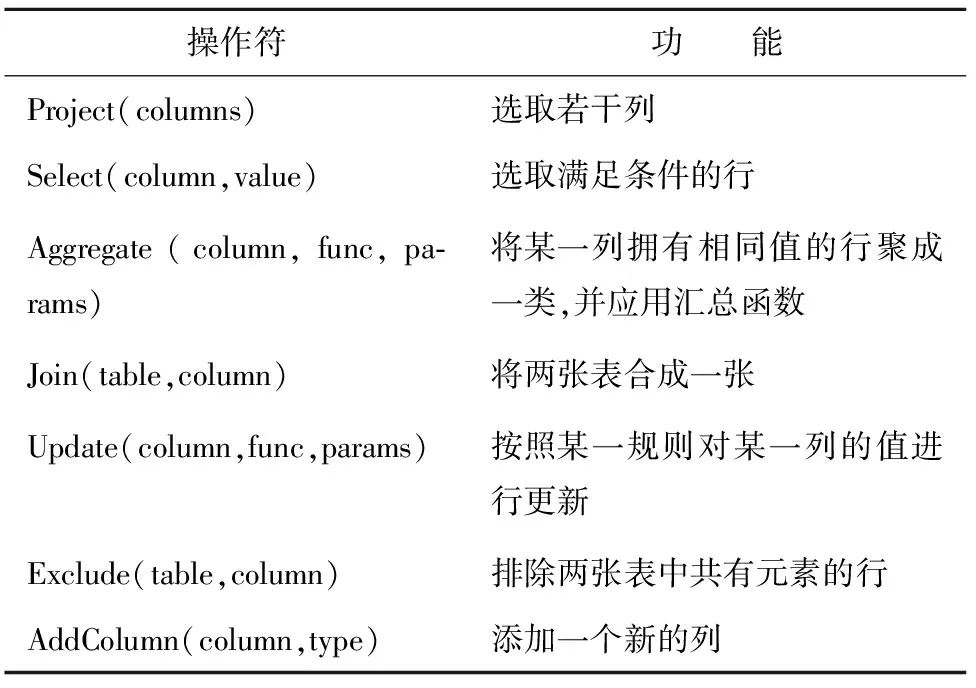
表3 文章级别的操作符列表
基于上述操作符,可构建相应的信息抽取任务。给定主题数K=100、alpha=0.5、beta=0.01、N=100,利用本文设计的操作符,实现LDA模型训练的过程如下:
第一步:用Exclude去除Corpus中的停用词;使用Project将不用的列删除;使用AddColumn和Update添加“topic”属性并且赋初值。
第二步:进行吉布斯采样,根据其采样结果,以服从多项式分布的方式,重新随机分配每个词对应的主题。为了让模型收敛,此步骤需要执行N次循环。
第三步:使用Aggregate统计每个主题的词分布。
1.2 数据处理及主题立方体
1.2.1 基于规则的行政区划归类方法
目前,多数采用机器学习或者深度学习的方法,对文章主题进行分类。基于学习的文本分类方法,不适用于本文期望实现的行政区划归类功能。由于基于学习的文本分类方法,需要大量的人工标注数据集,而本文为OLAP系统,要求能实现上卷、下钻等用户需求。单一粒度的地理维度显然很难满足OLAP用户的需求,当用户对某一主题感兴趣的时候,往往希望可以获得更细粒度的信息。
综上,本文设计了一个基于规则的行政区划归类方法。该方法首先对文本分词后的结果进行地名实体提取,再通过与三级行政区划表的比较,结合多条规则,求出最符合文章的行政区划,对于无法通过前述方法求出行政区划的文章,再利用百度地图API进行二次归类,最终达到一个较高的准确率。
基础算法通过比较词频的方式来决定行政区划的可信度。具体方法如下:
(1)将分词结果中词性为“ns”(地名)的词汇取出,将该词与出现次数保存进P。
(2)遍历P中的地名词汇w,将w与一、二、三级行政区划表中的地名进行匹配。将匹配到的行政区划a和w的加权词频存入U中。
(3)将U中每个行政区划的词频进行开根号处理(目的是降低词频饱和度),获取初步的可信度分数。
(4)对U中二、三级行政区划的分数加到上级行政区划上。
(5)在U中寻找分值最大的一级行政区划,然后在该区划中寻找分值最大的二级行政区划。
当一篇法律文章中同时出现上下两级行政区划(如:同时出现“上海市”“浦东新区”)时,这篇文章可能比只出现“上海”的文章更有可能属于上海市,即“上海市”和“浦东新区”两级行政区划在相互印证。因此,本文对同时出现上下两级行政区划的情况做出加分处理,在上面基础方法的第(3)步之后,“上海市”的分数将乘以(1+γ),γ为奖励系数。另外,法律文章标题中也蕴含地理位置信息。例如 “湖南衡阳女子,5年第5次离婚案宣判”,就能明显辨别出这篇法律文章的归属地为湖南省衡阳县。因此,本文对文章标题也进行了分词与词性标注,以同样的办法应用了上一节的(1)~(4)步,获取了标题的U,进行加权求和。然而,部分文章虽然包含了许多行政区划,但实际上是一篇综合性的文章,无法进行明确的行政区划归类。本文将出现大于等于4个省的文章,当做综合性文章;将某省内大于等于4个市的文章当做该省内的综合性文章。综合这3条优化规则后,最终算法流程如算法1所示。
算法1行政区划归类算法
输入Ptext,PtopicAdministrativeDivisionDictionary as dic
输出location,child_location
for(w,tf)inPtext,Ptopic:
locationList = findAdministrativeDivisionInDic(w, dic)
if locationList != null:
for loc inlocationList:
U.put(loc,U.getOrDefault(loc, 0)+ tf/locationList.size())
end for
for(loc,score)inUtext,Utopic:
if haschildLoc inU:
score = score *(1+γ)
childLoc.score = childloc.score *(1+γ)
for(loc,score)in Utext,Utopic:
if loc is childLoc:
parentLoc.score += loc.score
for(loc,score)in Utext,Utopic:
if loc inUtext = loc in Utopic :
score =scoretext +scoretopic
Uall.put(loc,score)
find the loc with biggest score inUall
find thechildLoc of loc with biggest socre in Uall
returnloc,childLoc
最后,本文对于行政区划归类方法进行了再度的优化,对那些无法进行归类的文章,利用百度地图API的地点检索服务。
1.2.2 主题立方体构建方法
通过对法律文章预处理和行政区划归类,法律文章拥有了时间和地点两个维度,因此主题立方体[14]可以表示为如图3的形式。其中横坐标为地点,纵坐标为时间,每个小方块中的内容即主题立方体的度量,即某一时间某一地点的主题分布。对于拥有时间和地点信息的法律文章数据,用户通过数据立方体,可以从时间和地域两个维度对这批数据进行OLAP操作。当用户想获取2月份上海市的法律文章时,只需要数据立方体中时间维从2月1日~2月29日以及地域维为上海的数据即可。
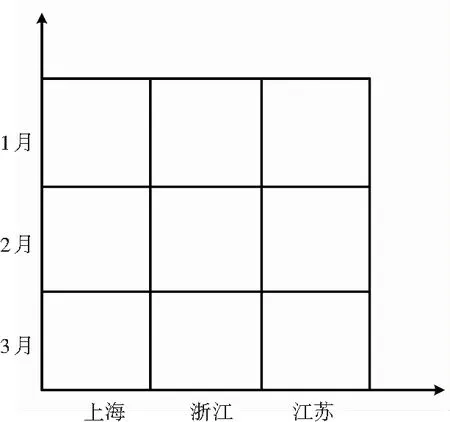
图3 主题立方体表示方式一
由于图3所示的定义中缺失城市地理位置信息这一重要信息,从图中无法知悉上海市和江苏省是否相邻,这种相邻关系在计算最大独特主题范围时非常重要。因此,本文将主题立方体表示为图4所示的形式,更能反映主题立方体真实的状态。图4是一张三维的中国地图,其厚度代表时间维度,时间沿着z轴的方向延伸。这样的表示方式保留了各省份之间的地理位置相对关系,可以承载更多的地理位置信息,同时也更加直观,便于理解。
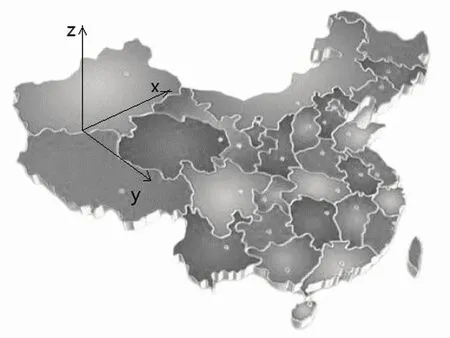
图4 主题立方体表示方式二
因此,本文提出了一种在多维文本集的主题立方体度量计算方法。其计算流程如下:
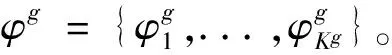
(2)对Cube中的每个中等大小单元进行训练:中等大小单元为一个二维的范围。例如“上海市1月份”的所有法律文章,粒度选择为某省某一个月份的所有法律文章。对于每个子单元ci,指定主题数量为Kl,利用吉布斯采样的方法训练出Kl个子主题。所以,总的子主题数|cell|*Kl,|cell|为全部子单元个数。
(4)经过第(3)步之后,全局主题得到了扩展,这其中的每个主题之间的Kl散度都超过阈值τ,则将这些主题做为最终的主题模型φ。最后,使用该主题模型φ,通过吉布斯采样的方式,计算每篇文章的主题分布θ,这一步被称为推导。
(5)获得了每篇文章的主题分布θ后,可以简单的聚合出每个最小单元的主题分布。此外,在时间维和地点维的不同粒度上进行聚合,以此来满足OLAP的上卷、下钻、切片等要求。
此后,将每篇文章的主题分布、一些单元的主题分布以及主题模型中每个主题的词概率分布存入HBase中,供OLAP模块使用。
1.3 线上查询技术
1.3.1 基于倒排索引的关键词搜索法
由于关键词搜索是线上模块,对于线上模块来说一个非常重要的指标就是时间效率。因此,OLAP系统对线上查询的性能要求较高,找到一种提升运行效率的算法尤为关键。
本文关键词搜索算法基于倒排索引的思想,将词汇表中的所有词作为关键,将包含这个词的所有主题以及这个词在这些主题中的概率作为值,存入HBase中。当用户输入某几个关键词时,只需在HBase中找到相应的条目,统计value中存在的主题分数即可。例如:表4展示了HBase中有“交通肇事”、“驾驶”、“离婚”、“财产分割”等关键词,其中关键词“交通肇事”在主题1、5、7中出现,概率分别是0.032 3、0.012 3、0.020 4。输入关键词“交通肇事 驾驶”进行搜索,通过倒排索引可以快速查询到包含“交通肇事”和“驾驶”关键词的主题及对应的概率,对主题进行分值计算就能获得最终结果。此例中,最符合这两个关键词的主题是主题1,其分值为0.032 3+0.024 5=0.056 8。通过倒排索引的方式,在主题数量十分庞大的情况下,搜索引擎可以在极短的时间内返回包含关键词的文章。
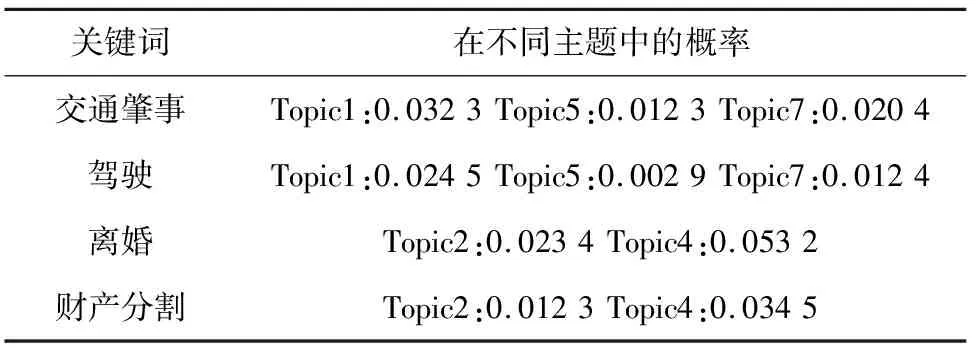
表4 关键词搜索的倒排索引
1.3.2 基于剪枝的最大独特主题范围查找法
独特主题是指经常出现在文档某一范围内的主题。本文用独特主题分数(Uscore)来评价该主题属于某一范围的独特程度。
(1)
其中:θrk表示主题k在范围r上的概率,θgk表示主题k在全局范围上的概率。当某个主题的独特主题分数大于阈值λ时,说明该主题是范围r上的独特主题。公式为:
UT(r)={k|UScore(r,k)>λ,k∈{1,...,K}}
(2)
其中,λ用来衡量一个主题在全局上的的独特程度。λ设置得越高,则被认定为独特主题的门槛就越高。这个参数可以由用户自行设定,默认值为0.007。
对于主题集合T中某个主题k来说,所有满足∃k∈T,k∈UT(r)和∀r'∈S,∀k∈T:r∈r',k∉UT(r')条件范围的r,都是该主题的最大独特主题范围。
其中,S为全部范围集合。当k是范围r上的独特主题,而且k不是任何包含r的范围的独特主题,那么r就是一个k的最大独特主题范围。
求最大独特主题范围的基本思路是:求出所有范围的独特主题,在其中找到包含主题k的范围,然后筛选出最大范围。具体流程如下:
(1)计算每个范围r的UScore(r,k)。
(2)找到UScore大于阈值的主题,作为范围r的独特主题。
(3)对于某个特定的主题,找到把其作为独特主题的所有范围。
(4)对步骤(3)中求出的范围进行筛选,得到最大范围集。
在地理维度上,“上海市”是一个范围,“上海市 浙江省”是一个范围,“江浙沪”也是一个范围,只要省份相邻就会形成新的范围。由于需要计算所有范围的独特主题,范围的个数非常多。因此,文献[15]中提出了在时间维度上找最大独特主题范围的剪枝算法。对于任意r和r',如果r和r'的Uscore(r,k)和UScore(r',k)都小于阈值λ,即主题k既不是r上的独特主题也不是r'上的独特主题,那么k也不可能是r∪r'上的独特主题。基于上述事实,本文设计了在地理维度上的剪枝方法。对于固定的主题k,剪枝算法先计算每个最小粒度范围的独特主题分数,然后再将相邻的范围组合,再次计算独特主题分数。如果两个子范围的独特主题分数都不满足条件,则其并集必定不满足条件。当计算出湖北省的独特主题分数之后,要找到其所有的邻居省份,分别计算取并集之后的独特主题分数。如果满足最大独特主题范围,则保留该省份。
2 系统评估
2.1 实验环境
为了验证系统的准确性以及线上即时交互的效率,对系统整体进行了测试。测试内容包括对行政区划归类模块的准确性测试和线上查询响应时间测试。
系统数据爬取自中国新闻网2019年1月~2020年5月发布的法律新闻数据,共347 635篇,去重后为273 029篇。系统使用Java语言开发,硬件环境见表5。
表5 硬件环境
2.2 行政区划归类准确性测试
通过人工标注方式,对530篇文章进行了手工标注,标注形式为<一级行政区划,二级行政区划>。如,法律新闻《张家界通报导游怒骂游客骗吃骗喝调查处理:对旅行社罚20万》被标注为<湖南省,张家界市>。实验对基础方法、优化方法,以及使用百度地图API辅助方法进行测试,测试结果,见表6。

表6 行政区划归类准确性测试
由此可见,无论是否使用地图API,优化方法的准确率都超过了93%,使用地图API辅助的方法准确率达到了95.6%,但在时间上的劣势比较明显。主要原因是每次使用地图API都需要进行一次远程调用,在这次实验当中,共有11篇文章未在行政区划识别词典中找到相关的行政区划,这部分文章都需要使用地图API进一步搜索。可以看出,调用地图API的成本比较大,但是总体的时间复杂度以及准确率均尚可。
2.3 线上查询响应时间测试
在线上查询响应时间的测试中,经反复调整输入的时间区间以及关键词,最后得到每个小模块的响应时间,结果如图5所示。可以看到,关键词搜索的平均响应时间在0.02 s左右。最大独特主题范围在1.2 s左右,下钻操作本身也是一个最大独立范围查询的过程,但是因为地图的范围比较小,所以查询时间比较短。相关新闻查询的平均响应时间为70 ms,虽然每个主题在任意空间和时间范围内的相关文章已经预先存储在posting list中。但因posting list空间占用过大,在增量压缩之后依然无法放入内存中,其时间主要消耗在读盘以及解压缩中。
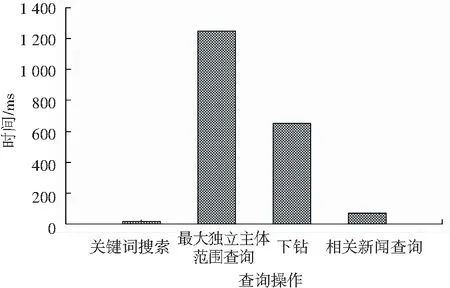
图5 平均响应时间
3 结束语
本文设计并实现了一个面向司法大数据的文本主题OLAP系统,设计了新的数据模型Span保存数据,并针对这种新的数据模型设计了多个操作符,后续的数据处理均由这些操作符组合实现。
针对文章无地理位置维度问题,提出了基于规则的二级行政区划归类,对提取出的地名词汇进行了可信度排序,从而得到最符合文章条件的行政区划。对于无法匹配的地名,通过调用百度地图API的方式进行识别,识别准确率高达95%以上。
在关键词相关主题匹配问题上,采用倒排索引的方式,将一个词语对应多个与之相关的主题,从而将单个关键词匹配主题的时间复杂度降低到常数级别。对于最大独特主题范围查询问题,本文提出一种在地理维度上快速寻找最大独特主题范围的方法。平均线上查询时间在优化过后保持在1 s以内。
